微服务导学
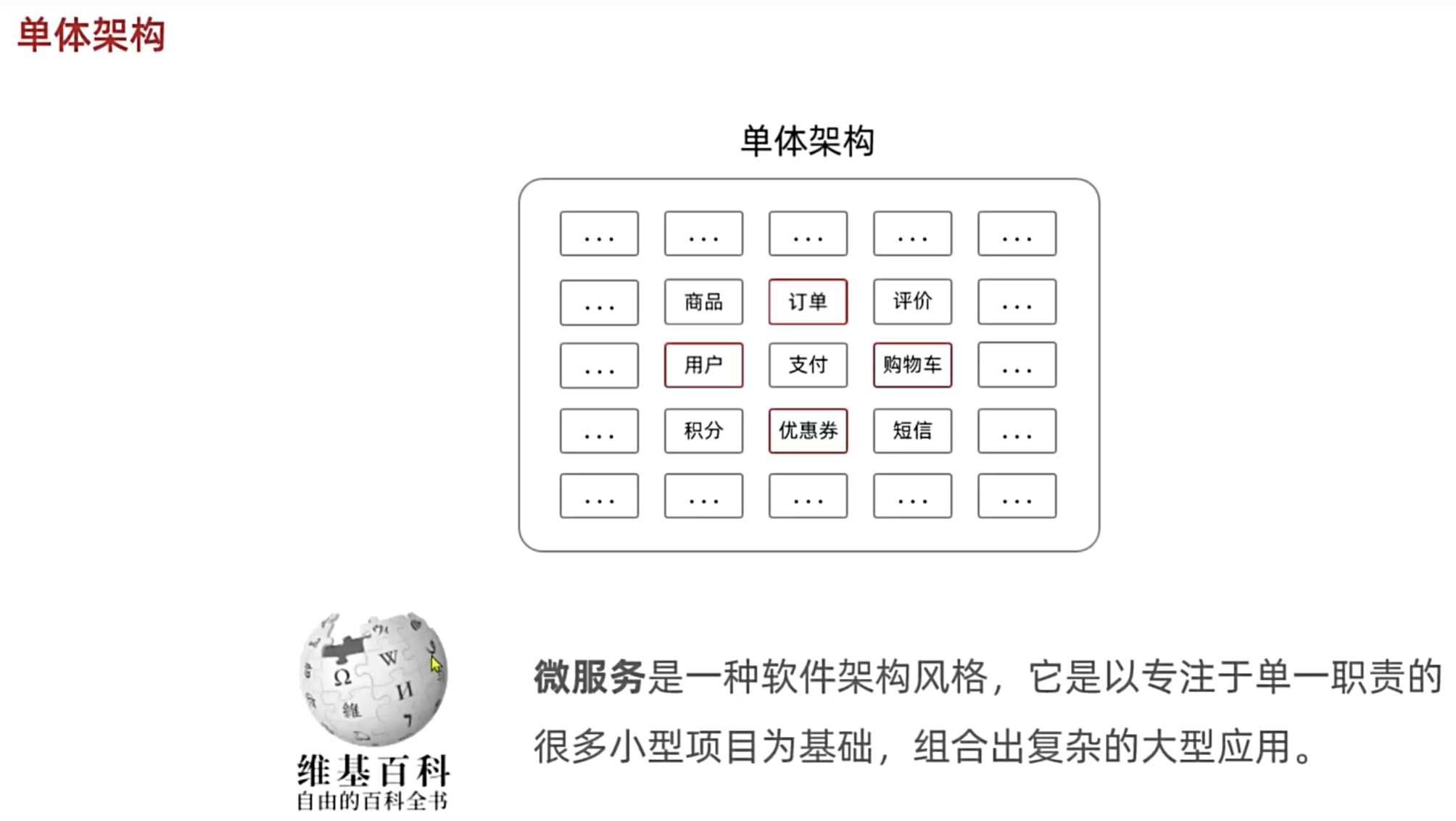
服务拆分
如何把单一的大项目如何拆分成一个个小项目
远程调用
每个小的单体项目,在物理上是隔绝开的,使用的是不同的Tomcat,有独立的运维和部署,互相之间如何调用就涉及到了远程调用的知识

学习微服务的最好方法是尝试着把一个大项目分成一个个小问题,然后解决这个过程中出现的问题
MybatisPlus
介绍

快速入门

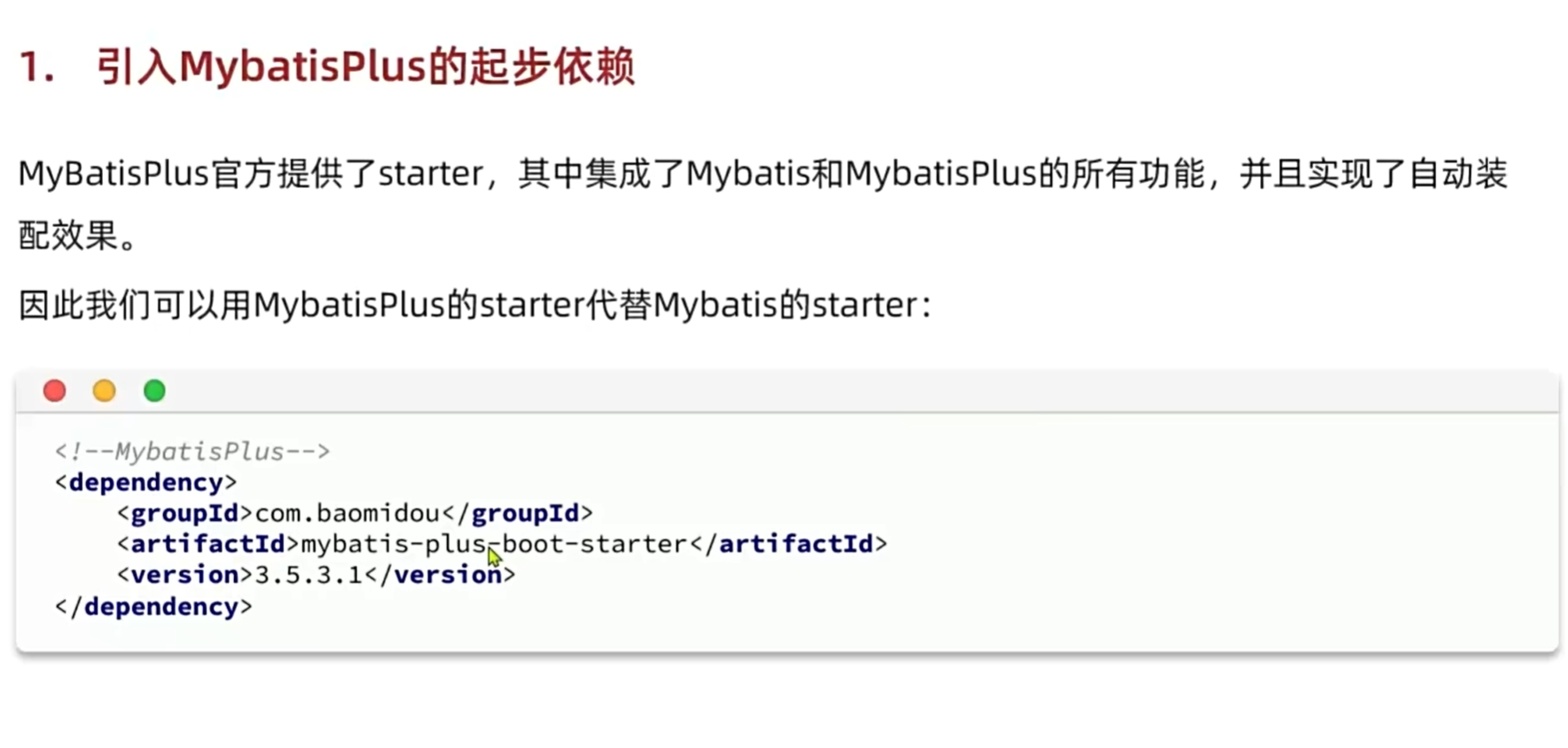
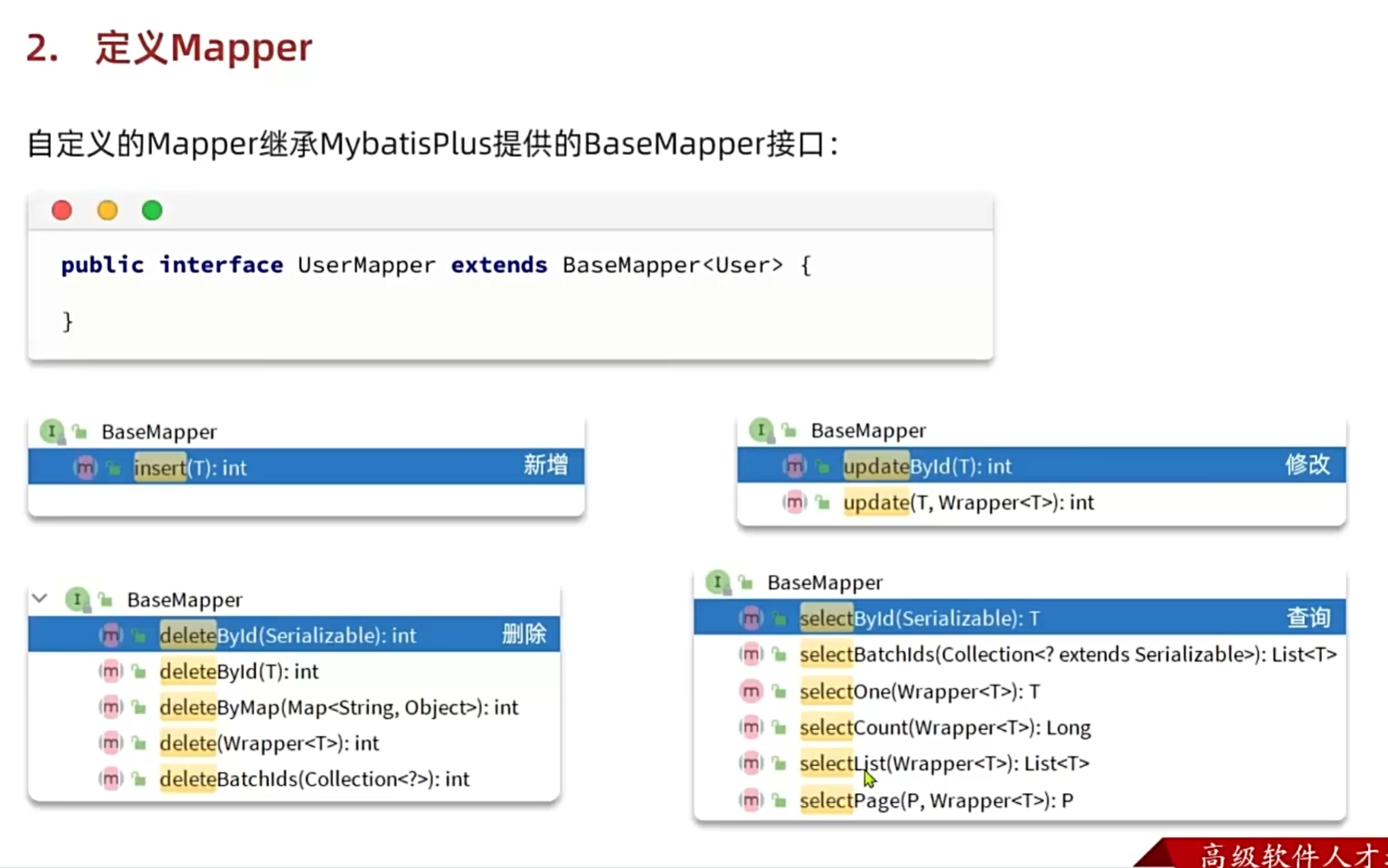

对于单表查询很好用
常用注解
MyBatisPlus用过扫描Mapper继承的实体类,基于反射获取实体类的信息作为数据库信息(也就是对应数据库的字段名)从而编写单表查询语句
实体类的字段名转数据库的字段名有约定如下,这就要求我们在编写实体类,以及数据库的时候要规范
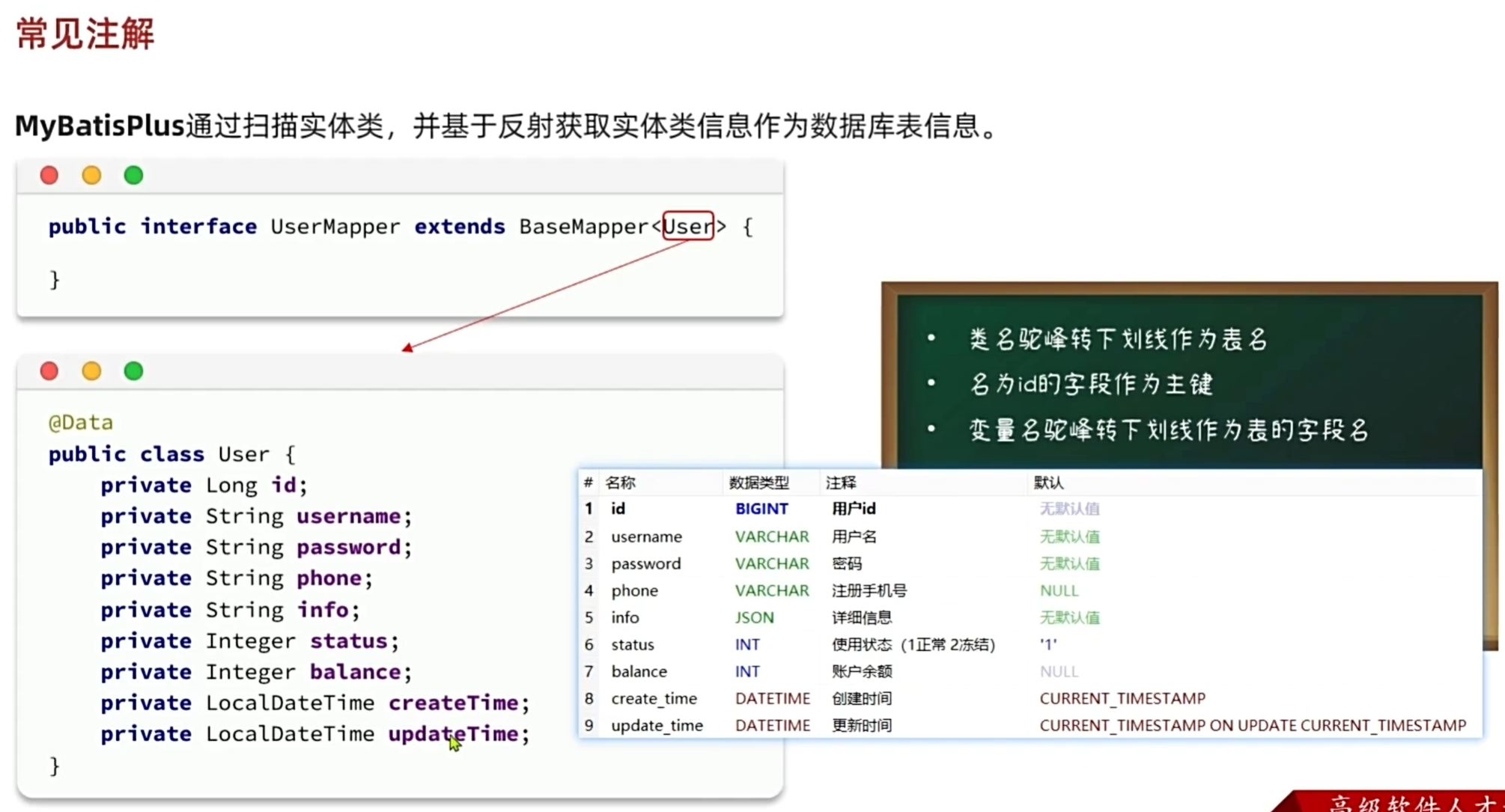
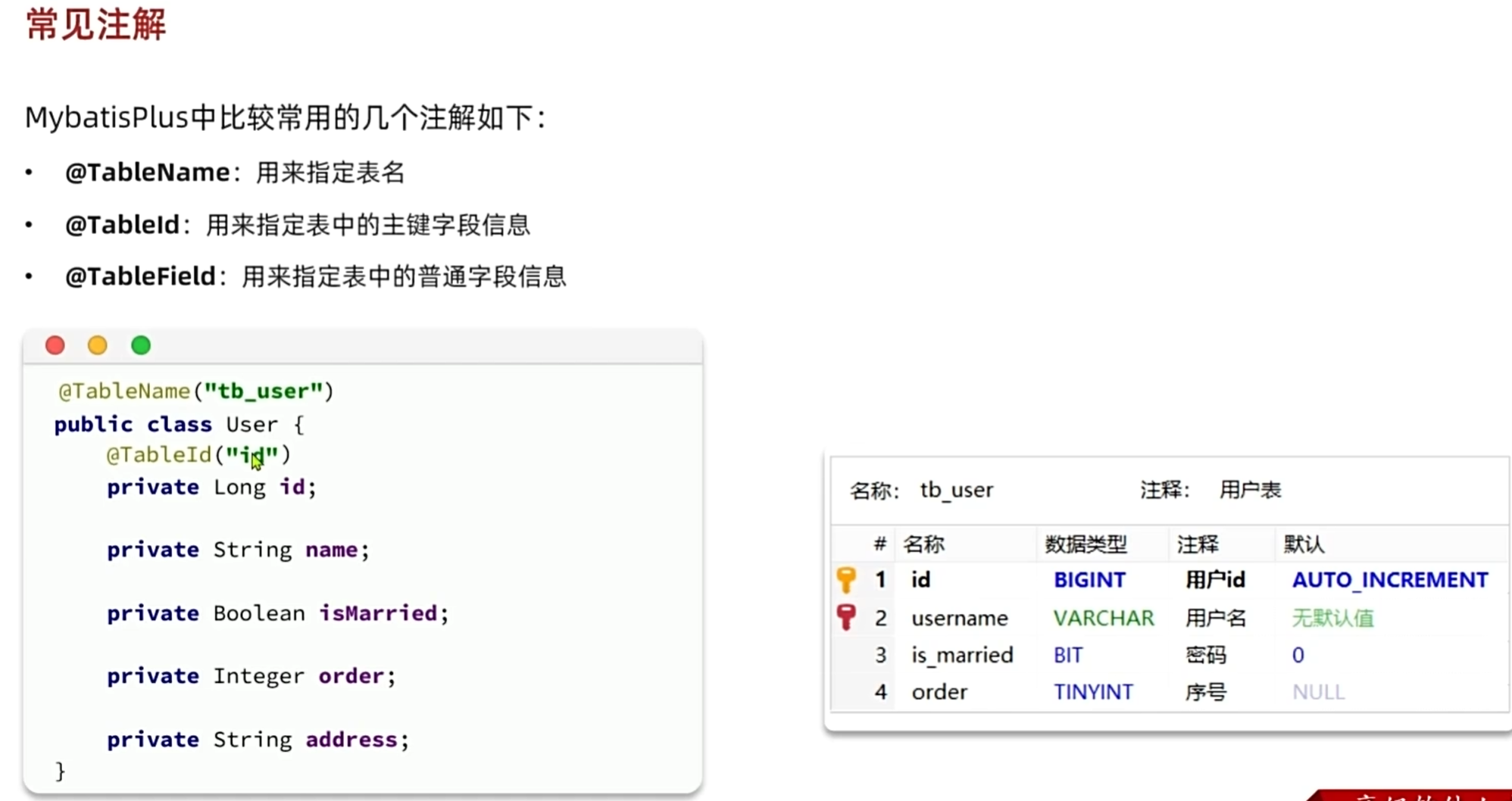
一定要注意的是,一定要有主键,有成员变量为id的或者用@TableId这个注解把主键是什么标出来
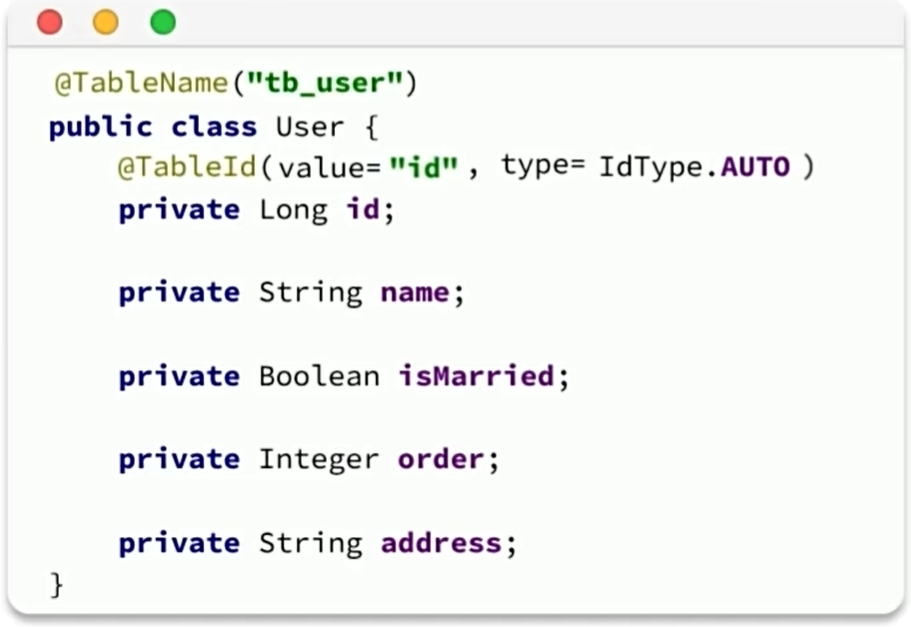
@TableId有两个属性,value是给这个成员变量起别名,并设置为主键,type是给这个成员变量设置如下属性


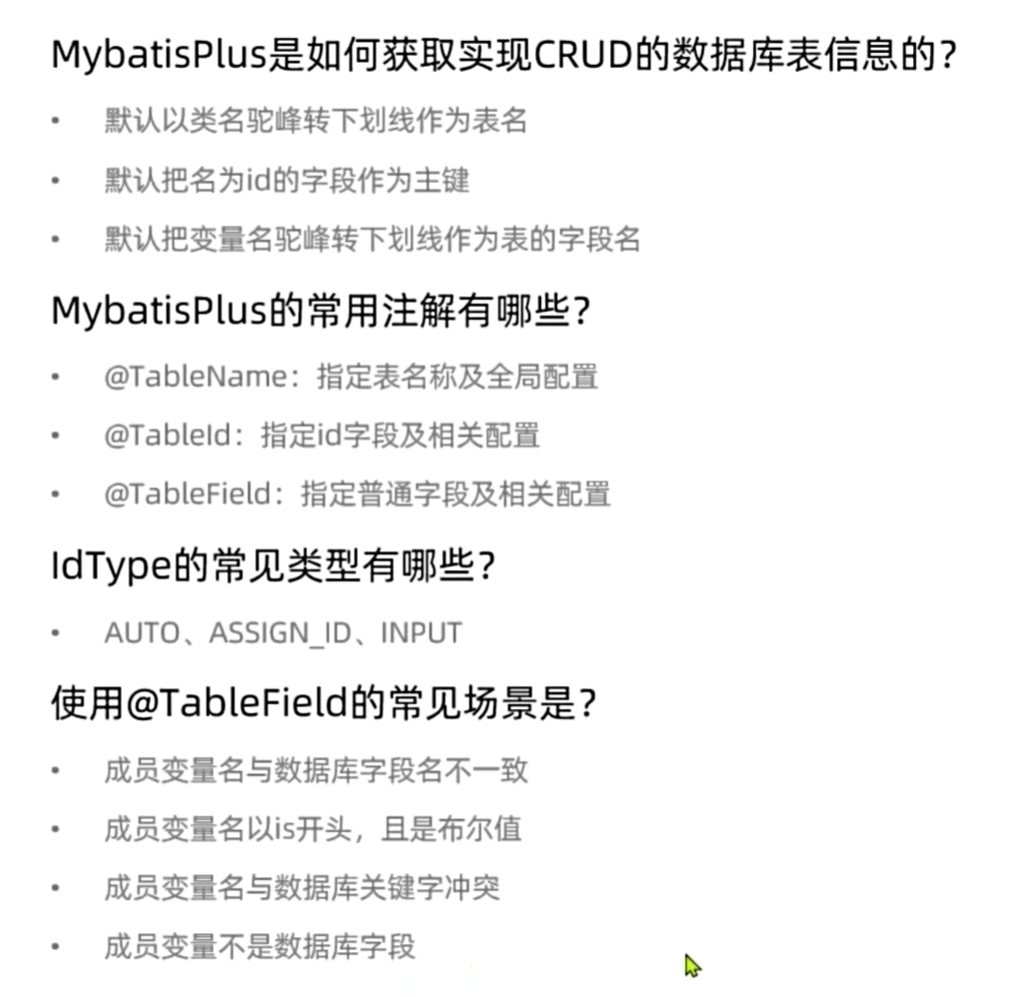
常用配置

默认id的type属性为雪花算法生成,但是优先级不如注解的高
java
mybatis-plus:
mapper-locations: '[classpath*:/mapper/**/*.xml]'
type-aliases-package: com.itheima.map.domain.po
global-config:
db-config:
id-type: assign-id
update-strategy: not-null
configuration:
map-underscore-to-camel-case: true
cache-enabled: false这些配置几乎都是默认的,不用自己配置

需要的时候看文档就行
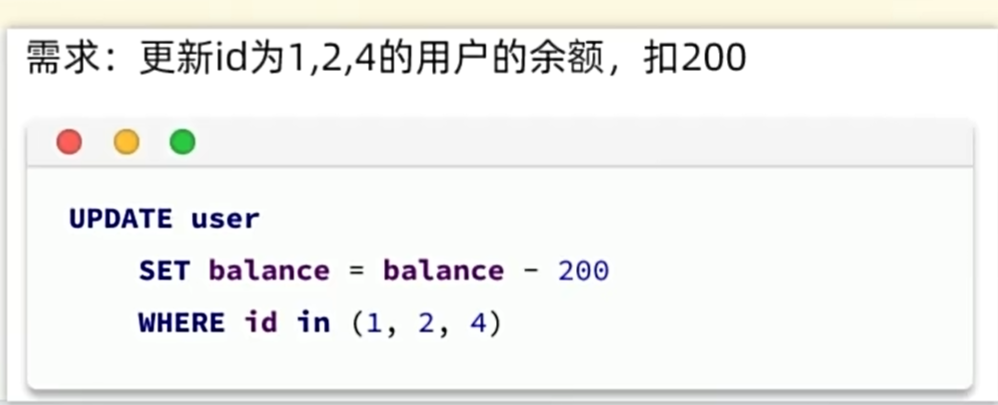
条件构造器
在给出复杂的where条件的时候可以使用条件构造器构造出来的一个类传入参数
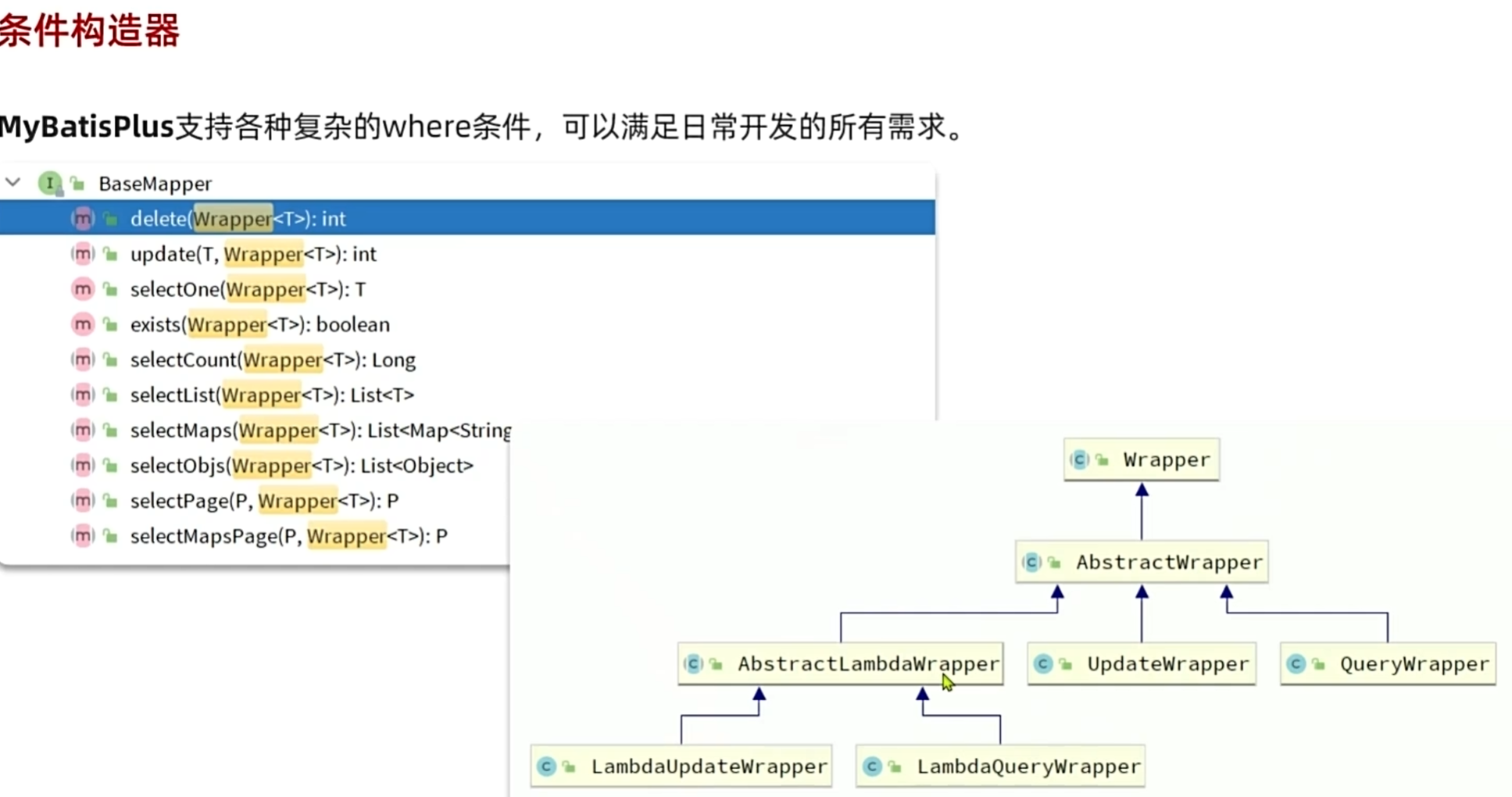
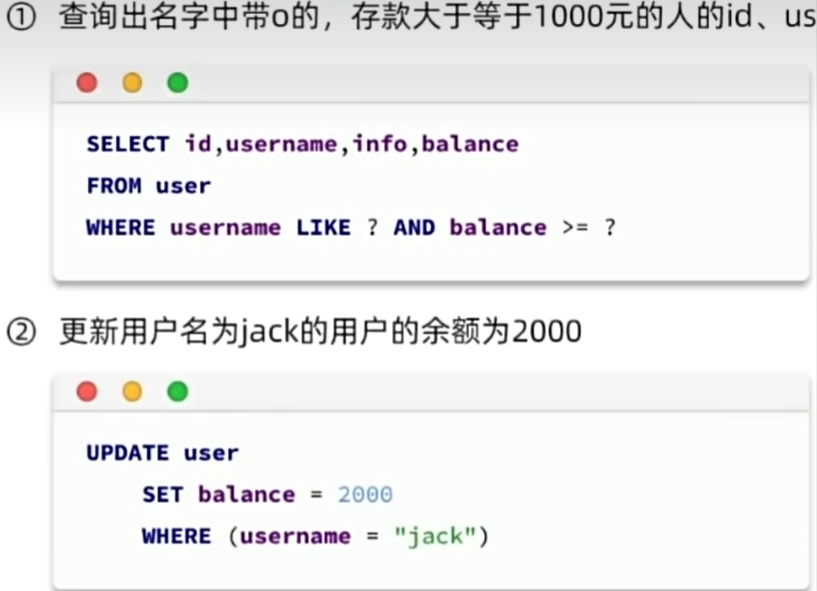
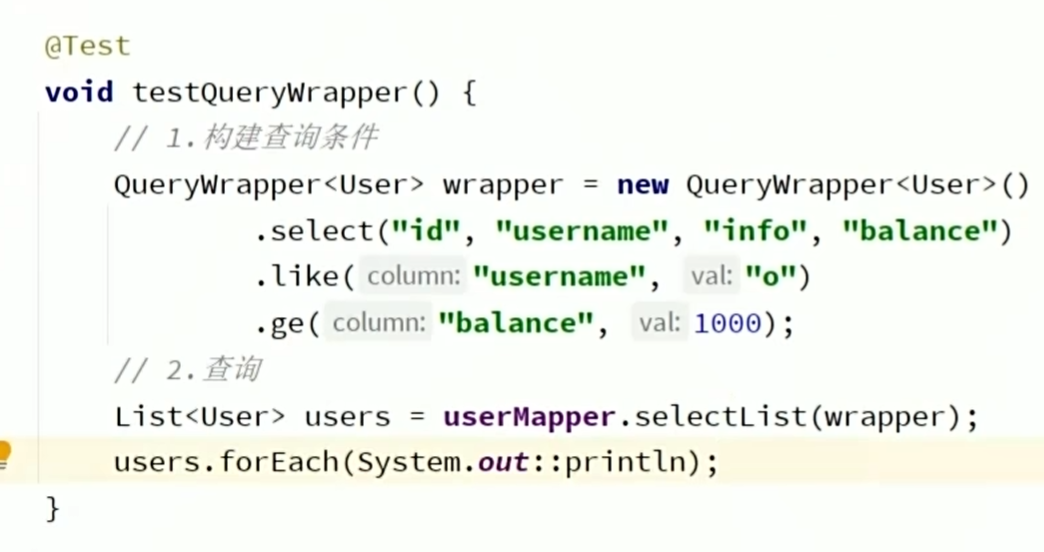

java
@Test
void testQuerywrapper() {
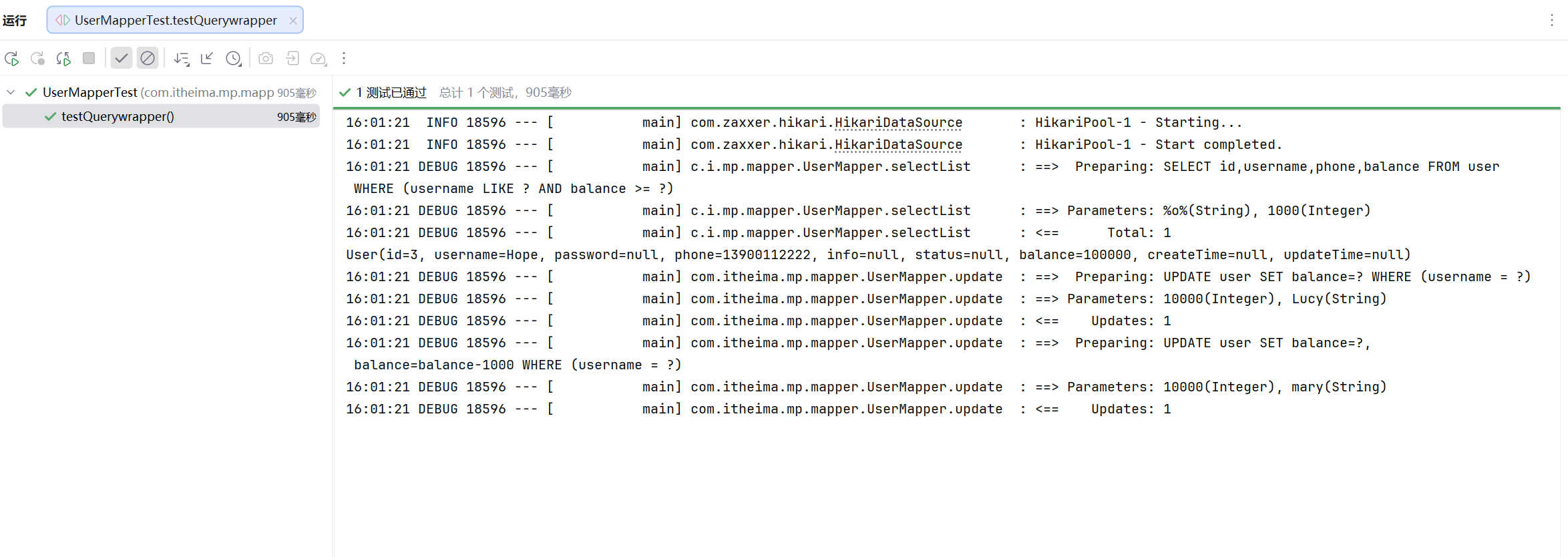
//在查询中 Wrapper用来填充复杂的条件语句,同时可以对查询结果做筛选
QueryWrapper<User> queryWrapper = new QueryWrapper<User>()
.select("id","username","phone","balance")
.like("username","o")
.ge("balance",1000);
List<User> users = userMapper.selectList(queryWrapper);
users.forEach(System.out::println);
//在更新中 Wrapper设置条件语句,还需要一个实体类来传递参数
User user = new User();
user.setBalance(10000);
QueryWrapper<User> queryWrapper1 = new QueryWrapper<User>()
.eq("username","Lucy");
userMapper.update(user,queryWrapper1);
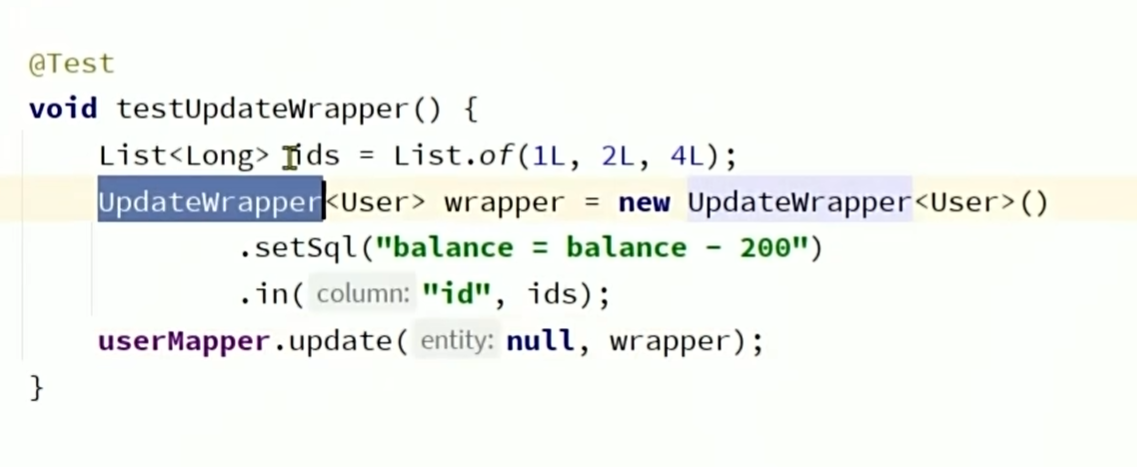
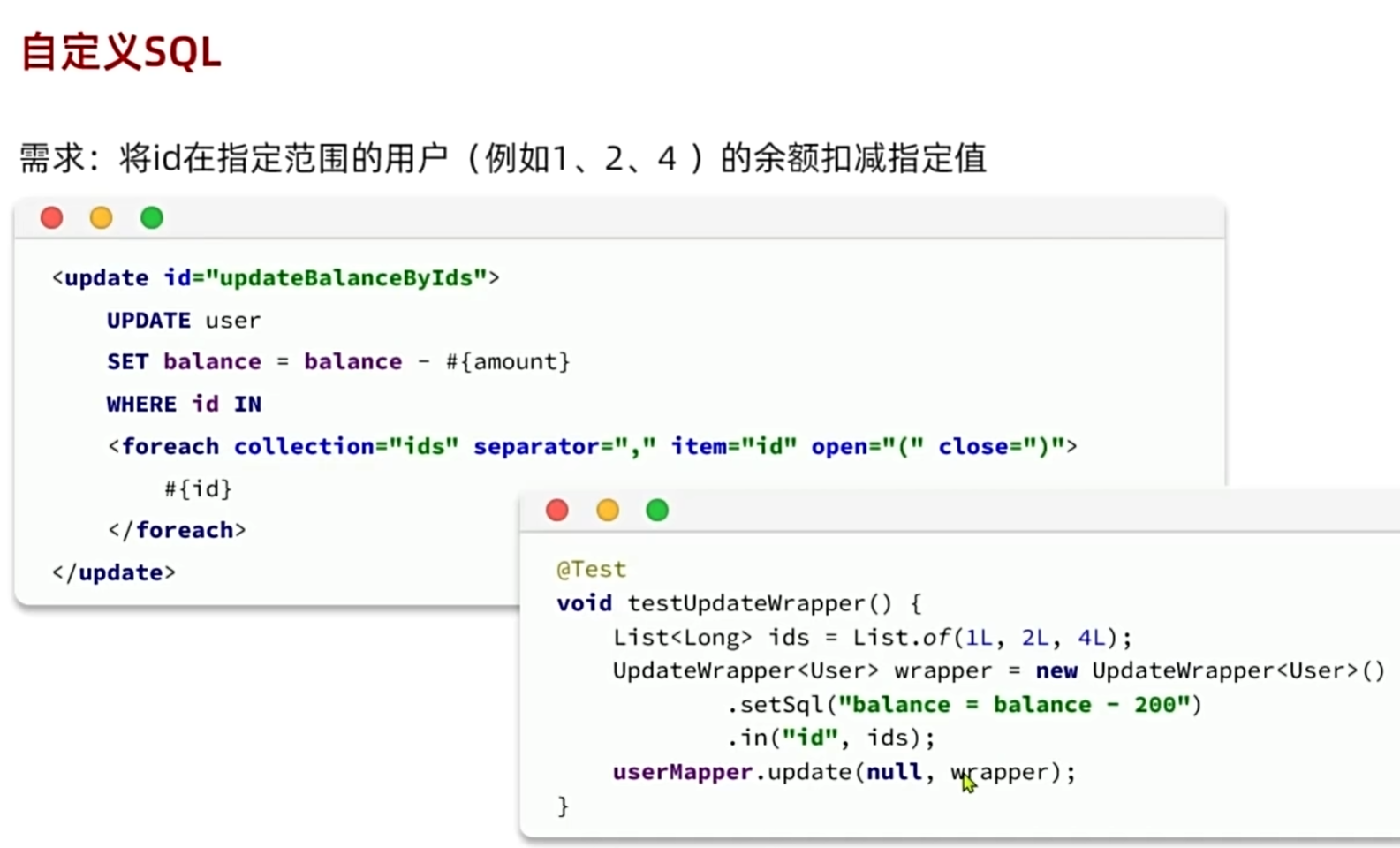
//在执行比较特殊的update语句的时候,可以手写sql语句
User user1 = new User();
user1.setUsername("zhangsan");
UpdateWrapper<User> updateWrapper = new UpdateWrapper<User>()
.setSql("balance=balance-1000")
.eq("username","mary");
userMapper.update(user,updateWrapper);
}
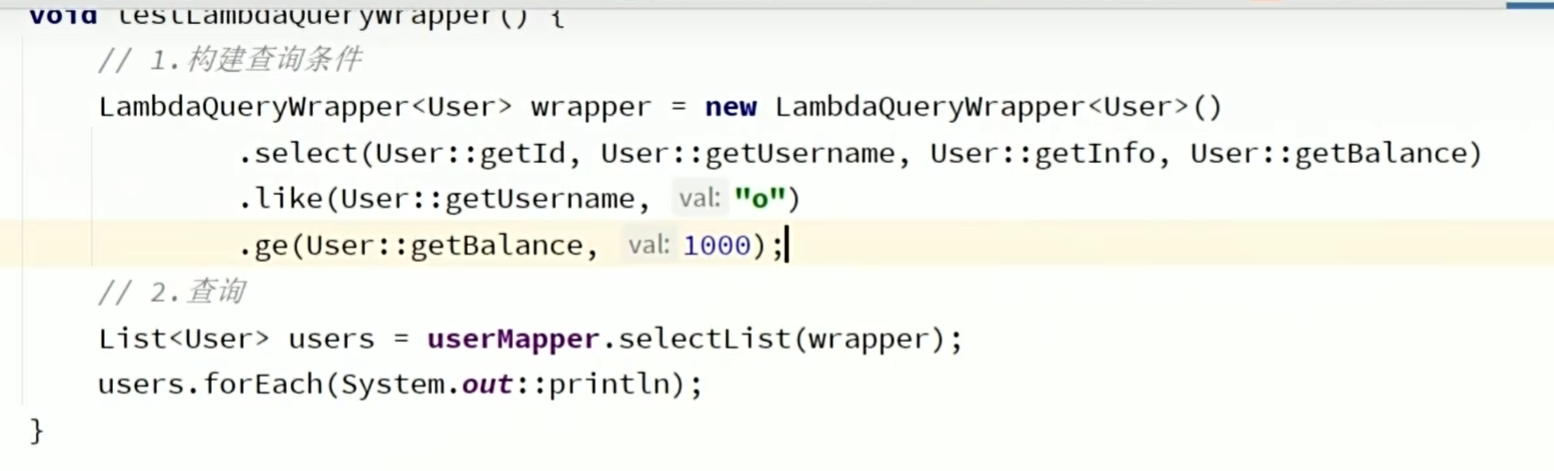
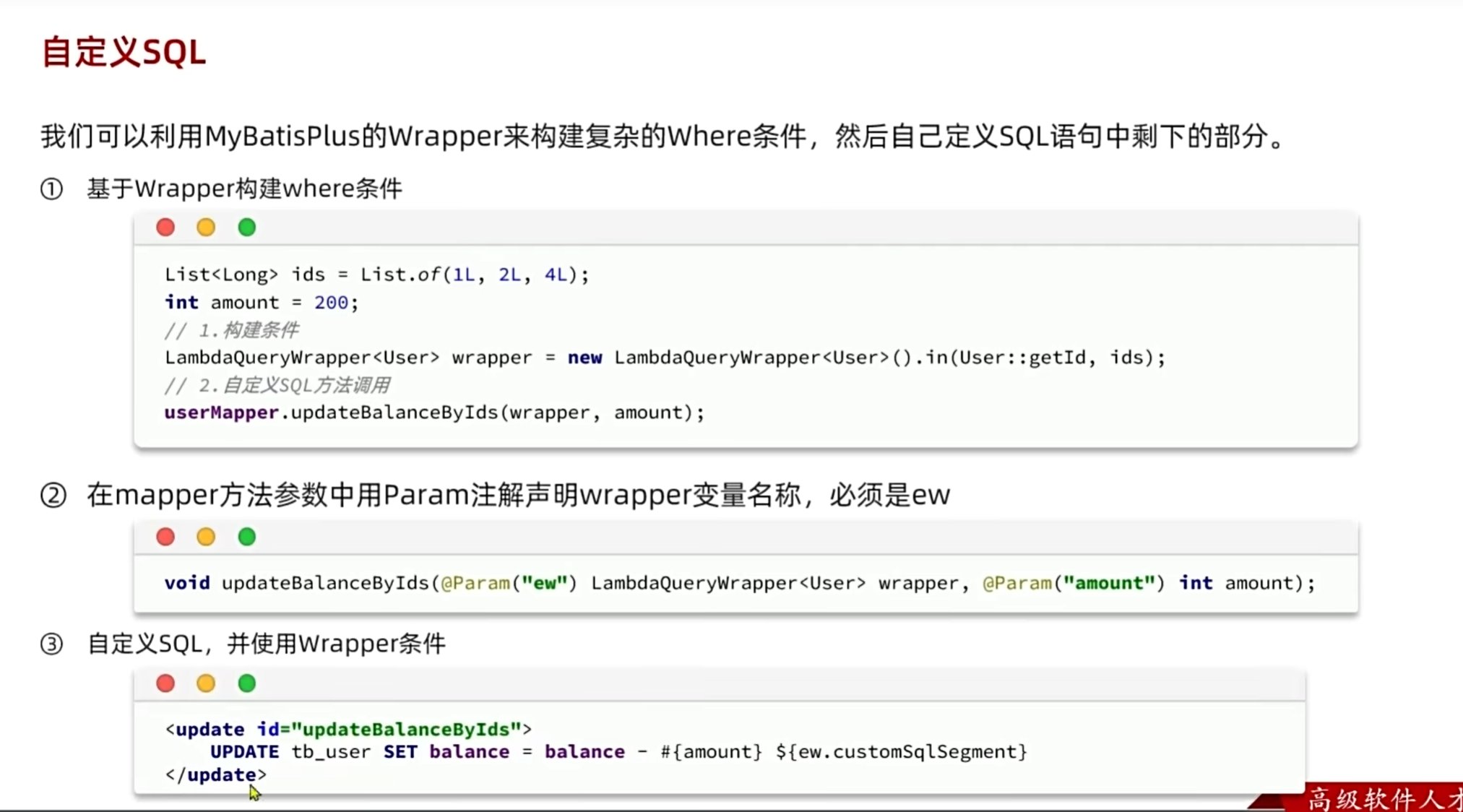
在构建wrapper的时候直接传入字段名是属于硬编码,要尽量避免,可以通过如下方法,传入函数的get方法来避免

自定义sql


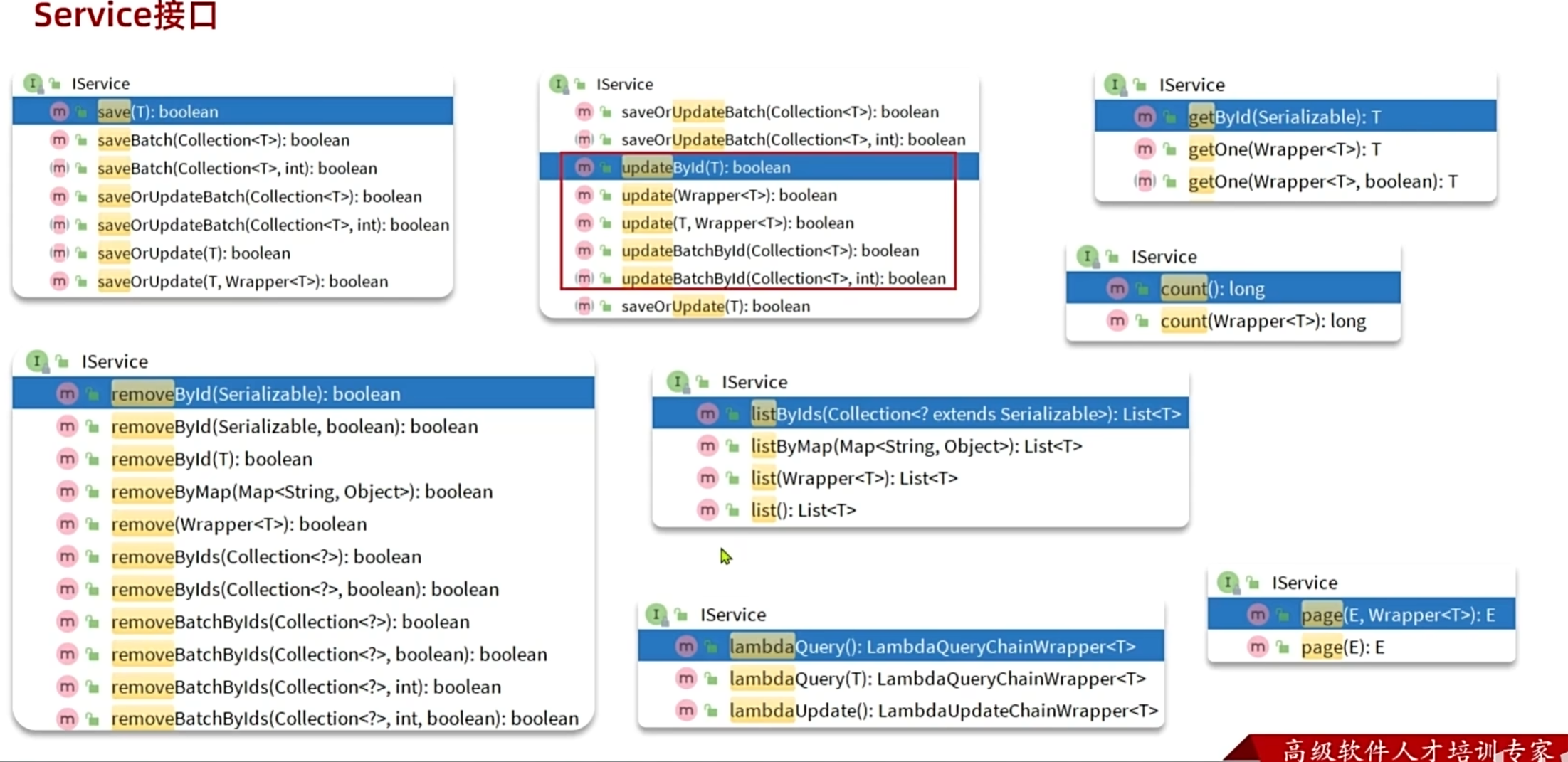
IService接口
基本用法
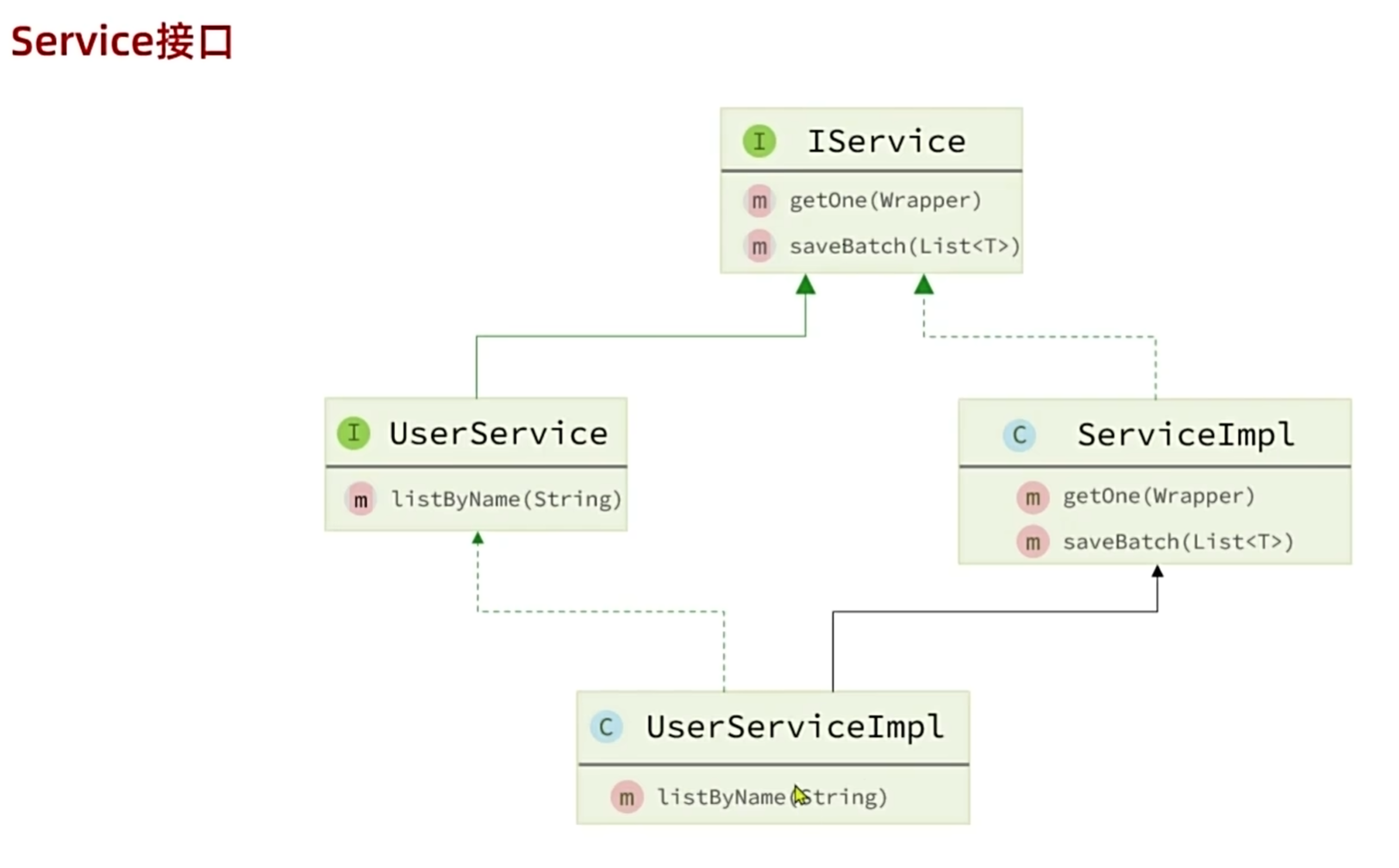
自定义接口继承IService接口
自定义实现类继承IService的实现类

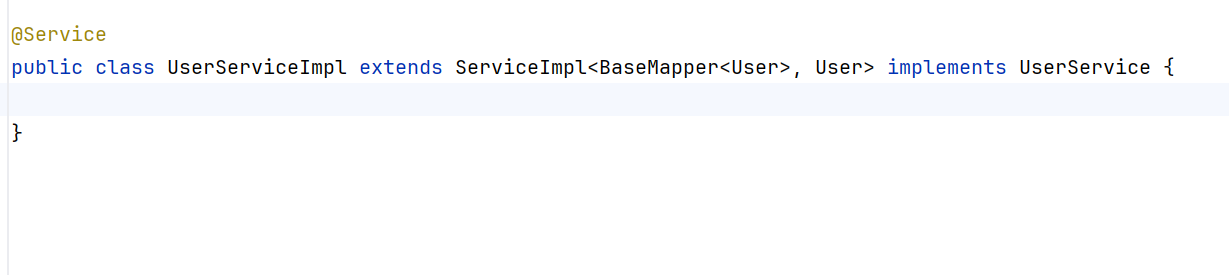
要传递baseMapper给ServiceImpl(IService的实现类)是因为调用Mapper方法时要知道要调用哪一个类的Mapper

开发基础业务接口
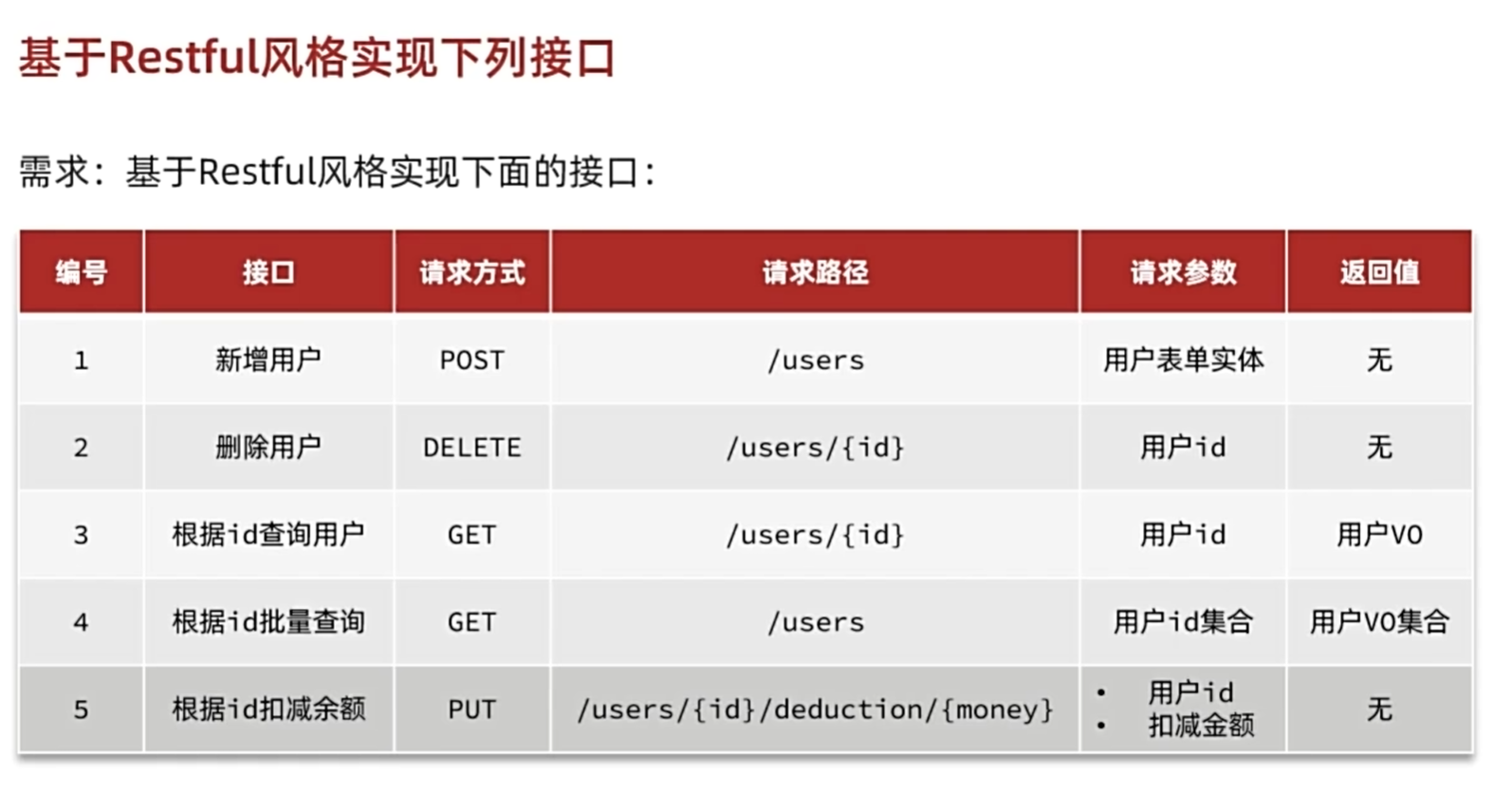
java
@RestController
@RequestMapping("/users")
@Api(tags="用户管理相关接口")
public class UserController {
private final UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
@PostMapping
@ApiOperation("新增用户")
public void saveUser(@RequestBody UserFormDTO userFormDTO) {
//把DTO拷贝到pojo
User user = BeanUtil.copyProperties(userFormDTO,User.class);
userService.save(user);
}
@DeleteMapping("/{id}")
@ApiOperation("删除员工")
public void deleteUser(@PathVariable String id) {
//删除用remove
userService.removeById(id);
}
@GetMapping("/{id}")
@ApiOperation("根据id查询用户")
public UserVO getUserById(@PathVariable String id) {
User user = userService.getById(id);
return BeanUtil.copyProperties(user,UserVO.class);
}
@GetMapping
@ApiOperation("根据id批量删除")
public List<UserVO> getUserByIds(@RequestParam List<Long> ids) {
//批量查询用list
List<User> userList = userService.listByIds(ids);
//因为返回类型是固定的,所以类的复制,转换会很常用
return BeanUtil.copyToList(userList,UserVO.class);
}开发复杂业务接口
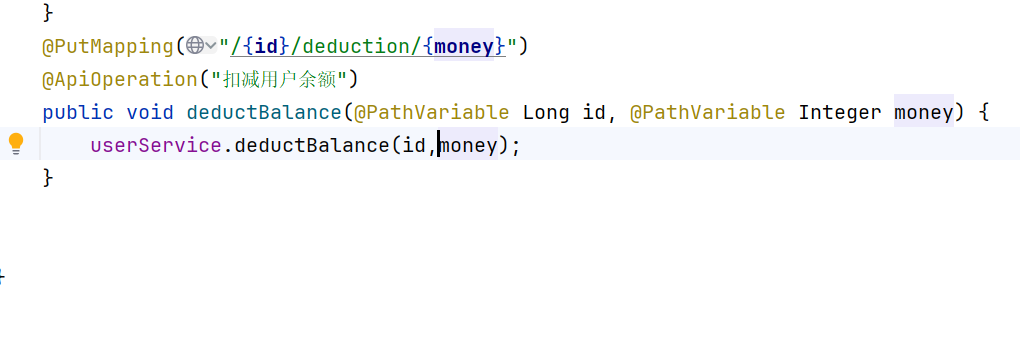

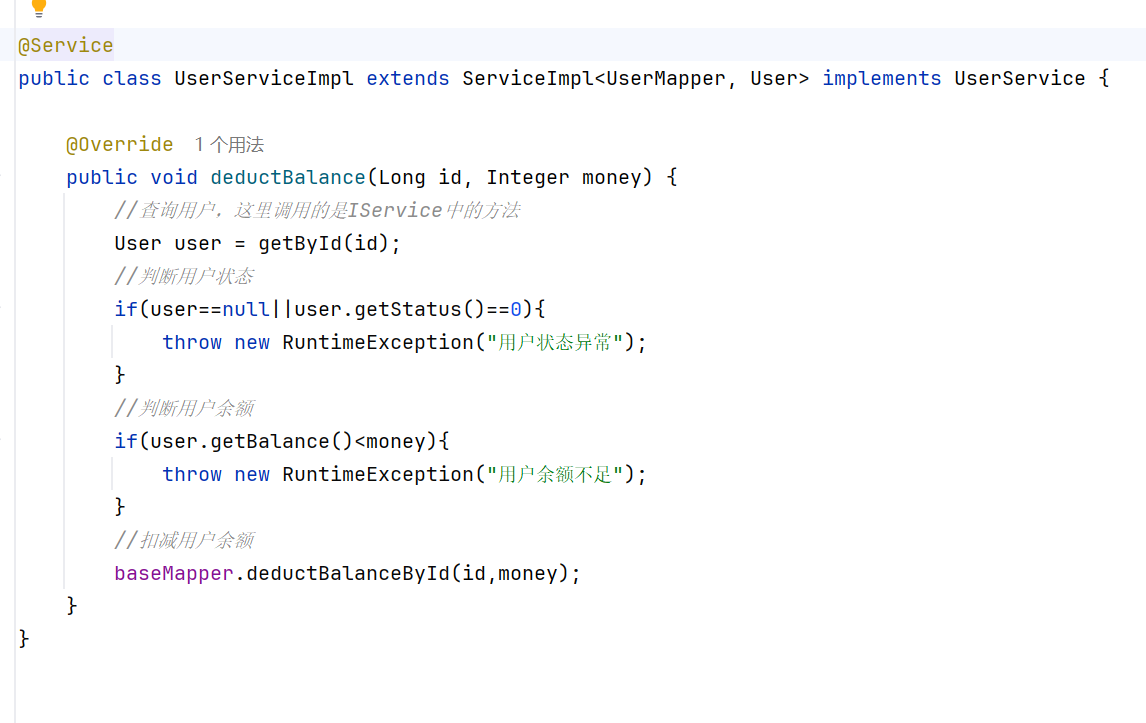
baseMapper是编译时多态,userMapper是运行时多态,通过泛型绑定实现了,自定义实现类继承mp提供的serviceImpl<UserMapper,User>的时候通过泛型绑定了,所以这里的BaseMapper实际上运行时使用的是userMapper对象,尽管deductMoneyById是不在BaseMapper中自定义的方法。

Lambda方法

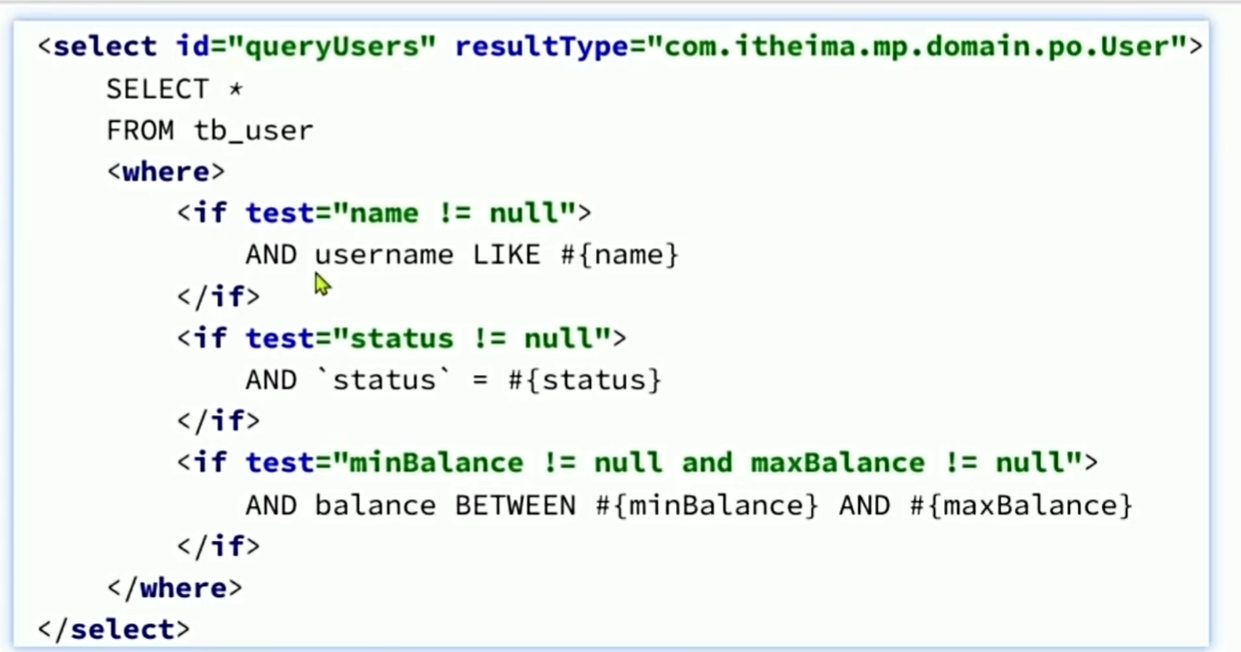

在查询参数比较多的时候,不建议用requestParam一个一个查询,太过于麻烦,可以定义一个对象来接收
ISerice的批量新增
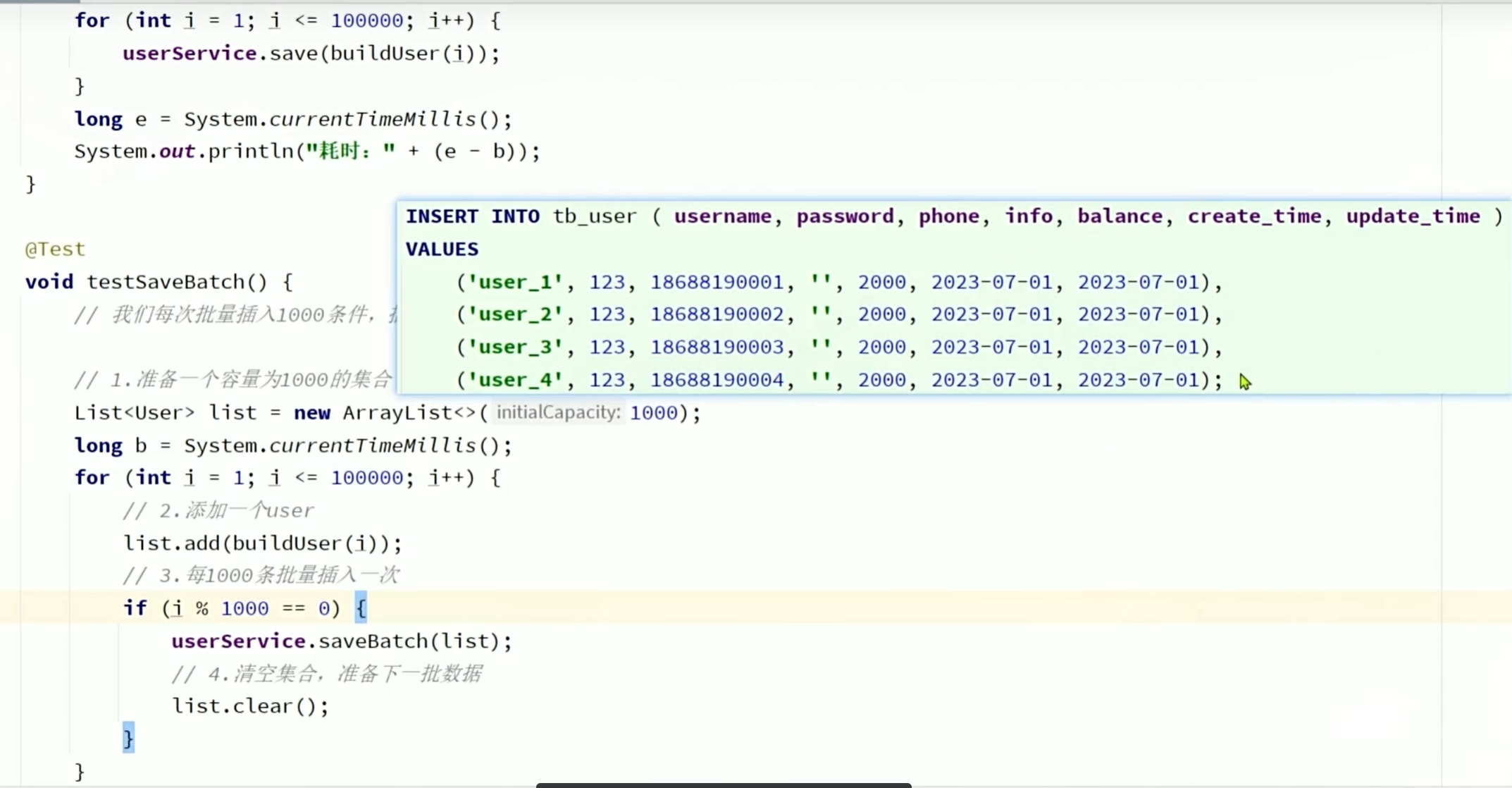
每一次循环只插入一条数据,一共要插入十万条数据就进入十万次数据库,每一次进入数据库就是一次网络请求,网络请求比较耗时间,所以效率比较低
每一次循环插入一千条数据,要插入十万条数据就要进入一百次数据库,执行网络请求的次数变少了,效率提升了,但是由于还是一条sql执行一次新增用户,效率还没有达到最好
一次性插入十万条数据,只进入一次数据库,且一条sql执行批量新增用户,一条sql可以添加多个用户,效率最高

java
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: root
password: 1234
java
@SpringBootTest
class MpDemoApplicationTests {
@Autowired
private UserService userService;
private User buildUser(int i) {
User user = new User();
user.setUsername("user_" + i);
user.setPassword("123");
user.setPhone("" + (18688190000L + i));
user.setBalance(2000);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(user.getCreateTime());
return user;
}
@Test
void testSaveBatch() {
// 准备10万条数据
List<User> list = new ArrayList<>(1000);
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
list.add(buildUser(i));
// 每1000条批量插入一次
if (i % 1000 == 0) {
userService.saveBatch(list);
list.clear();
}
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}代码生成器
插件功能

Docker

快速入门
-部署MySQL

应用的运行对环境和操作系统有强要求,windows64位的qq换到windows32位上面就不能运行
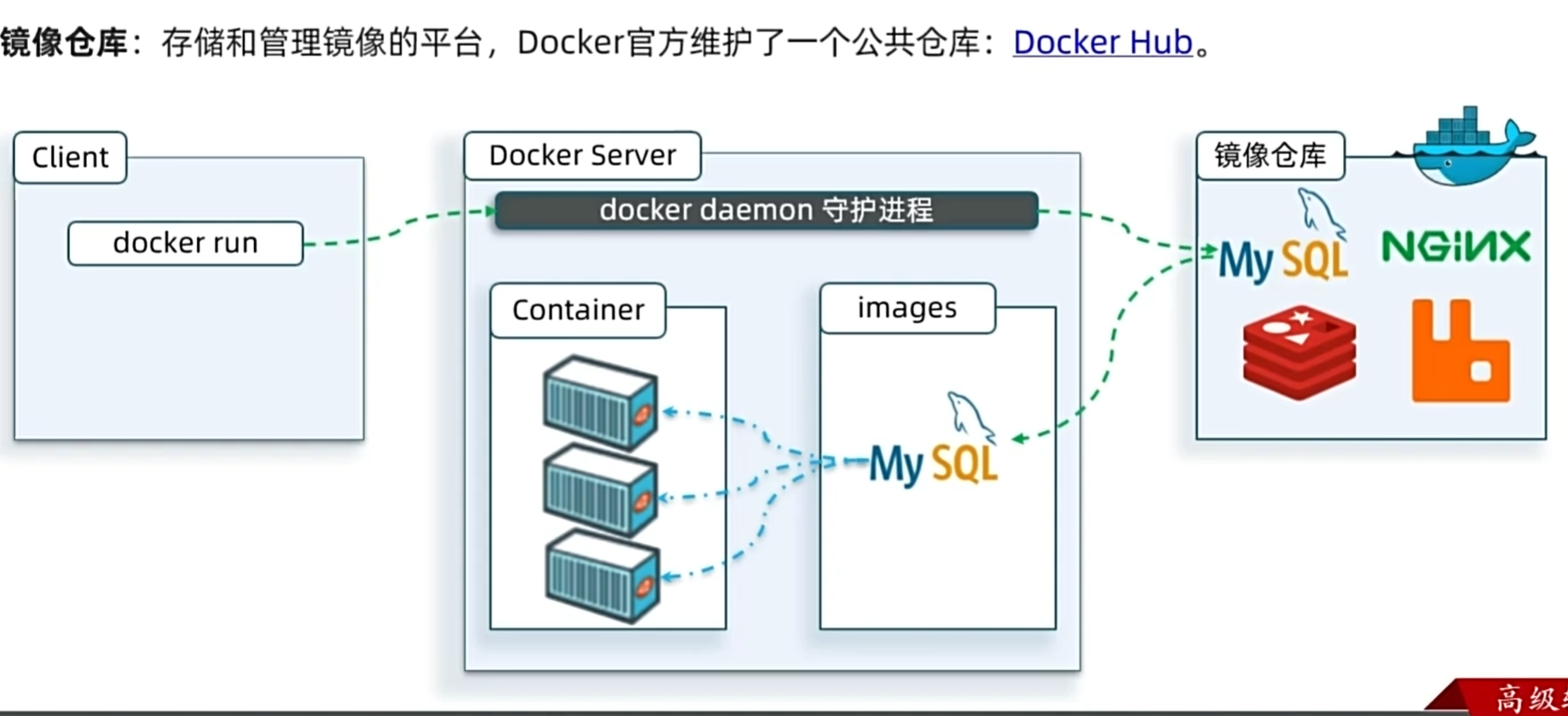
命令解读
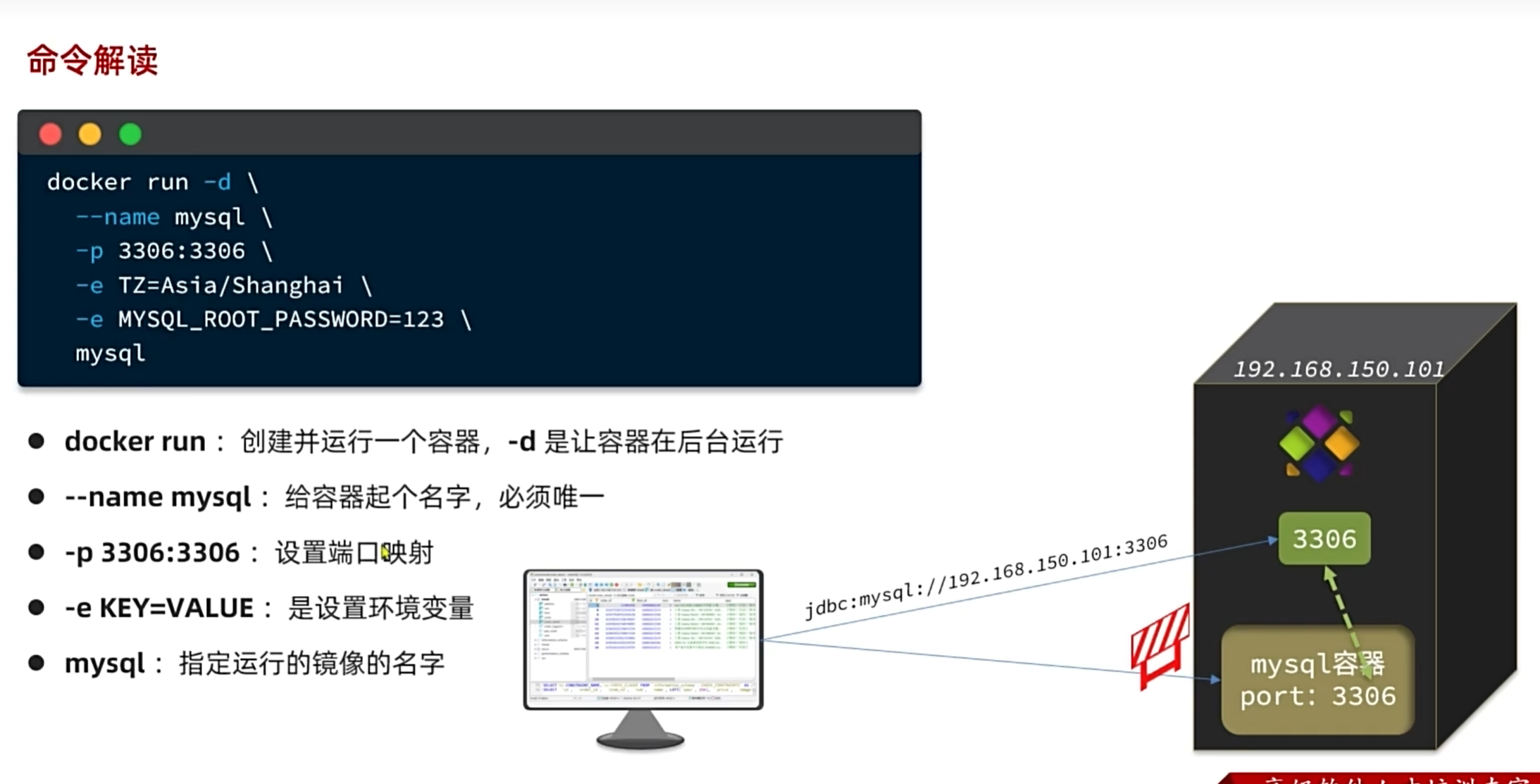
docker run是创建并运行一个容器,但可能会中途停止,-d是让容器一直运行
--name是给容器指定一个名字,以后去操作容器的时候就是根据名字来的,这个名字是这里我们自己起的名字
-p 3306:3306前一个端口号是虚拟机自己的端口号,后面那个端口号是虚拟机内部给mysql容器分配的端口号,不同的容器前面的3306虚拟机端口号是不变的,后面的端口号会不同,因为虚拟机内部是隔离的,外部不能直接访问到内部的容器,只能通过虚拟机提供的端口号来访问虚拟机然后再访问容器
-e 是设置环境变量
TZ=Asia/Shanghai:设置容器时区为上海,避免 MySQL 时间与宿主机不一致。MYSQL_ROOT_PASSWORD=123:强制必填,用于初始化 MySQL 的 root 用户密码,是 MySQL 镜像的核心启动参数,无此参数容器会启动失败。
最后的mysql
指定运行的镜像名称,docker daemon 基于该镜像创建容器实例;本地无镜像时自动从镜像仓库拉取
以后操作容器时,--name指定要操作的容器,docker daemon找到对应容器之后会自己起个名字自己用
常见命令

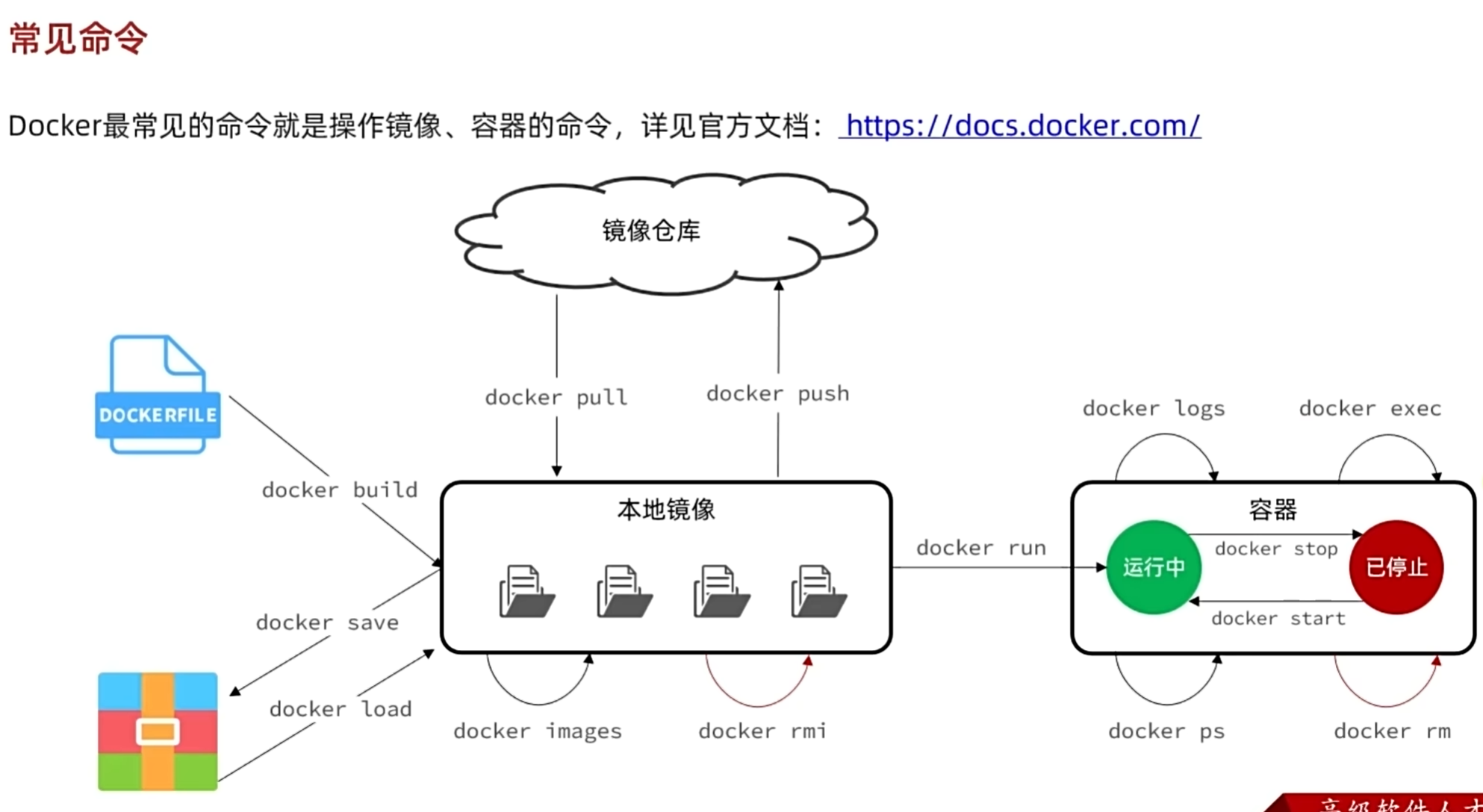
docker pull
去镜像仓库里面拉取镜像要用pull,可能会有必须输入的内容,这部分可以去docker hub网站上面去搜索要拉取的镜像名称来确认
docker image
镜像的英文翻译是image,要查看镜像使用这个命令就行
docker save -o nginx.tar nginx:latest
将镜像下载到本地镜像列表要用save命令,具体内容如下docker save -o nginx.tar nginx:latest意思是将nginx镜像的最新版本下载到本地的文件nginx.tar里面
docker load -i nginx
去本地镜像列表里可以下载镜像用load命令
忘了都可以用--help查看
容器操作
| 命令 | 作用 | 示例 (Nginx) |
|---|---|---|
| docker run -d --name nginx -p 8081:80 nginx | 启动并运行 Nginx 容器(推荐) | docker run -d --name nginx -p 8081:80 nginx |
| docker ps | 查看正在运行的容器 | docker ps |
| docker ps --all | 查看所有容器(包括停止的) | docker ps -a |
| docker start nginx | 启动已存在的 Nginx 容器 | docker start nginx |
| docker stop nginx | 安全停止 Nginx 容器 | docker stop nginx |
| docker restart nginx | 重启 Nginx 容器 | docker restart nginx |
| docker rm -f nginx | 强制删除 Nginx 容器(解决端口冲突用) | docker rm -f nginx |
| 软件 | 端口 | 启动命令 |
|---|---|---|
| Nginx | 8081 | 8081:80 |
| phpMyAdmin | 8080 | 8080:80 |
| MySQL | 3306 | 3306:3036 |
| 命令 | 作用 | 示例 (Nginx) |
|---|---|---|
| docker exec -it nginx /bin/bash | 进入 Nginx 容器终端 | docker exec -it nginx bash |
| exit | 退出容器,回到宿主机 | exit |
| 命令 | 作用 | 示例 (Nginx) |
|---|---|---|
| docker logs nginx | 查看 Nginx 日志 | docker logs nginx |
| docker logs -f nginx | 实时跟踪 Nginx 日志 | docker logs -f nginx |
数据卷
镜像就是最小化的系统,只给你准备必要的,最少的,运行所必需的,所以在容器内修改容器是非常困难的
在创建数据卷的时候,每创建一个数据卷就会对应宿主机文件系统里的一个文件
每一个数据卷里的都和宿主机里的文件有对应关系
在修改宿主机文件系统里面的文件时容器内的文件也会改变
Docker 挂载数据卷时
把宿主机的某个目录,直接映射进容器的文件系统树。
-
宿主机写 → 直接写硬盘
-
容器读 → 直接读硬盘
-
两边看到的是同一块物理存储空间
没有同步、没有传输、没有复制。改一个 = 改另一个。
为什么会这样?
因为容器本质不是虚拟机,容器是共享宿主机内核的进程。
它没有自己独立的硬盘,只能通过挂载方式,使用宿主机的真实文件。
最终一句话总结
宿主机和容器修改的是硬盘上同一份真实文件,所以一边改,另一边立刻变。