多模态思路 LLM Wiki Skill
"LLM 负责写和维护 wiki;人负责阅读和提问。"
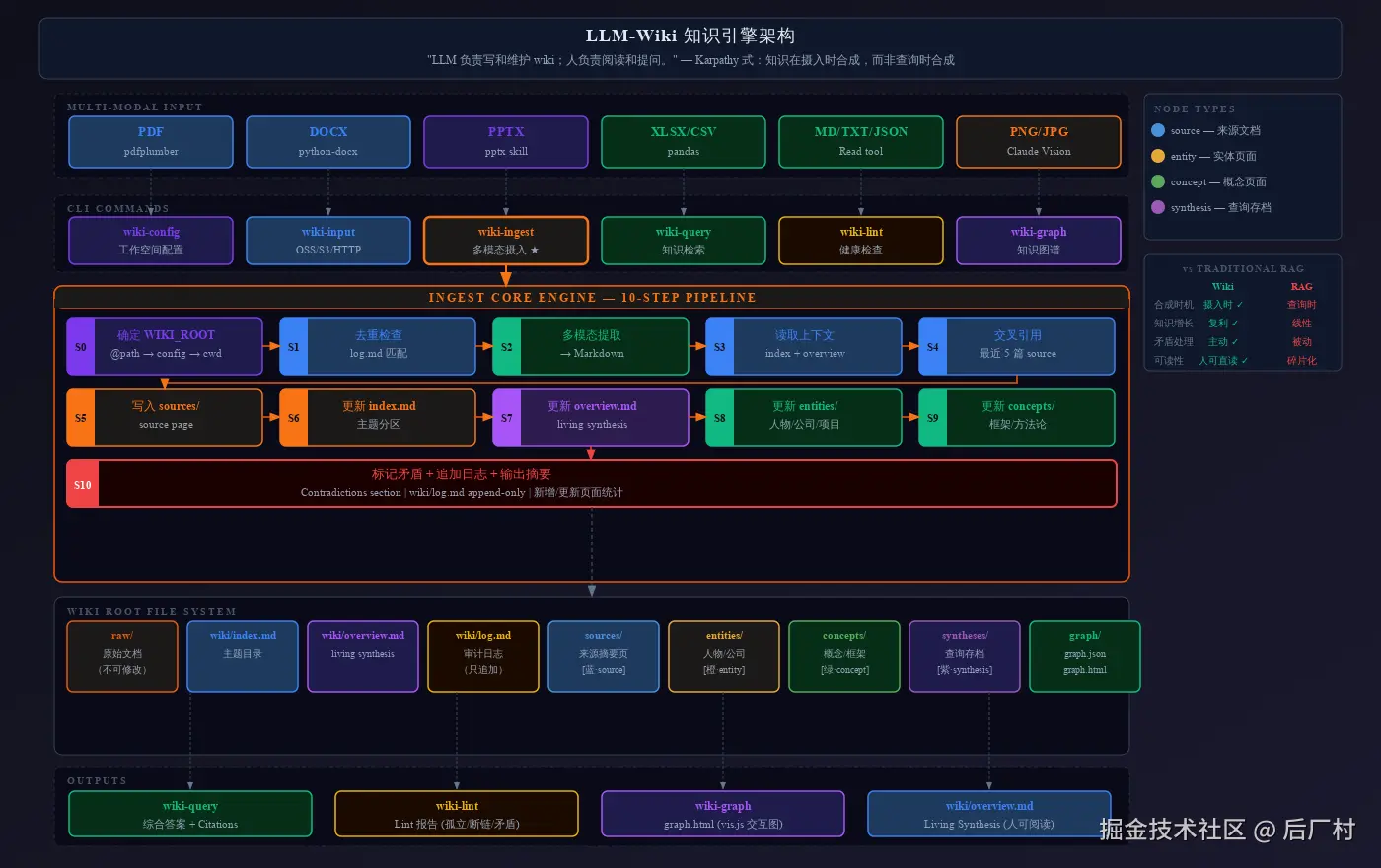
llm-wiki-skill是什么
llm-wiki-skill 是一个运行在 Claude Code 中的 Skill,将任意格式的原始文档(PDF、DOCX、PPTX、XLSX、Markdown、图片)摄入到结构化 Wiki,并自动构建可交互的知识图谱(graph.html)。
它实现 Karpathy 提出的知识管理理念:知识在摄入时合成,而非查询时合成。每次新文档加入时,LLM 自动提取要点、建立交叉引用、标记矛盾、更新综合摘要,使知识库随每次摄入复利增长。
这与 RAG 的核心区别在于:RAG 把原始文档丢进向量库,查询时临时组装答案;llm-wiki 在摄入时就把知识编译为耐久的 wiki 页面,查询时读取已综合好的结论。
目录结构
perl
<wiki-root>/
raw/ # 原始文档(永远不修改)
<topic>/ # 按主题组织,一级子目录
wiki/
index.md # 所有页面的目录(按主题分区)
overview.md # 跨来源的 living synthesis
log.md # 只追加的操作日志
sources/ # 每份原始文档的摘要页
entities/ # 人物 / 公司 / 项目 / 产品
concepts/ # 概念 / 框架 / 方法论
syntheses/ # 查询答案存档
archive/ # 归档的过时页面
graph/
graph.json # 节点 + 边数据
graph.html # 基于 vis.js 的自包含可视化命令速查
| 命令 | 用途 |
|---|---|
wiki-config workspace <path> |
设置 wiki 工作空间路径 |
wiki-config show |
查看当前配置及目录状态 |
wiki-input <path> [--topic <slug>] |
摄入任意路径文件(自动归档到 raw/<topic>/) |
wiki-ingest <file> |
摄入已在 raw/ 中的文件 |
wiki-query: <问题> |
查询知识库,综合答案 |
wiki-lint |
检查孤立页面、断链、矛盾等质量问题 |
wiki-graph |
构建可视化知识图谱(graph.html) |
日常使用推荐 wiki-input :接受本地或远程路径,自动复制到 raw/<topic>/ 归档后再摄入,无需手动管理 raw/ 目录。
工作流说明
摄入(Ingest)
摄入一份文档时,LLM 会依次执行:
- 多模态内容提取(PDF/DOCX/PPTX/XLSX/图片 → Markdown)
- 写入
wiki/sources/<slug>.md(摘要、要点、关键引用) - 更新
wiki/index.md和wiki/overview.md - 创建或更新
wiki/entities/和wiki/concepts/页面 - 标记与已有内容的矛盾
- 追加操作日志到
wiki/log.md
查询(Query)
读取 wiki/index.md 识别相关页面,综合答案并以 [[PageName]] 格式内联引用。可选将答案存为 wiki/syntheses/<slug>.md 归档备查。
知识图谱(Graph)
提取页面间的显式 wikilink(EXTRACTED)和 AI 推断的语义关联(INFERRED,置信度 ≥ 0.5),生成零依赖的自包含 graph.html,支持节点类型着色和社区分组。
支持格式
| 格式 | 提取方式 |
|---|---|
.md .txt |
直接读取 |
.pdf |
pdfplumber(文本 + 表格) |
.docx |
python-docx(正文 + 标题 + 表格) |
.pptx |
python-pptx(标题 + 正文 + 备注) |
.xlsx .csv |
pandas(转 Markdown 表格) |
.png .jpg .jpeg .webp .gif .bmp |
Claude vision(多模态) |
多模态支持详解
llm-wiki 使用 Claude 原生多模态能力理解图像内容------不仅是 OCR 文字识别,而是对图表、流程图、截图的完整语义理解。
直接摄入图片文件
将图片文件直接传给 wiki-input 或 wiki-ingest,Claude 读取图片并转换为结构化 Markdown,再进入标准 Ingest 流程:
bash
wiki-input ~/截图/架构图.png --topic system-design
wiki-input ~/照片/白板会议.jpg --topic meetingsClaude 从图片中提取的内容:
- 图表与折线图 --- 数据系列、坐标轴标签、趋势、数值
- 架构图与流程图 --- 节点、连线、关系、流向
- 截图 --- UI 结构、可见文本、布局上下文
- 手写笔记 / 白板 --- 转录文字和绘制的结构
- 图片中的表格 --- 重建为 Markdown 表格
- 混合内容 --- 拍照或扫描的含文字和图形的文档
文档内嵌图片
摄入包含嵌入图片的 PDF、DOCX 或 PPTX 时,提取工具会获取所有文字内容。若文档中的图表对理解至关重要,而纯文字提取不足以覆盖,可将这些图表另存为图片文件单独摄入。
支持的图片格式
| 格式 | 说明 |
|---|---|
.png |
无损压缩,适合截图、架构图 |
.jpg / .jpeg |
照片、扫描文档 |
.webp |
网络优化图片 |
.gif |
分析第一帧(静态内容) |
.bmp |
未压缩位图 |
多模态提取流程
所有图片内容经过与文本文档相同的 Ingest 流程------图片仅在进入流程前先转换为 Markdown:
perl
图片文件
│
▼
Claude Vision(Read 工具)
│ 提取:文字、结构、数据、关系
▼
Markdown 描述
│
▼
标准 Ingest 流程(步骤 2--10)
│ sources/ entities/ concepts/ index/ overview/ log/
▼
Wiki 页面 + 知识图谱快速开始
bash
# 1. 设置 wiki 工作空间
wiki-config workspace ~/my-wiki
# 2. 摄入第一份文档
wiki-input ~/Downloads/paper.pdf --topic papers
# 3. 查询
wiki-query: 这篇论文的核心贡献是什么?
# 4. 构建知识图谱
wiki-graph