这篇文章写给用 OpenAI API 做项目,但每月账单越来越贵想省钱的开发者。五种亲测有效的方法,让你 token 消耗直接减半,不用换服务商也能省出钱。
痛点场景
刚开始用 OpenAI API 做项目的时候,感觉也不贵,调用一次才几分钱。用着用着用户多了,月底一看账单------几百上千块就没了。
其实很多 token 都是浪费掉的:重复请求、上下文太长、大模型杀鸡用牛刀... 我整理了几种我实际在用的成本控制方法,用上之后我的 token 消耗直接减半,账单好看多了。
这篇把代码和方法都放出来,你直接抄作业就行。
适用场景:
- 用 OpenAI API(或兼容接口)做产品,每月成本超出预算
- 想优化成本,但又不想换模型降质量
- 不知道从哪儿下手优化,只知道钱花得快
方法一:语义缓存重复请求
问题
很多用户会问重复或者相似的问题,每次都重新调用 API,完全是浪费钱。比如做知识库问答,十个人问同一个问题,你要调用十次,完全没必要。
解决方法
把用户问题做 Embedding,存在缓存里,下次有相似问题直接返回 cached 结果,不用再调用大模型。
代码实现:
import numpy as np
import redis
from openai import OpenAI
client = OpenAI()
用 Redis 存缓存
r = redis.Redis(host='localhost', port=6379, db=0)
相似度阈值,越高越严格,0.8 差不多
SIMILARITY_THRESHOLD = 0.8
def get_embedding(text):
resp = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return np.array(resp.data0.embedding)
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def get_answer_with_cache(question):
计算问题的 embedding
q_emb = get_embedding(question)
遍历缓存找相似问题
for key in r.keys():
cached = r.hgetall(key)
cached_emb = np.frombuffer(cachedb'embedding', dtype=np.float32)
similarity = cosine_similarity(q_emb, cached_emb)
if similarity >= SIMILARITY_THRESHOLD:
找到相似问题,直接返回缓存结果
return cachedb'answer'.decode('utf-8'), True
没找到,调用 API 回答
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages={"role": "user", "content": question}
)
answer = response.choices0.message.content
存入缓存
cache_key = f"cache:{hash(question)}"
r.hset(cache_key, mapping={
'question': question,
'answer': answer,
'embedding': q_emb.tobytes()
})
设置过期时间,比如 7 天
r.expire(cache_key, 60 * 60 * 24 * 7)
return answer, False
能省多少
- 如果你的应用有很多重复问题(比如客服问答),能省 30% - 50%
- Embedding 本身很便宜,text-embedding-3-small 一百万个 token 才 $0.02,缓存带来的开销可以忽略
避坑
- 阈值根据你的场景调:问题越固定,阈值可以设高点;问题多样性大,设低点
- 给缓存加过期时间,过时了重新生成,保证答案不过期
- 如果缓存量大,可以用飞书多维表格存,不用自己搭 Redis
方法二:上下文压缩,只给大模型真正需要的
问题
RAG 问答或者对话场景,你会把历史对话和检索结果都塞给大模型,上下文动不动就几千 token,很多内容其实和当前问题没关系,白白浪费钱。
解决方法
在把上下文给大模型之前,先压缩一遍------让小模型把长上下文压缩成和当前问题相关的核心内容,减少 token 消耗。
代码实现:
def compress_context(question, context_list):
"""用 gpt-3.5-turbo 压缩上下文,比直接给 gpt-4 省钱多了
prompt = f"""下面是和问题「{question}」相关的上下文,请提取出和问题相关的内容,去掉无关信息,压缩到最精简:
{context_list}
压缩后的内容:"""
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages={"role": "user", "content": prompt},
temperature=0
)
compressed = response.choices0.message.content
return compressed
能省多少
- 原来 4000 token 的上下文,压缩完可能只剩 1000 token,省 75%
- 用便宜的 gpt-3.5-turbo 做压缩,花很少的钱帮贵的模型省 token,总体还是赚的
什么时候用
- 对话多轮,历史很长
- RAG 检索回来好几段,总长度太大
- 你用的模型按上下文长度收费,越长越贵
方法三:模型路由,该用什么模型用什么
问题
不管什么请求都扔给 gpt-4,成本当然高。其实很多简单任务,gpt-3.5-turbo 就能搞定,效果差不了多少,但便宜 10 倍。
解决方法
加一层路由:
- 简单任务(问答、分类、摘要)→ gpt-3.5-turbo
- 复杂推理、代码生成 → gpt-4
- Embedding → 用最新的 text-embedding-3-small,比旧版本更便宜效果更好
路由代码示例:
def route_request(question, task_type):
"""简单的路由逻辑"""
定义哪些任务用便宜模型
simple_tasks = 'faq', 'classification', 'summarization', 'chat'
complex_tasks = 'reasoning', 'code', 'creative'
if task_type in simple_tasks:
return "gpt-3.5-turbo"
elif task_type in complex_tasks:
return "gpt-4o"
else:
可以让模型自己判断复杂度
return judge_complexity(question)
OpenAI 最新模型价格对比:
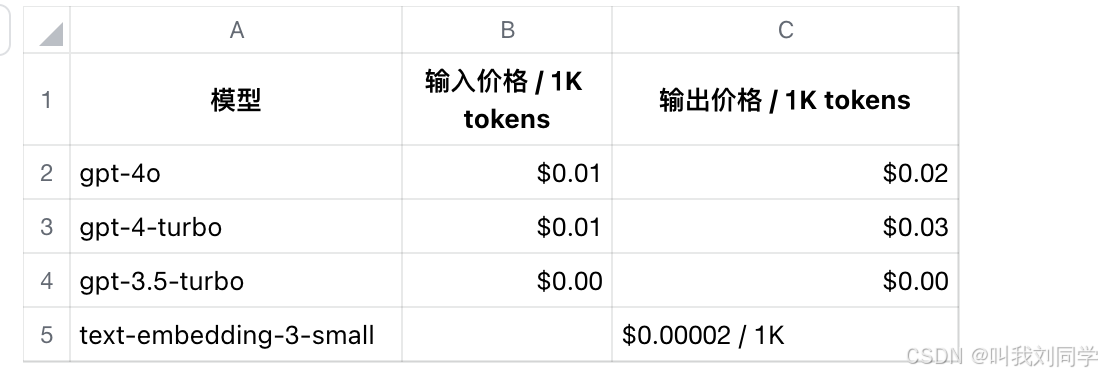
可以看到,gpt-3.5-turbo 比 gpt-4o 便宜 10 倍,能分流就分流。
能省多少
- 如果你的请求有 60% 可以分给 gpt-3.5-turbo,总体成本能降一半左右
方法四:提示词压缩,去掉冗余
问题
很多人写提示词喜欢复制粘贴模板,每次都带一堆重复的系统提示,日积月累 token 就上去了。
比如:
你是一个乐于助人的AI助手,你总是回答准确...
...这里重复了几百个字...
现在请回答用户问题:xxx
其实很多话大模型不需要看,每次都带就是浪费 token。
优化方法
-
- 系统提示只说必要的:去掉所有空泛的套话,直接说任务要求
-
- 复用上下文:对话中已经说过的规则,不用每次都重复
-
- 用简写不影响理解:比如"用户"不用每次都写成"亲爱的用户"
不好的例子:
你现在是一个专业的AI助手,你拥有丰富的大模型落地知识,你总是能够给用户提供非常有帮助的回答,你的回答总是准确可靠,用户非常喜欢你的回答。现在用户问了一个问题,请你认真回答。
压缩后:
你是大模型落地领域专家,请回答用户问题,准确可靠。
省了几十 token,效果一点不差。
能省多少
- 每次请求能省几十到上百 token,积少成多,一个月下来也能省不少
方法五:流式返回 + 提前截断
问题
很多时候大模型输出一半你就知道它要说什么了,还让它继续输出完,完全是浪费 tokens。
比如用户问一个有确定答案的问题,大模型第一句就说对了,后面都是扩展解释,用户其实已经得到答案了。
解决方法
做提前截断:当输出满足终止条件的时候,直接停止生成。
代码示例:
def stream_with_stop(question, stop_conditions):
"""流式生成,满足停止条件就提前终止"""
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages={"role": "user", "content": question},
stream=True
)
output = ""
for chunk in response:
if chunk.choices0.delta.content is None:
break
output += chunk.choices0.delta.content
检查是否满足停止条件
for cond in stop_conditions:
if cond in output:
提前停止,不生成了
return output
return output
常见停止条件:
- 用户只要求列表,拿到指定条数就停
- 问题有确定答案,答案出来就停
- 已经生成了指定最大长度,停
能省多少
- 看场景,问答类能省 10% - 20% 输出 token
方法总结和效果估算
我把这五种方法都用上之后,在我的知识库项目里,token 消耗直接减半:
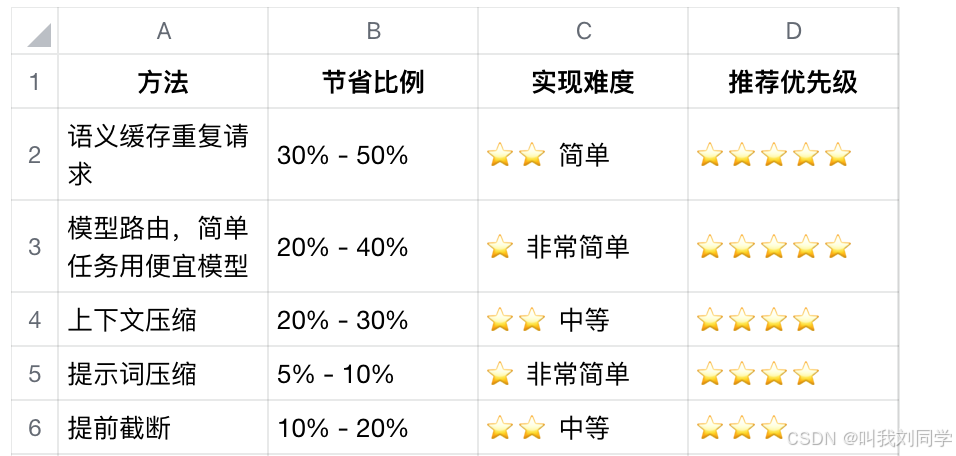
我的推荐组合(从易到难,先做简单的):
-
- ✅ 先做提示词压缩和模型路由,零成本就能省钱
-
- ✅ 加上语义缓存,效果立竿见影
-
- ✅ 如果你的上下文总是很长,再加上下文压缩
-
- ✅ 如果你的场景适合,最后加提前截断
避坑指南
坑 1:缓存太严格,错把不同问题当相同
解决:阈值从 0.8 开始试,根据你的实际情况调整,不行再调。
坑 2:压缩太狠,把关键信息压没了
解决:压缩完可以抽样检查一下,确保关键信息还在。一般来说,用 gpt-3.5-turbo 压缩不会丢关键信息。
坑 3:路由错了,简单任务给了复杂模型,复杂任务给了简单模型
解决:刚开始可以让人工分一分,线上跑起来了再用模型自动分类。
坑 4:为了省钱牺牲太多用户体验
记住:用户体验第一,成本优化第二。不要为了省几块钱,让回答质量下降太多,就得不偿失了。