1. 引言:边缘AI的新纪元
视觉语言模型(Vision-Language Models, VLMs)代表了人工智能领域的重大突破,它将计算机视觉与自然语言处理深度融合,使机器能够像人类一样理解图像内容并用自然语言进行描述和推理。与传统的图像分类模型不同,VLMs不再局限于预定义的标签集合,而是通过联合嵌入空间(joint embedding space)将视觉特征与语义信息映射到同一表示空间,从而实现对开放域场景的理解和交互。这种能力使得VLMs在机器人导航、工业质检、智能监控等实际应用场景中展现出巨大潜力。
随着模型压缩技术和推理优化算法的快速发展,大规模VLMs已经可以在边缘设备上高效运行。NVIDIA Jetson系列作为专为物理AI和机器人应用设计的边缘计算平台,从高性能的AGX Thor、AGX Orin到紧凑型的Orin Nano Super,提供了完整的算力梯度选择。其中,Jetson AGX Thor作为最新一代旗舰产品,搭载了更强大的GPU架构和更大的内存容量,为部署大规模AI模型提供了理想的硬件基础。本文将详细介绍如何在Jetson AGX Thor上部署NVIDIA Cosmos Reason 2B模型,并通过实时Web界面实现交互式视觉推理应用。
2. NVIDIA Cosmos Reason 2B模型架构解析
2.1 模型核心技术特性
NVIDIA Cosmos Reason 2B是一个专为边缘设备优化的轻量级视觉语言模型,其"2B"表示模型包含约20亿参数。该模型采用了多模态Transformer架构,通过视觉编码器(Vision Encoder)提取图像特征,再通过交叉注意力机制(Cross-Attention)将视觉信息与语言模型融合。与传统VLMs相比,Cosmos Reason 2B的核心创新在于引入了链式思维推理(Chain-of-Thought Reasoning)能力,模型在生成最终答案前会先输出中间推理步骤,这使得其推理过程更加透明和可靠。
2.2 FP8量化技术深度解析
在量化技术方面,本教程使用的是FP8(8位浮点)量化版本。FP8量化相比传统的INT8量化具有更好的数值表示范围,能够在保持模型精度的同时将模型大小压缩至原始FP16版本的一半左右,显著降低内存占用和推理延迟。对于Jetson AGX Thor这类内存受限的边缘设备,FP8量化是实现大模型部署的关键技术。此外,模型还采用了静态KV缓存(static-kv8)优化,通过预分配键值对缓存空间,避免了推理过程中的动态内存分配开销,进一步提升了推理效率。
3. 系统环境准备与硬件要求
3.1 系统环境安装
在开始部署之前,需要确保硬件和软件环境满足以下要求。Jetson AGX Thor开发者套件需要运行JetPack 7(基于L4T r38.x内核),这是NVIDIA专为Thor平台优化的系统镜像,包含了CUDA 12.6、cuDNN 9.x等深度学习框架的最新版本。存储方面,强烈建议使用NVMe SSD作为系统盘,因为模型权重文件约占5GB空间,vLLM容器镜像约8GB,加上运行时的缓存和日志文件,至少需要预留20GB以上的可用空间。相比传统的SD卡或eMMC存储,NVMe SSD的读写速度可达数GB/s,能够显著缩短模型加载时间和推理响应延迟。
3.1.1 安装SDK Manager
前往下面的网址,下载适合自己电脑架构的SDK Manager安装包并安装:
https://developer.nvidia.com/sdk-manager
这里以Ubuntu为例,安装好后在任意终端输入sdkmanager即可进入,因为jetson系列的系统和软件包是绑定的,因此如果系统内的CUDA等软件包不符合需要,并且在现有的sdkmanager中无法找到,就可以输入sdkmanager --archived-versions查看并安装老版本系统。
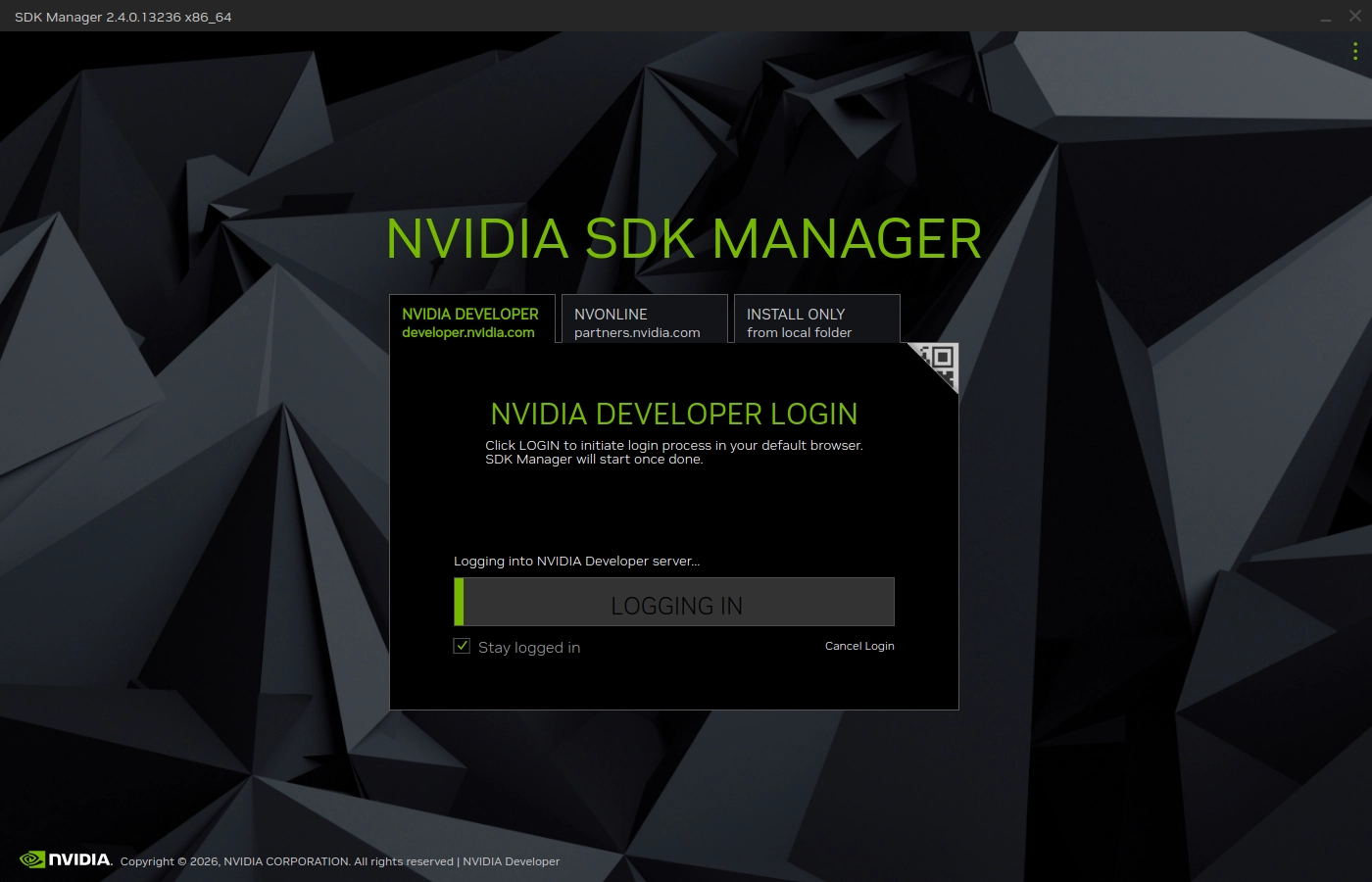
进入sdkmanager后需要注册并登录,国内可以使用微信注册Nvidia账号,还是比较方便的。
3.1.2 Jetson Thor安装系统
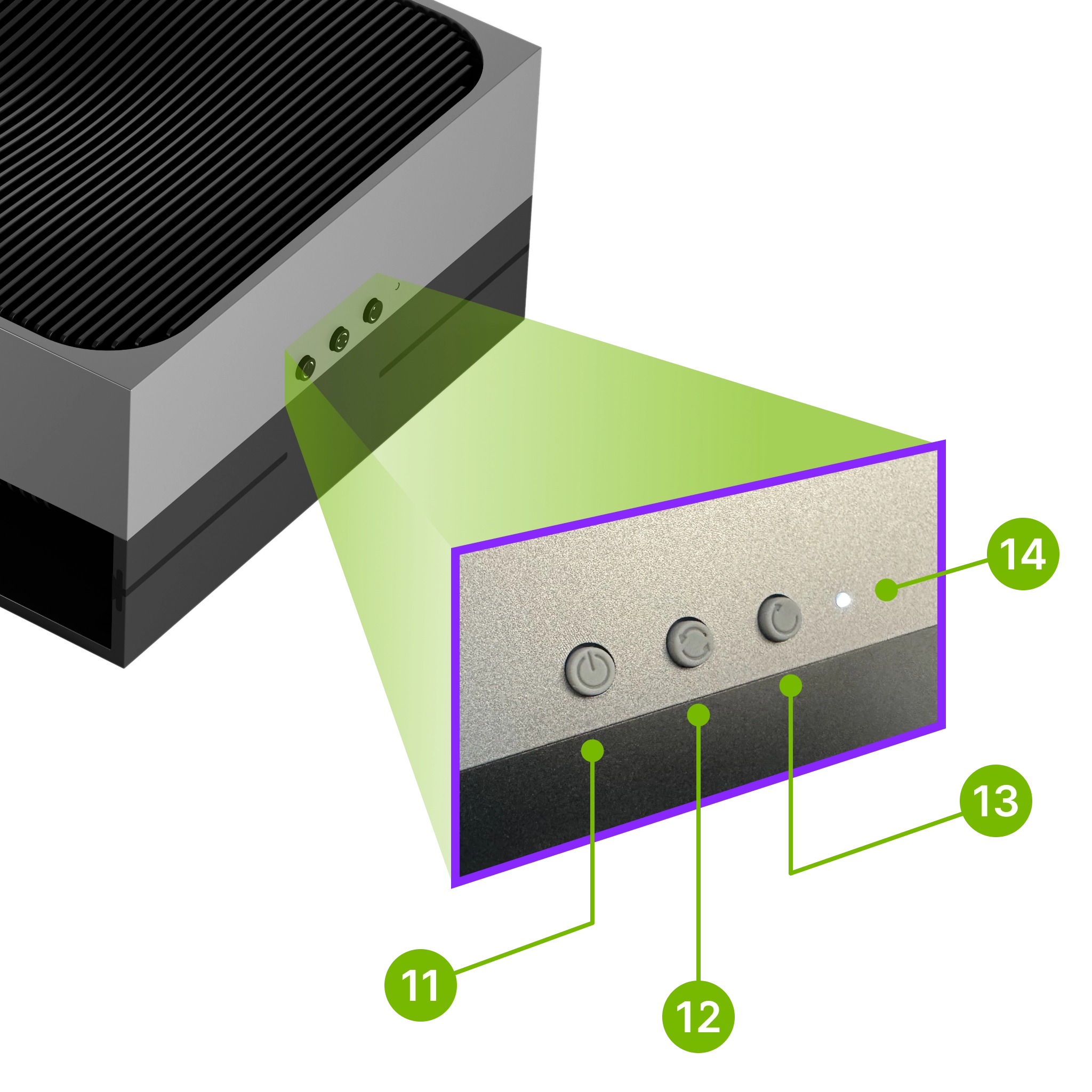
在给Thor插入供电之前,请一直按住三个按钮中间的按键,让机器进入Recovery模式,只有在这个状态下系统才能成功烧录:
进入sdkmanager后,我们可以使用一根usb线连接Thor和电脑,此时软件会自动检测:
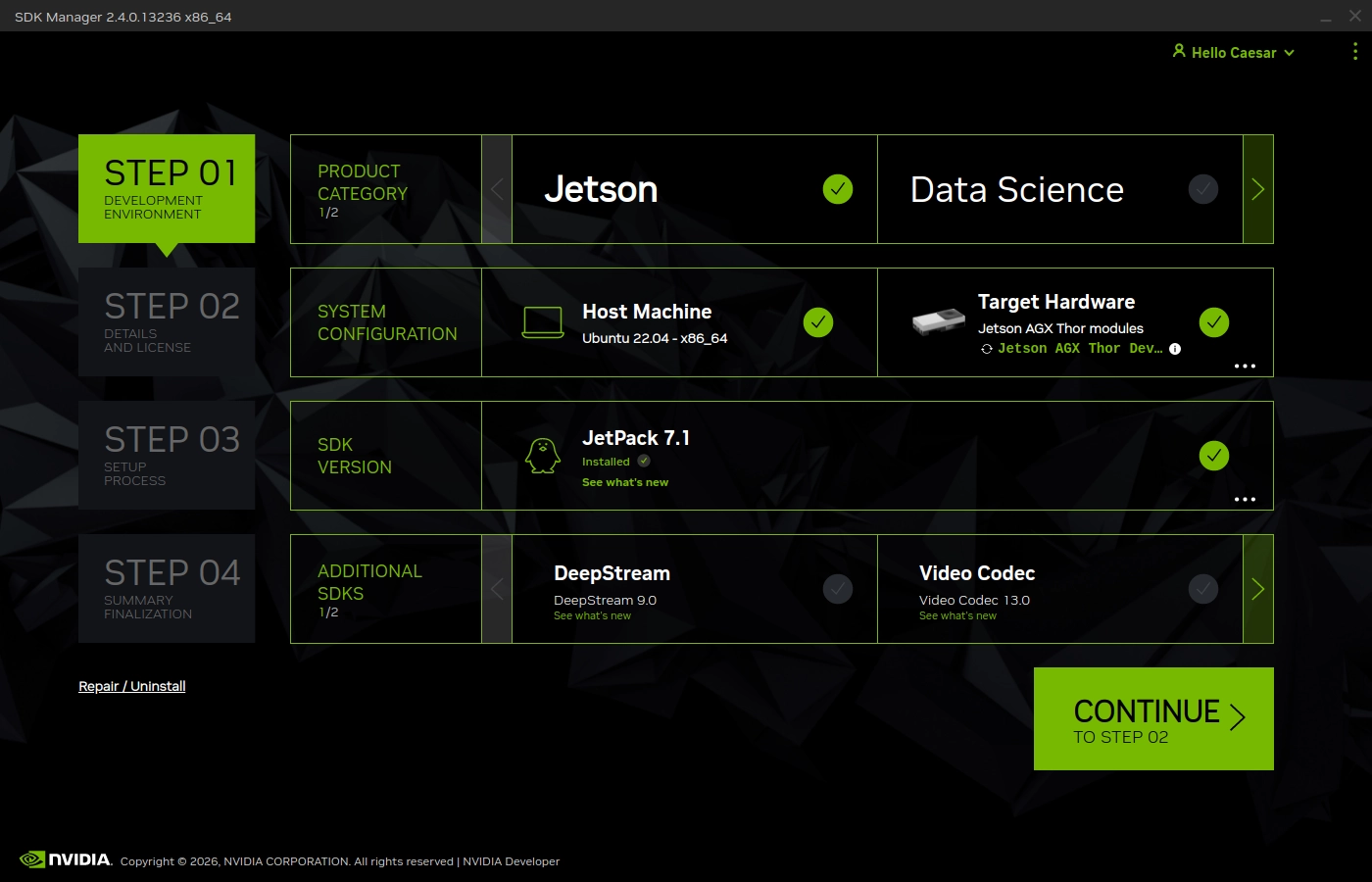
如果对软件版本没有过多的需求,直接点击下一步准备进行安装。这里要注意sdkmanager会尝试更新你本机也就是Host的Nvidia软件,如果不想本地环境被干扰请直接取消勾选,下方的Target Components表示我们即将安装到Thor中的内容,包括Jetson Linux也就是Nvidia定制的Ubuntu镜像、Jetson计算库的Runtime和SDK版本,如果要使用CUDA进行开发一定要安装SDK版本,Runtime版本中很多功能都会受到限制。
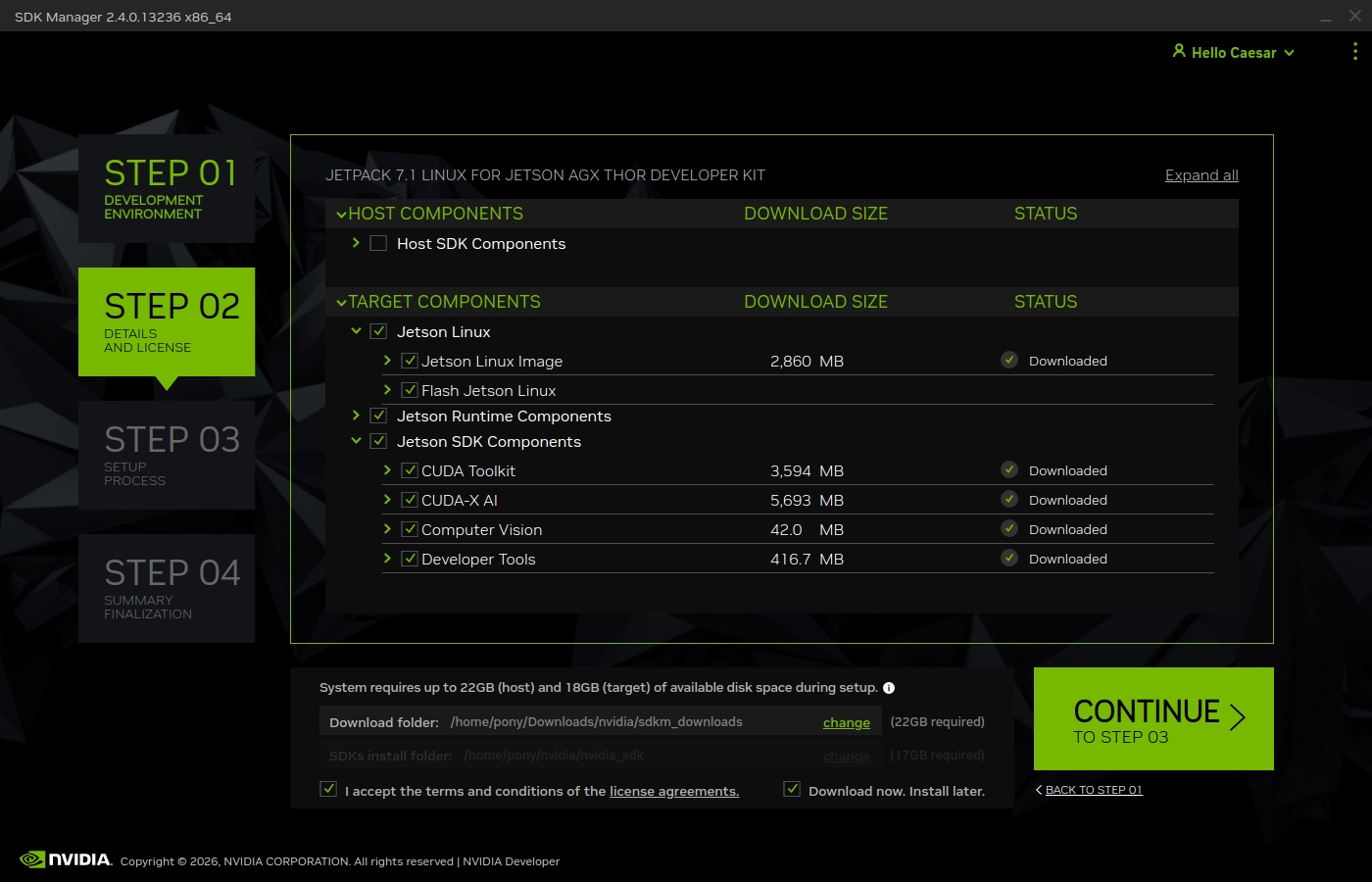
如果你的操作系统不支持同时使用两个有线网络,请勾选先下载后安装的复选框,因为Thor与电脑的连接本质上也是生成了一个局域网连接,如果这个局域网连接没有被打开的话,就会下载失败。
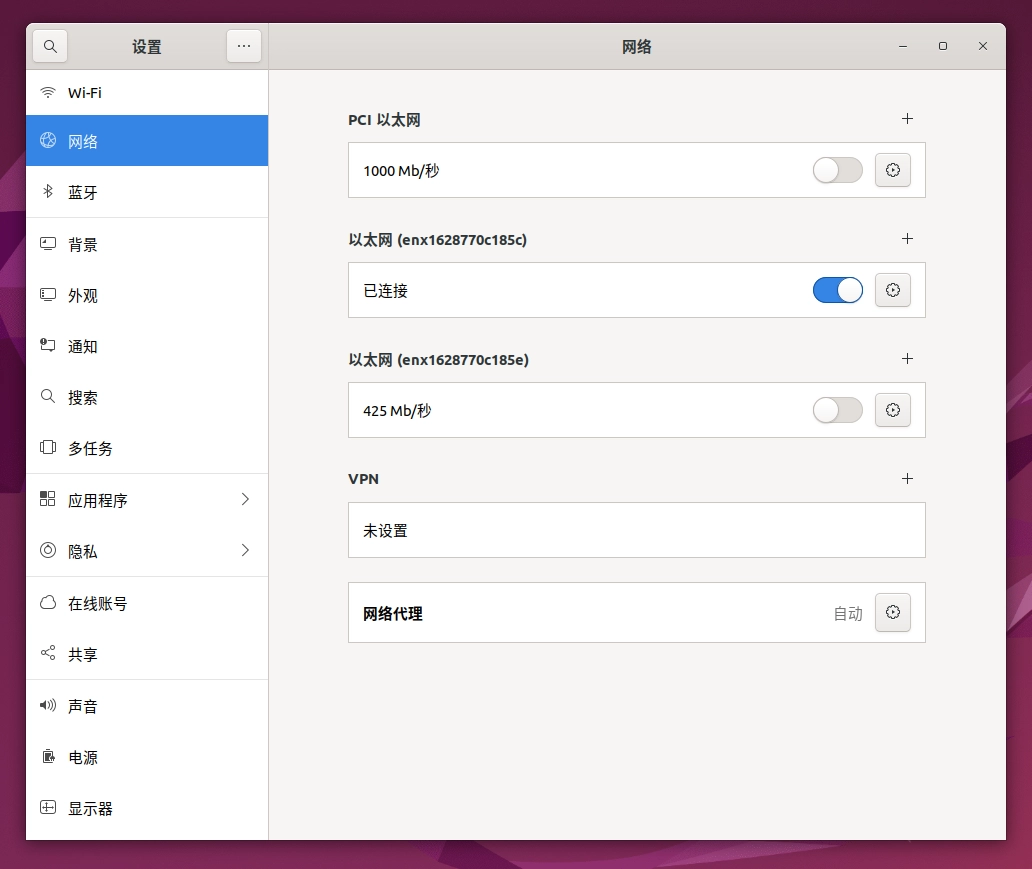
接下来系统就会从网络上拉取镜像,然后开始安装了,安装过程中可能会需要你指定用户名与密码,输入后即绑定为Thor中系统的用户名和密码。
安装完成后重启,即可正常进入系统,记得在右上角将性能调整成MAXN以发挥Thor的最强性能。
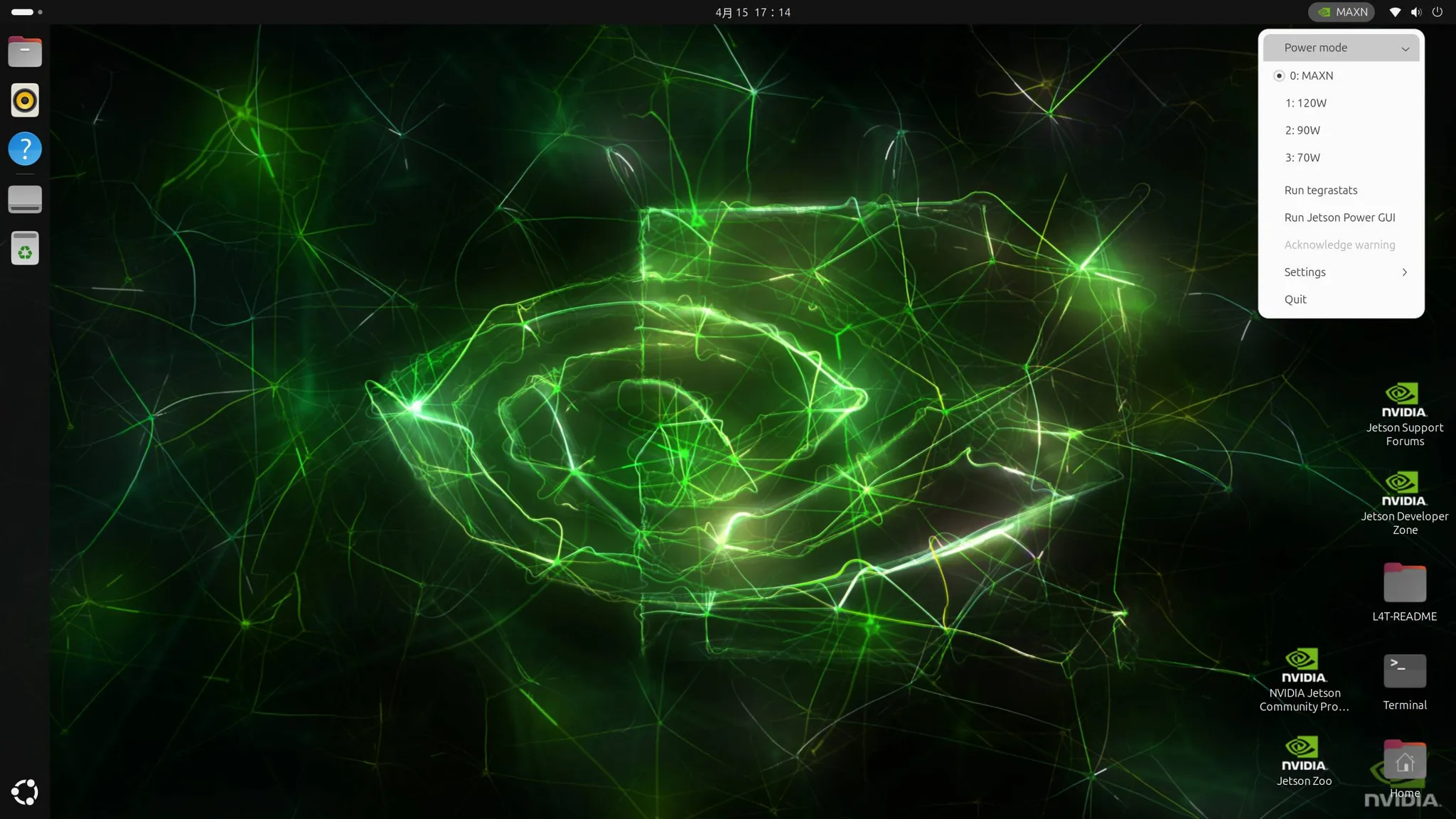
3.2 软件环境依赖
软件依赖方面,需要注册NVIDIA NGC(NVIDIA GPU Cloud)账号以下载模型权重和容器镜像。NGC是NVIDIA提供的云端AI资源平台,托管了大量预训练模型、优化容器和开发工具。注册过程完全免费,只需访问ngc.nvidia.com并使用企业邮箱或个人邮箱完成注册即可。注册后需要生成API密钥用于命令行工具的身份验证,该密钥在后续的模型下载步骤中会用到。
3.3 Jetson平台对比分析
| 设备型号 | GPU架构 | 内存容量 | 最大上下文长度 | GPU利用率 |
|---|---|---|---|---|
| Jetson AGX Thor | Blackwell | 64GB | 8192 tokens | 0.8 |
| Jetson AGX Orin | Ampere | 32/64GB | 8192 tokens | 0.8 |
| Orin Super Nano | Ampere | 16GB | 256 tokens | 0.65 |
从上表可以看出,Thor相比Orin系列在GPU架构上实现了代际升级,采用了最新的Blackwell架构,提供了更高的算力密度和能效比。在内存容量方面,Thor标配64GB统一内存,使其能够支持更长的上下文窗口(8192 tokens),这对于处理复杂的多轮对话或长视频分析场景至关重要。
4. 部署实施步骤
4.1 安装NGC命令行工具
NGC CLI是NVIDIA提供的命令行工具,用于从NGC目录下载模型检查点、容器镜像和数据集。首先在Thor设备上创建工作目录并下载适用于ARM64架构的NGC CLI安装包:
bash
# 创建项目目录
mkdir -p ~/Projects/CosmosReason
cd ~/Projects/CosmosReason
# 下载NGC CLI for ARM64
wget -O ngccli_arm64.zip https://api.ngc.nvidia.com/v2/resources/nvidia/ngc-apps/ngc_cli/versions/4.13.0/files/ngccli_arm64.zip
# 解压并设置执行权限
unzip ngccli_arm64.zip
chmod u+x ngc-cli/ngc
# 将NGC CLI添加到系统路径
export PATH="$PATH:$(pwd)/ngc-cli"
# 将路径永久添加到shell配置文件
echo 'export PATH="$PATH:$HOME/Projects/CosmosReason/ngc-cli"' >> ~/.bashrc
source ~/.bashrc安装完成后,需要配置NGC CLI的认证信息。运行ngc config set命令会启动交互式配置向导:
bash
ngc config set配置过程中需要输入以下信息:
- API Key:访问https://org.ngc.nvidia.com/setup/api-key 生成个人API密钥,该密钥具有访问NGC资源的权限
- CLI output format :选择输出格式,推荐使用
ascii以获得更好的可读性 - org:组织名称,个人用户直接按回车使用默认值即可
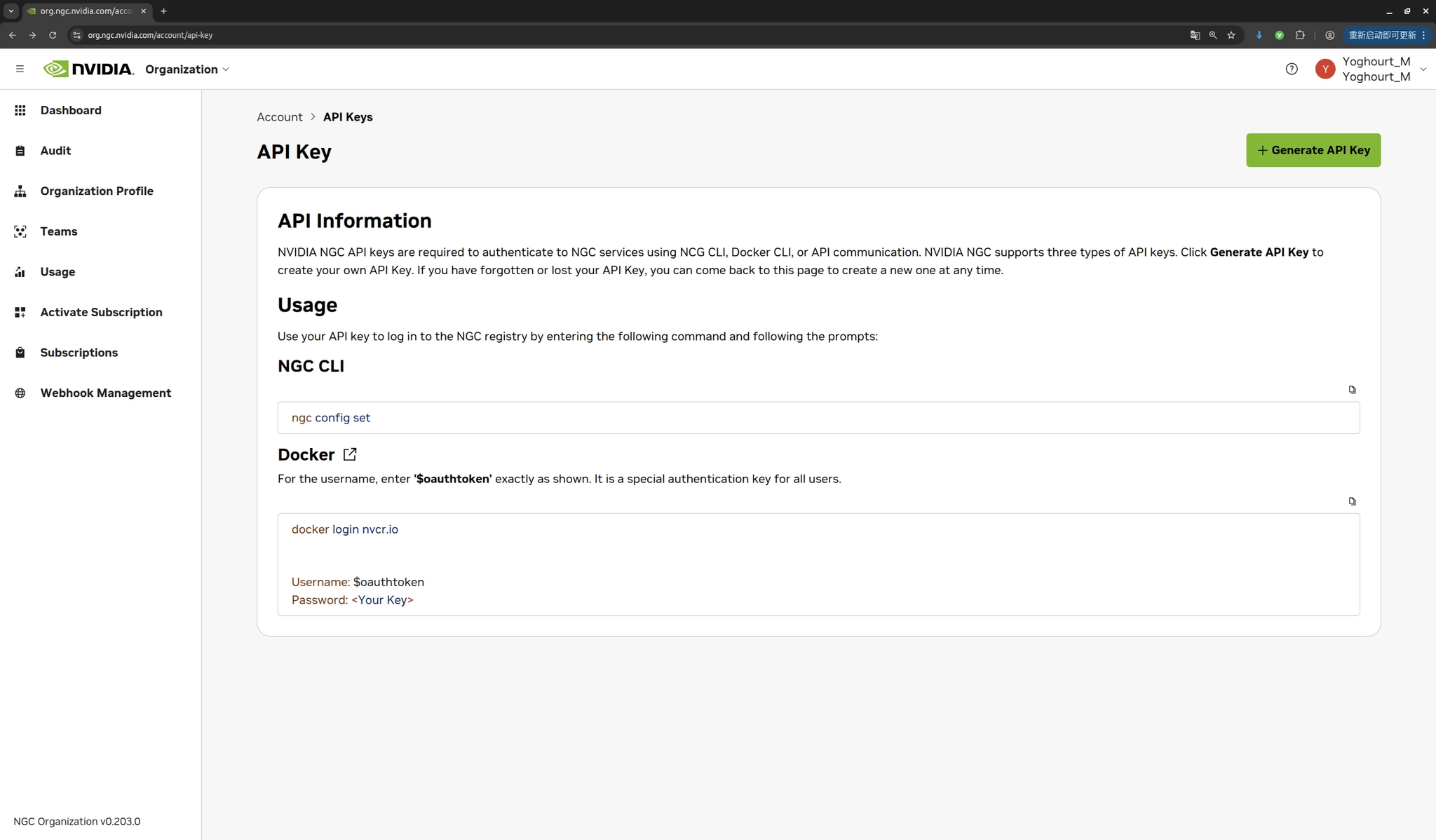
配置完成后,可以通过ngc registry model list命令验证配置是否成功,该命令会列出NGC目录中可用的模型列表。
4.2 下载Cosmos Reason 2B模型权重
使用NGC CLI下载FP8量化版本的Cosmos Reason 2B模型。该版本经过静态量化和KV缓存优化,是所有Jetson设备推荐使用的版本:
bash
cd ~/Projects/CosmosReason
ngc registry model download-version "nim/nvidia/cosmos-reason2-2b:1208-fp8-static-kv8"下载过程根据网络速度可能需要10-30分钟。下载完成后会在当前目录下创建cosmos-reason2-2b_v1208-fp8-static-kv8/文件夹,其中包含模型的权重文件、配置文件和分词器(tokenizer)。可以通过以下命令查看下载的文件结构:
bash
ls -lh cosmos-reason2-2b_v1208-fp8-static-kv8/典型的目录结构包括:
config.json:模型配置文件,定义了模型架构参数model-*.safetensors:模型权重文件,采用SafeTensors格式存储tokenizer.json:分词器配置文件preprocessor_config.json:图像预处理配置
记录下完整的模型路径,后续在启动vLLM服务时需要将该目录挂载到Docker容器中。建议使用绝对路径以避免路径解析错误:
bash
MODEL_PATH="$HOME/Projects/CosmosReason/cosmos-reason2-2b_v1208-fp8-static-kv8"
echo $MODEL_PATH4.3 拉取vLLM推理引擎容器镜像
vLLM(Very Large Language Model)是一个高性能的大语言模型推理框架,专为生产环境优化。它采用了PagedAttention算法来管理KV缓存,通过类似操作系统虚拟内存的分页机制,将连续的KV缓存分割成固定大小的块(blocks),从而实现更高效的内存利用。相比传统的推理框架,vLLM在批处理吞吐量上可以提升数倍,同时支持流式输出、动态批处理等高级特性。
对于Jetson AGX Thor,NVIDIA提供了专门优化的vLLM容器镜像,该镜像基于JetPack 7构建,包含了针对Thor GPU架构的CUDA内核优化和TensorRT加速层。拉取容器镜像:
bash
docker pull nvcr.io/nvidia/vllm:26.01-py3镜像大小约8GB,首次拉取需要较长时间。拉取完成后可以通过docker images命令查看本地镜像列表,确认镜像已成功下载。该容器镜像包含了完整的Python 3.10环境、PyTorch 2.6、CUDA 12.6以及vLLM框架的最新版本,开箱即用无需额外配置。
容器化部署的优势在于环境隔离和依赖管理。所有的Python包、系统库都封装在容器内部,不会与宿主机的环境产生冲突。同时,容器镜像经过NVIDIA的严格测试和优化,确保了在Jetson平台上的稳定性和性能表现。
4.4 启动vLLM推理服务
在启动容器之前,建议先清理系统缓存以释放更多可用内存。Linux内核会将空闲内存用作文件系统缓存(page cache),虽然这些缓存在需要时会自动释放,但主动清理可以确保模型加载时有足够的连续内存空间:
bash
# 设置模型路径环境变量
MODEL_PATH="$HOME/Projects/CosmosReason/cosmos-reason2-2b_v1208-fp8-static-kv8"
# 清理系统缓存(需要sudo权限)
sudo sysctl -w vm.drop_caches=3vm.drop_caches=3参数会清理页缓存、目录项缓存和inode缓存,通常可以释放数GB的内存。接下来启动Docker容器并挂载模型目录:
bash
docker run --rm -it \
--runtime nvidia \
--network host \
--ipc host \
-v "$MODEL_PATH:/models/cosmos-reason2-2b:ro" \
-e NVIDIA_VISIBLE_DEVICES=all \
-e NVIDIA_DRIVER_CAPABILITIES=compute,utility \
nvcr.io/nvidia/vllm:26.01-py3 \
bash参数说明:
--runtime nvidia:使用NVIDIA Container Runtime,使容器能够访问GPU设备--network host:使用宿主机网络栈,避免端口映射带来的性能损耗--ipc host:共享宿主机的IPC命名空间,提升共享内存通信效率-v "$MODEL_PATH:/models/cosmos-reason2-2b:ro":将模型目录以只读方式挂载到容器的/models/cosmos-reason2-2b路径-e NVIDIA_VISIBLE_DEVICES=all:使容器可见所有GPU设备-e NVIDIA_DRIVER_CAPABILITIES=compute,utility:授予容器计算和工具能力
进入容器后,启动vLLM推理服务。Thor的充足内存允许我们使用较大的上下文窗口和较高的GPU利用率:
bash
vllm serve /models/cosmos-reason2-2b \
--max-model-len 8192 \
--media-io-kwargs '{"video": {"num_frames": -1}}' \
--reasoning-parser qwen3 \
--gpu-memory-utilization 0.8关键参数解析:
--max-model-len 8192:设置最大上下文长度为8192个token,约相当于6000-8000个英文单词或4000-5000个中文字符。更长的上下文窗口允许模型处理更复杂的多轮对话和更详细的图像描述--media-io-kwargs '{"video": {"num_frames": -1}}':配置视频处理参数,num_frames: -1表示自动采样视频帧数,框架会根据视频长度和模型容量动态调整--reasoning-parser qwen3:启用链式思维推理解析器,该解析器基于Qwen3模型的推理格式,能够从模型输出中提取中间推理步骤--gpu-memory-utilization 0.8:设置GPU内存利用率为80%,为系统进程和CUDA运行时预留20%的内存空间
服务启动过程中会经历以下阶段:
- 模型加载:从磁盘读取权重文件并加载到GPU内存,Thor的NVMe SSD可以在30秒内完成加载
- KV缓存预分配 :根据
max-model-len参数预分配键值对缓存空间 - Warmup预热:运行几次前向传播以初始化CUDA内核和优化执行计划
- 服务就绪:启动HTTP服务器监听8000端口
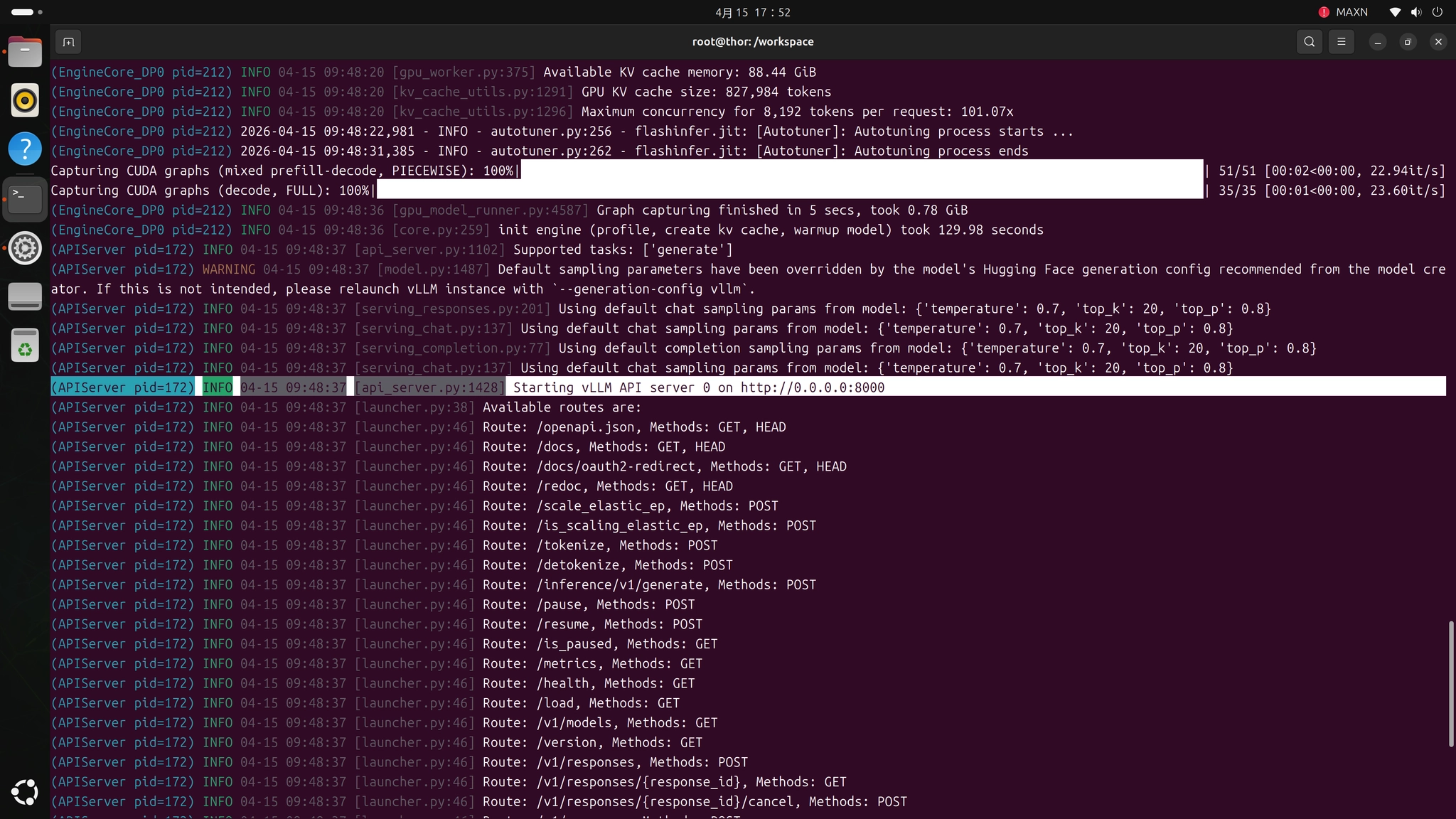
当看到以下日志输出时,表示服务已成功启动:
INFO: Uvicorn running on http://0.0.0.0:8000
INFO: Application startup complete.此时vLLM已经在后台运行,并通过OpenAI兼容的API接口对外提供服务。
4.5 验证推理服务
在启动推理服务后,建议先通过简单的API调用验证服务是否正常工作。打开Thor设备上的另一个终端窗口(保持vLLM容器继续运行),执行以下命令:
bash
# 查询可用模型列表
curl http://localhost:8000/v1/models正常情况下会返回JSON格式的模型信息,包括模型ID、创建时间等元数据。接下来进行一次实际的推理测试:
bash
curl -s http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/models/cosmos-reason2-2b",
"messages": [
{
"role": "user",
"content": "What capabilities do you have?"
}
],
"max_tokens": 128
}' | python3 -m json.tool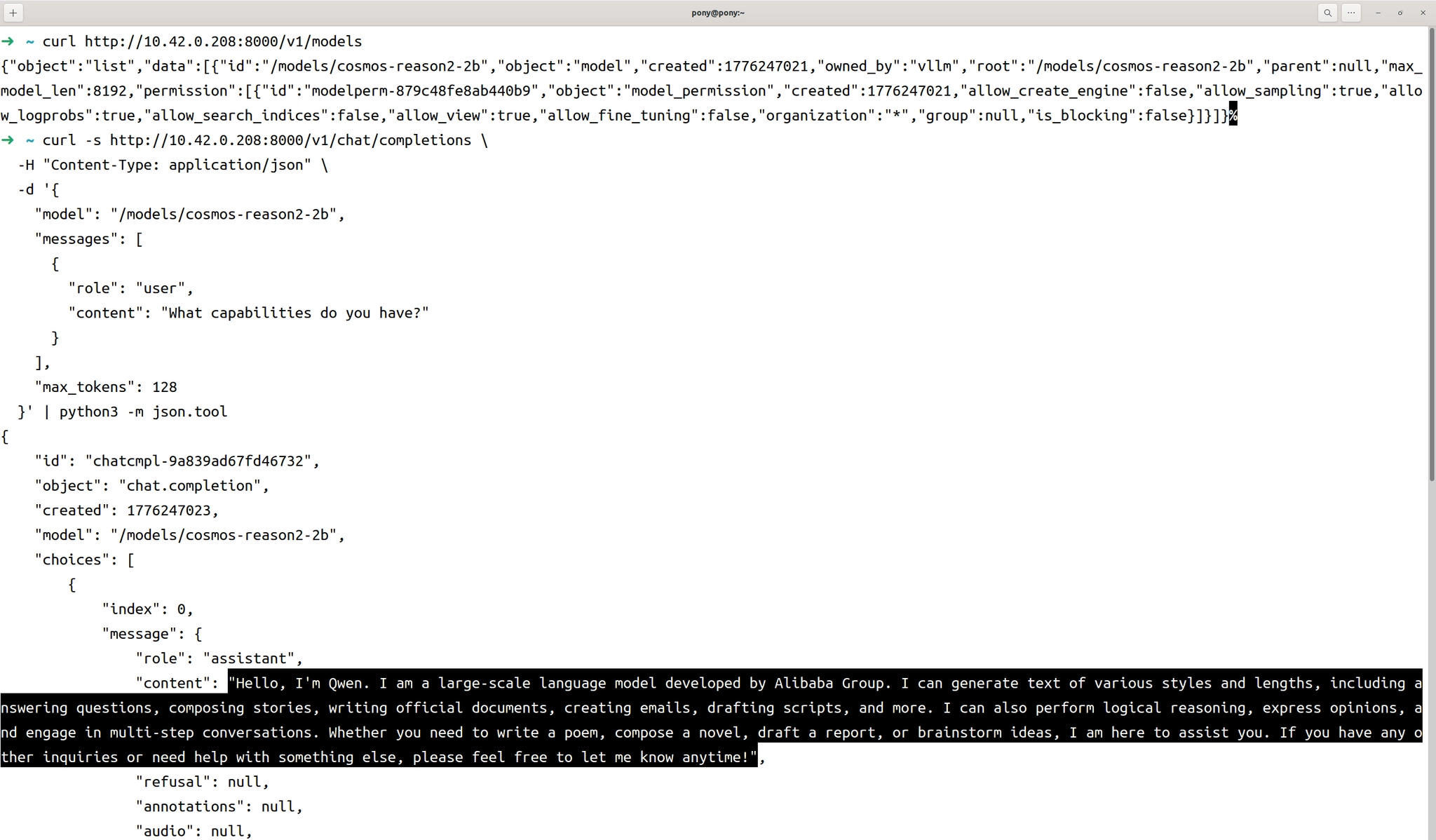
该请求使用了OpenAI Chat Completions API的标准格式,vLLM完全兼容该接口规范,因此可以无缝替换OpenAI的API端点。响应结果会包含模型生成的文本、token使用统计、推理延迟等信息。如果返回了正常的JSON响应,说明推理服务已经正确配置并可以处理请求。
对于视觉语言模型,还可以测试图像理解能力。需要将图像编码为base64格式并嵌入到请求中:
bash
# 将图像转换为base64编码
IMAGE_BASE64=$(base64 -i /path/to/your/image.jpg)
# 发送包含图像的推理请求,直接用curl可能因为过大导致发送失败
cat <<EOF | curl -s http://10.42.0.208:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d @- | python3 -m json.tool
{
"model": "/models/cosmos-reason2-2b",
"messages": [
{
"role": "user",
"content": [
{"type": "text", "text": "please describe this picture in detail"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,${IMAGE_BASE64}"}}
]
}
],
"max_tokens": 256
}
EOFCosmos Reason 2B会分析图像内容并生成详细的描述,包括场景识别、物体检测、空间关系推理等。由于启用了--reasoning-parser qwen3参数,模型的输出中还会包含推理过程,展示模型是如何一步步分析图像并得出结论的。
下面是我们使用的图片以及推理结果:

bash
"content": "这张图片描绘了一个繁华都市的中心地带,一个熙熙攘攘的十字路口。图片中心,一座巨大的电子广告牌矗立在建筑之上,上面展示着两个人物形象,周围环绕着各种广告和标语。广告牌下方,一家名为 TSUTAYA 的书店格外显眼,其标志性的字母在阳光下熠熠生辉。书店周围,各式各样的商店和餐馆林立,招牌上用日文写着吸引人的信息。街道上,行人如织,他们或匆匆赶路,或悠闲漫步,共同构成了这幅生动的城市画卷。车辆穿梭其间,其中一辆白色出租车尤为引人注目。整个场景充满了活力与生机,展现了都市生活的繁忙与多彩。"4.6 部署Live VLM WebUI实时交互界面
Live VLM WebUI是NVIDIA AI-IOT团队开发的开源项目,提供了一个基于Web的实时视觉语言交互界面。该应用可以捕获摄像头视频流,将每一帧图像发送给VLM模型进行分析,并在界面上实时显示模型的推理结果。这种实时交互能力使得Cosmos Reason 2B可以应用于机器人视觉导航、工业质检、智能监控等需要即时反馈的场景。
4.6.1 安装Live VLM WebUI
推荐使用uv包管理器进行安装,uv是一个用Rust编写的超快Python包管理工具,相比传统的pip安装速度提升10-100倍。首先安装uv:
bash
# 安装uv包管理器
curl -LsSf https://astral.sh/uv/install.sh | sh
# 加载uv环境变量
source $HOME/.local/bin/env创建独立的Python虚拟环境并安装Live VLM WebUI:
bash
# 进入项目目录
cd ~/Projects/CosmosReason
# 创建Python 3.12虚拟环境
uv venv .live-vlm --python 3.12
# 激活虚拟环境
source .live-vlm/bin/activate
# 安装Live VLM WebUI
uv pip install live-vlm-webui
# 启动WebUI服务
live-vlm-webuiWebUI服务会在8090端口启动HTTPS服务器。由于使用了自签名证书,首次访问时浏览器会显示安全警告,这是正常现象。应用架构采用了前后端分离设计,前端使用React构建,后端使用FastAPI提供RESTful API,通过WebSocket实现视频流的实时传输。
如果更倾向于使用Docker部署,可以采用以下方式:
bash
# 克隆项目仓库
git clone https://github.com/nvidia-ai-iot/live-vlm-webui.git
cd live-vlm-webui
# 使用提供的脚本启动容器
./scripts/start_container.shDocker方式的优势是环境完全隔离,不会影响宿主机的Python环境,同时容器内已经预装了所有依赖库和优化配置。
4.6.2 配置WebUI连接到vLLM服务
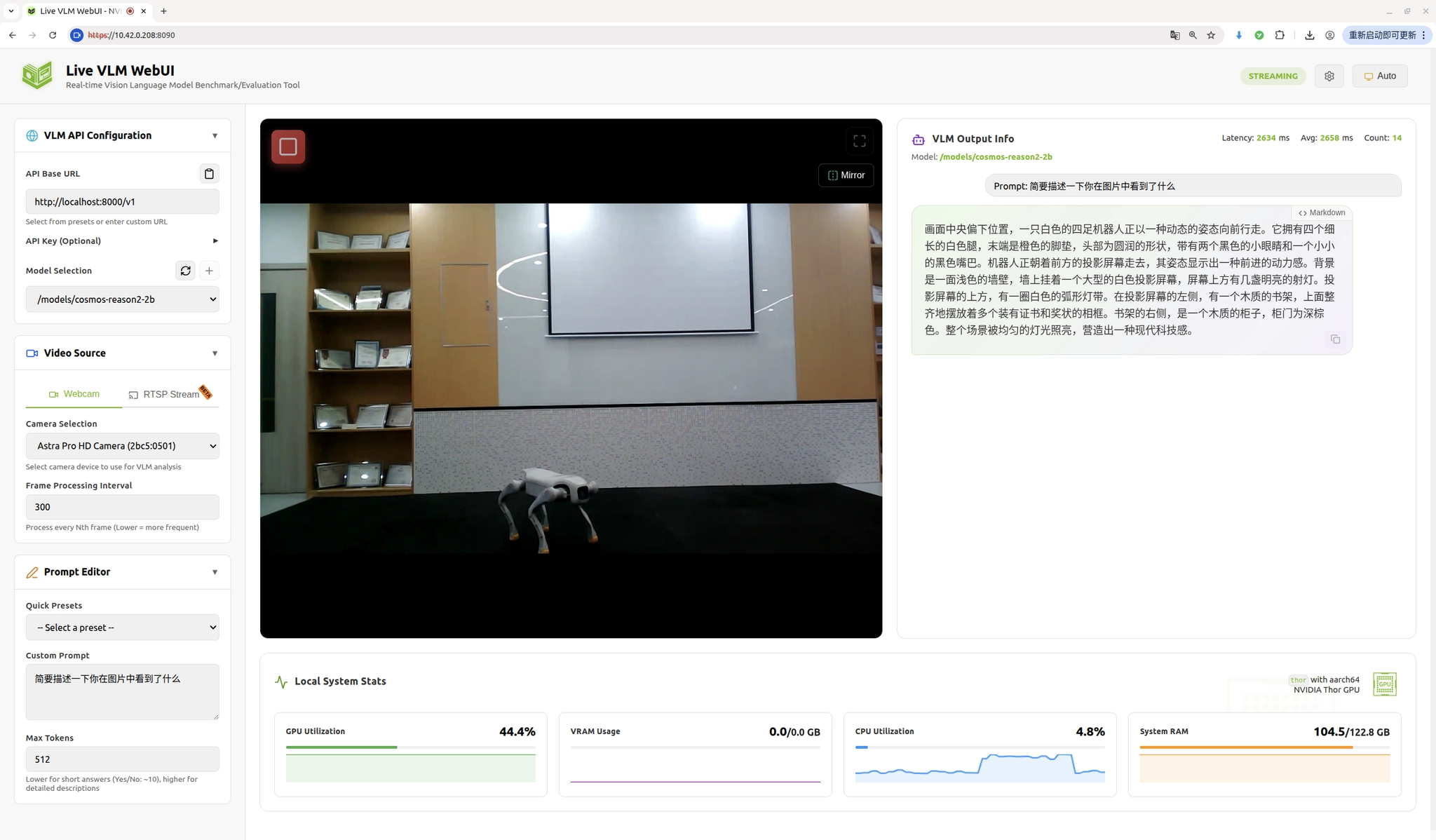
在浏览器中访问https://localhost:8090,接受自签名证书警告后进入主界面。界面左侧是配置面板,右侧是视频预览和推理结果显示区域。按照以下步骤配置VLM连接:
- 设置API端点 :在左侧"VLM API Configuration"区域,将"API Base URL"设置为
http://localhost:8000/v1。注意这里使用HTTP而非HTTPS,因为vLLM服务默认不启用TLS加密 - 刷新模型列表 :点击"Refresh"按钮,WebUI会向vLLM服务发送
/v1/models请求获取可用模型列表 - 选择模型:在下拉菜单中选择"cosmos-reason2-2b"模型
- 配置推理参数 :
- Max Tokens:设置为200-300,控制每次推理生成的最大token数量
- Temperature:设置为0.7,控制生成文本的随机性,较低的值使输出更确定
- Frame Processing Interval:设置为30-60,表示每隔多少帧处理一次图像,避免过于频繁的推理请求
- 选择摄像头:在"Camera Selection"区域选择USB摄像头或CSI摄像头设备,由于使用的是网络摄像头,因此可以直接调用访问网页的设备采集到的图像
- 启动推理:点击"Start"按钮开始实时推理
WebUI会持续捕获摄像头画面,按照设定的帧间隔将图像发送给vLLM服务,并在界面上显示模型的分析结果。由于Cosmos Reason 2B支持链式思维推理,你可以在输出中看到模型的推理过程,例如"首先我观察到画面中有一个红色物体,根据其形状和纹理判断这是一个苹果..."这样的逐步分析。
5. 总结与展望
本文详细介绍了在Jetson AGX Thor上部署NVIDIA Cosmos Reason 2B视觉语言模型的完整流程,涵盖了从环境准备、模型下载、推理服务配置到实时Web界面部署的各个环节。通过使用vLLM推理框架和FP8量化技术,我们成功在边缘设备上实现了高性能的视觉语言推理能力。
Cosmos Reason 2B的链式思维推理能力使其在复杂场景理解、异常检测、质量评估等任务中表现出色。结合Live VLM WebUI的实时交互界面,开发者可以快速构建原型并验证AI应用的可行性。Thor强大的算力和充足的内存使其能够支持8192 tokens的长上下文,这对于处理详细的场景描述和多轮对话至关重要。
展望未来,随着模型压缩技术的进一步发展和Jetson硬件的持续升级,我们可以期待在边缘设备上运行更大规模、更强能力的视觉语言模型。多模态融合、实时3D场景理解、端到端的具身智能等前沿技术将逐步从实验室走向实际应用,为机器人、自动驾驶、智能制造等领域带来革命性的变化。
6. 参考资源
-
NVIDIA Cosmos模型主页:https://build.nvidia.com/nvidia/cosmos-reason2-2b
-
NGC模型目录:https://catalog.ngc.nvidia.com/
-
vLLM官方文档:https://docs.vllm.ai/
-
Live VLM WebUI项目:https://github.com/NVIDIA-AI-IOT/live-vlm-webui
-
Jetson AI Lab:https://www.jetson-ai-lab.com/
-
NVIDIA开发者论坛:https://forums.developer.nvidia.com/c/agx-autonomous-machines/jetson-embedded-systems/
-
Jetson Projects社区:https://developer.nvidia.com/embedded/community/jetson-projects
-
Hugging Face VLM讨论区:https://huggingface.co/spaces/nvidia/cosmos-reason2-2b/discussions