输入一个主题,从文案到配音到配图到合成,全自动出片。Pixelle-Video 是一个开源的 AI 短视频全自动生成引擎,GitHub 7.3k Stars,支持竖屏、横屏、数字人口播、图生视频、动作迁移等多种模式。
一、项目概述
我在GitHub上发现了一个很有意思的开源项目------Pixelle-Video。 它是一个开源的 AI 全自动短视频生成引擎,GitHub 已获得 7.3k Stars。它实现了从主题输入到视频输出的全流程自动化,支持多种生成模式和自定义配置,为内容创作者和开发者提供了强大的视频生产解决方案。
项目地址:https://github.com/AIDC-AI/Pixelle-Video
开源协议:Apache-2.0
技术栈:Python + ComfyUI + Streamlit
只需输入一个 主题,Pixelle-Video 就能自动完成:
- ✍️ 撰写视频文案
- 🎨 生成 AI 配图/视频
- 🗣️ 合成语音解说
- 🎵 添加背景音乐
- 🎬 一键合成视频
让视频创作成为一句话的事!效果十分不错,我们只需要接入自己模型的API,就可以很好的使用这个项目进行创作视频。
下面我将按照技术架构、第三方 API 接入、官方效果展示来展示这个开源项目效果。
二、技术架构
整个视频生成流程采用模块化设计,每个环节可独立替换模型和引擎:
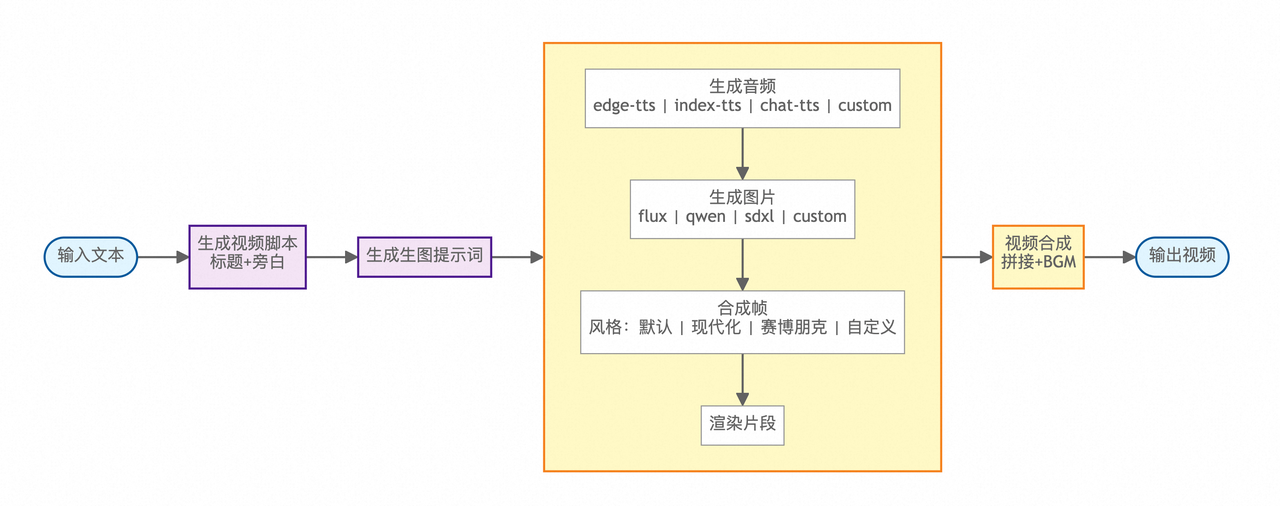
底层基于 ComfyUI 构建,模块可独立替换:
-
文案生成( LLM ):支持 GPT、通义千问、DeepSeek、Ollama 等,OpenAI 兼容格式
-
图片生成:本地 ComfyUI 或 RunningHub 云端调用,支持 FLUX 等模型
-
视频生成:支持 WAN 2.1 等 AI 视频模型(通过 ComfyUI 工作流)
-
语音合成 ( TTS ):Edge-TTS(免费)、Index-TTS 等,支持音色克隆
三、API 接入
Pixelle-Video 的 LLM 配置支持 OpenAI 兼容格式的 API,可以直接使用魔芋的 API 中转服务来驱动文案生成。以下是各模块的接入方式:
随着现在越来越多不正规的第三方API平台的跑路,封禁,选择一个安全稳定,价格合适很重要,
通过对比价格,稳定性,速度,三方面后,我决定选择的第三方魔芋api平台来获取API key。
大家可以参考我选择的第三方魔芋api平台来获取API key。
点击链接前往api平台注册👉https://www.moyu.info/register?aff=g2d7
1、使用手机号码进行账号注册
2、注册成功后进入【令牌管理】
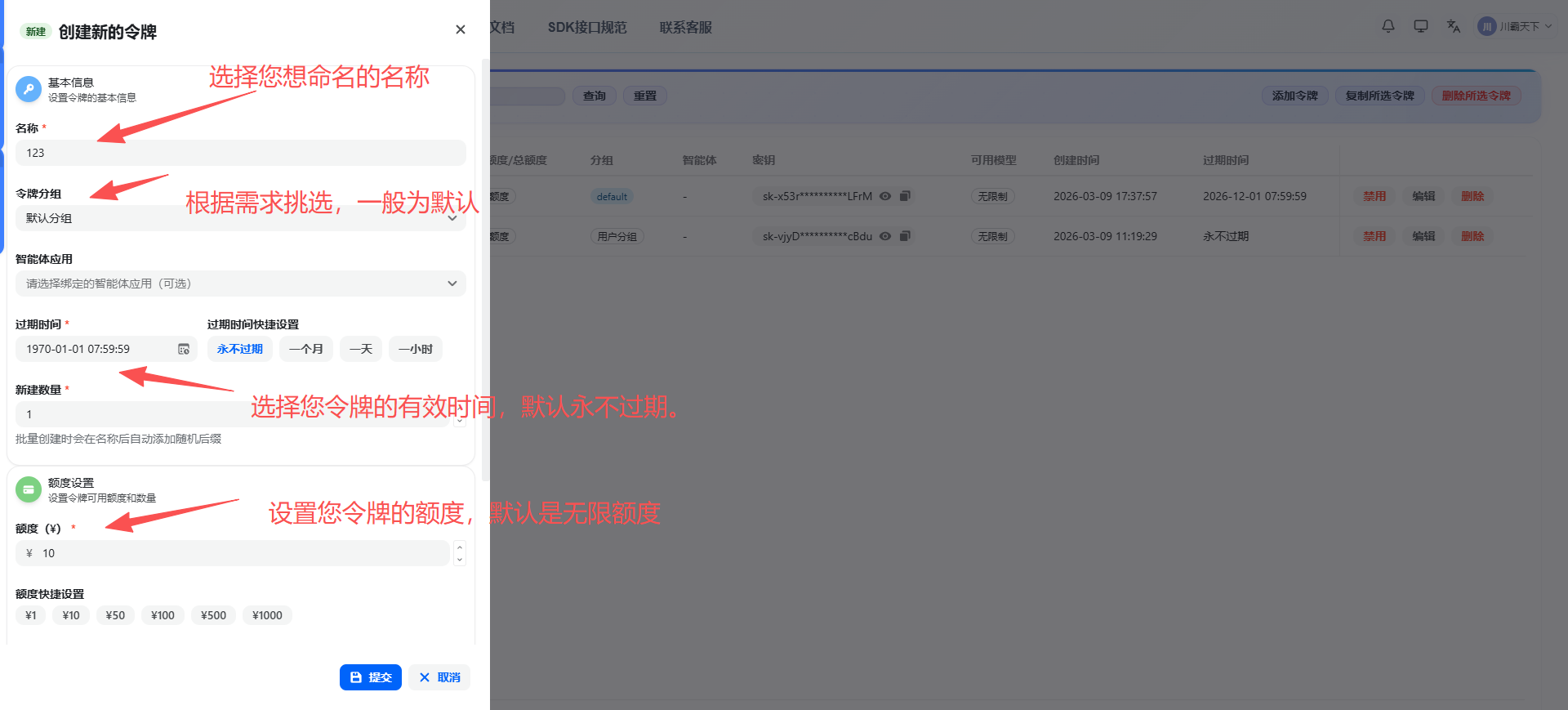
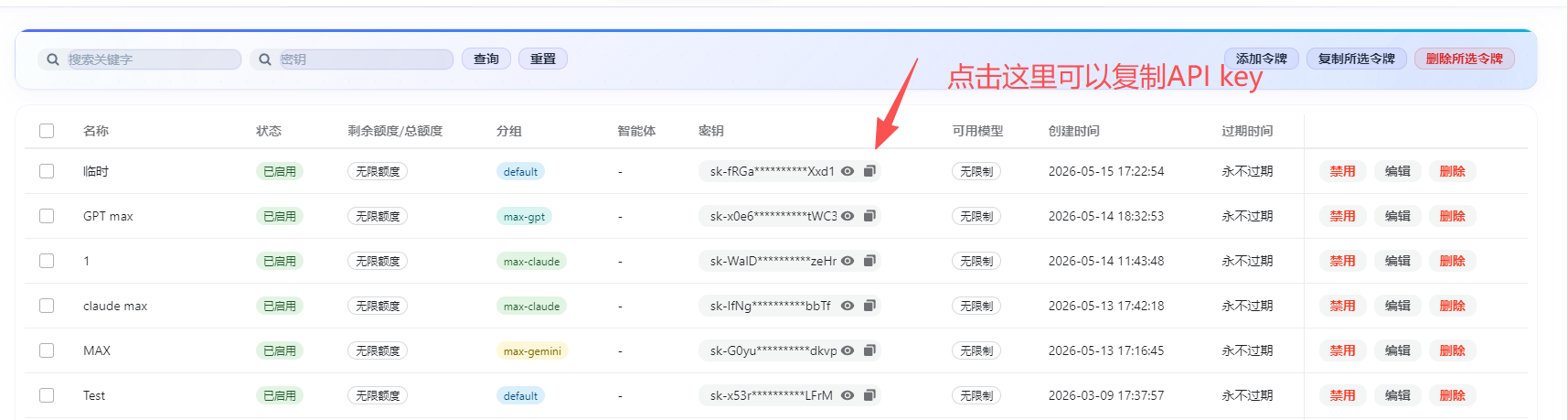
3、模型广场上复制要使用的模型ID
(模型广场没有完全显示的可以添加魔芋客服进行开白权限)
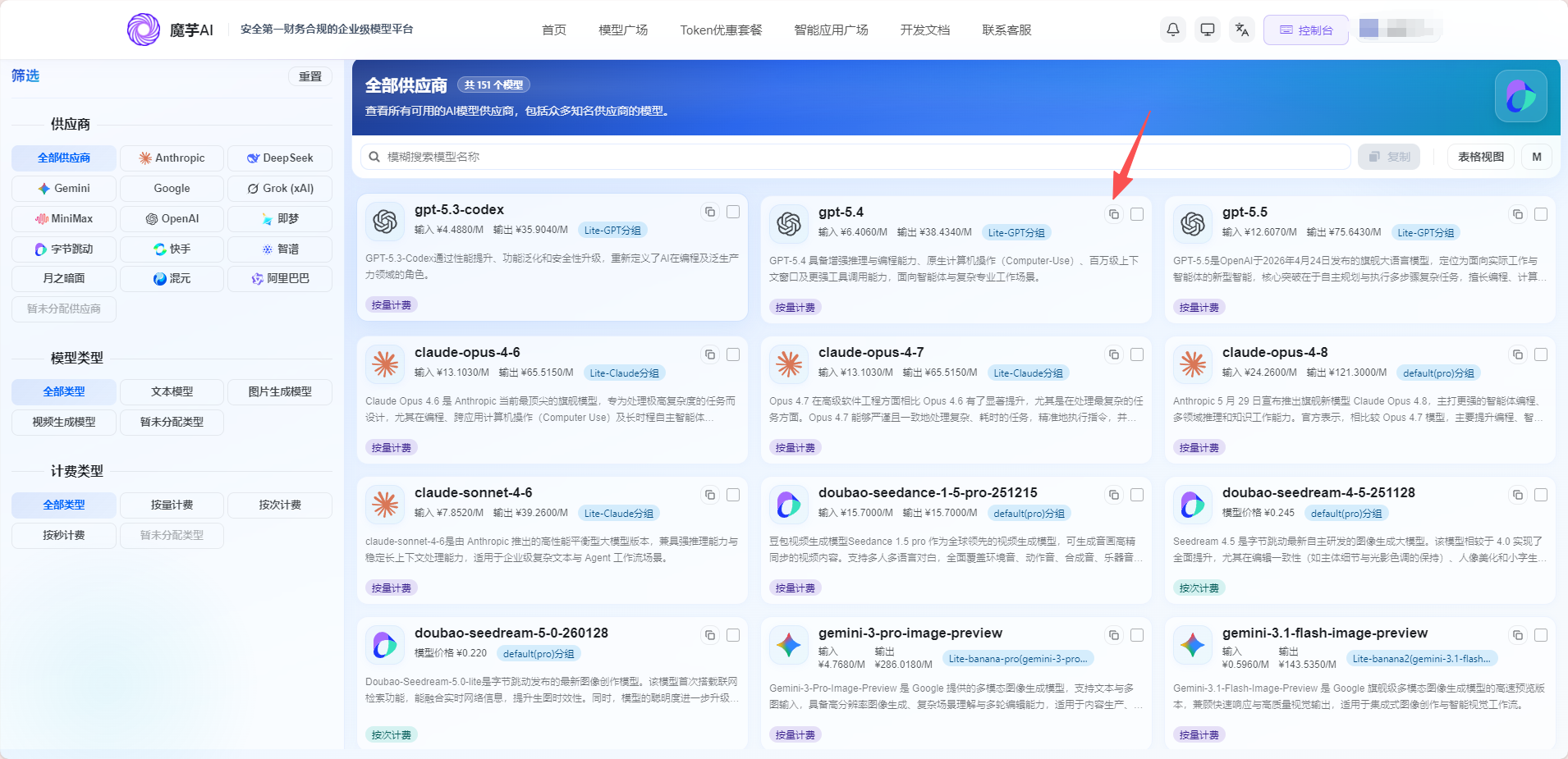

获取到信息后可以开始模型接入Pixelle-Video
文本模型接入(推荐)
这是最简单也最直接的接入方式。Pixelle-Video 的文案生成、脚本创作都依赖 LLM,魔芋提供的高质量文本模型完全覆盖这个需求。
操作步骤:
-
根据前面步骤注册魔芋AI获取到体验额度
-
创建 API 令牌(API Key)
-
打开 Pixelle-Video 的「⚙️ 系统配置」面板
-
在「LLM 配置」中填写:
-
API Key:填入魔芋的 API Key
-
Base URL:填入魔芋的 API 地址
-
Model:填写模型名称
-
推荐模型搭配:
| 用途 | 推荐模型 | 说明 |
|---|---|---|
| 文案生成 | gpt-5.5 | 中文文案质量高,响应快 |
| 深度脚本 | claude-sonnet-4.6 | 长文本逻辑强,适合有深度的内容 |
| 高性价比 | deepseek-v4 | 成本低,中文能力优秀 |
| 多语言 | gemini-3.1-pro | 多语言支持好,适合海外内容 |
配置示例:
API Key: sk-xxxxxxxxxxxxxxxx
Base URL: https://www.moyu.info/v1
Model: gpt-5.5💡 魔芋的 API 完全兼容 OpenAI 格式,Pixelle-Video 的预设模型中选"手动配置",填入魔芋的信息即可。无需修改任何代码。
图片生成接入
Pixelle-Video 的图片生成依赖 ComfyUI 工作流,不走标准的 OpenAI 图片 API 格式。接入方式有两种:
方式一:通过 RunningHub 云端(推荐小白用户)
-
在「图像配置」中选择 RunningHub
-
填入 RunningHub API Key
-
RunningHub 云端运行 ComfyUI 工作流,不需要本地 GPU
方式二:本地部署 ComfyUI
-
本地安装 ComfyUI(需要 NVIDIA GPU)
-
在「图像配置」中填写本地 ComfyUI 地址(默认 http://127.0.0.1:8188)
-
可以自由替换生图模型为 FLUX、SD3 等
视频生成接入
视频生成同样基于 ComfyUI 工作流,接入方式与图片生成一致:
-
通过 RunningHub 云端调用(推荐,支持 WAN 2.1 等视频模型)
-
或本地部署 ComfyUI(需要大显存,建议 48G 以上)
语音合成接入
TTS 是独立的模块,不依赖魔芋 API:
-
Edge-TTS:免费,内置支持,开箱即用,多语种多音色
-
Index-TTS:支持音色克隆,上传一段参考音频即可克隆音色
-
ChatTTS:更自然的语音风格
四、官方界面与工作流
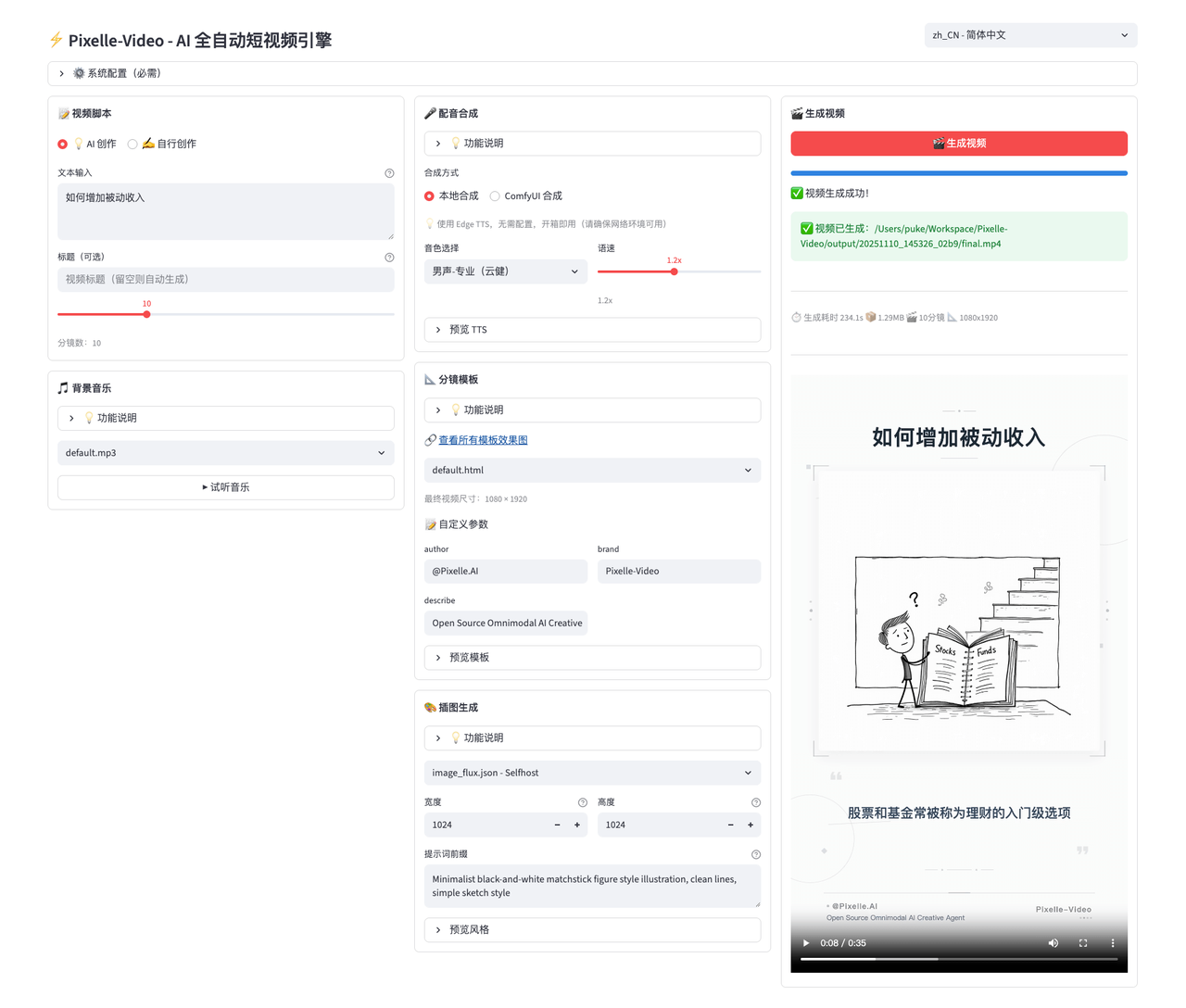
核心能力
全链路自动出片:输入主题后,AI 自动完成脚本撰写、配图/视频生成、语音合成、背景音乐匹配、最终视频合成。支持竖屏(9:16)和横屏(16:9),多种视觉模板可选。
数字人口播:支持生成多语言数字人口播视频,适合做口播类内容。
图生视频:上传一张图片,AI 自动生成动态视频内容。
动作迁移:上传参考视频和图片,AI 学习动作并迁移到新图上。
自定义素材:可以上传自己的照片和视频,AI 智能分析后生成配套脚本和视频。