一、前言:为什么数据同步如此关键?
在微服务、多数据中心、数仓建设等场景中,我们经常面临:
- ❌ 订单系统与风控系统数据不一致
- ❌ 用户修改头像后,APP 端仍显示旧图
- ❌ 数仓报表延迟一天,无法支持实时决策
- ❌ 主从数据库切换后数据丢失
数据同步的本质 :在多个数据副本之间保持一致性 ,同时平衡实时性、可靠性、性能与成本。
本文将系统梳理6 大主流数据同步策略 ,并提供选型指南与避坑建议。
二、数据同步的核心维度
在选择策略前,先明确你的需求:
| 维度 | 选项 | 说明 |
|---|---|---|
| 同步方向 | 单向 / 双向 | 如主从复制 vs 多活 |
| 数据范围 | 全量 / 增量 | 首次同步 vs 后续变更 |
| 实时性 | 批处理(小时级) / 近实时(秒级) / 实时(毫秒级) | 根据业务容忍度 |
| 一致性 | 强一致 / 最终一致 | 金融 vs 电商场景差异 |
| 数据源 | 同构(MySQL→MySQL) / 异构(Oracle→Kafka) | 决定技术选型 |
三、六大核心数据同步策略详解
策略 1:全量同步(Full Sync)------ 初始同步首选 ✅
原理:一次性导出全部数据并导入目标库。
适用场景:
- 新建从库
- 数据迁移(如 MySQL → PostgreSQL)
- 小表每日快照(如配置表)
工具:
mysqldump+mysql- DataX
- Sqoop
缺点:
- 资源消耗大(CPU/IO/网络)
- 无法用于大表(TB 级)
- 同步期间源库可能被锁
💡 最佳实践:全量 + 增量组合使用(先全量,再接增量)
策略 2:基于时间戳的增量同步 ------ 简单场景够用 ⏱️
原理:记录上次同步的最大时间戳,下次只同步更新时间 > 该时间戳的数据。
sql
-- 源表需有 update_time 字段
SELECT * FROM orders
WHERE update_time > '2026-04-02 10:00:00';优点:
- 实现简单
- 无需 DB 权限(只需读表)
缺点:
- 依赖业务字段(可能被误改)
- 无法捕获 DELETE 操作
- 时间回拨问题
⚠️ 注意 :仅适用于无删除、时间字段可靠的场景。
策略 3:基于 Binlog 的 CDC(Change Data Capture)------ 企业级实时同步 🏢
原理:解析数据库事务日志(如 MySQL Binlog),获取 INSERT/UPDATE/DELETE 变更。
代表工具:
- Canal(阿里开源)
- Debezium(Kafka 生态)
- Maxwell
架构:
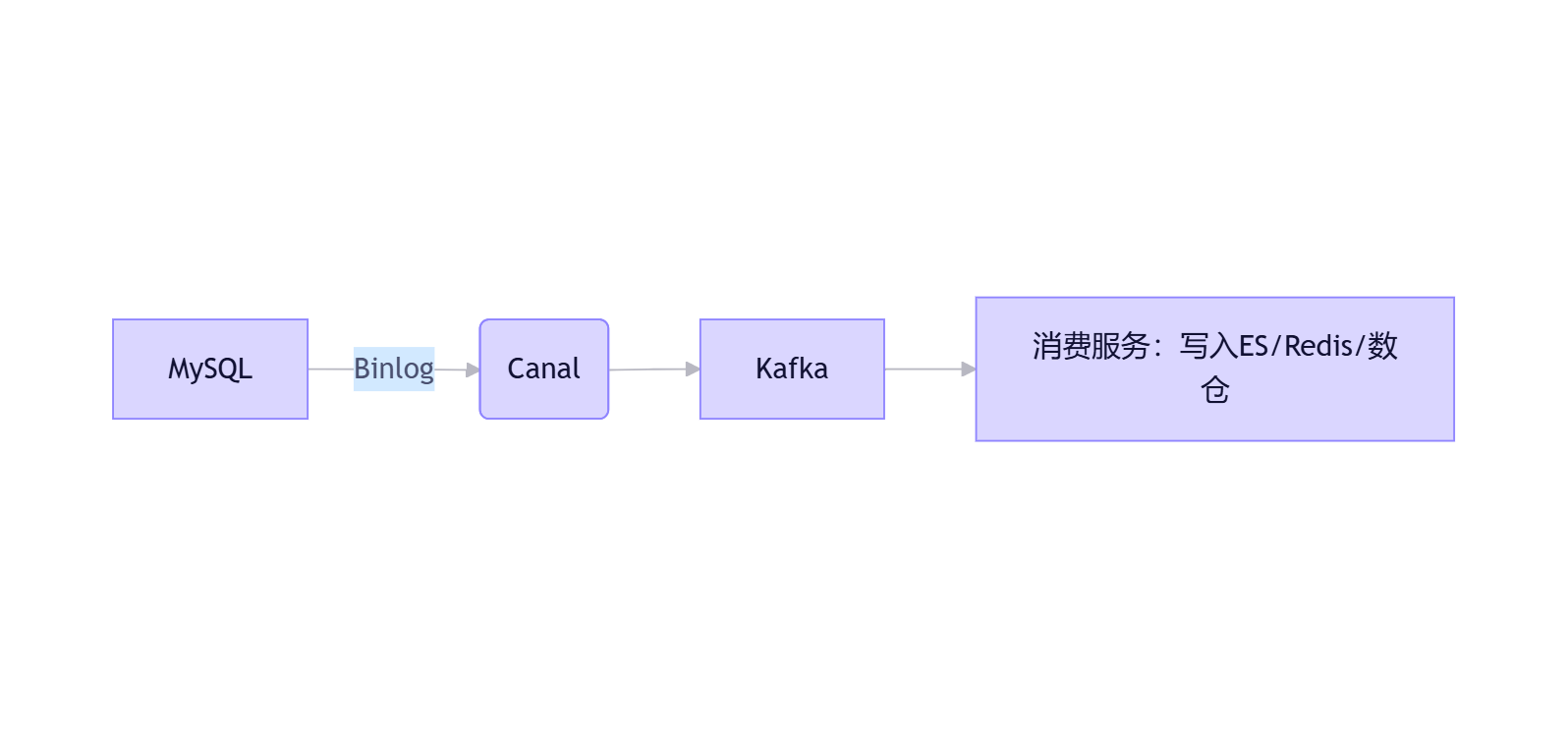
优势:
- 近实时(秒级延迟)
- 低侵入(不改业务代码)
- 支持异构目标(DB → MQ → Cache)
- 捕获完整变更(含 DELETE)
缺点:
- 需开启 Binlog(ROW 格式)
- 运维复杂(需处理断点续传、重复消费)
✅ 典型应用:实时数仓、缓存同步、审计日志
策略 4:消息队列中间件同步 ------ 解耦与削峰 🔗
原理:业务代码在写 DB 后,发送消息到 MQ,消费者负责同步到其他系统。
python
# 伪代码
def create_order(order):
db.insert(order)
mq.send("order.created", order) # 发送事件消费者:
python
def on_order_created(msg):
es.index(msg.order) # 同步到 ES
redis.set(msg.order.id, msg.order) # 同步到 Redis优势:
- 解耦:业务与同步逻辑分离
- 可靠:MQ 保证消息不丢
- 灵活:一个事件可同步到多个目标
缺点:
- 非强一致:存在短暂窗口
- 需处理幂等:防止重复消费导致数据错乱
💡 最佳实践:结合本地事务表 or 事务消息(如 RocketMQ)
策略 5:ETL 工具同步 ------ 复杂转换场景 💼
原理:通过可视化工具配置数据抽取(Extract)、转换(Transform)、加载(Load)。
代表工具:
- DataX(阿里,离线)
- Flink CDC(实时)
- Informatica(商业)
- Kettle(开源)
适用场景:
- 字段映射(user_name → name)
- 数据清洗(过滤无效值)
- 聚合计算(日活统计)
优势:
- 支持复杂逻辑
- 可视化配置,降低开发成本
缺点:
- 学习成本高
- 实时性较差(批处理为主)
策略 6:数据库原生复制 ------ 高可用基石 🛡️
原理:利用数据库内置的主从复制机制。
类型:
- MySQL 主从复制(基于 Binlog)
- PostgreSQL 流复制
- MongoDB 副本集
特点:
- 强一致性(半同步模式)
- 自动故障转移
- 仅支持同构数据库
适用场景:
- 读写分离
- 灾备容灾
- 高可用部署
⚠️ 注意:不适用于异构同步(如 MySQL → Oracle)
四、高级策略:组合拳解决复杂问题
4.1 全量 + 增量组合
- 首次:全量同步(DataX)
- 后续:Binlog 增量同步(Canal)
- 保障:定期校验一致性(如 checksum 对比)
4.2 双写 + 补偿
- 业务层同时写 DB 和 Cache
- 定时任务扫描不一致数据并修复
- 适用:对一致性要求极高但无法用 MQ 的场景
4.3 多级同步链
业务 DB → Binlog → Kafka → Flink → 数仓 Hive
↓
Redis 缓存五、生产环境避坑指南
| 陷阱 | 正确做法 |
|---|---|
| 忽略 DELETE 操作 | 使用 CDC 或带 is_deleted 标记 |
| 时间戳回拨 | 改用自增 ID 或 Binlog 位点 |
| 大事务阻塞同步 | 拆分大事务,监控 Binlog 延迟 |
| 未处理重复消费 | 消费者实现幂等(如 upsert) |
| 无一致性校验 | 定期跑 diff 脚本,告警不一致 |
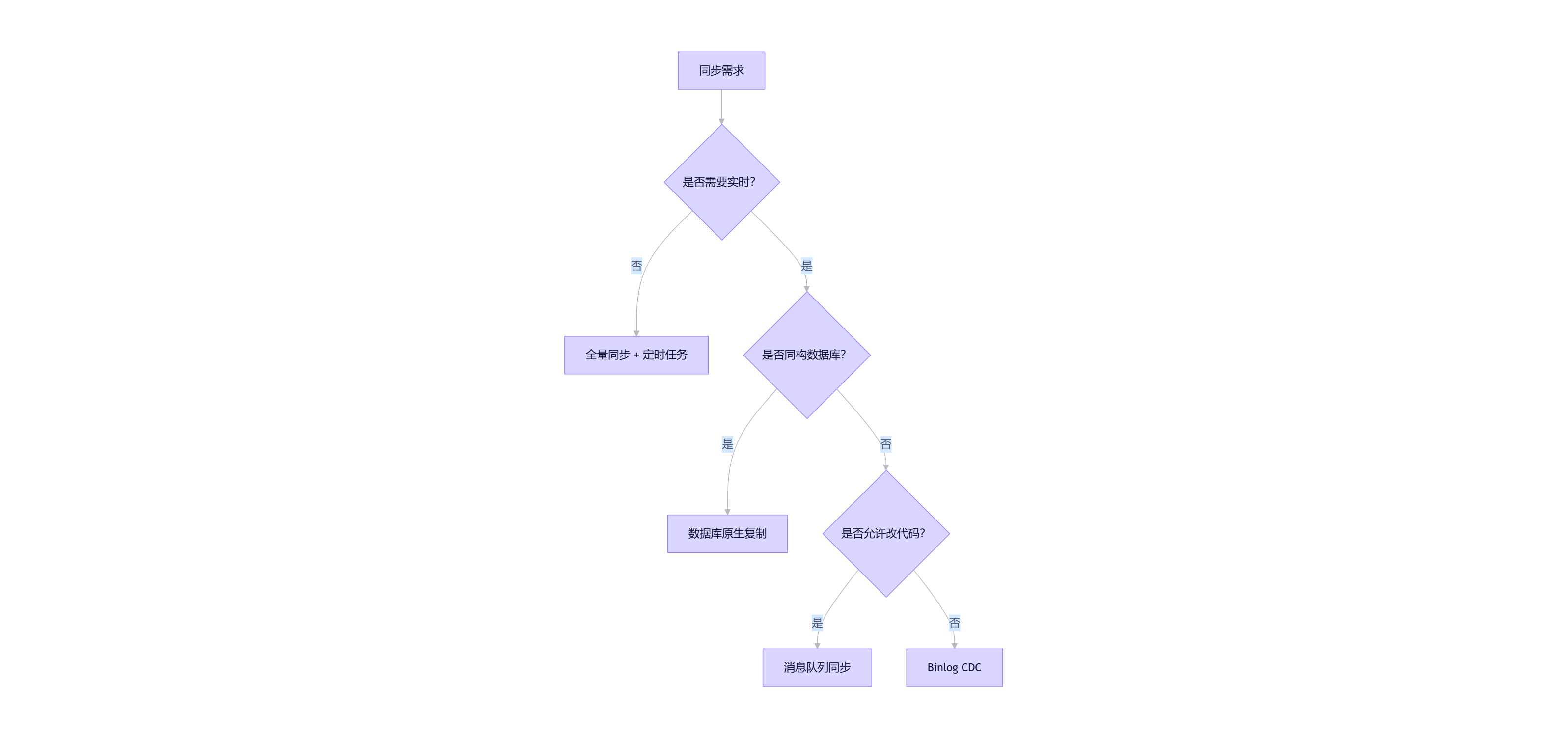
六、策略选型决策树
七、结语
感谢您的阅读!如果你有任何疑问或想要分享的经验,请在评论区留言交流!