前言
在互联网高并发业务架构中,缓存是提升系统吞吐量、降低数据库IO压力、优化接口响应耗时的核心基础设施。绝大多数业务系统均采用「数据库 + 缓存」的读写架构,通过缓存承接海量读请求,规避频繁查询数据库的性能瓶颈。
但缓存并非无懈可击,不合理的缓存使用策略,反而会引发流量击穿、服务瘫痪、数据错乱等严重线上事故。其中,缓存预热、缓存穿透、缓存雪崩、缓存数据不一致是高并发场景下最经典、最高频、最需要落地解决的四大核心问题。
一、缓存预热
1. 问题描述
缓存预热,是指系统启动、缓存清空、缓存批量失效后,主动将热点数据提前加载至缓存的技术手段。
若未做预热,系统重启或缓存清空后,Redis 缓存整体为空,海量用户请求无法命中缓存,全部直接穿透到数据库,短时间内数据库 QPS 飙升、连接数打满,极易引发数据库卡顿、超时甚至宕机,造成服务不可用。
简单概括:空缓存承接不了流量,全量流量裸打数据库。

2. 核心成因
-
服务重启、容器重建、Redis 重启清空数据,导致缓存全局为空;
-
大量热点缓存 key 过期时间集中,同一时间批量失效;
-
新功能上线、数据重置后,缓存无初始化数据;
-
高并发场景下,冷缓存无法瞬时承接海量流量。
3. 生产级解决方案(由浅入深)
(1)手动脚本预热(轻量化方案)
系统上线前,通过后台接口、Shell 脚本、运维平台手动触发热点数据加载,将首页、热门商品、系统配置、高频字典等固定热点数据提前写入 Redis。
优点:零代码侵入、无需开发、操作简单;
缺点:依赖人工操作,容易遗漏,无法自动化;
适用场景:小型项目、低频发布、静态配置类数据。
(2)项目启动自动预热(主流通用方案)
基于 Spring 提供的 ApplicationRunner / CommandLineRunner 启动钩子,在服务启动完成、流量接入之前,自动执行热点数据查询与缓存写入逻辑,完成缓存初始化。
优点:全自动化、无需人工干预、上线即就绪;
缺点:服务集群多实例部署时,需控制重复预热,避免频繁刷缓存;
适用场景:绝大多数互联网业务、中小型高并发系统。
(3)定时预热 + 增量更新(高稳定方案)
通过定时任务定时刷新全量热点缓存,同时监听业务数据变更(MQ/数据库binlog),实现数据增量更新缓存。既解决启动冷缓存问题,又避免热点缓存长期不更新导致的数据过期失效。
优点:兼顾实时性与稳定性,杜绝缓存长期失效;
缺点:开发复杂度稍高,需要监听数据变更;
适用场景:电商首页、热门榜单、活动数据等高频变更热点业务。
(4)灰度流量预热(大厂高并发方案)
服务重启上线后,不直接放开全量流量,先放行少量灰度流量,通过用户真实请求自动触发缓存加载,待核心热点缓存全部预热完成后,再逐步放开全量流量。
优点:完美规避启动瞬间流量冲击,零数据库压力峰值;
适用场景:超大流量核心服务、秒杀、首页流量等高并发核心场景。
二、缓存穿透
1. 问题描述
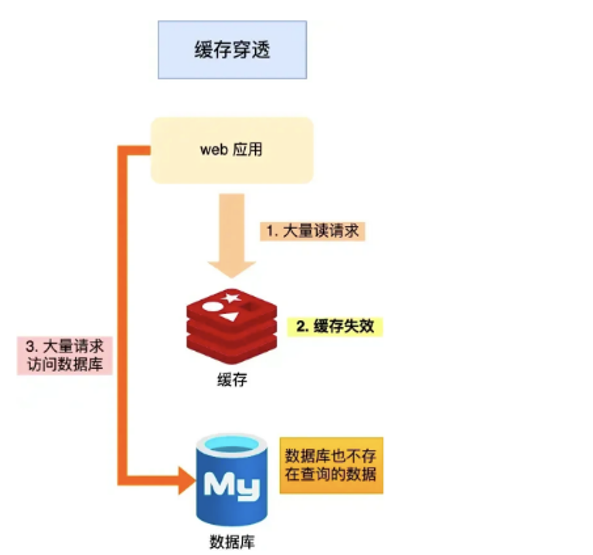
缓存穿透是指:请求的数据在缓存、数据库中均不存在,导致该请求永远无法命中缓存,每次都会直接穿透到数据库查询。
正常缓存流程:请求 → 缓存命中直接返回;未命中 → 查询数据库 → 回写缓存。
穿透流程:请求 → 缓存无数据 → 查询数据库无数据 → 不写缓存 → 下次请求继续查库。
核心风险:恶意攻击者可通过随机ID、非法参数批量刷接口,持续打穿缓存,压垮数据库,引发系统瘫痪。
2. 核心成因
-
业务存在大量不存在的无效查询请求;
-
恶意攻击、爬虫批量请求非法 key;
-
缓存只缓存有效数据,空数据不落地,导致永久穿透。
3. 落地解决方案
(1)接口参数校验(基础兜底)
在网关/接口层统一拦截非法请求:拦截负数ID、空参数、超长参数、非法格式参数,从源头杜绝无效请求。所有业务系统必备第一层防护。
(2)缓存空值/默认值(简单高效)
当数据库查询不到数据时,依然向缓存写入空值、空对象或默认值,并设置较短过期时间(30s~5min)。
后续相同请求直接命中缓存,不再查询数据库,彻底解决重复穿透问题。
优点:实现简单、无业务侵入、防护有效;
缺点:会占用少量缓存内存,需控制过期时间,避免大量无效 key 堆积。
(3)布隆过滤器拦截(高并发优选)
布隆过滤器是高并发场景下解决缓存穿透的最优方案,核心原理:先判断存在性,再放行请求。
写入逻辑:数据入库时,将数据 key 通过多个哈希函数映射到位数组,标记对应下标为1;
查询逻辑:请求到来先校验布隆过滤器:
-
若判定不存在 → 数据库一定无数据,直接返回,无需查缓存、查库;
-
若判定存在 → 可能存在,正常走缓存+数据库查询流程。
优点:内存占用极小、拦截效率极高、可抵御大规模恶意攻击;
缺点:存在极小概率误判、不支持精准删除,需定时重建;
适用场景:用户ID、商品ID等固定主键查询场景。
三、缓存雪崩
1. 问题描述
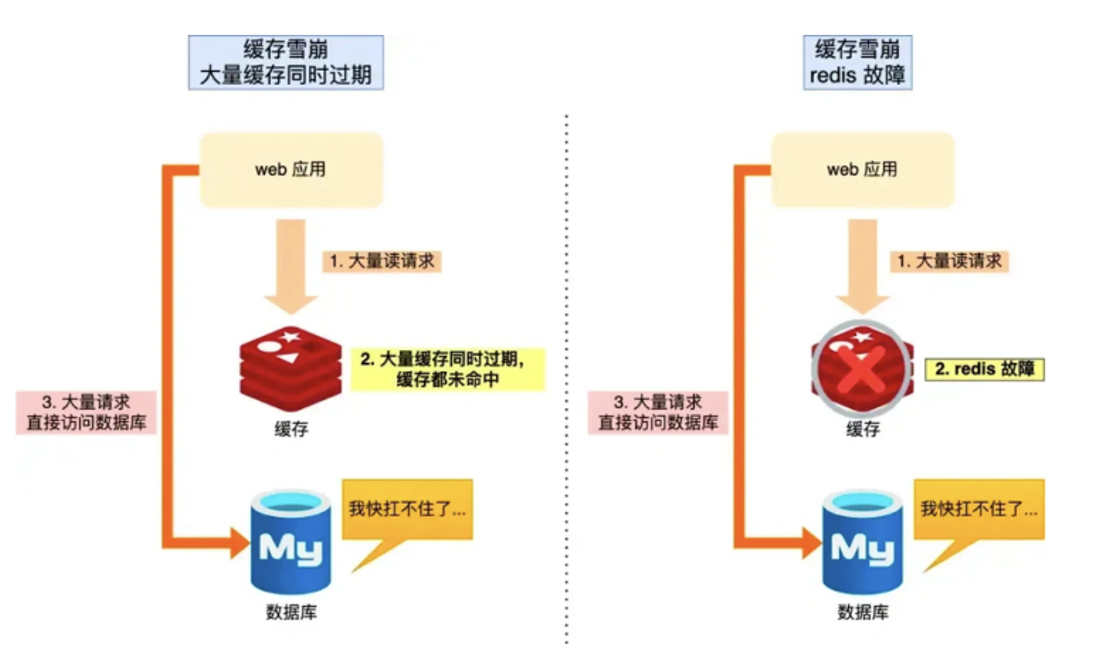
缓存雪崩是指:大量热点缓存 key 在同一时刻批量失效,或 Redis 集群整体宕机,导致海量流量瞬间失去缓存承接,全部直接涌向数据库,超出数据库最大承载阈值,引发数据库 CPU、连接数打满,服务雪崩式瘫痪。
与缓存穿透核心区别:
-
穿透:查「不存在的数据」,单次请求均打库;
-
雪崩:查「存在的数据」,缓存集体失效导致流量集中击穿。
2. 核心成因
-
批量缓存 key 设置相同过期时间,集中过期;
-
Redis 宕机、集群故障、主从切换,缓存整体不可用;
-
热点缓存大批量同时失效,无兜底方案。
3. 生产级解决方案
(1)过期时间随机偏移(最通用)
在固定过期时间基础上,增加随机时间偏移。例如预设过期1小时,再随机增减 1~10 分钟,打散缓存过期时间,杜绝批量 key 同时失效。
成本极低、效果显著,是所有业务的基础防护方案。
(2)热点数据逻辑永不过期
针对核心热点数据,取消主动过期策略,设置逻辑永不过期。通过后台定时任务、数据变更监听主动更新缓存,不依赖 Redis 自动过期淘汰。
同时配合分布式互斥锁,保证缓存失效瞬间,同一时间只有一个线程更新缓存,避免并发击穿数据库。
(3)多级缓存架构(高可用终极方案)
搭建「本地缓存(Caffeine/Guava) + 分布式缓存(Redis)」多级缓存架构。
即使 Redis 宕机或批量失效,本地内存缓存依然可以承接流量,杜绝全量流量直打数据库,极大提升系统容灾能力。
四、缓存与数据库数据不一致
1. 问题描述
在「数据库+缓存」架构中,数据库更新和缓存更新是两个独立操作,不具备原子性。任意一步执行失败、或多线程执行顺序错乱,都会导致缓存数据与数据库数据不统一,出现脏数据,引发商品价格错误、订单状态异常、用户信息滞后等线上业务bug。
2. 两种更新策略优缺点与问题分析
(1)先更新缓存,再更新数据库(不推荐)
执行流程:更新Redis缓存 → 更新MySQL数据库
正常结果:缓存、数据库均更新成功,数据一致。
异常致命问题:Redis更新成功,MySQL更新失败。
Redis 不支持事务回滚,已更新的缓存新值无法撤销,数据库保留旧数据,会产生永久脏数据,直到缓存过期淘汰。
优化方案:
-
设置短TTL,缩小脏数据存活时间;
-
数据库失败后定时重试同步;
-
MQ异步兜底,保障数据库最终更新成功。
结论:该策略一致性差,生产环境基本不使用。
(2)先更新数据库,再更新缓存(业界主流)
执行流程:更新MySQL数据库 → 更新Redis缓存
异常场景一:数据库成功、缓存更新失败
可通过事务回滚、MQ重试兜底解决,数据可保证最终一致。
异常场景二:多线程并发颠倒,产生永久脏数据
线程A更新旧值、线程B更新新值,因网络/CPU调度问题,A后更新缓存、B先更新缓存,最终缓存被旧值覆盖,出现永久性脏数据。
3. 最终一致性落地解决方案
(1)全局TTL过期兜底(通用必备)
所有缓存强制设置过期时间,即使出现并发覆盖产生脏数据,缓存过期后,读请求会自动查询数据库刷新缓存,实现最终数据一致性,是所有业务的基础兜底方案。
(2)数据库行锁 + RR隔离级别(低频更新)
利用MySQL可重复读隔离级别+行级锁,锁住更新数据行,同一时间只允许一个线程更新该行数据,串行化写操作,从源头杜绝并发顺序颠倒问题。
缺点:高并发场景锁竞争激烈,吞吐量下降,仅适用于低频更新业务。
(3)MQ异步更新缓存(高并发最优解)
数据库事务提交成功后,发送可靠消息至MQ,由消费者异步执行缓存更新操作。
核心优势:
-
缓存操作异步化,不阻塞主业务流程,提升接口性能;
-
依靠MQ重试机制,彻底解决缓存更新失败问题;
-
保证数据库与缓存最终数据一致。
五、全文总结
-
缓存预热解决「冷缓存流量冲击数据库」问题,通过自动化、灰度流量、定时刷新实现系统平稳启动;
-
缓存穿透针对「不存在的数据恶意请求」,参数校验、空值缓存、布隆过滤器三层防护层层兜底;
3.缓存雪崩解决「缓存批量失效/宕机流量击穿」,通过时间打散、永不过期、多级缓存实现高可用;
- 数据不一致核心是「库、缓存操作无原子性」,优先采用先更新库、异步更缓存策略,配合TTL、MQ实现最终一致性。
四大缓存问题是高并发架构的基础核心,合理搭配对应方案,可彻底解决99%的缓存线上故障,保障系统高可用、高并发、数据一致。