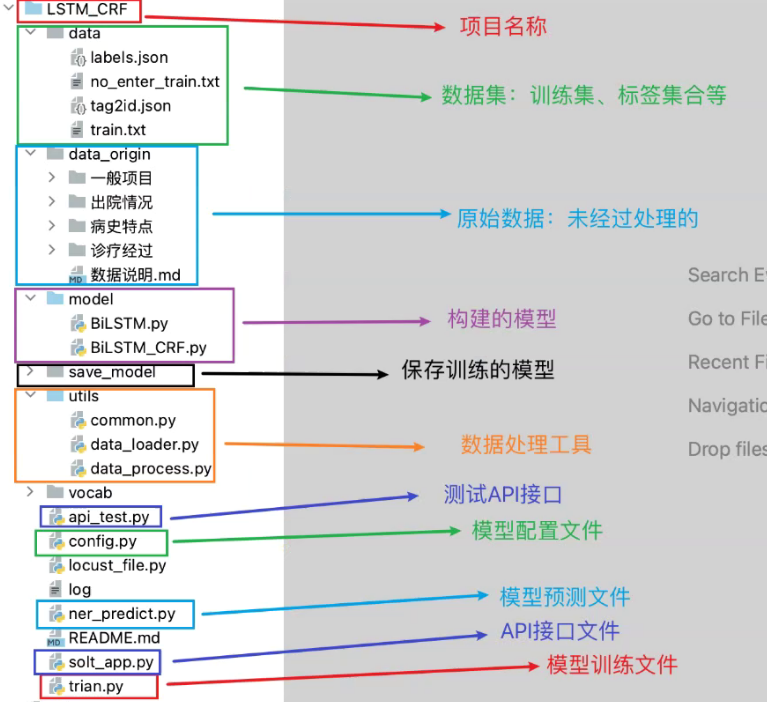
一、代码架构图
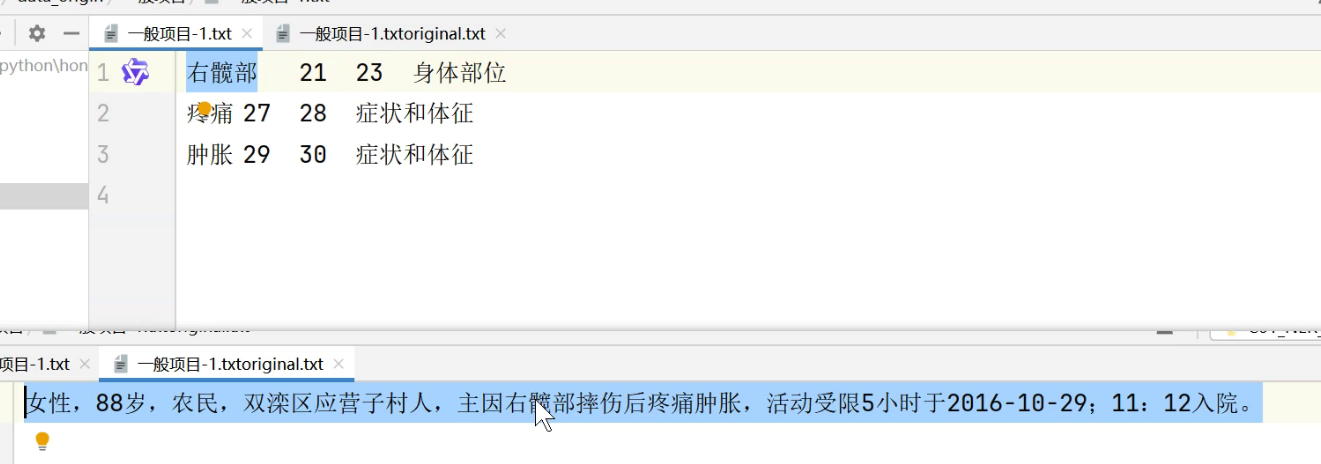
在data_origin中有两种类型的数据:分别是一般项目和一般项目txtoriginal
一般项目中放的是部位、症状、索引;列之间用制表符隔开
一般项目txtoriginal放的是原始数据;
二、构建序列标注数据
要把原始数据转换为目标数据:
常用的方式是构建字典,把索引作为键,把标签作为值。
可以使用标签类型字典把中文转换为英文
然后遍历索引(防止中间的索引被标记为O)可以判断是否是起始索引,若果是起始索引拼接B,不是起始索引拼接I

难点:
(1)获取到所有原始数据
通过os.Walk()遍历原始数据所在的文件夹,得到所有数据文件
(2)获取原始数据对应的标注数据
通过文件名称的特点,将原始数据文件名中的.txtoriginal替换成",就是对应的标注数据
三、BILSTM输入输出计算
BILSTM输入有三个元素分别是输入张量、隐藏状态、细胞状态;
BILSTM输出有三个元素分别是输出张量、最终隐藏状态、最终细胞状态;
无论是输入张量还是输出张亮,默认参数的顺序是(L【序列长度】,N(批次数),H(张量维度));
如果参数batch_first=True的时候,那么参数顺序是(N(批次数),L【序列长度】,H(张量维度)),这是我们常用的顺序;
输入参数:输入序列:(batch_size,seq_length,n_dim)batch_first=True
隐藏状态维度:hidden_size
隐藏状态:(D*num_lays,batch_size,hidden_size)
细胞状态:(D*num_lays,batch_size,hidden_size)
输出参数:
输出序列:(batch_size,seq_length,D*hidden_size)batch_first=True
隐藏状态:(D*num_lays,batch_size,hidden_size)
细胞状态:(D*num_lays,batch_size,hidden_size)
如果在输出层上面加一个线性层,那所有的输出参数最后一维的hidden变为线性层的维度
小结:
输入序列(批次,序列长度,序列维度)输出序列(批次,序列长度,输出维度(隐藏维度/自定义的线性维度))
细胞状态(层数*双向/单向,批次数,隐藏状态)细胞状态(层数*双向/单向,批次数,隐藏状态)
例如:输入序列8,50,128(batch_first=true),隐藏层维度100
那么隐藏状态是(D*1,8,100)
细胞状态为(D*1,8,100)
D的取值是看这个模型是双向模型还是单向模型,如果说是单向模型(比如:LSTM)那么D=1,如果是双向模型(比如BILSTM),那么D=2
num_lays指的是总共有多少个模型,如果整个系统只有一个BILSTM,那么num_lays=1,如果整个系统里面有两个BILSTM,那么num_lays=2
输出序列8,50,D\*100(batch_first=True)
隐藏状态是(D*1,8,100)
细胞状态是(D*1,8,100)

四、项目BILSTM应用
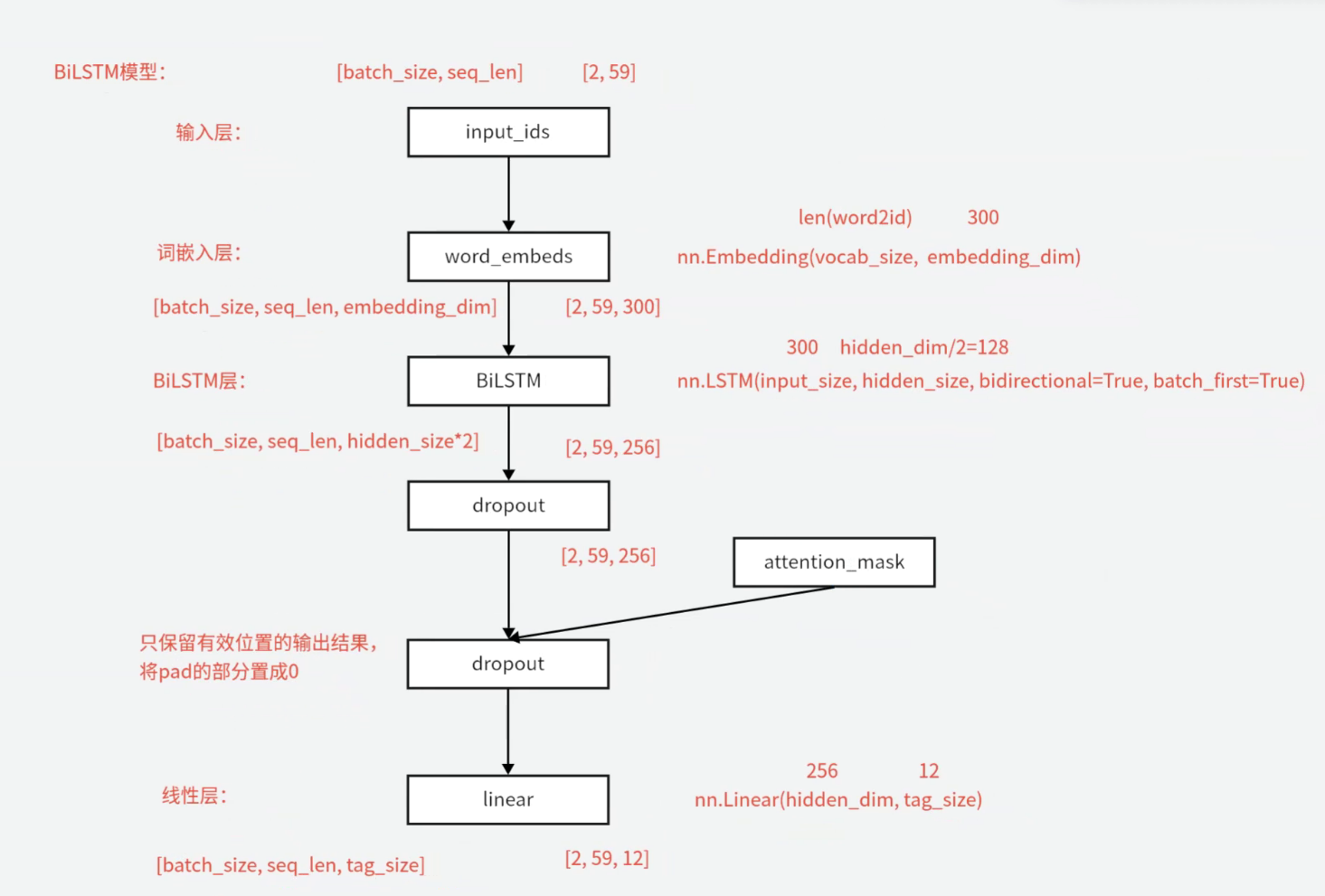
- 输入序列的批次和长度:batch_size,seq_length
- 向量层对输入序列进行向量化:batch_size,seq_length,embedding_dim
- 输入序列到BILSTM里面,BILSTM输出维度:batch_size,seq_length,hidden_size\*2(input_size,hidden_size,bidirectional=True,batch_first=True)
- BILSTM输出的维度是:隐藏层*D,所以真正的隐藏层维度是BILSTM输出维度/2
- 随机失活层:只保留有效未知的输出结果,无效部分的值转换为0
- attention_mask:因为输入序列长短不一,但是神经网络要求同一批次输入序列长度相同.这时候使用attention_mask可以防止神经网络看到这些补齐的padding,让神经网络只关注有用的信息(使用padding补齐序列是在数据预处理的时候完成的)
- 线性层:把输出维度转换为标签类型数
五、BILSTM实现NER
总共有五个超参需要设置:向量化维度、隐藏层维度、随机失活比例、字符数量、标签数量

import torch
import torch.nn as nn
class NERLSTM(nn.Module):
def __init__(self, embedding_dim, hidden_dim, dropout, word2id, tag2id):
super(NERLSTM, self).__init__()
self.name = "BiLSTM"
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.vocab_size = len(word2id)
self.tag_size = len(tag2id)
self.word_embeds = nn.Embedding(self.vocab_size, self.embedding_dim)
self.dropout = nn.Dropout(dropout)
self.lstm = nn.LSTM(self.embedding_dim, self.hidden_dim // 2,
bidirectional=True, batch_first=True)
self.hidden2tag = nn.Linear(self.hidden_dim, self.tag_size)
def forward(self, x, mask):
embedding = self.word_embeds(x)
outputs, hidden = self.lstm(embedding)
outputs = outputs * mask.unsqueeze(-1) # 仅保留有效位置的输出
outputs = self.dropout(outputs)
outputs = self.hidden2tag(outputs)
return outputs