原论文链接:https://arxiv.org/abs/2103.00020
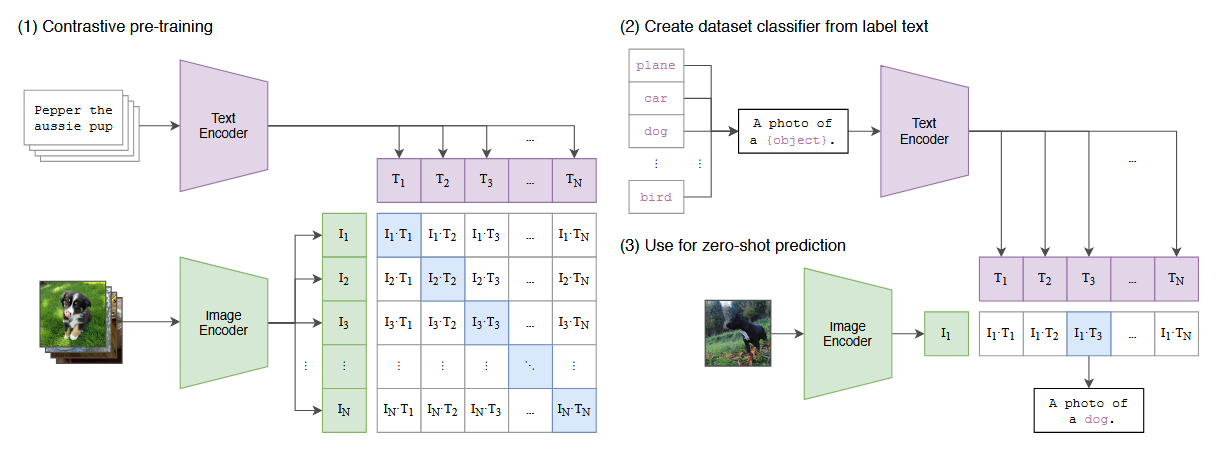
原论文的框架图展示了分为三大阶段:
(1)Contrastive Pre-training:对比预训练
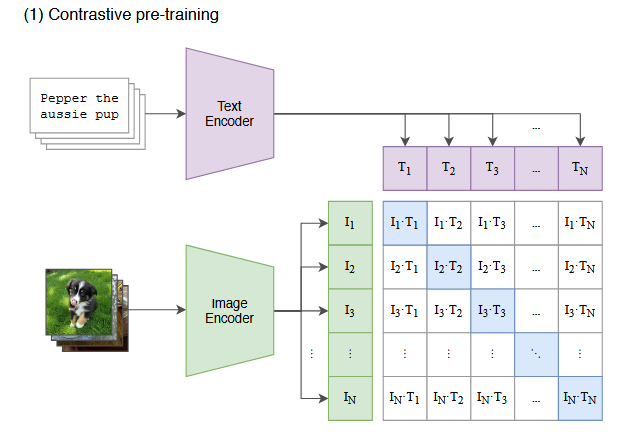
这一步是 CLIP 的核心,目的是学习图像和文本的对齐特征空间。
- 输入 :大量成对的「图像-文本描述」(例如图中的狗狗照片 + 文字描述 "Pepper the aussie pup")。
- 双编码器 :
- Image Encoder(绿色) :把图像映射成向量 I 1 , I 2 , . . . , I N I_1, I_2, ..., I_N I1,I2,...,IN
- Text Encoder(紫色) :把文本映射成向量 T 1 , T 2 , . . . , T N T_1, T_2, ..., T_N T1,T2,...,TN
- 对比学习目标 :
计算所有图像向量和文本向量的余弦相似度矩阵 (图中的格子矩阵),训练目标是让匹配的图文对(对角线蓝色格子)相似度最大化 ,不匹配的对相似度最小化。
这一步让模型学会了:"狗的图像"和"描述狗的文字"在特征空间中是离得最近的。
对角线格子 对应的是完全匹配的「图像-文本对」:
- I 1 ⋅ T 1 I_1 \cdot T_1 I1⋅T1:第1张图像和它自己的描述文本的相似度
- I 2 ⋅ T 2 I_2 \cdot T_2 I2⋅T2:第2张图像和它自己的描述文本的相似度
- ...
- I N ⋅ T N I_N \cdot T_N IN⋅TN:第N张图像和它自己的描述文本的相似度
这些对角线的蓝色格子,就是我们要最大化的目标------让图像和它自己的描述文本在特征空间里尽可能接近。
(2)Create dataset classifier from label text:用标签文本生成分类器
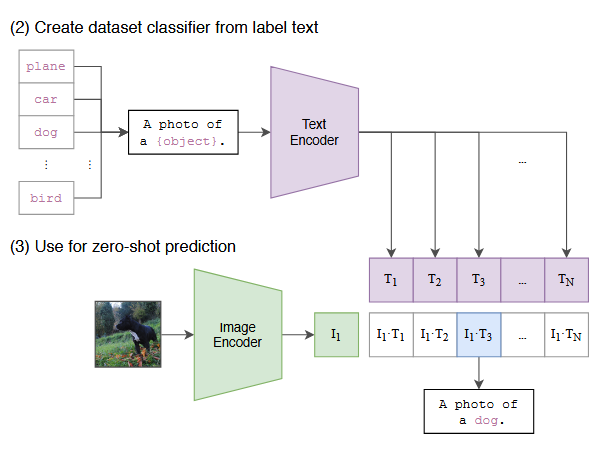
预训练完成后,模型学会了图文对齐,我们就可以用它做分类任务了。
- 输入 :数据集的类别标签(比如
plane、car、dog、bird)。 - 模板化文本 :把标签套入固定模板,比如
A photo of a {object}.,得到描述文本:A photo of a plane.、A photo of a dog.。 - 文本编码 :用训练好的 Text Encoder ,把这些模板文本编码成向量 T 1 , T 2 , . . . , T N T_1, T_2, ..., T_N T1,T2,...,TN。
这些向量,就构成了零样本分类的"类别原型"。
(3)Use for zero-shot prediction:零样本预测
这一步就是用 CLIP 做无训练分类。
- 输入:一张待分类的图像。
- 图像编码 :用 Image Encoder 把图像映射成向量 I 1 I_1 I1。
- 相似度匹配 :计算 I 1 I_1 I1 与上一步生成的所有文本向量 T 1 . . . T N T_1...T_N T1...TN 的余弦相似度。
- 输出结果 :相似度最高的文本,就是模型的预测结果。
比如图中 I 1 ⋅ T 3 I_1 \cdot T_3 I1⋅T3 相似度最高,对应文本是A photo of a dog.,模型就判定这张图片是"狗"。
总结
CLIP 先通过对比学习,把图像和文本都"翻译"到同一个特征空间;再通过文本模板,把分类任务变成"找最像的文本描述",从而实现零样本分类。