合同管理是企业运营中的关键环节,涉及大量非结构化或半结构化文档的处理。传统的人工录入方式效率低下且易出错,而基于规则的自动化抽取方法对文档格式的一致性要求极高,难以适应实际业务中合同模板多样、版面布局多变的情况。近年来,光学字符识别(OCR)与大语言模型(LLM)的结合,为文档智能抽取提供了新的技术路径。本文从技术实现角度,探讨基于OCR与大模型的文档抽取系统在合同管理中的应用,重点分析其技术原理、工作流程及适用场景。
技术原理
- OCR:从图像到文本的转换
合同文档的原始形态通常为扫描件、PDF或图片,无法直接被上层模型解析。OCR技术负责将图像中的文字区域检测并转录为机器可读的文本。传统OCR采用基于连通域或投影分析的版面分析方法,对表格、多栏等复杂结构效果不佳。当前主流的OCR系统(如PaddleOCR、Tesseract 5.x)引入基于深度学习的目标检测网络(如DBNet、PSENet)定位文本行,再通过CRNN+CTC或Transformer-based的序列识别模型完成字符转录。对于合同这一特定领域,公章压盖、手写签名、低质量传真等问题对OCR的鲁棒性提出较高要求,通常需要针对性地训练去噪与字符修复模块。
2.大模型驱动的信息抽取
OCR输出的文本片段带有空间坐标信息,但尚未形成结构化的字段映射。传统的基于规则或条件随机场(CRF)的方法需要针对每种合同模板编写正则表达式或标注大量训练数据,泛化能力有限。大语言模型(LLM)的出现改变了这一局面:通过将OCR结果与用户定义的抽取字段描述以提示(prompt)形式输入LLM,模型可利用其语义理解能力定位目标信息。
具体技术路线:
- 微调(Fine-tuning)方式:在预训练LLM基础上,使用少量标注的合同数据(每份合同标注若干字段键值对)进行参数高效微调(LoRA、QLoRA)。微调后模型能够学习到"合同编号"、"签约日期"、"总金额"等字段在上下文中的表达模式。
3.少样本配置与字段自定义
文档抽取系统的核心能力之一是用少量样本完成新字段的配置。其技术实现可分解为:
- 字段定义输入:用户通过界面指定要抽取的字段名称及自然语言描述(如"乙方开户银行:合同中的乙方收款银行账户所属银行名称")。
- 样本标注:用户上传2-5份典型合同,并在可视化界面上框选或点选每个字段对应的文本位置。系统将位置坐标与OCR结果中的文本行关联,生成正例。
- 特征学习:系统利用标注样本提取字段周围的文本模式、关键词触发词、相对位置等特征。对于LLM方法,标注样本会被构造为few-shot示例嵌入提示;对于检索增强方法,系统可能构建字段相关的语义索引,以便在新文档中检索最相似的文本段。
- 抽取泛化:配置完成后,系统对未标注的批量合同执行自动化抽取,返回结构化JSON数据。
这一机制使得非技术人员无需编写正则或训练模型,即可快速适配新的合同类型。
应用领域:合同管理中的典型场景
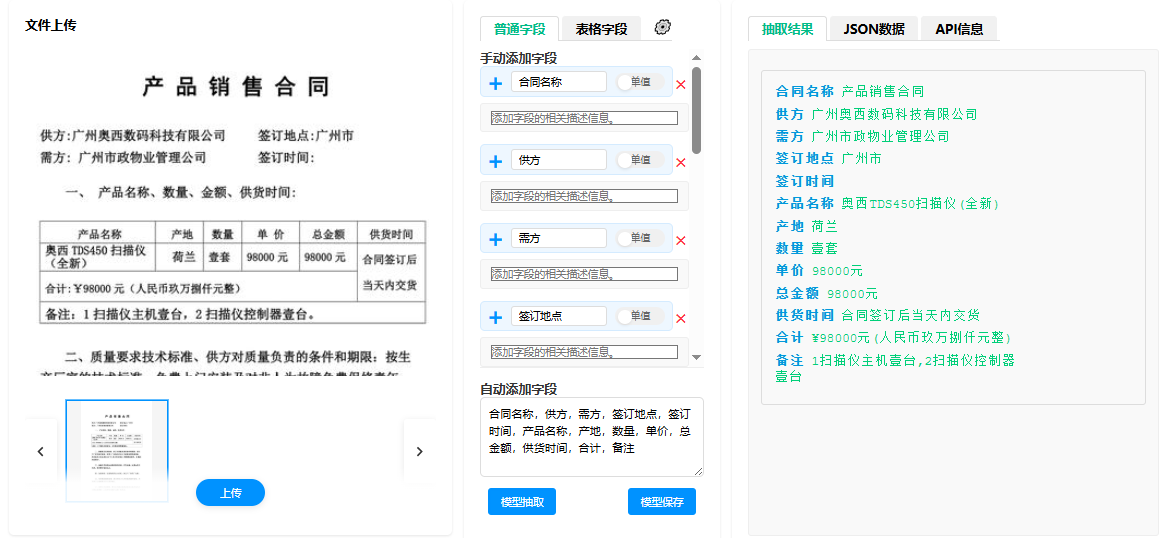
合同关键要素提取
- 企业法务或采购部门需要从大量合同中提取"合同双方"、"签订日期"、"有效期"、"合同金额"、"付款条款"等核心字段,用于建立合同台账或触发后续业务流程(如付款审批、到期提醒)。文档抽取系统能够处理不同格式的合同------无论是标准采购订单还是松散格式的合作协议------统一输出结构化记录。
历史合同数字化与合规审核
- 许多企业拥有存量纸质合同档案。通过批量扫描并应用抽取系统,可将历史合同转化为可检索、可分析的结构化数据库。在此基础上,合规部门可以设置规则(如金额超过阈值必须附有授权签字),系统自动抽取出关键字段后与规则进行比对,输出异常项供人工复核。
跨文档关联与风险发现
- 在并购尽职调查或审计场景中,可能需要同时审查主合同、补充协议、验收单等多份关联文档。抽取系统可以从各类文档中提取"项目名称"、"合同编号"、"变更金额"等关联键,通过实体链接技术建立文档间的对应关系,进而识别条款不一致、金额不匹配等风险。
多语言合同处理
- 跨国企业经常面对中英文或多语言合同。当LLM本身具备多语言理解能力时(如GPT系列、Claude、Qwen),文档抽取系统可直接抽取不同语言合同中的字段,无需单独训练语言模型。OCR层面需选择支持对应语言字库的识别引擎。
基于OCR与大模型的文档抽取系统,通过少样本配置和语义理解能力,显著降低了合同信息结构化的人力成本。其技术本质是将"视觉感知"(OCR)与"语义抽取"(LLM)解耦,再由用户自定义的字段描述进行桥接。当前系统在处理复杂版面、低质量扫描件及长文档时仍有局限,但随着多模态模型的发展和领域适配技术的成熟,文档抽取有望成为合同管理系统中不可或缺的基础能力。