在AI应用开发中,让大语言模型(LLM)稳定输出合法、规范的JSON是生产环境的刚需。一旦JSON格式出错,轻则接口解析失败,重则导致整个服务链路崩溃。
LLM 输出 JSON 格式的常见翻车现场:
- 前后带多余文字:
根据你的需求,结果如下:{"name":"xxx"} - 语法错误:单引号、尾随逗号、括号不匹配
- 字段缺失 / 类型错误:本该数字返回字符串,必填字段直接消失
- 被 Markdown 包裹:
json {...}
想彻底解决,不能只靠 "求模型听话",必须建立多层防御体系,从软引导到硬约束,层层兜底。 本文将其分为四层:
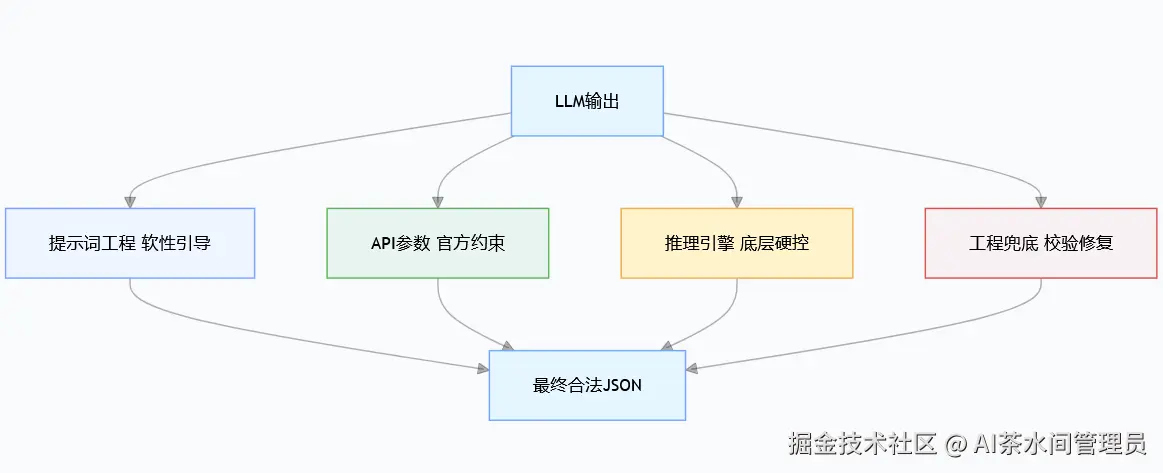
一、提示词工程(成本最低)
不改动任何代码,只优化 Prompt,就能解决 60% 的格式问题,适合原型验证或低风险场景。
1. 明确格式禁令
直接告诉模型禁止做什么,比只说 "输出 JSON" 更有效。系统提示词示例:
text
你是一个专业的数据格式化助手。
请严格遵循以下规则:
1. 仅输出符合 RFC 8259 标准的纯 JSON,无任何多余文字、解释、注释。
2. 禁止使用 Markdown 代码块、禁止加 ```json 标记。
3. 字段名称、类型严格按照要求,字符串用双引号,禁止尾随逗号。
4. 只返回 JSON,不回答任何其他问题。2. 注入 Schema + Few-Shot
模型对 "示例" 的服从度远高于文字描述。
text
# 输出结构
{
"code": 数字,
"message": 字符串,
"data": { "name": 字符串, "age": 数字 }
}
# 示例1
输入:用户小明,18岁
输出:{"code":0,"message":"success","data":{"name":"小明","age":18}}二、利用 LLM 的 API 原生能力
大部分厂商都提供了强制 JSON 输出的参数,比纯 Prompt 稳定一个量级。
1. JSON Mode
OpenAI、DeepSeek、通义千问等均支持,强制返回合法 JSON 语法。
py
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo",
response_format={"type": "json_object"}, # 核心参数
messages=[{"role": "user", "content": "提取用户信息:小李25岁"}]
)
json_result = response.choices[0].message.content2. Structured Outputs
直接传入 JSON Schema,模型必须严格按结构生成,字段、类型、枚举都能锁死。
OpenAI 文档中的示例:
py
from openai import OpenAI
from pydantic import BaseModel
client = OpenAI()
class CalendarEvent(BaseModel):
name: str
date: str
participants: list[str]
response = client.responses.parse(
model="gpt-4o-2024-08-06",
input=[
{"role": "system", "content": "Extract the event information."},
{
"role": "user",
"content": "Alice and Bob are going to a science fair on Friday.",
},
],
text_format=CalendarEvent,
)
event = response.output_parsed3. Function Calling 变相稳定输出
将这个 Json 格式输出封装成一次Function Calling。
把 JSON 结构定义为工具参数,模型返回的参数天然合规。适合需要结构化返回 + 工具调用的场景。
三、约束解码-推理引擎约束
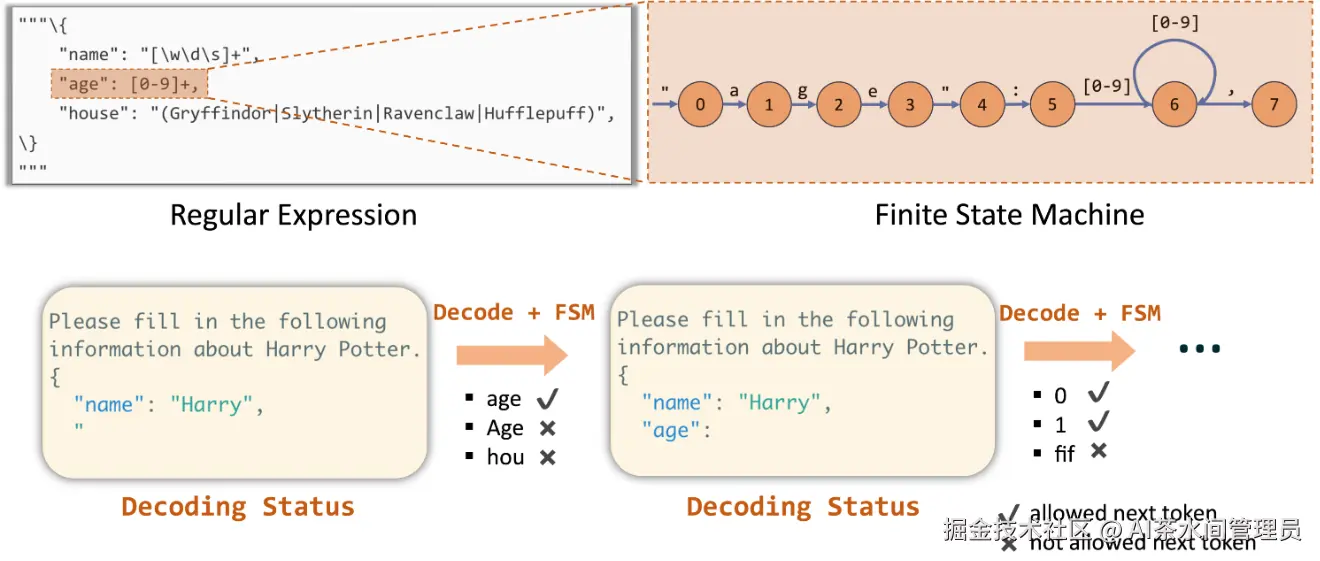
如果你的项目是私有化部署开源模型(如Llama 3、Qwen等),没有官方API的结构化输出支持,就需要用到更底层的推理引擎技术------约束解码(Constrained Decoding),实现"物理层面"杜绝格式错误。
原理:
在模型生成每一个 Token 时,动态屏蔽非法字符:
- 该出现
{时,其他字符概率直接置零 - 该出现数字时,禁止输出字母
- 严格遵循 JSON Schema 语法路径
相当于给模型铺死铁轨,根本无法脱轨。
四、工程兜底
再强的约束,极端场景也可能出问题,这时就需要工程上进行兜底。
1. 清洗脏数据
当模型输出包含多余文字(如"以下是JSON结果:{...}")、Markdown标记时,用正则表达式或状态机解析器,自动提取核心JSON结构,移除冗余内容。
2. 自动修复轻微错误
对于单引号、尾随逗号、缺失引号等轻微语法错误,无需重试模型,直接用工具库自动修复,提升效率。
3. 校验+重试
对输出进行语法和语义校验,一旦校验失败,不要简单重试,而是将"原始错误输出"和"具体校验错误信息"一同反馈给模型,引导它自我修正。
参考文献:
developers.openai.com/api/docs/gu...