在 Java 集合框架中,TreeSet 是基于红黑树实现的有序、不重复集合,它不仅能保证元素无重复,还能按照指定规则对元素进行排序,是处理有序唯一元素场景的核心工具。
一、TreeSet 基础定义
TreeSet 是 java.util 包下的实现类,核心特性:
- 元素唯一性:不允许存储重复元素(通过比较器判断重复,而非 equals 方法);
- 有序性 :元素会按照自然排序 (如 Integer 升序、String 字典序)或自定义排序规则排列;
- 非线程安全 :多线程并发操作时需手动加锁,或使用
Collections.synchronizedSortedSet包装; - 不允许 null 元素 :JDK 8 及以后,TreeSet 存储 null 会抛出
NullPointerException(排序时无法比较 null); - 底层数据结构 :红黑树(自平衡二叉查找树),保证增删改查的时间复杂度为 O(logn)。
二、TreeSet 继承与实现关系
TreeSet 的继承体系清晰体现了其功能定位,完整层级关系如下:
html
java.lang.Object
↳ java.util.AbstractCollection<E>
↳ java.util.AbstractSet<E>
↳ java.util.TreeSet<E>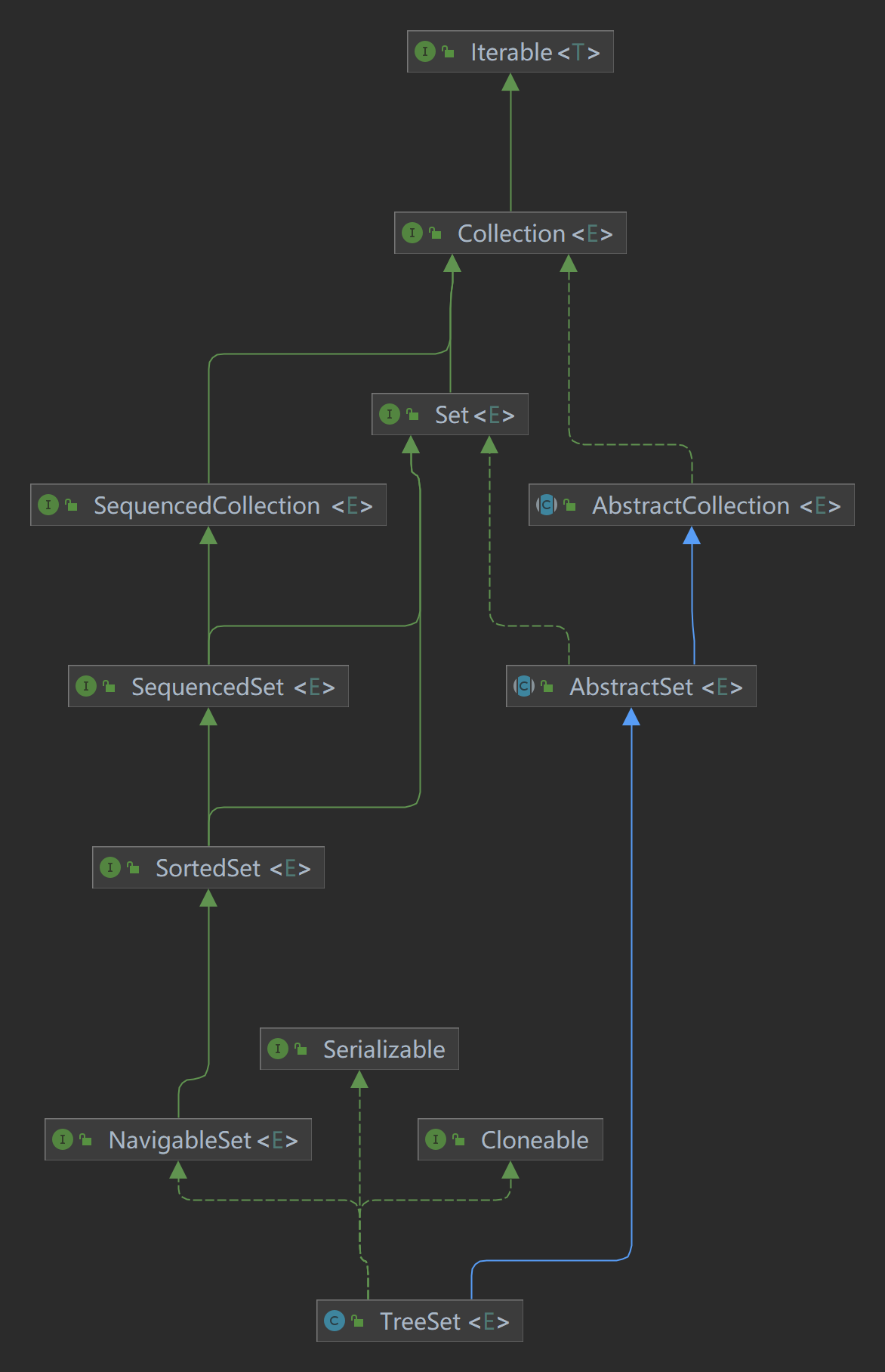
核心接口实现:
NavigableSet<E>:提供导航性方法(如获取小于 / 大于某个元素的节点、逆序遍历等);SortedSet<E>:保证集合元素有序,支持获取子集、首尾元素等有序操作;Cloneable:支持克隆;Serializable:支持序列化。
简化理解 :TreeSet = 有序 + 无重复 + 导航功能的集合,所有有序特性依赖 NavigableSet 和 SortedSet 接口。
三、TreeSet 源码深度解析(JDK 8)
TreeSet 是装饰者模式 的典型应用,底层没有自己的数据结构 ,完全基于 TreeMap 实现(所有核心操作都委托给 TreeMap)。这是理解 TreeSet 源码的核心突破口。
1. 核心成员变量
java
public class TreeSet<E> extends AbstractSet<E>
implements NavigableSet<E>, Cloneable, java.io.Serializable
{
// 底层存储:TreeSet 的所有元素都存在 TreeMap 的 key 中
private transient NavigableMap<E,Object> m;
// 固定的默认值:TreeMap 的 value 是无意义的占位符,所有元素共享此对象
private static final Object PRESENT = new Object();
// 序列化版本号
private static final long serialVersionUID = -2479143000642829578L;
}结论:
- TreeSet 本质是TreeMap 的 key 集合 ,value 统一为
PRESENT静态对象; - TreeMap 底层是红黑树,因此 TreeSet 天然继承了红黑树的有序、自平衡特性。
2. 核心构造方法
TreeSet 提供 5 种构造方法,核心都是初始化底层的 TreeMap:
java
// 1. 无参构造:使用自然排序,底层创建 TreeMap
public TreeSet() {
this(new TreeMap<E,Object>());
}
// 2. 带比较器构造:自定义排序规则
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
// 3. 集合参数构造:将指定集合转为 TreeSet,自然排序
public TreeSet(Collection<? extends E> c) {
this();
addAll(c);
}
// 4. SortedSet参数构造:复用已有排序规则
public TreeSet(SortedSet<E> s) {
this(s.comparator());
addAll(s);
}
// 5. 包访问权限构造:直接传入 NavigableMap(供内部使用)
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}核心逻辑 :所有构造方法最终都是为了初始化底层的 NavigableMap(实际为 TreeMap)。
3. 核心增删改查方法
TreeSet 的所有方法都是调用 TreeMap 的对应方法,源码极其简洁:
(1)add (E e):添加元素
java
public boolean add(E e) {
// 调用 TreeMap 的 put 方法,key=元素,value=固定的 PRESENT
return m.put(e, PRESENT) == null;
}原理:
- TreeMap 的 put 会将元素插入红黑树,并自动平衡树结构;
- 若元素已存在(比较器判定重复),put 返回旧值,add 返回 false(保证元素唯一);
- 若元素不存在,put 返回 null,add 返回 true(插入成功)。
(2)remove (Object o):删除元素
java
public boolean remove(Object o) {
// 调用 TreeMap 的 remove 方法,返回旧值
return m.remove(o) == PRESENT;
}原理:删除红黑树中的节点,自动调整树平衡;若元素存在,删除成功返回 true,否则返回 false。
(3)contains (Object o):判断元素是否存在
java
public boolean contains(Object o) {
// 调用 TreeMap 的 containsKey
return m.containsKey(o);
}(4)size()/isEmpty()/clear()
java
public int size() { return m.size(); }
public boolean isEmpty() { return m.isEmpty(); }
public void clear() { m.clear(); }全部委托 TreeMap 实现,无任何自定义逻辑。
4. 排序核心:比较器
TreeSet 判断元素是否重复 和排序规则 ,完全依赖比较器,而非 equals/hashCode:
- 自然排序 :元素实现
Comparable接口,重写compareTo方法(如 Integer、String 默认实现); - 自定义排序 :创建 TreeSet 时传入
Comparator接口实现,重写compare方法。
源码关联:TreeMap 的 put/get 操作会调用比较器的 compare 方法,若返回 0,判定为重复元素。
四、TreeSet 内部方法(有序 / 导航方法)
作为 NavigableSet 实现类,TreeSet 提供了大量有序导航方法,这是 HashSet 不具备的核心能力:
first():获取集合第一个元素(最小元素);last():获取集合最后一个元素(最大元素);lower(E e):获取小于 e 的最大元素;higher(E e):获取大于 e 的最小元素;floor(E e):获取小于等于 e 的最大元素;ceiling(E e):获取大于等于 e 的最小元素;subSet(E from, boolean fromInclusive, E to, boolean toInclusive):获取指定范围的子集;headSet(E to, boolean inclusive):获取小于 to 的子集;tailSet(E from, boolean inclusive):获取大于 from 的子集。
这些方法底层均调用 TreeMap 的对应导航方法,时间复杂度 O(logn)。
五、TreeSet 迭代器实现
TreeSet 的迭代器基于红黑树的中序遍历实现,保证遍历顺序与排序顺序一致。
1. 获取迭代器
java
public Iterator<E> iterator() {
// 调用 TreeMap 的 keySet 迭代器
return m.navigableKeySet().iterator();
}2. 迭代器特性
- 有序遍历 :中序遍历红黑树,输出升序排序结果(自然排序 / 自定义排序);
- 快速失败(Fail-Fast) :迭代过程中若修改集合(add/remove),会抛出
ConcurrentModificationException; - 支持逆序迭代 :通过
descendingIterator()获取逆序迭代器,遍历降序元素。
核心原理:红黑树的中序遍历规则 = 左子树 → 根节点 → 右子树,天然保证有序输出。
六、TreeSet 与 HashSet 核心对比
两者都是 Set 接口实现类,核心区别源于底层数据结构,详细对比:
| 特性 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希表(数组 + 链表 + 红黑树) |
| 元素顺序 | 有序(自然 / 自定义排序) | 无序(JDK 8 后遍历顺序固定,但无排序意义) |
| 重复判断 | 比较器(compare/compareTo 返回 0) | equals() + hashCode() |
| 元素要求 | 必须实现 Comparable / 传入比较器 | 无强制要求(建议重写 equals/hashCode) |
| 时间复杂度 | 增删改查:O(logn) | 增删改查:O(1)(哈希冲突少) |
| null 元素 | 不允许 | 允许存储 1 个 null |
| 性能 | 较低(红黑树自平衡开销) | 较高(哈希寻址效率高) |
| 适用场景 | 需排序、去重的有序场景 | 仅需去重、追求高性能场景 |
一句话总结:需要有序选 TreeSet,追求性能选 HashSet。
七、TreeSet 面试高频知识点
1. TreeSet 如何保证元素有序?
底层基于红黑树实现,插入元素时通过比较器(Comparable/Comparator) 确定元素在红黑树中的位置,迭代时通过中序遍历红黑树,保证输出有序。
2. TreeSet 如何判断元素重复?
不是通过 equals 方法 ,而是通过比较器的 compareTo 或 compare 方法:若返回 0,判定为重复元素,拒绝插入。
3. 为什么 TreeSet 不允许存储 null?
TreeSet 插入元素时会调用比较器进行排序,null 无法参与比较,JDK 8 及以后会直接抛出 NullPointerException。
4. TreeSet 与 TreeMap 的关系?
TreeSet 是 TreeMap 的包装类,TreeSet 所有元素存储在 TreeMap 的 key 中,value 为固定静态对象,所有核心操作委托 TreeMap 实现。
5. TreeSet 迭代时为什么会报并发修改异常?
TreeSet 迭代器采用快速失败机制 ,迭代过程中会检测 modCount(修改次数),若集合被修改,modCount 变化,立即抛出异常,避免遍历数据不一致。
6. 自然排序 vs 自定义排序优先级?
自定义排序(Comparator)优先级高于自然排序(Comparable):若创建 TreeSet 时传入 Comparator,优先使用自定义比较器,否则使用元素的 Comparable 接口。
7. TreeSet 是线程安全的吗?
不是。多线程环境下,推荐使用 java.util.concurrent.ConcurrentSkipListSet(线程安全的有序集合),或用 Collections.synchronizedSortedSet 包装。
八、总结
- TreeSet 是基于 TreeMap(红黑树) 实现的有序、无重复集合,核心是红黑树的自平衡和排序特性;
- 所有操作委托 TreeMap 实现,判断重复依赖比较器,而非 equals/hashCode;
- 适合需要排序 + 去重的场景,性能低于 HashSet,但具备强大的有序导航能力;
- 面试核心考点:底层结构、重复判断、排序规则、与 HashSet/TreeMap 的区别、并发安全。
掌握 TreeSet 的核心,本质是掌握红黑树 和比较器的原理,这也是理解 Java 有序集合的关键。