目录
- 🌷引言:AI时代下,系统的进化
- 🌷具体改造步骤
-
- [1. 搭建环境](#1. 搭建环境)
- [2. 引入系统](#2. 引入系统)
- [3. RAG架构设计(图+描述)](#3. RAG架构设计(图+描述))
- 🌷接口测试
- 🌷踩坑记录
- 🌷附:核心代码段
-
- [1. UserContext 与 JwtFilter](#1. UserContext 与 JwtFilter)
- [2. SecurityConfig 中的 CORS 配置](#2. SecurityConfig 中的 CORS 配置)
- [3. RAG投喂链路:自动化切片与向量化存储](#3. RAG投喂链路:自动化切片与向量化存储)
- [4. 智能问答里线路:基于语义的增强生成](#4. 智能问答里线路:基于语义的增强生成)
- [5. 全链路监控日志逻辑](#5. 全链路监控日志逻辑)
这篇也是基础博客,毕竟我是小白。在原本的系统上进行更新改造。(5)的版本和这版(6)之间我改了挺多部分没往上写的,比如添加了新的接口啥的,很基础的东西,或者代码结构略变了一下......(所以别跟着写,不然会很跳跃...搞崩溃呢...这篇用的策略可以进行参考)
🌷引言:AI时代下,系统的进化
-
现状:我目前使用的是 MySQL 的模糊检索(LIKE %keyword%)。
-
痛点:用户搜索"深度学习",如果文章里写的是"神经网络",他就搜不到,这不符合"跨学科交流"的初衷。
-
于是我们引入RAG(Retrieval-Augmented Generation,检索增强生成)架构。
-
技术栈新增
- LangChain4j
- Milvus / Weaviate / Qdrant:选一个向量数据库(证明你懂非结构化数据)
- 本地LLM:使用 Ollama 在你本地跑一个 Qwen 2.5 或 Llama 3,省去 API 费用。
🌷具体改造步骤
1. 搭建环境
- 看这篇博客:从零搭建 Spring Boot 3 + 本地大模型 (Ollama) 的 AI 开发环境

- 选 Ollama + Gemma 3:实现零成本与离线开发。gemma3是轻量级优秀开源模型。
- LangChain4j 的集成:它把大模型(ChatModel)、向量化模型(EmbeddingModel)和向量数据库(EmbeddingStore)全部抽象成了接口。且自带了文档切片器(DocumentSplitters)、检索器(Retriever)以及对话记忆管理(ChatMemory),避免程序员去手写这些底层逻辑。
2. 引入系统
按照 RAG(检索增强生成) 的标准流程,我们需要修改的代码分为三部分:基础设施层、数据存入层、AI 交互层。
- 1)配置基础设施
在 Spring Boot 中,我们需要定义几个核心的 Bean:模型、向量存储、文档助手。
当一篇文章发布时,我们需要把它转化为向量存进数据库。 - 2)数据存入层
原本的文章保存在 MySQL。现在的逻辑是:文章存入 MySQL 的同时,也要切片、向量化,存入向量数据库。 - 3. AI 交互层 ------ 实现"智能问答"
这是 RAG 的核心。系统会先去向量库找资料,再把资料喂给大模型。
3. RAG架构设计(图+描述)
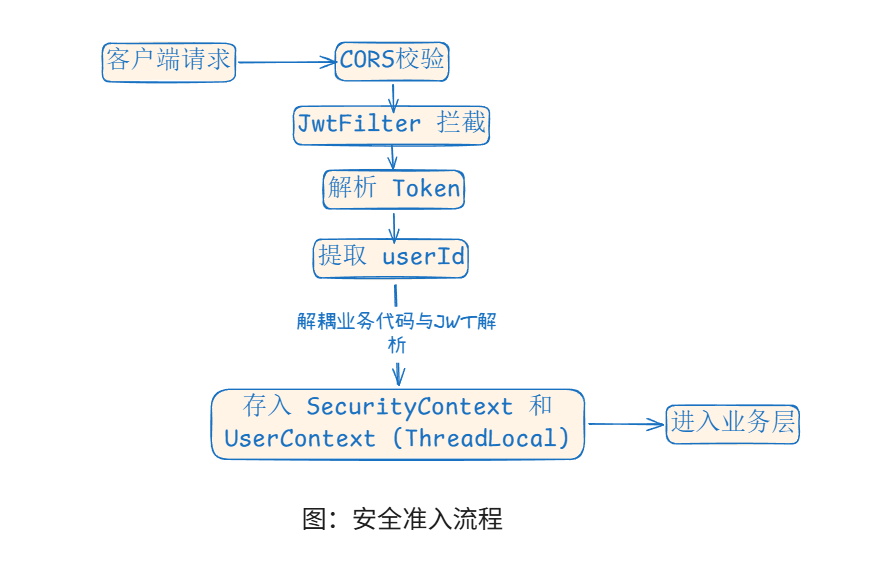
首先,不论进行什么业务,都要先进行身份校验,如图是逻辑链路:
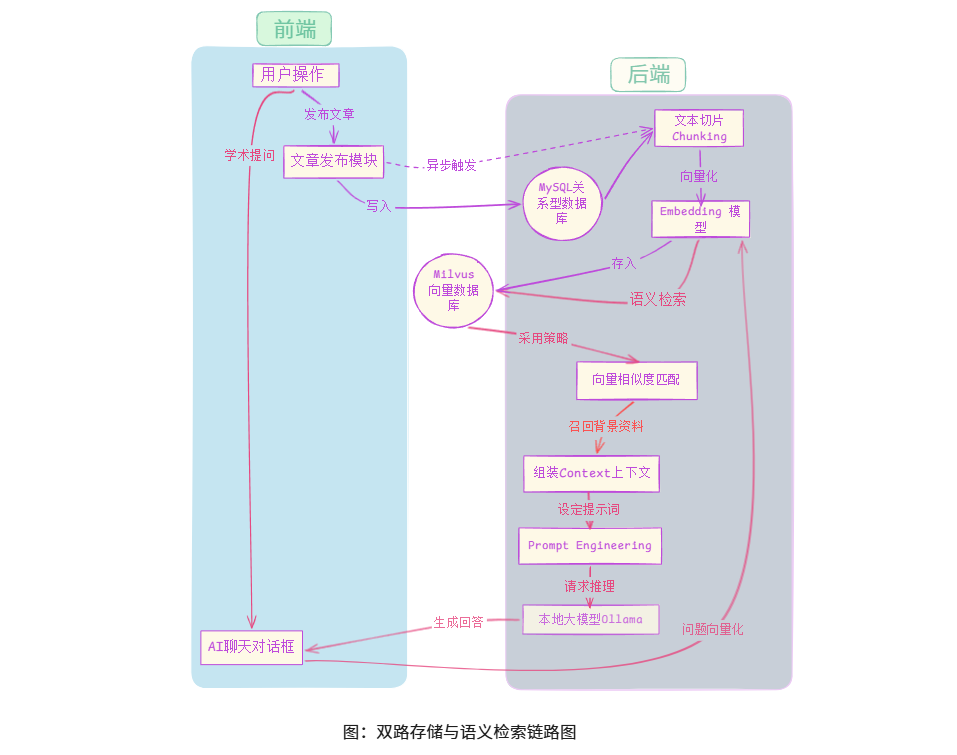
发布文章流程:
- 原始文本存入MYSQL(保证基本存储)。
- 同时,启动异步任务将长文章切片成易读的小块
- ------>利用Embedding模型将这些文字转换成代表语义特征的数字向量
- ------>把向量连原文一起存入Milvus 向量数据库。
智能助手问答流程:
-
核心逻辑:解决"AI 如何根据我的博客给出准确答案?"。
-
用户发起提问
-
------>系统经过安全准入,确保是合法用户提问
-
------>后端调用与投喂时相同的 Embedding 模型,将用户的 自然语言问题转化为空间向量
-
------>系统在向量数据库中进行 近邻搜索 ,找回与问题最相关的 Top-5 文本片段,与原始博客片段 拼接成一段"背景资料"
-
------> 将背景资料和用户问题填入预设的提示词模板(Prompt Template),约束 AI "仅根据资料回答",将最终的 Prompt 发送至本地部署的 Ollama (Gemma 3) 进行推理。
-
------> AI 生成回答 并返回前端
-
------>请求结束,触发 UserContext.clear() ,释放线程资源,防止内存泄漏。
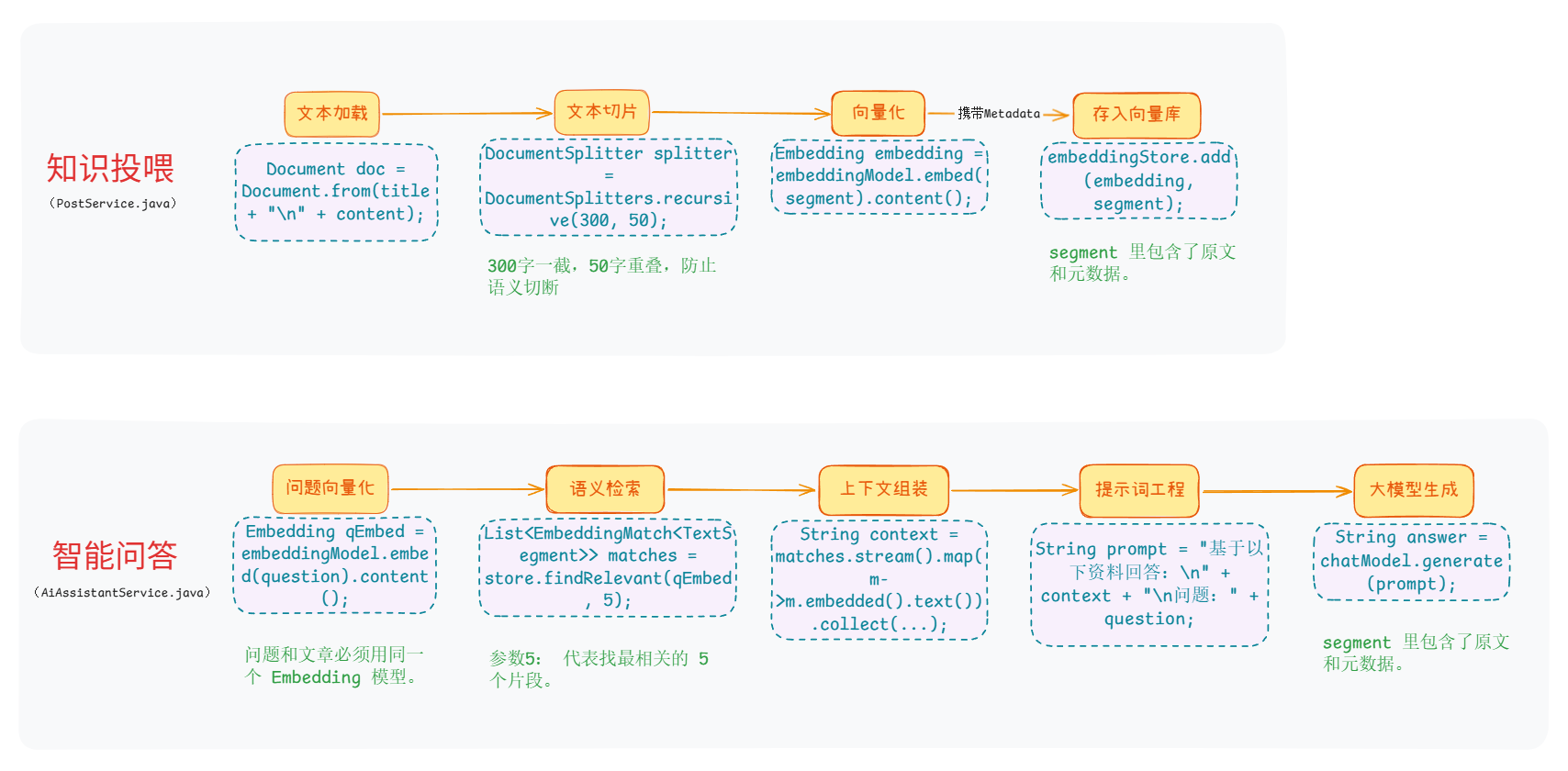
部分名词和逻辑解释:
- 文本切片(Chunking):将长文章切成一块一块。
- Embedding 模型:把文字转化成向量
- Milvus:代码中使用的是 InMemoryEmbeddingStore(内存版向量库)。这是 LangChain4j 提供的"临时方案",直接跑在Java程序里。
- 为什么300字一截,50字重叠?兼顾性能和效果的选择。300字大概是一个标准段落的长度,既能保证包含一个完整的观点,又能让向量检索的匹配度极高。太长的文本块在进行 Embedding 向量化和 LLM 推理时会消耗更多算力。
- 向量化(Embedding):"语义匹配"。将一段自然语言转化为一串固定长度的数字,意思相近的句子或词语被转化出来的坐标就相近。用户搜索的结果会包括相近意思的词与文章。
🌷接口测试
先调用init接口,往向量数据库里存数据。
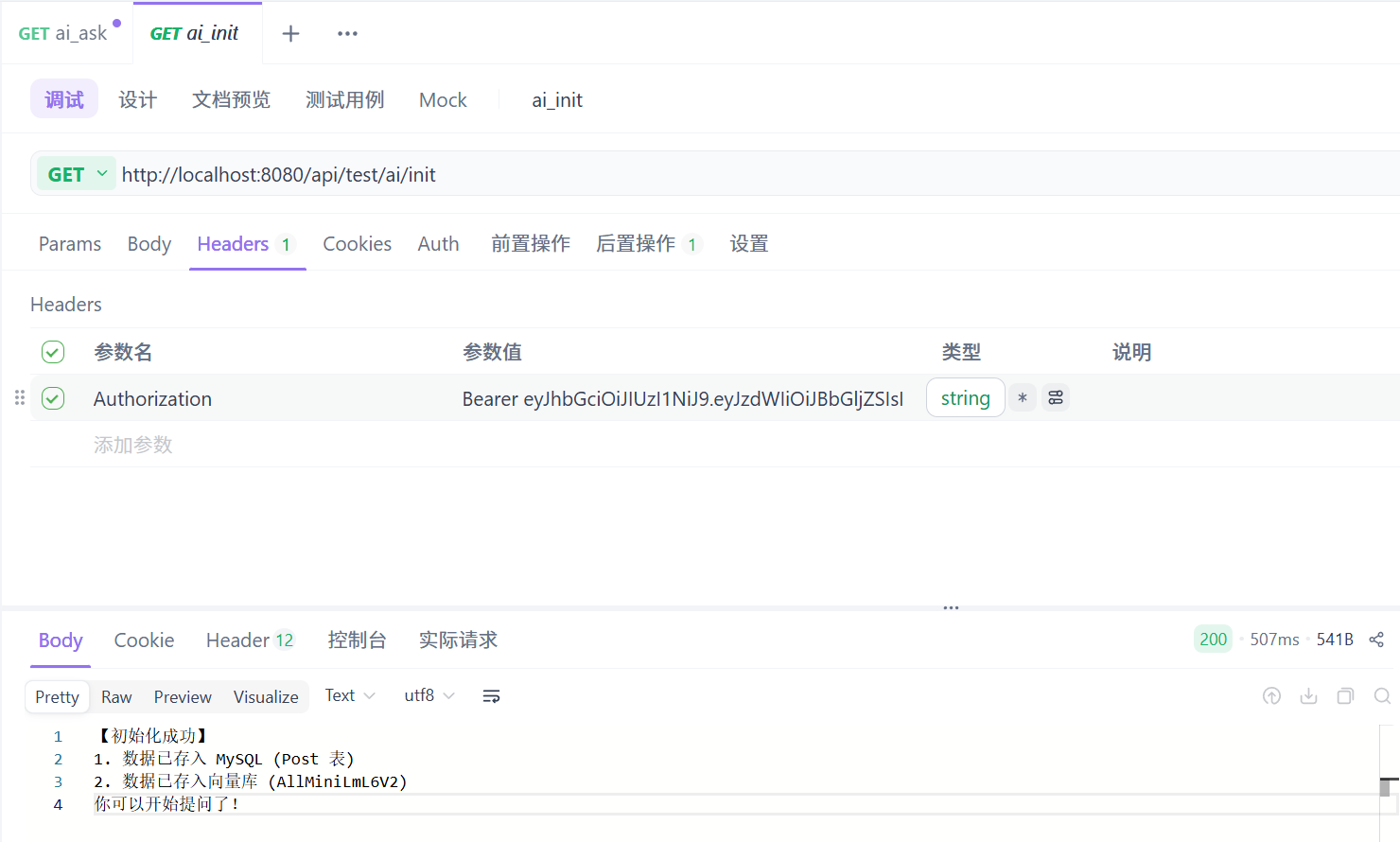
再调用ask接口:
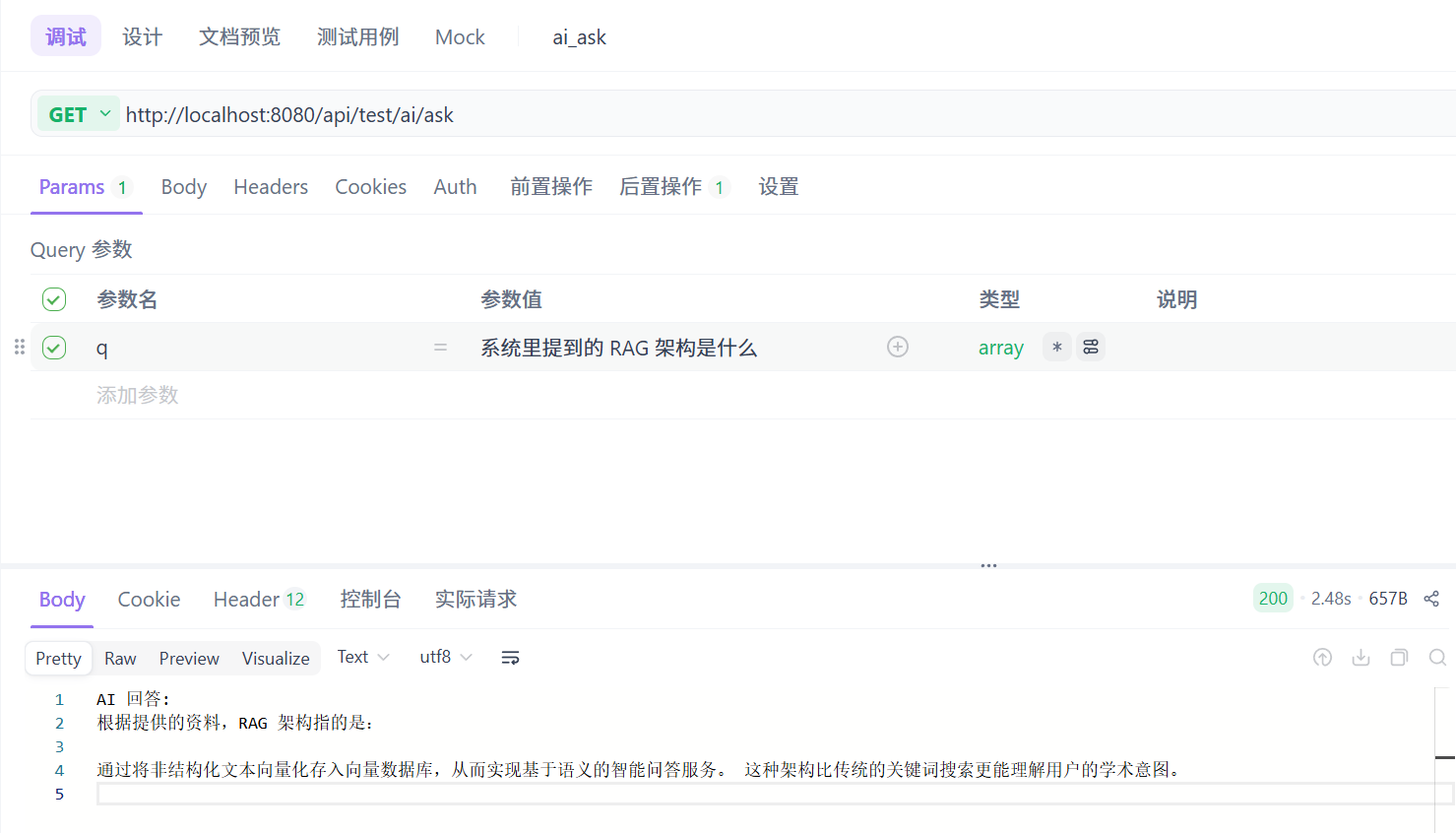
🌷踩坑记录
- CORS 403 错误
- 现象:在 SecurityConfig 中配置了 .permitAll(),且自定义了 CorsFilter,但通过 Apifox 或前端访问时依然报 403 Forbidden: Invalid CORS request。
- 排查过程:发现 Spring Security 6 在处理请求时,其内部的 DefaultCorsProcessor 优先级极高。如果 Security 内部没有显式配置 CORS,它会先于你的自定义 Filter 判定跨域非法。
- 解决方案:废弃独立的 CorsWebConfig,改为在 SecurityFilterChain 中注入 CorsConfigurationSource。
- 经验:在 Spring Security 项目中,凡是涉及安全准入(CORS、CSRF、Session、JWT)的配置,应尽量收敛到 SecurityFilterChain 中统一管理,避免多个 Filter 优先级冲突导致的"幽灵报错"。
- 重启即失效的 Token(JWT 签名异常)
- 现象:系统运行期间一切正常,但只要重启后端服务,之前发放的 Token 全部报 SignatureException(签名不匹配)。
- 原因:使用了 Keys.secretKeyFor(SignatureAlgorithm.HS256)。该方法在每次应用启动时都会生成一个全新的随机密钥。
- 经验:"密钥持久化"。在分布式或生产环境下,JWT 的 Secret 必须是固定的(通过 yml 配置或环境变量注入),否则会导致服务重启后用户强制掉线,无法实现无状态认证。
- UserId 的消失
- 现象:在 JwtFilter 里明明解析出了 userId,但到了 Service 层调用 UserContext.getUserId() 却返回 null,导致数据库报 Column 'user_id' cannot be
null。- 排查过程:通过 Debug 发现,是由于 initData 等测试接口在调用时,没有正确地将 Filter 中提取的 ID 传递给业务对象,或者是异步线程(如果开启了异步)导致 ThreadLocal 隔离。
- 经验:"上下文生命周期管理模式"。 使用 try-finally 结构是 ThreadLocal 的金科玉律:在 Filter 结束时必须调用 remove()。
- 深度思考:在 Tomcat 线程池模型下,线程是复用的。如果不清理,下一个随机请求可能会"继承"上一个用户的身份,这不仅是内存泄漏问题,更是严重的安全漏洞(越权风险)。
- 数据在存入向量数据库这一步失败,模型回答时没有搜索到任何内容。
现象:
- 用户通过 API 提问有关站内文章的问题,AI 明确回答"无法得知相关信息"或"资料未提到"。
- 但MySQL 数据库中文章记录完整,确认业务层保存逻辑已触发。
- 后端显示 >>> 检索到的片段数量: 0,表明向量数据库检索(Retrieval)环节未命中任何有效数据。
原因:MyBatis ID 回填失效。在保存逻辑中,先 insert MySQL 再向量化。由于 PostMapper.xml 未配置 useGeneratedKeys="true",Java 对象中的 id 为 null。
解决:在 Service 层引入全链路日志打印;在 MyBatis 中开启 useGeneratedKeys,确保 Java 对象能实时获取自增 ID,保证元数据完整性。
可复用经验:
- 引入"双路写入日志模式" :在任何涉及双存储(如 MySQL+Redis, MySQL+ElasticSearch, MySQL+VectorDB)的系统中,必须记录每条路径的完成状态。
- 遵循"元数据完整性原则":在非结构化数据投喂时,必须绑定主数据库的 ID。
- 防御性上下文补齐:在 Service 层实现身份自动装配。 下面为具体实践:
javaif (article.getUserId() == null) { article.setUserId(UserContext.getUserId()); }
🌷附:核心代码段
1. UserContext 与 JwtFilter
展示出队线程安全、多用户隔离及内存泄漏预防的理解。
要点:ThreadLocal 的封装以及 finally 块中的 remove()
java
// 核心片段 A:上下文工具类
public class UserContext {
private static final ThreadLocal<Long> USER_ID_HOLDER = new ThreadLocal<>();
public static void setUserId(Long userId) { USER_ID_HOLDER.set(userId); }
public static Long getUserId() { return USER_ID_HOLDER.get(); }
public static void clear() { USER_ID_HOLDER.remove(); } // 防止内存泄漏
}
// 核心片段 B:过滤器中的生命周期管理
@Override
protected void doFilterInternal(...) {
try {
String userId = jwtUtil.parseUserId(token);
UserContext.setUserId(Long.parseLong(userId)); // 身份注入
filterChain.doFilter(request, response);
} finally {
UserContext.clear(); // 关键:请求结束,销毁上下文
}
}2. SecurityConfig 中的 CORS 配置
应对 Spring Security 6 常见的 403 跨域预检问题。
代码要点:显式注入 CorsConfigurationSource。
java
@Bean
public SecurityFilterChain securityFilterChain(HttpSecurity http) throws Exception {
http.cors(cors -> cors.configurationSource(corsConfigurationSource())) // 集成跨域
.csrf(csrf -> csrf.disable())
.authorizeHttpRequests(auth -> auth
.requestMatchers("/user/login", "/api/test/**").permitAll()
.anyRequest().authenticated()
)
.addFilterBefore(jwtFilter, UsernamePasswordAuthenticationFilter.class);
return http.build();
}3. RAG投喂链路:自动化切片与向量化存储
展示非结构化数据处理的工程细节。
代码要点:递归切片参数(300/50)和元数据(Metadata)绑定。
java
@Transactional
public void publishArticle(Post article) {
postMapper.insert(article); // 1. MySQL 持久化
// 2. RAG 投喂:切片策略(300字/片,50字重叠)
DocumentSplitter splitter = DocumentSplitters.recursive(300, 50);
List<TextSegment> segments = splitter.split(Document.from(article.getContent()));
for (TextSegment segment : segments) {
// 绑定元数据,实现引用溯源
segment.metadata().add("articleId", article.getId());
Embedding embedding = embeddingModel.embed(segment).content();
embeddingStore.add(embedding, segment); // 3. 存入向量库
}
}4. 智能问答里线路:基于语义的增强生成
展示Prompt Engineering(提示词工程)和语义检索的逻辑。
代码要点:检索(Retrieve)------>组装(Augment)------>生成(Generate)。
java
public String answerQuestion(String question) {
// 1. 语义检索:寻找最相关的 5 个知识片段
Embedding questionEmbedding = embeddingModel.embed(question).content();
List<EmbeddingMatch<TextSegment>> matches = embeddingStore.findRelevant(questionEmbedding, 5);
// 2. 构造增强提示词(约束 AI 不得瞎编)
String context = matches.stream().map(m -> m.embedded().text()).collect(Collectors.joining("\n"));
String prompt = "你是一个学术助手。请仅根据以下参考资料回答问题:\n" + context + "\n问题:" + question;
// 3. 驱动大模型推理
return chatModel.generate(prompt);
}5. 全链路监控日志逻辑
代码要点:打印相似度分数(Score)和检索到的具体内容。
java
// 在检索代码中加入
System.out.println(">>> 检索命中片段数量: " + matches.size());
for (EmbeddingMatch<TextSegment> match : matches) {
System.out.println(">>> 匹配得分: " + match.score()); // 相似度分数
System.out.println(">>> 片段预览: " + match.embedded().text().substring(0, 20));
}