传输层:
①**++UDP特点(TCP仅对比):++**
1. 无连接
不用先建立连接,发就完事。
- TCP:像打电话,要先拨号、等接通,才能说话。
- UDP:像寄平信,直接写地址扔邮筒,不需要先建立连接。
2. 不可靠传输
不保证一定送到,不保证不乱序,丢了也不重发。
- TCP:丢包会重发、乱序会重排、送达有确认 → 可靠。
- UDP:发出去就不管了,丢了就丢了,乱了就乱了,不重传、不确认、不保证顺序。
3. 面向数据包
一包是一包,边界清晰,不拆不粘。
- TCP:像水流,数据是连续的,没有天然边界。
- UDP:你发多大一包,对方就收到多大一包,一包就是一个完整消息,不会粘包、不会拆包。
4. 全双工
两边可以同时发,不用等对方说完。
- 双方都能随时发送数据,
- 不需要 "你发完我才能发"。
- 打电话、微信语音都是全双工。
②++UDP协议端格式++

(1)其中源端口号,目的端口号,UDP长度,UDP检验和均为16位 (即每个字段在 UDP 报头里,都占 16 个二进制位(也就是 2 个字节)的存储空间)
(2)UDP 报文的总长度上限约为 64KB
如果想要突破64KB长度上限有两个方案
1)应用层全部重写,工作量大,而且已经使用的如果想改也很难,不选
2)使用TCP协议,没有数据包长度限制
(3)校验和:
校验和 = 一个用来检查数据有没有传错的 "验证码"
工作原理:
-
发送方:把整个 UDP 包(头部 + 数据)算一个简单的数学结果 ,这个结果就是校验和,一起发过去。
-
接收方:收到后,用同样方法再算一遍。
- 算出来一样 → 数据没问题
- 算出来不一样 → 数据传坏了/被篡改了,直接丢掉
两个原始数据相同,使用相同的校验和算法,得到的校验和也相同
两个校验和相同,原始数据不一定相同,因为不同数据可能产生相同校验和,也有可能遇到多个比特翻转相抵消得到相同校验和(小概率)
③++TCP协议特点:++
1. 有连接
TCP 在传输数据前,必须先建立连接 (三次握手),传输结束后还要断开连接(四次挥手)。就像打电话:先拨号接通,再说话,说完挂电话。
2. 可靠传输
- 数据不会丢,丢了会重发
- 数据不会乱序,到达后会重新排序
- 有确认机制,收到数据会回复 ACK保证数据完整、正确、按顺序到达。
3. 面向字节流
- 数据像水流一样连续发送,没有明显边界
- 发送方写 100 字节,接收方可能分两次收到
- 不保留 "一包一包" 的边界,只保证字节顺序正确
对比:UDP 是面向数据包,一包就是一包。
4. 有接收缓冲区,也有发送缓冲区
- 发送缓冲区:暂存要发的数据,等网络空闲再发
- 接收缓冲区:暂存收到的数据,等应用程序来读取缓冲区让收发双方不用同步等对方,提高效率。
5. 大小不限
TCP 是字节流 ,没有单个数据包 64KB 的限制。可以传输任意大小的数据(文件、视频等),系统会自动拆包、组包,对应用透明。
④++TCP协议段格式++
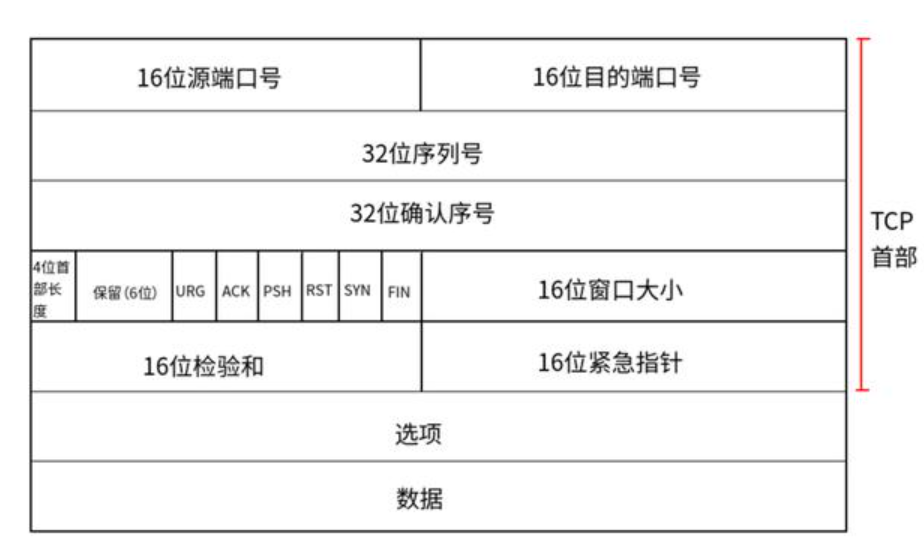
(1)TCP首部就是TCP报头
(2)源 / 目的端口号:源端口号 表示数据是从哪个进程来,目的端口号到哪个进程去。
(3)32 位序号:标识本报文段数据部分的第一个字节的编号 。解决网络传输中数据包丢失、乱序的问题,保证数据能按发送顺序重组
(4)32 位确认号:表示接收端期望收到的下一个字节的编号 ,是对收到数据的正向确认。 告知发送端 "我已经成功收到了你发送的所有编号小于该确认号的数据",让发送端可以放心地丢弃已确认的数据。
(5)4 位 TCP 报头(首部)长度:表示该 TCP 头部有多少个 32 位 bit(有多少个 4 字节,1字节=8bit,所以一个单位是4字节);
所以 TCP 头部最大长度是 15*4=60 字节
(4 位二进制能表示的最大值是是 15 (二进制是 1111)所以最大表示15个)。
作用:(告诉接收方,TCP 头部到底有多长,从哪里开始才是真正的数据。)
(5)6 位标志位:
- URG: 紧急指针是否有效
- ACK: 确认号是否有效
- PSH: 提示接收端应用程序立刻从 TCP 缓冲区把数据读走
- RST: 对方要求重新建立连接;我们把携带 RST 标识的称为复位报文段
- SYN: 请求建立连接;我们把携带 SYN 标识的称为同步报文段
- FIN: 通知对方,本端要关闭了,我们称携带 FIN 标识的为结束报文段
用来表示我这个包是干嘛的,你该怎么处理。
(6)16 位窗口大小(后面讲):是 TCP 用来做流量控制 的字段,代表接收方当前还能接收的数据量
(7)16 位校验和:"数字指纹",用来保证数据在传输过程中没有被篡改、没有出错
(8)16 位紧急指针:标识哪部分数据是紧急数据:从正文数据部分开头算起,到哪个位置为止是紧急数据,接收端要优先处理这一段,不用排队等缓冲区
(9)选项(可忽略): 40 字节头部选项,放在固定 20 字节头部之后,用来实现一些额外功能
⑤++TCP的核心机制:++
(1)确认应答:就TCP 实现可靠传输最核心的机制
- 发出去的包,必须等对方回复 "收到了",才敢认为发送成功
- 没收到回复,就重发
- 收到确认,才继续发下一批
可能会出现"先发后至"(即发送顺序与接收顺序不一致)这个网络传输中非常常见且棘手的问题
在 TCP 协议中,这个问题主要通过序列号(Sequence Number)和确认应答(ACK) 机制协同来完美解决。
核心逻辑就一句话:给每一个字节编号,按编号排队,乱了就拼好。
具体解决步骤如下:
1. 给数据 "上牌":序列号机制
TCP 把每一个字节的数据都编上唯一的号码(序列号)。
- 发送时:即使数据分成了 10 个包发送,每个包都带有自己的起始序号。
- 接收时 :不管这 10 个包是按什么顺序到达的,接收方都会根据序号,把它们按正确的顺序排队排好。
120 / 310 / 无数据 / 211 一共 4 个包,我按初始序号 = 0来算:
第 1 包:数据长度 120
- 序号 Seq:0
- 数据字节:0 ~ 119
- 对方确认号 ACK:120
第 2 包:数据长度 310
- 序号 Seq:120
- 数据字节:120 ~ 429
- 对方确认号 ACK:430
第 3 包:无数据(纯 ACK 包)
- 序号 Seq:430
- 无数据,不占用实际字节,但序号要 +1
- 对方确认号 ACK:431
第 4 包:数据长度 211
- 序号 Seq:431
- 数据字节:431 ~ 641
- 对方确认号 ACK:642
++下一个包的序号 = 上一个包的确认号++
2. 确认 "整段" 收到:累积确认
TCP 的确认不是单发一个回一个,而是累积确认。
- 原理 :接收端发送一个 ACK(确认号),它代表的意思是:"我已经成功收到了所有编号小于该确认号的数据,请以后从这个编号开始发新数据。"
- 效果:如果中间丢了一个包,后面的包虽然先到了,但确认号不会推进,直到丢失的包重传并收到,确认号才会继续前进。
3. 超时重传:兜底方案
如果发送方发出去数据后,迟迟收不到对方的 ACK 确认,它就会认为数据包丢了(或者是 ACK 丢了)。
- 机制 :发送方启动超时计时器,时间到了没收到回复,就把那个包重新发一遍。
(2)超时重传:我发出去了,规定时间内没收到你的回信,肯定是出事了,我就再发一次
-
发送并计时 当发送方把一个数据包发出去后,会立刻启动一个超时计时器(Timeout Timer)。
- 类比:你发微信给朋友,然后开始看表,约定 "如果 1 分钟没回复,我就再发一条"。
-
等待确认 发送方会等待接收方返回的确认报文(ACK)。
- 类比:你等朋友的微信回复。
-
两种结果
- 收到 ACK: 说明数据安全到达,计时器关闭,继续发送下一个数据。
- 没收到 ACK(超时): 计时器时间到了。发送方判定数据或者确认包丢失了,于是把同一个数据包重新发送一遍 。这就是超时重传。
- 类比:1 分钟到了,朋友没回,你就再发一条微信,问 "你看到了吗?"
因此接收方 会收到很多重复数据。那么 TCP 协议需要能够识别出那些包是重复的包,并且把重复的丢弃掉。这时候我们可以利用前面提到的序列号,就可以很容易做到去重的效果。
超时的时间如何确定?
1. 核心依据:RTT(往返时间)
- RTT:一个包发出去 → 收到 ACK 回来的总时间
- RTO:基于 RTT 计算出来的超时重传时间
2. 怎么算?(简化版)
- 先采样多个 RTT,算出平均 RTT(SRTT)
- 再算出波动值(RTT 偏差)
- 最终:波动给波动留足够余量,避免网络稍微一卡就乱重传。
一句话通俗版
超时时间 = 数据包来回一趟的平均时间 + 一点安全余量,网络越差等得越久,而且一直在自动调整。
(3)连接管理
连接管理就是管理建立连接和断开连接
建立连接:也就是三次握手
- 客户端发送 SYN → 第一次握手
- 服务端回复 ACK +SYN→ 第二次握手 (这里其实是回复ACK和发送SYN合并了)
- 客户端再回复 ACK → 第三次握手
SYN 是 TCP 协议里的一个标志位 ,全称是 Synchronize ,意思是同步。
它的作用只有一个:在建立 TCP 连接(三次握手)时,用来发起连接请求,并同步双方的序列号。
为什么双方都要发 SYN?
因为 TCP 连接是全双工通信 ------ 两边都能同时发数据,所以两个方向都要单独 "初始化" 一次。
总结:用来让对方存储自己的关键信息
客户端发 SYN告诉服务器:"我要给你发数据了,先同步一下我的起始序号,你记好。"
服务器也发 SYN告诉客户端:"我也要给你发数据,我也有我的起始序号,你也记好。"
注:一定是客户端先主动发起 SYN ,服务端永远是被动等待、后发 SYN。
TCP状态-CLOSED:"连接已关闭" 的状态,表示当前没有任何连接,也不占用任何资源。
TCP状态-LISTEN:服务器已经开启端口,正在监听,等待客户端来连接。
TCP状态-SYN_SENT:
- 只出现在客户端
- 客户端已经发出 SYN 连接请求
- 正在等待服务器回复
- 状态含义:我发了连接请求,等你答应
TCP状态-SYN_RCVD:
- 只出现在服务端
- 服务器已经收到了客户端的 SYN
- 并且已经回复了 SYN+ACK
- 正在等客户端最后一次 ACK
- 状态含义:收到你的连接请求,我也回应了,就等你最后确认
TCP状态-ESTABLISHED:TCP 连接里的已建立状态
- 三次握手全部完成
- 客户端和服务器正式连通
- 双方可以自由、可靠地收发数据
TCP状态-TIME_WAIT: 主动关闭连接后,为保证可靠断开、避免数据包混乱而设置的等待收尾状态。
- 确保对方收到最后的 ACK,防止丢包导致连接异常
- 等待足够长的时间,让网络中残留的旧数据包过期消失,避免端口被重复使用时出错
TIME_WAIT 会持续 **2MSL(通常 1~2 分钟),之后才会真正释放连接回到 CLOSED。
TCP状态-CLOSE_WAIT:是 TCP 被动关闭方的等待状态。
- 对方已经发了关闭请求(FIN)
- 我方也回复了 ACK
- 但我方自己还没关闭连接,还在等程序处理完剩余数据、主动调用 close
断开连接:四次挥手
1.主动关闭方发 FIN 我数据发完了,要关我这边的发送通道。
2.被动关闭方回 ACK 收到,我知道你要关了。→ 被动方进入 CLOSE_WAIT。
3.被动关闭方也发 FIN我这边数据也发完了,我也要关通道。
4.主动关闭方回 ACK收到,我确认关闭。
2,3步能不能合并?
有时候可以,有时候不行,绝大多数时候不能
不能:ack和fin这两次交互的时机是不同的。ACK 是立即回的,但 FIN 要等程序处理完才能发,两者不能随便绑在一起
能:被动关闭方也正好没有数据要发了
(4)滑动窗口
刚刚说到每接收到一个数据消息,就要返回一个ACK,一发一收,所以会有效率低的问题,那么如果日次发送多条数据,这样很多个等待返回的ACK的时间就会重叠在一起,效率就提高了
那么窗口就是去控制允许发送字节量的范围,窗口大小 = 能连续发多少数据(一口气发送)
- 把整个窗口大小的数据一次性发完
- 然后就停下来等,不能再发新的
- 收到第一个 ACK ,窗口就往右滑一段
- 滑出来的新位置,就是下一组可以发的数据
举个例子(窗口大小 = 4)
数据:1 2 3 4 5 6 7 8
- 一次性发:1、2、3、4
- 只收到 ACK=2(确认收到 1、2)
- 窗口立刻向右滑动
- 新窗口变成:3、4、5、6
- 马上就能发 5、6
++3、4 还没被 ACK,但不影响发新的!++
那么如果出现了丢包,如何进行重传?这里分两种情况讨论。
1. 数据包已经抵达,ACK被丢了
比如:
- 发送方发了:1、2、3、4
- 接收方全都收到了,依次回 ACK:2、3、4
- 结果 ACK2、ACK3 在路上丢了,只有 ACK4 到达发送方
发送方收到 ACK4→ 就知道:1~4 全部收到了
这就是累计确认:
确认到 4,就代表 4 及以前所有包都收到了。
所以:前面的 ACK 丢了完全没关系,只要最后一个 ACK 到了就行。
真的完全不用处理吗?
只有一种极端情况:
- 接收方收到了所有包
- 但所有 ACK 全都丢光了
- 发送方迟迟收不到任何 ACK
这时发送方会触发超时重传,把未确认的包再发一遍。但接收方发现是重复包,会:
- 收下(不交给应用层)
- 再回一个 ACK
- 发送方收到后就正常滑动窗口,结束重传
2. 数据包被丢了。
1). 靠超时重传(最基础)
- 发送方发完窗口内的数据后,会启动超时计时器
- 如果一段时间内,没有收到任何对应的 ACK
- 就认为数据包丢了
- 发送方会重新发送这一批未被确认的数据
2.) 靠快速重传(更高效,TCP 优化)
- 接收方没收到期望的包,但收到了后面的包
- 就会重复发送同一个 ACK(重复确认)
- 发送方收到 3 次重复 ACK
- 不等超时,立刻重传丢失的那个包
简单记:数据包丢了 → 要么超时重传,要么收到三次重复 ACK 快速重传
(5)流量控制
流量控制就是:让接收方控制发送方的发送速度,防止自己缓冲区溢出、处理不过来
它通过滑动窗口实现:
- 接收方在 TCP 报文头的16 位窗口字段中,返回当前可用缓冲区大小
- 发送方根据这个窗口大小发送数据,不超过接收方处理能力
- 窗口大小随接收方缓冲区占用情况自动变化,从而实现速率控制
1. 它到底在控制什么?
控制发送方发数据的速度,让它:
- 不要发太快
- 不要发太多
- 刚好匹配接收方的处理能力
2. 靠什么实现?
滑动窗口 + 接收窗口(rwnd)
- 接收方在每个 ACK 里,告诉发送方:我还能接收多少字节(窗口大小)
- 发送方严格按照这个窗口大小发送
- 接收方处理完数据,就把窗口变大;处理不过来,就把窗口变小甚至设为 0
3. 最终效果
- 接收方从容收数据
- 不丢包、不溢出
- 网络更稳定
举例:
场景:A = 发送方(说话的人)B = 接收方(听的人)窗口大小 = B 一次能记住多少句话
1. 刚开始
B 告诉 A:我一次能记 4 句,你最多发 4 句,别多了。
→ 窗口大小 = 4
A 就连发:1、2、3、4
2. B 收到了 1、2
B 处理完,腾出空间,告诉 A:我已经收到 1、2 了,现在窗口还剩 4,你可以继续发。
窗口向右滑动,A 继续发:5、6
现在发出去的是:3、4、5、6
3. B 突然很忙(比如打游戏去了)
B 不读数据了,缓冲区满了。B 告诉 A:我满了,窗口大小 = 0,别发了!
→ A 立刻停止发送,开始等待。
4. B 忙完了
B 读了数据,腾出缓冲区,告诉 A:好了,窗口恢复成 4,你继续发。
A 才继续发 7、8、9、10......
数据从发送方 → 网络 → 先到接收方的缓冲区,再到你的应用程序。
不是说同时发多个数据吗?为什么能先到1,2:
- 不是发 1 等 ACK→再发 2
- 而是一口气连续发:1 → 2 → 3 → 4
- 中间几乎没有停顿,速度非常快
它们在时间上确实有先后 ,但间隔极小,整体是一批发完。
(6)拥塞控制
拥塞控制就是防止发送方发得太快,把网络本身给堵死(在刚开始阶段就发送⼤量的数据),是针对网络状况的控制。
和流量控制的区别(必须分清)
- 流量控制:管接收方接收方说 "我收不过来" → 慢点发
- 拥塞控制 :管网络网络说 "我太堵了" → 慢点发
TCP 拥塞控制完整过程(4 个阶段)
1. 慢启动(刚连接时)
- 刚开始不知道网络状况,发送速度慢慢增加
- 拥塞窗口 cwnd 从 1 开始,每收到一个 ACK,窗口就加倍
- 速度上升非常快(指数增长)
- 直到达到一个阈值(ssthresh),进入下一阶段
2. 拥塞避免(超过阈值后)
- 不再指数增长,改为线性增长
- 每经过一个往返时间,cwnd 只加 1
- 平稳试探网络,防止突然拥塞
3. 快速重传(发现丢包时)
- 发送方收到 3 个重复的 ACK
- 立刻判断:数据包丢了,网络拥堵
- 不等超时,直接重传丢失的包
4. 快速恢复(丢包后恢复)
- 把门限阈值 ssthresh 设为当前 cwnd 的一半
- 拥塞窗口 cwnd 也降到一半左右
- 然后重新进入拥塞避免,线性增长
- 不回到慢启动,效率更高
流量控制和拥塞控制:
发送方最终能发多少数据,取这两个窗口里更小的那个,两个同时生效、一起限制发送速度。
(7/8)延时应答/捎带应答 (捎带应答是延时应答的目标 / 结果)
- 接收方收到数据后,不马上回 ACK
- 等一小会儿(比如 200ms)
- 看看有没有数据要一起发给对方
- 有就一起发(把 ACK 绑在我要发给你的数据里,一起发过去,不要单独发一个 ACK 包),没有再单独发 ACK
目的:减少 ACK 包数量,减少网络小包。
(9)面向字节流
面向字节流:TCP 不关心你发的是几段数据,它只把所有数据当成一长串连续的字节,挨个发送、挨个接收。
- TCP 是面向字节流:数据像水流一样,没有边界、没有分段,连续不断。
- UDP 是面向报文:数据像包裹一样,一段是一段,有明确边界。
1. 底层架构:缓冲区是基石
创建 TCP socket 时,内核自动创建发送缓冲区和接收缓冲区。
解读:
- 这是 TCP 连接的五脏六腑。程序(应用层)不直接把数据扔到网络里,也不直接从网络里收数据。
- 发送缓冲区 :是你程序调用
write/send后,数据暂时存放的 "候车室"。 - 接收缓冲区 :是数据从网卡进来后,暂时存放的 "快递柜",等你调用
read/recv来取。
2. 发送侧:N 次写变一串流
调用 write 先入缓冲区;太长拆分发,太短攒够再发。
解读:
- 入队 :你程序里写
send("Hello"),数据只是拷贝到了内核的发送缓冲区,立刻返回给程序,它不会等发出去才回来。 - Nagle 算法(合并) :如果你连续 100 次
write一个字节,TCP 为了不发一堆芝麻大的包占带宽,它会把这些字节攒在一起,等到缓冲区满了,或者超时了,再一起打包发出去。 - 拆分 :如果你一次
write了 100MB,TCP 发现这个包太大,路由器可能传不动,它会自动把这一大串字节流切成多个 MSS(最大分段大小) 的小包,一个个发出去。
3. 接收侧:一串流变 N 次读
数据先到接收缓冲区,应用程序调用 read 拿数据。
解读:
- 数据从网卡过来,先填满你的接收缓冲区。
- 你调用
read(100)时,是从缓冲区里拷贝数据出来。 - 关键点 :缓冲区里的数据是一长串连续的字节,不管你原来是怎么 send 的,到了接收方都是一串流水。
4. 核心特性:读与写不需要匹配(最重要的考点)
由于缓冲区存在,TCP 的读和写不需要一一匹配。解读:这是 TCP 面向字节流最直观的表现,也是最容易写错的地方!
| 行为 | 发送方(写) | 接收方(读) |
|---|---|---|
| 写操作 | 一次 write 100 字节 || 100 次 write 1 字节 | (无影响) 数据都在缓冲区里排成一串 |
| 读操作 | 完全不管原来是怎么写的 一次 read 100 字节 || 100 次 read 1 字节 | 都能正确拿到 100 字节数据 边界消失了! |
边界消失:发送时的 "消息边界、分段边界",到了接收方全都没了、不存在了
发送方分两次发:
- 第一次发:
Hel - 第二次发:
lo
这两次发送,在你眼里是两段独立的数据 ,中间有明显的边界。
但到了 TCP 里:
- 先进发送缓冲区,拼成一串:
H e l l o - 再发给对方
- 对方接收缓冲区里,也是一整串连续字节
例子 :你发送:
send("Hel")接着send("lo")。对方接收:可以
read(3)拿到 "Hel",再read(2)拿到 "lo";也可以直接
read(5)直接拿到 "Hello"。双方完全不用协商 ,发送方分多少次写数据、每次写多少字节,和接收方分多少次读数据、每次读多少字节,完全没有关系,两边可以完全不一样。这就是 "面向字节流" 的自由。
5. 通信模式:全双工
既有发送缓冲区,也有接收缓冲区,即可读也可写。
解读:
- TCP 连接是双通道。
- 同一时刻,你既能往缓冲区里塞数据(发),也能从缓冲区里取数据(收),互不干扰。
- 这就像打电话,你可以边说话边听,不用按顺序等对方说完你才能说。
总结:TCP 基于内核的发送 / 接收缓冲区 ,将应用数据视为无结构字节流 。发送时自动合并或拆分数据,接收时按需提取,消除了读写次数的一一对应关系,实现了高效且灵活的全双工传输。
(10)粘包问题
粘包: 就是 TCP 因为「面向字节流、无消息边界」的特性,把发送方多次发送的多条业务消息,在接收方合并成了一整串字节流,导致接收方无法区分每条消息的起止边界的问题。
粘包问题中的"包",是指的应⽤层的数据包.
在传输层的角度,TCP是一个一个数据包传过来的,按序号排好在
但是在应用层,只能看见一连串字节数据,无法知道从哪个部分到哪个部分是一个完整的数据包。
那么如何解决? 明确两个包之间的边界 ( 加的边界是逻辑的边界,而不是每个包之间的边界**)**
最标准、最常用的方法就是:
先发长度,再发数据
比如:发送:长度(5) + Hello
网络可能拆成:
- 包 1:
5 He - 包 2:
llo
接收方怎么做?
- 先读 长度 5
- 知道接下来要收 5 个字节
- 收到
He不够,继续等 - 收到
llo凑齐 5 字节 - 拼成完整
Hello
1. GET 请求:根本没有请求体
- GET 只有 请求行 + 请求头
- 没有要传输的 "业务数据体"
它的边界只有一个:遇到空行(\r\n\r\n),请求就结束了。
所以 GET 不存在 "数据边界" 问题。
2. POST 请求:有请求体,靠两个规则定边界
POST 会发一大段数据(表单、JSON、文件等),HTTP 规定了两种明确边界的方式:
① Content-Length(最常用)
格式:
Content-Length: 1024意思:接下来有 1024 字节的请求体,读到够数就结束。
这就是你刚才理解的:先发长度,再读数据
② Transfer-Encoding: chunked(分块传输)
数据太长时不用先算总长度,分成一块块发:
3\r\n Hel\r\n 2\r\n lo\r\n 0\r\n \r\n格式不详细展开了
(10)异常情况
1)进程崩溃终止:跟主动退出没有区别,释放⽂件描述符,并进行四次挥手
2)主机(网络中的一台计算机)关机:关机也需要时间,如果这段时间能进行完四次挥手那和正常一样,如果无法进行完四次挥手,即另一方无法收到ACK,几次后也会主动释放连接
3)主机掉电(停电断电):
任意一方掉电,对端(活着的那一端)会认为连接仍在。
- 若活着的那一端有写入操作(即发送数据包):TCP 尝试发送数据,多次重传无响应后,发送 RST 重置报文,主动释放连接;
- 若没有写入操作:TCP 内置的保活定时器 会定期发送探测报文,若多次无响应,TCP 主动判定连接失效,释放连接。
4)网线断了:跟3)主机掉电同理
⑥++TCP和UDP对比++
TCP用于可靠传输,大部分场景下都用TCP
UDP用于高速传输和实时性要求高的通信领域,比如视频通话,直播等等
网络层:
⑦ip协议
协议头格式:
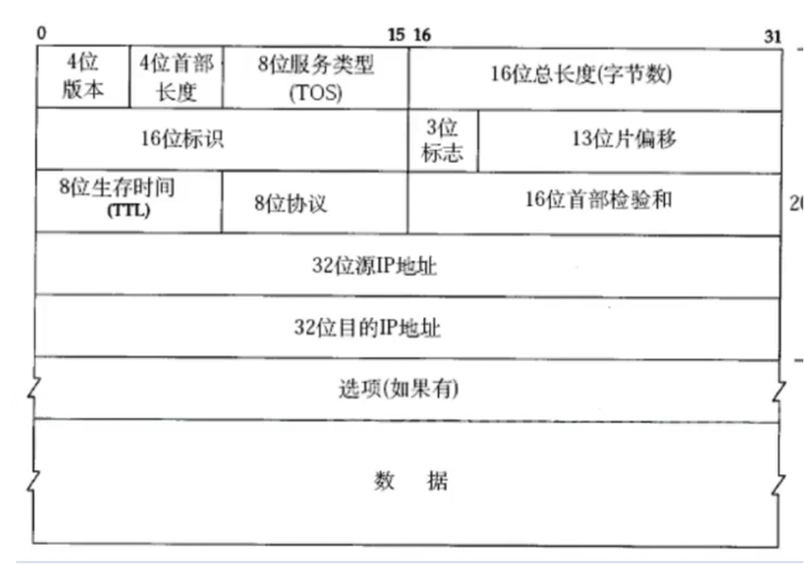
(1)4位版本号 : 指定 IP 协议的版本,对于 IPv4 来说,就是 4.
(2)4位头部长度:IP头部的长度是多少个32bit,也就是length * 4的字节数.4bit表示最大的数字是15,因此IP头部最大长度是60字节(只算 IP 头部,不包括后面的数据部分)
(3)8 位服务类型 :用来设置数据包的传输优先级与服务质量要求,告诉路由器如何选择转发策略。3 位优先权字段 (已经弃用),4 位 TOS 字段,和 1 位保留字段 (必须置为 0).4 位 TOS 分别表示:最小延时,最大吞吐量,最高可靠性,最小成本。这四者相互冲突,只能选择一个。对于 ssh/telnet 这样的应用程序,最小延时比较重要;对于 ftp 这样的程序,最大吞吐量比较重要
(4)16位总长度:IP数据报整体占多少个字节(整个 IP 数据报的总字节数 ,包含IP 头部 + 数据部分,单位是字节。)
(5)16 位标识 (id): 唯一的标识主机发送的报文。如果 IP 报文在数据链路层被分片了,那么每一个片里面的这个 id 都是相同的.
用来标识同一个原始 IP 数据报 的编号。作用:当一个 IP 包太大、需要分片 传输时,所有分片的标识 ID 都相同,方便目标主机收到后根据这个 ID 把分片重组成原来的完整数据包
(6)3 位标志字段: 主要用来控制 IP 数据包是否分片、以及标识是否为最后一个分片。
三位含义分别是:
- 第一位:保留位,暂未使用
- 第二位 :DF 位(不分片位)
- 置 1:禁止分片,数据包超 MTU 则直接丢弃
- 第三位 :MF 位(更多分片位)
- 置 1:表示后面还有分片
- 置 0:表示这是最后一个分片
(7)13 位分片偏移:用来表示当前分片在原始 IP 数据报中的位置。
- 单位是8 字节,实际偏移字节数 = 偏移值 × 8
- 作用:让接收方能按顺序把多个分片重组成完整数据包
- 所以除最后一个分片外,前面每个分片长度必须是8 的整数倍
(8)8位⽣存时间:设置数据包最多能经过多少个路由器,防止数据包在网络里无限转圈。
具体作用
- 每经过一个路由器,TTL 减 1
- 减到 0 还没到目的地,路由器就直接丢弃该数据包
- 同时会发送一个 ICMP 超时消息给发送方
常见初始值
- Windows:默认 128
- Linux / Unix:默认 64
- 某些路由设备:32
(9)8位协议:用来标识IP 数据报的数据部分,使用的是哪一种传输层协议,方便接收方收到后交给对应的上层协议处理。
常见对应值:
- 6 → TCP
- 17 → UDP
- 1 → ICMP(ping 用的就是它)
(10)16位头部校验和:仅针对 IP 头部计算的校验值 ,用来验证 IP 头部在传输过程中是否出错。
要点:
- 只校验 IP 头部,不校验后面的数据部分
- 发送端计算好值并填入该字段
- 接收端重新计算,结果不一致就直接丢弃该数据包
- 每经过一个路由器,TTL 会变,所以校验和也要重新计算
(11)32位源地址和32位⽬标地址:
- 32 位源 IP 地址 :发送数据包的发送方 IP 地址,标识数据包从哪台主机发出。
- 32 位目标 IP 地址 :接收数据包的接收方 IP 地址,标识数据包要送达哪台主机。
两者都是32 位二进制 ,也就是我们日常用的IPv4 地址。
(12)选项:略
⑧++地址管理-网段划分++
IP地址分为两个部分,⽹络号和主机号
- 网络号:标识这个 IP 属于哪个网段(相当于 "小区地址")
- 主机号:标识这个网段里的具体设备(相当于 "门牌号")
网段划分在做什么
就是在决定:从哪里切开网络号和主机号
- 用子网掩码来切
- 划分子网 = 从主机号里借几位当网络号,把一个大网段切成多个小网段
所以:IP 地址结构 → 网络号 + 主机号 ↓子网划分 → 调整网络号和主机号的边界
不同的⼦⽹其实就是把⽹络号相同的主机放到⼀起
如果在⼦⽹中新增⼀台主机,则这台主机的⽹络号和这个⼦⽹的⽹络号⼀致,但是主机号必须不能和⼦⽹中的其他主机重复
CIDR
CIRD=无类别域间路由 说白了就是一种更灵活、更简洁地表示 IP 网段的写法。
1. 长什么样?
格式:IP 地址 / 前缀位数
比如:
192.168.1.0/2410.0.0.0/8172.16.0.0/12
2. /数字 是什么意思?
前 24 位 = 前三段数字
一个 IP 写成二进制是 32 位 ,但我们平时看的是 4 段十进制:
192 . 168 . 1 . 100
每一段,刚好就是 8 位二进制
- 1 段 = 8 位
- 2 段 = 16 位
- 3 段 = 24 位
- 4 段 = 32 位
所以:
- 前 8 位 = 第一段:192
- 前 16 位 = 前两段:192.168
- 前 24 位 = 前三段:192.168.1
- 前 32 位 = 整个 IP
所以
/24表示:前 24 位是网络号,剩下的是主机号- 等价于子网掩码:
255.255.255.0
对应关系(常用必背):
/8→255.0.0.0/16→255.255.0.0/24→255.255.255.0/32→255.255.255.255(单个 IP)
平时看到的 IP 只是单纯的地址 ,CIDR 后缀 /24 是子网信息,系统不会一起显示给你。
特殊的 IP 地址
将 IP 地址中的主机地址全部设为 0,就成为了网络号,代表这个局域网
将 IP 地址中的主机地址全部设为 1,就成为了广播地址,用于给同一个链路中相互连接的所有主机发送数据包
127.* 的 IP 地址用于本机环回 (loop back) 测试,通常是 127.0.0.1
/ 数字 决定哪部分是网络号
剩下的部分就是主机号,用来区分设备
不管这个网络号是私有还是公网,规则一模一样
实际上,由于一些特殊的 IP 地址的存在,数量远不足 43 亿,另外 IP 地址并非是按照主机台数来配置的,而是每一个网卡都需要配置一个或多个 IP 地址。
CIDR 在一定程度上缓解了 IP 地址不够用的问题(提高了利用率,减少了浪费,但是 IP 地址的绝对上限并没有增加),仍然不是很够用。这时候有三种方式来解决:
- 动态分配 IP 地址:只给接入网络的设备分配 IP 地址。因此同一个 MAC 地址的设备,每次接入互联网中,得到的 IP 地址不一定是相同的;
- NAT 技术(后面会重点介绍);
- IPv6:IPv6 并不是 IPv4 的简单升级版。这是互不相干的两个协议,彼此并不兼容;IPv6 用 16 字节 128 位来表示一个 IP 地址;但是目前 IPv6 还没有普及。
⑨++私有IP地址和公⽹IP地址++
1. 公网 IP(公网地址)
- 全球唯一,在整个互联网上只有这一个
- 由运营商分配,用来在互联网上标识你的设备
- 可以直接被外网访问
- 比如你家路由器在互联网上的 IP
一句话:公网 IP = 你家在地球上的详细地址,全世界都能找到你。
2. 私有 IP(内网地址)
- 只能在局域网内部使用(家里、公司、学校)
- 不允许在互联网上路由
- 所有局域网都可以重复使用这些段,不冲突
- 你的手机、电脑、平板拿到的基本都是私有 IP
一句话:私有 IP = 你家房间号,只在你家内部有用,出了家门就不认。
3. 三段私有 IP 地址(必背)
- 10.0.0.0 ~ 10.255.255.255 (/8)
- 172.16.0.0 ~ 172.31.255.255 (/12)
- 192.168.0.0 ~ 192.168.255.255(/16)
前三段一样 = 同一个局域网比如:192.168.1.2192.168.1.3192.168.1.100→ 都在一个家里 / 公司内网
前三段不一样 = 不同网段比如:192.168.1.xxx 192.168.2.xxx→ 不是一个局域网
公网 IP、私有 IP 是 "地址的身份",CIDR 是 "怎么切分网段"。 不管是公网还是私有,都要用 CIDR 来划分网段。
子网掩码圈出网络号 →网络号决定是公网还是私有 →剩下的主机号只用来区分设备,不改变公私有身份。
⑩++路由选择(了解)++
路由选择 = 数据包在互联网上 "怎么走、走哪条路" 的决策过程。
可以理解成:IP 数据包的导航系统。
1. 它到底在干嘛?
你要给某个 IP 发数据,比如访问百度:
- 你的电脑不知道百度具体在哪,只知道目标 IP
- 沿途的路由器会查自己的路由表
- 决定下一步把数据包发给谁,一步步靠近目标
这一步一步选路的过程,就叫路由选择。
2. 核心东西:路由表
每个路由器都有一张表,长这样(简化):
表格
| 目标网段 | 下一跳 | 接口 |
|---|---|---|
| 192.168.1.0/24 | 直接连 | 局域网口 |
| 10.0.0.0/8 | 192.168.1.1 | 局域网口 |
| 0.0.0.0/0(默认) | 运营商路由器 | 外网口 |
收到数据包 → 看目标 IP → 匹配最精确的网段 → 发给下一跳
3. 数据包怎么走(以你访问百度为例)
- 你的电脑:
192.168.1.100 - 发给家里路由器(网关)
- 家里路由器查路由表 → 发给运营商路由器
- 运营商路由器查路由表 → 发给省级骨干网
- 骨干网一路转发 → 到达百度服务器
- 百度回包,原路返回
每一步都在做路由选择。
4. 和你前面学的 IP 有什么关系?
- 路由选择只看网络号,不看主机号
- 同一个网段(相同网络号)→ 直接走局域网
- 不同网段 → 交给网关,走外网路由
- 公网 IP 之间的跳转,全靠路由选择
5. 最简单总结
路由选择 = 路由器根据目标 IP 的网络号, 决定数据包下一步发给谁, 让它一步步从你这里走到目标设备。
你可以把路由器当成快递中转站 ,路由表就是中转指南 ,路由选择就是按指南分拣包裹。
数据链路层(了解):
①①++以太网++
以太网 = 现在最普遍的局域网技术标准
说白了就是:网线 + 网卡 + 交换机 这套东西的统称。
以太⽹帧格式:
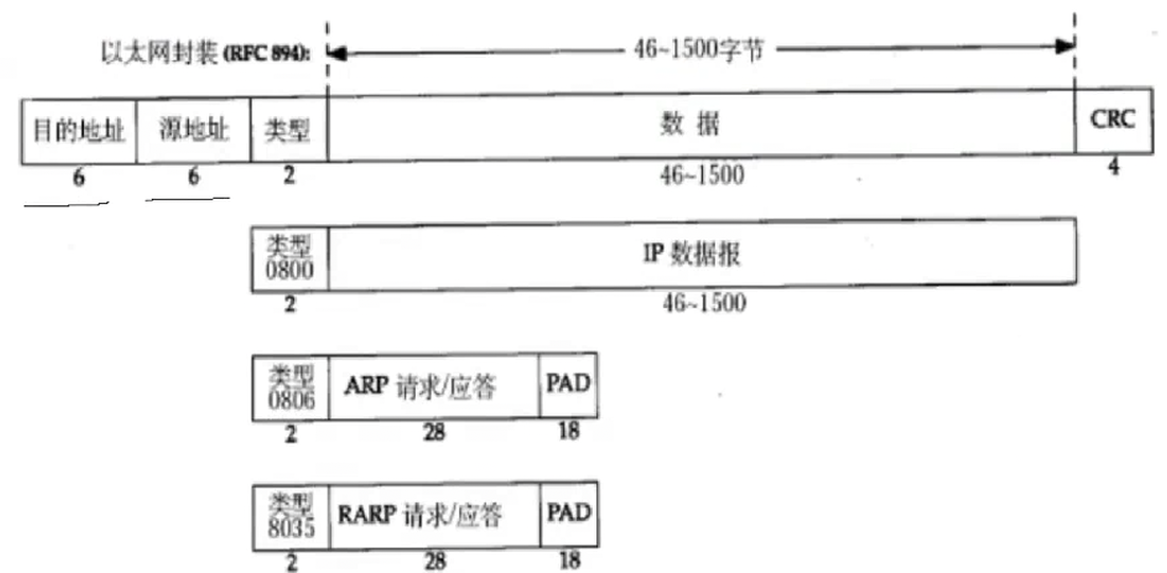
这里的地址是mac地址(不是ip地址)
MAC 地址 = 设备出厂自带的 "物理身份证",全世界唯一,烧在网卡里,改不了。(可以作为一个电脑的身份标识)
1. 它长什么样
类似这样:38-F7-2D-1A-7B-99一共 6 段,12 个字符
2. 和 IP 地址的区别
- MAC 地址:身份证号,跟着设备走,不变
- IP 地址:住址,换网络就变(家里一个、学校一个、公司一个)
- IP 地址描述的是路途总体的起点 和终点;
- MAC 地址描述的是路途上的每一个区间的起点和终点。
你在北京,要寄快递给上海的朋友
1. IP 地址 = 寄件地址 + 收件地址
- 你的地址:北京市 XX 小区(源 IP)
- 朋友地址:上海市 XX 小区(目的 IP)
这就是整条路的起点和终点,不管中间怎么转运,最终目标就是这两个地址。
2. MAC 地址 = 每一段运输的收发点
快递不会直接飞过去,要一段段转运:
- 快递员取件 → 北京网点
- 北京网点 → 北京转运中心
- 北京转运中心 → 上海转运中心
- 上海转运中心 → 上海网点
- 上海网点 → 朋友家
每一段的发货方和收货方,就是一对 MAC 地址
- 这段起点:上一个中转站
- 这段终点:下一个中转站
每走完一段,就换一对新的 MAC 地址,直到送到最终目的地。
对应到网络
- IP 从头到尾不变 ,标记整条路的起点和终点
- MAC 每经过一个路由器就变 ,只标记当前这一段的起点和终点
①②**++重要应⽤层协议DNS++**
DNS = 互联网的 "通讯录"
把域名(www.baidu.com)翻译成 IP 地址(110.242.68.66)
- 人记不住 IP,只记得域名
- 机器只认 IP,不认域名
- DNS 负责在两者之间翻译
你输入:www.baidu.comDNS 帮你查出来:110.242.68.66然后浏览器才真正去连接这个 IP。
①③++NAT++
NAT = 网络地址转换,让一堆私有 IP 设备,共用一个公网 IP 上网。
1. 它解决了什么问题?
IPv4 公网 IP 非常少,不可能给你家每个手机、电脑都分配一个公网 IP。于是就有了这套方案:
- 家里设备用 私有 IP
- 路由器用 一个公网 IP
- NAT 负责在两者之间翻译、替换地址
2. 工作过程超级通俗版
你手机(私有 IP:192.168.1.100)访问百度:
-
手机发数据包:
- 源 IP:
192.168.1.100(私有) - 目标 IP:百度 IP
- 源 IP:
-
到你家路由器,NAT 上场:
- 把源 IP 换成路由器的公网 IP
- 记录下:"这个请求来自 192.168.1.100" (用于接受返回值的时候精确指定接受者)
-
数据发到百度,百度只看到你家公网 IP,不知道你手机
-
百度回包到路由器
-
路由器查记录,再把目标 IP 换回你手机私有 IP,发给你
同一个路由器下面的所有私有 IP,网络号全都一样
公网 IP 的规则
- 同一个网络号 (例如
220.181.38)- 子网掩码决定哪部分是网络号
- 剩下的主机位不同 → 变成一个个不同的公网 IP
220.181.38.1220.181.38.2220.181.38.3...私有 IP 的规则
- 同一个网络号 (例如
192.168.1)- 子网掩码决定哪部分是网络号
- 剩下的主机位不同 → 变成一个个不同的私有 IP
192.168.1.100192.168.1.101]注意这里说的不同的私有ip是指在一个公网ip下的私有ip
不同公网ip是可以包含相同的网络ip的
区分就靠NAT的表
私有IP 公网IP+端口 192.168.1.100 → 123.45.67.89:50001 192.168.1.101 → 123.45.67.89:50002互联网整体结构(公网 ↔ 私有 IP)
第一层:全球公网区域(全部唯一,不能重复)
公网网络号 1:
123.1.1.0/24
- 公网 IP1:123.1.1.1
- 公网 IP2:123.1.1.2
- 公网 IP3:123.1.1.3
公网网络号 2:
222.2.2.0/24
- 公网 IP4:222.2.2.1
- 公网 IP5:222.2.2.2
公网网络号 3:
111.3.3.0/24
- 公网 IP6:111.3.3.1
第二层:每个公网 IP 对应 一个家庭内网(私有 IP 可重复)
家庭 A(公网 IP:123.1.1.1)
内网网络号:
192.168.1.0/24
- 私有 IP:192.168.1.10
- 私有 IP:192.168.1.11
- 私有 IP:192.168.1.12
家庭 B(公网 IP:123.1.1.2)
内网网络号:
192.168.1.0/24
- 私有 IP:192.168.1.10
- 私有 IP:192.168.1.11
家庭 C(公网 IP:222.2.2.1)
内网网络号:
192.168.1.0/24
- 私有 IP:192.168.1.10
家庭 D(公网 IP:111.3.3.1)
内网网络号:
192.168.5.0/24
- 私有 IP:192.168.5.10