利益相关:下面所有结论来自我在生产环境长期调用 Claude API 的观察,数据基于公开接口。文末会提到一个我日常在用的社区状态面板(非官方,与 Anthropic 无从属关系),仅作为一个排障信号源。
先上结论,给凌晨被 PagerDuty 叫醒的同行省一个小时。
结论先行
- HTTP 529
overloaded_error不是你的限流。它是 Anthropic 告诉你:你请求的那个模型,整个容量池已经打满。 - 同模型、同区域、同请求、同一秒内硬重试,正是把墙撞得更厚的方式。你的重试风暴就是 529 想阻止的东西。
- 尊重
retry-after头。没这个头就加 2--8 秒抖动,非关键路径立即降级到 Haiku。 - 当你自己的重试策略让情况变糟时,去看第三方信号(社区状态面板、跨区域延迟探针、用户上报),不要一上来就升级到团队群里。
529 和 429 不是一回事
我见过的大部分 Claude 客户端封装,只对 429 做了重试逻辑,到此为止。对你的 API key 配额而言这没问题。但 Claude 还会返回:
json
{
"type": "error",
"error": {
"type": "overloaded_error",
"message": "Overloaded"
}
}HTTP 状态码是 529。
- 429 = 你 发太多了
- 529 = 模型容量池 太小了
同一个请求,下一秒重放,得到的还是同一个响应。两种失败模式需要的重试策略完全不同。
先看响应头
碰到 529 / 429,第一件事不是改代码,是看响应头里有没有这几个:
yaml
anthropic-ratelimit-requests-limit: 4000
anthropic-ratelimit-requests-remaining: 3987
anthropic-ratelimit-requests-reset: 2025-11-03T12:34:56Z
anthropic-ratelimit-tokens-limit: 400000
anthropic-ratelimit-tokens-remaining: 398420
anthropic-ratelimit-tokens-reset: 2025-11-03T12:34:00Z
retry-after: 12判断逻辑:
requests-remaining/tokens-remaining还够 → 是服务端容量墙,不是你的 key 问题,不要改你的 gateway 配置retry-after有值 → 严格按值等待,最常见错误是客户端库忽略这个头 500ms 后硬重试
一个真正尊重 529 的重试策略
TypeScript,不依赖 SDK,生产用的是这个:
ts
type RetryInput = { attempt: number; retryAfterSec?: number };
function backoff({ attempt, retryAfterSec }: RetryInput): number {
if (retryAfterSec) return retryAfterSec * 1000;
// 1s, 2s, 4s, 8s, 16s --- 叠加 50% jitter
const base = Math.min(16_000, 1_000 * 2 ** attempt);
return Math.floor(base * (0.5 + Math.random() * 0.5));
}
async function callClaude(req: ClaudeRequest, maxAttempts = 5) {
for (let attempt = 0; attempt < maxAttempts; attempt++) {
const res = await fetch("https://api.anthropic.com/v1/messages", {
method: "POST",
headers: {
"x-api-key": process.env.ANTHROPIC_API_KEY!,
"anthropic-version": "2023-06-01",
"content-type": "application/json",
},
body: JSON.stringify(req),
});
if (res.ok) return res.json();
if (res.status === 529 || res.status === 429) {
const retryAfter = Number(res.headers.get("retry-after")) || undefined;
if (attempt === maxAttempts - 1) throw new Error(`claude ${res.status} after ${maxAttempts}`);
await new Promise(r => setTimeout(r, backoff({ attempt, retryAfterSec: retryAfter })));
continue;
}
throw new Error(`claude ${res.status}: ${await res.text()}`);
}
throw new Error("unreachable");
}两个关键点:
- 抖动(jitter)必须加。十个 worker 用确定性的退避时间,会在队列刚开一条缝的那一瞬间集体冲进去,把墙再撞一次。随机抖动把负载摊开。
- 最大退避封顶。别让第 7 次尝试 sleep 128 秒,那不叫重试,叫把用户请求吊死。16 秒还不行,就走 fallback,不是继续等。
模型降级作为一等公民
不是需要深度推理的路径,我第二次 529 就立刻降到 Haiku:
ts
async function callWithFallback(req: ClaudeRequest) {
try {
return await callClaude(req, 2); // 主模型快速失败
} catch {
const downgraded = { ...req, model: "claude-haiku-4-5-20251001" };
return callClaude(downgraded, 3);
}
}Haiku 是独立的容量池。Opus / Sonnet 打满的时候,Haiku 往往正常。这是质量换可用性的交换,在短时容量波动面前几乎永远是对的选择。
不要完全相信你自己的重试
真正的坑:一旦你有了重试策略,529 就从你的监控里消失了。p99 悄悄爬升,latency budget 悄悄被吃掉,面板全绿,用户却在骂你。
我依赖两个信号来看见这种"隐性 529 滴漏":
- 按模型拆开的错误计数器 :
anthropic_http_5xx_total{model="opus",code="529"}必须作为独立指标,不要合并到api_errors_total。529 要像账单一样显眼。 - 跨区域延迟探针 :判断自己代码有 bug 之前,先确认 Claude 是不是 全球 都在慢,而不仅是你这个区域。
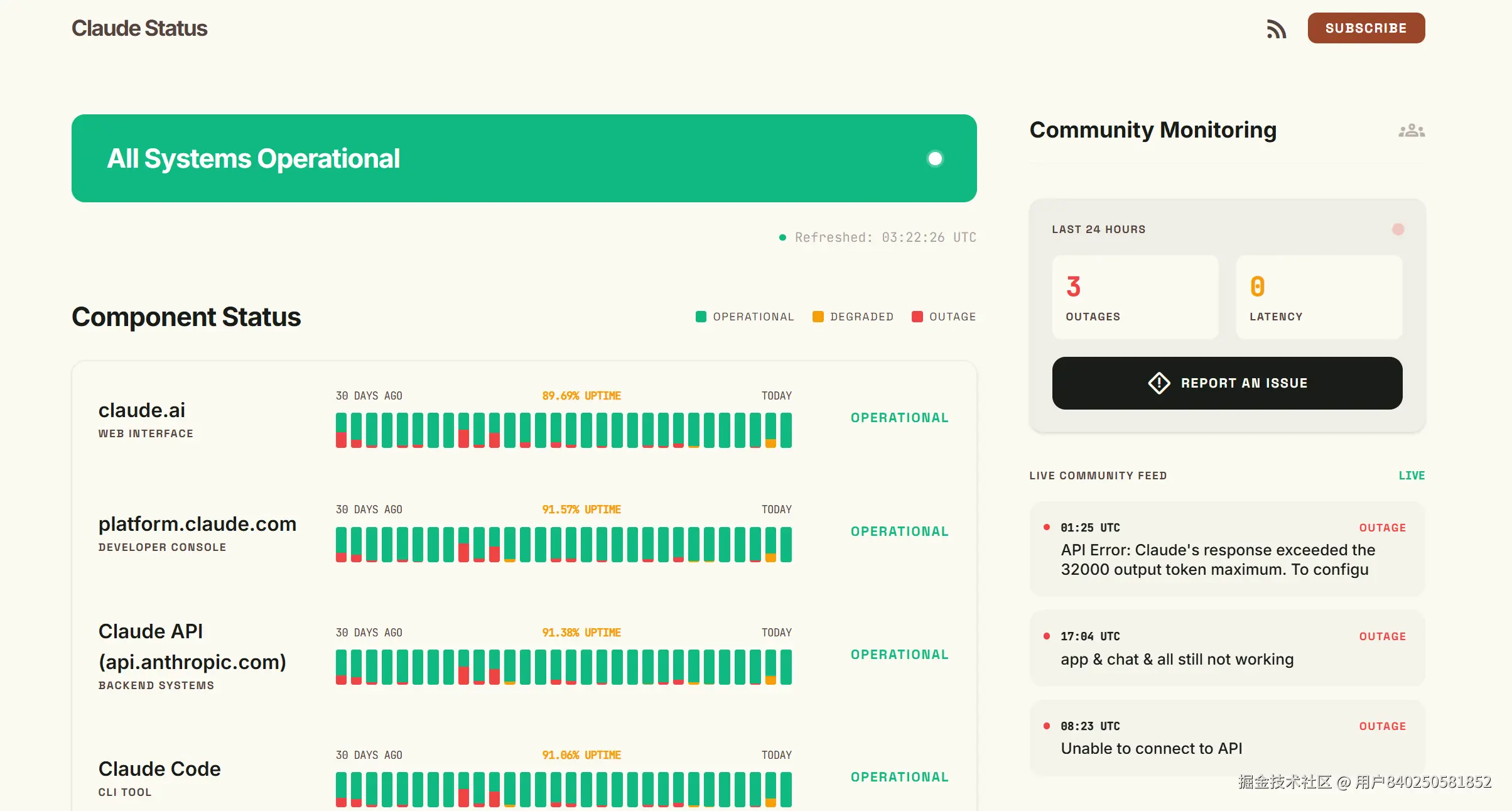
第二点我自己用的是一个社区面板 ------ claudestatus.com,非官方,与 Anthropic 无任何从属 。某次凌晨值班我在 Reddit 翻到的,后来一直开着用:它通过 Anthropic Statuspage 公共 API 抓状态,同时从 17 个国家跑 HTTP 延迟探针,再叠加社区上报。生产告警响起来时,我会先看一眼上面的 30 天历史曲线 确认是不是全局事件,十有八九是一波区域或模型级容量波动,等几分钟自己过,不用叫醒同事。
下一次 529 的 checklist
告警响起时,按这个顺序:
- 看响应头 ------
requests-remaining是不是 0?不是 0 那就是容量墙,改 gateway 没用 - 看
retry-after------ 有就严格用,别自作聪明 - 看
tokens-remaining------ 长 prompt 会先打爆 token 桶而不是请求桶 - 看外部信号 ------ 只是你,还是你的区域,还是全球?社区面板 10 秒内回答
- 降级 / fallback ------ 切 Haiku、走缓存、告诉用户稍等一分钟
- 最后 才去怀疑自己的代码
没什么高深的,我踩的最大坑就是把 529 当 429,抱着一堵墙硬重试。
上面提到的面板:claudestatus.com,社区维护,非官方,与 Anthropic 无任何从属