拿到题目附件,先查看文件类型,得知是64位的 elf 文件。

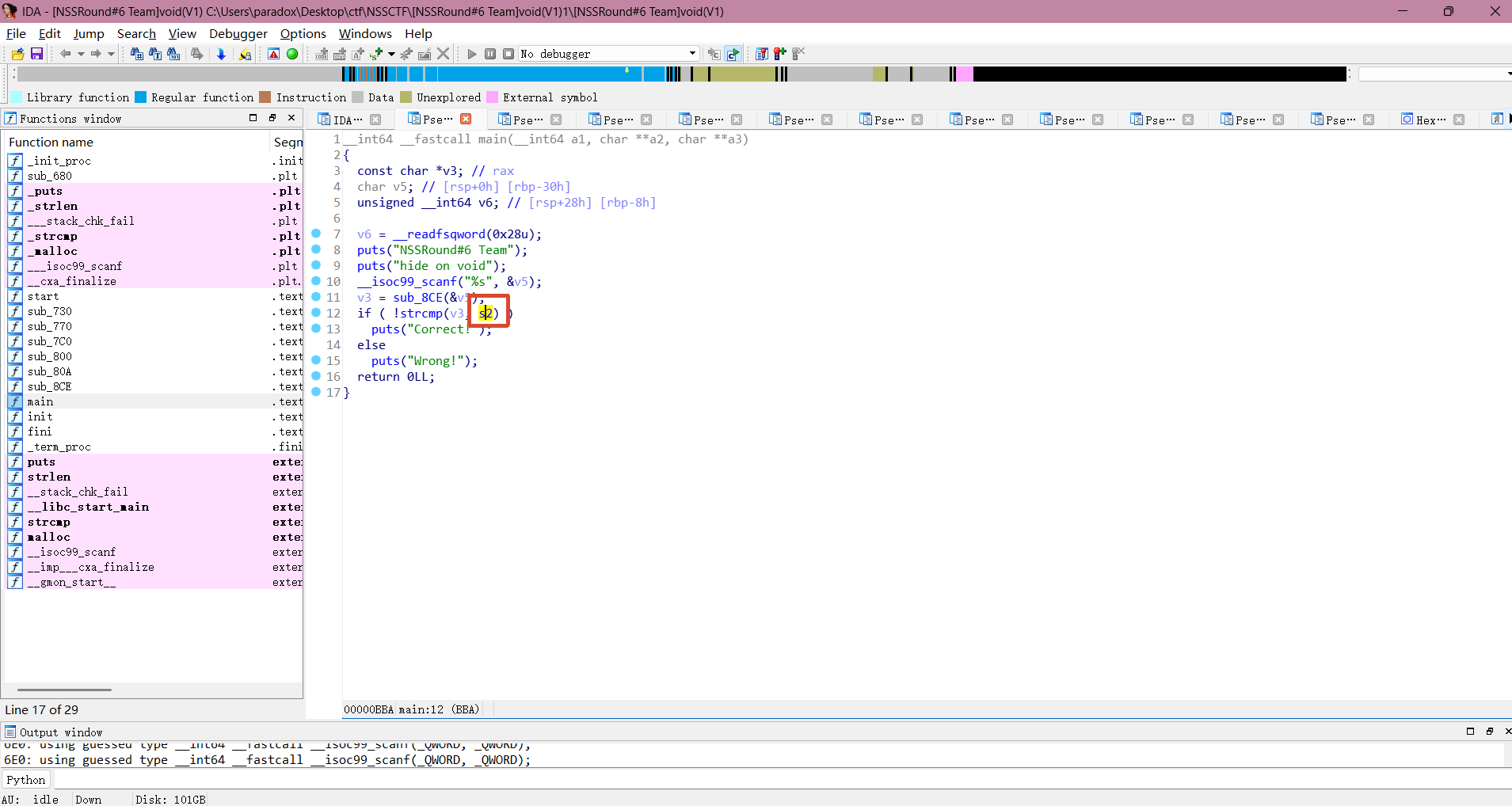
先用 ida64 打开程序进行静态分析,查看 main 函数逻辑,可以的得知这里的逻辑是将用户输入传给 sub_8CE 函数处理过后,赋值给 v3 ,之后 v3 与 s2 做比较。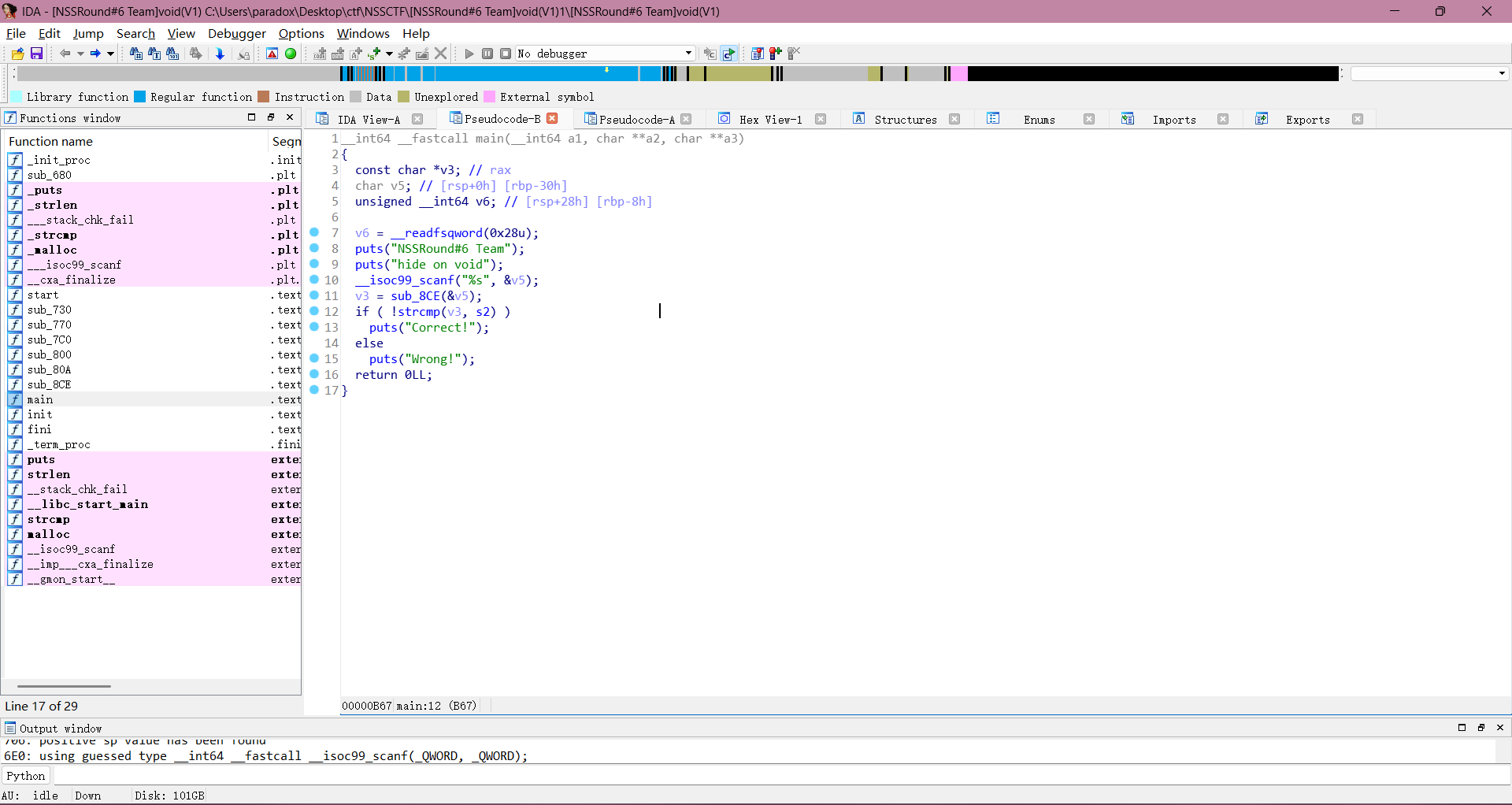
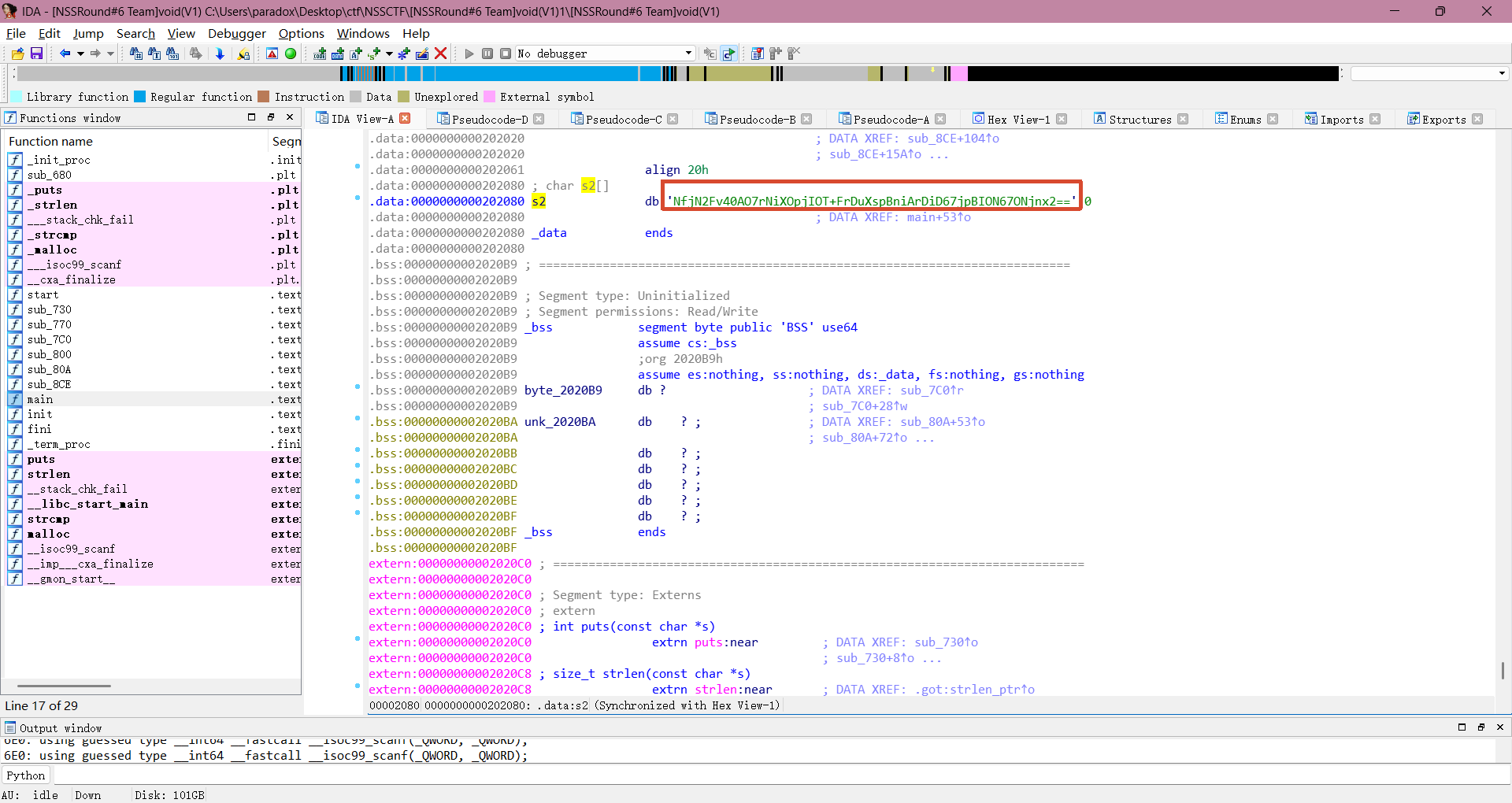
双击 s2 进入查看 .data 的汇编视图,可以看到 s2 的值为:"NfjN2Fv40AO7rNiXOpjIOT+FrDuXspBniArDiD67jpBION67ONjnx2=="
双击进入 sub_8CE 函数查看逻辑,发现这是一个用于 base64 编码用的函数。
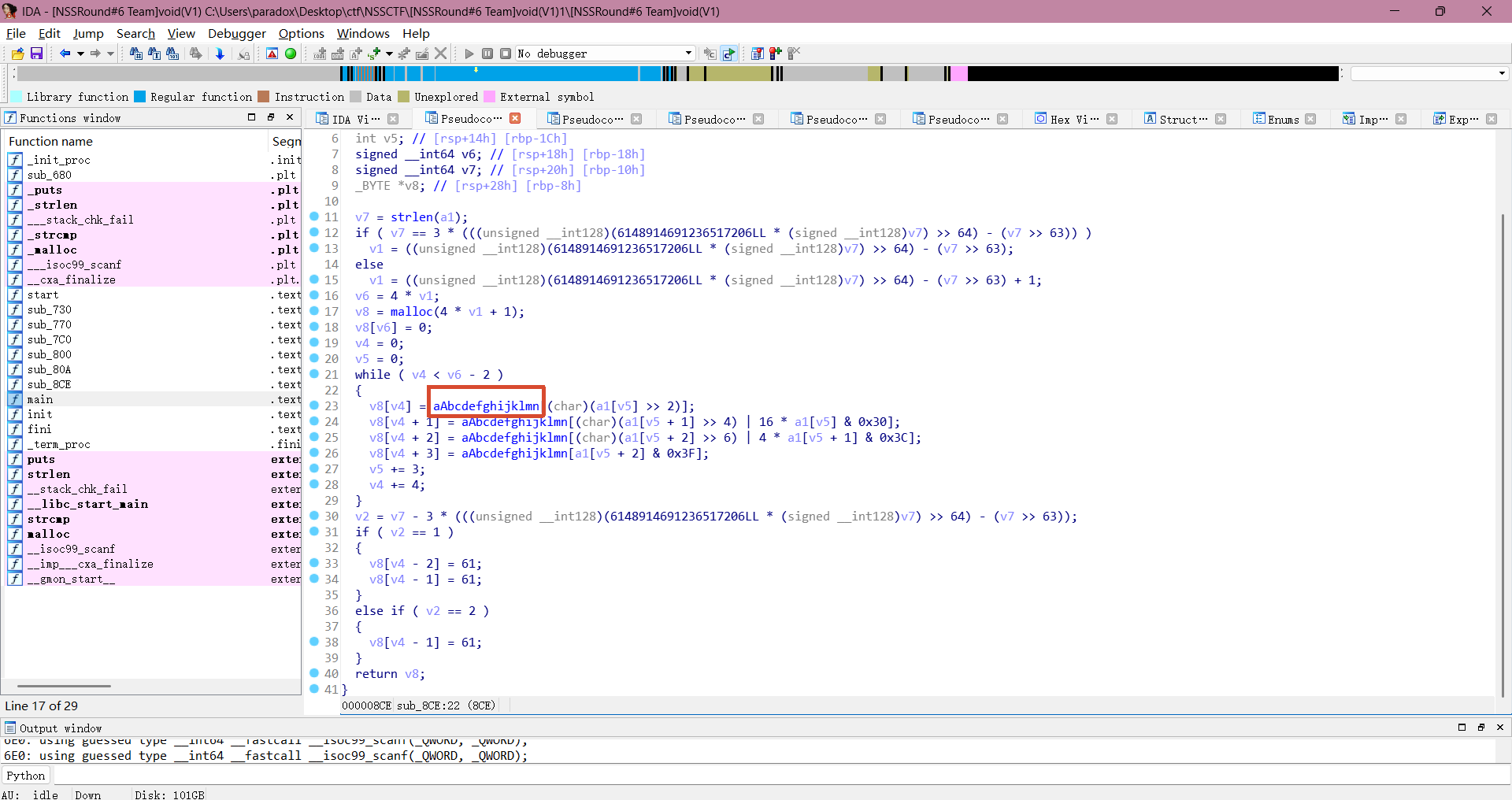
看看编码用的是自定义 base64 编码表还是标准的 base64 编码表,双击进入 "aAbcdefghijklmn" ,可以看到用的标准的 base64 编码表进行 base64 编码。
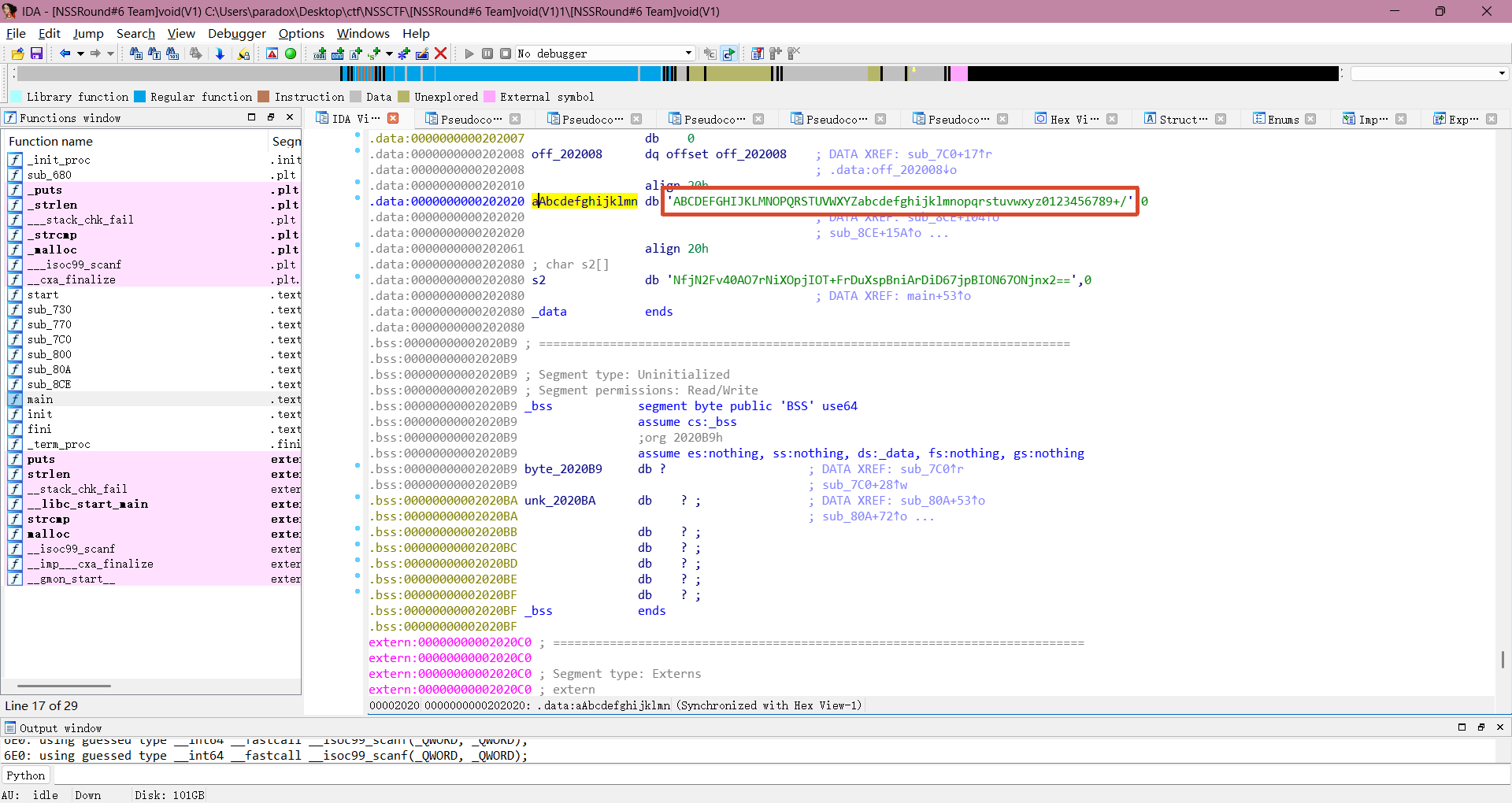
现在整理一下逻辑,用户输入(flag) -> 经过标准的 base64 编码 -> 与硬编码比较查看是否正确
那么我们现在只需要将上面得到的硬编码"NfjN2Fv40AO7rNiXOpjIOT+FrDuXspBniArDiD67jpBION67ONjnx2=="进行标准的 base64 解码就能得到 flag 了------吗?试试看
python
def custom_base64_decode(encoded_str):
# 自定义编码表
custom_table = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# 移除填充符
if encoded_str.endswith("=="):
encoded_str = encoded_str[:-2]
padding = 1 # 原始长度 % 3 == 1
elif encoded_str.endswith("="):
encoded_str = encoded_str[:-1]
padding = 2 # 原始长度 % 3 == 2
else:
padding = 0 # 原始长度 % 3 == 0
# 将每个字符转换为6位二进制
binary_str = ""
for char in encoded_str:
index = custom_table.index(char)
binary_str += format(index, '06b')
# 移除填充的0(根据原始长度模3的余数)
if padding == 1:
binary_str = binary_str[:-4] # 移除4个填充0
elif padding == 2:
binary_str = binary_str[:-2] # 移除2个填充0
# 将二进制每8位一组转换为字符
result = ""
for i in range(0, len(binary_str), 8):
byte = binary_str[i:i + 8]
if len(byte) == 8:
result += chr(int(byte, 2))
return result
# 目标字符串
target = "NfjN2Fv40AO7rNiXOpjIOT+FrDuXspBniArDiD67jpBION67ONjnx2=="
flag = custom_base64_decode(target)
print(f"Flag: {flag}")得到的结果是:
python
Flag: 5øÍØ[øÐ>>¬Ø:È9?
¬;²g
Ã>>>H8Þ>>8ØçÇ到这里,一切步骤仿佛都是正确的,没有问题的,那么问题出现在哪里呢?
回到题目看描述:"But I always seem to disappear again."(但似乎我总是又会消失不见)
标签也让我们动态调试,我们刚刚的结果是静态分析就得到了 flag ,也许我们需要试试动态分析。也许是 base64 或者 s2 硬编码 会在运行时被替换,题目描述所说的消失不见应该就是体现在这一部分。
打开 linux ,用 checksec 看看有没有保护,发现 PIE 是开着的,那么在程序运行时,基地址就会随机化,无法通过静态分析得到的地址去操作,也就是我们无法使用 ida 中看到的地址;显示 NO Symbols ,在动态调试时就无法通过函数名来下断点。

gdb 开始对题目附件进行分析。
因为开了随机基地址,所以我们需要断点调试的话,要用到的地址就只能自己算。要看看基地址是什么的话,首先得先让程序跑起来
首先先关闭基地址随机化,方便我们下次重新运行时,基地址不会再次变化
python
set disable-randomization on随后开始运行
python
starti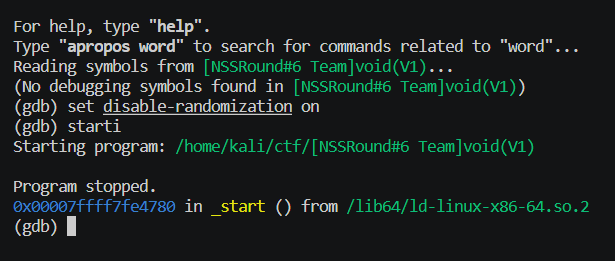
接下来需要查看基地址,看完之后按 q 回车退出
python
info file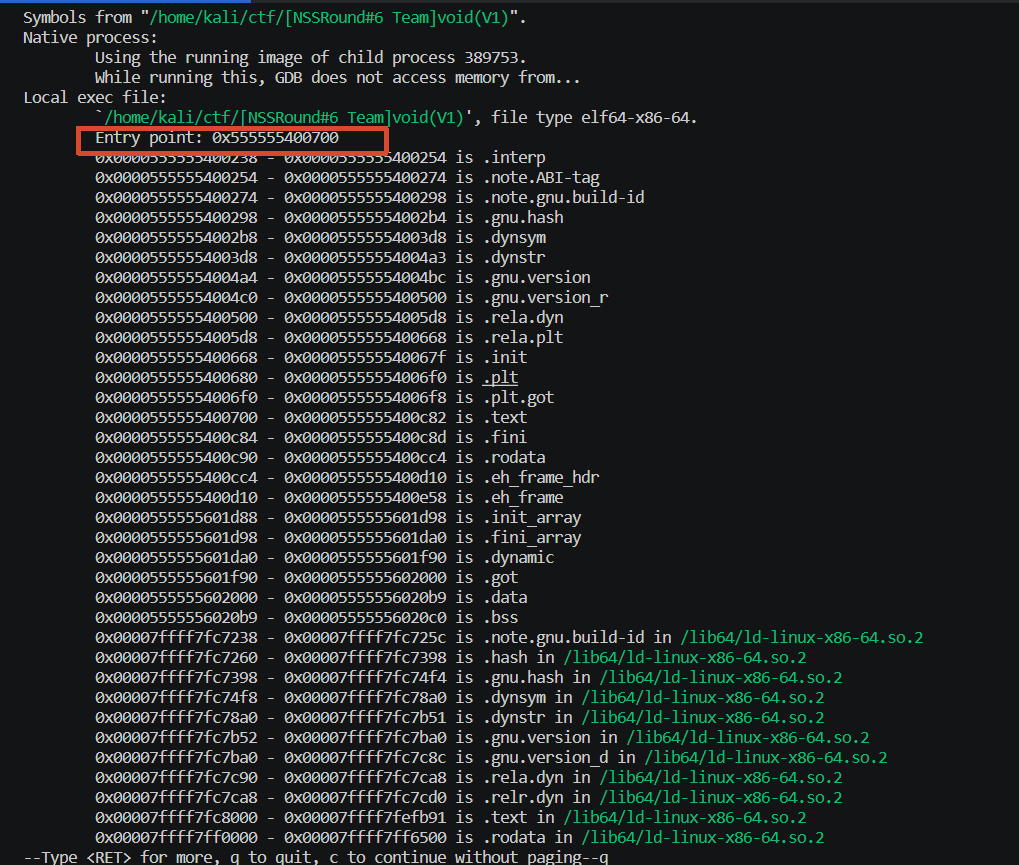

可以得知程序的基地址是:0x555555400000(因为程序的基地址必须是 0x1000 对齐的,所以最后三位直接抹零,0x0000555555400700 - > 0x0000555555400000)
接下来我们只需要看想要断点的目标的偏移量就能得到其真实地址,在 ida 中查看 s2 硬编码和 base64 编码表的偏移量,回到 main 函数双击 s2 进入 汇编视图
可以看到自定义 base64 编码表和硬编码的 s2 的偏移量分别是 0x00202020 和 0x00202080
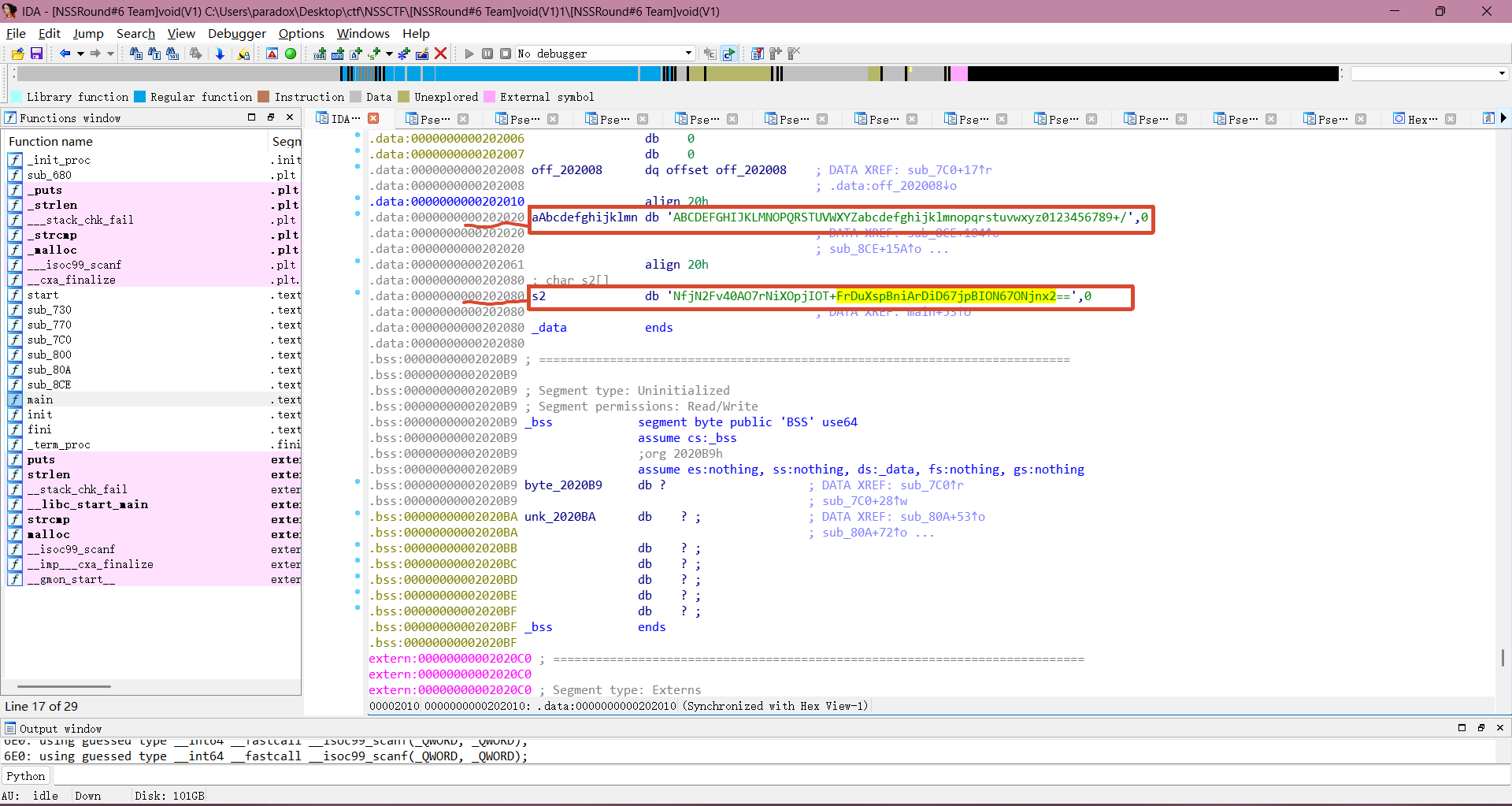
真实地址 = 基地址 + 偏移量,得到硬编码 s2 的真实地址是 :0x555555400000+ 0x00202080 = 0x555555602080 。base64编码表的真实地址是:0x555555400000+ 0x00202020 = 0x555555602020 。这两个地址待会用于查看内存的值。
接下来考虑断点断在哪,方便我们查看程序运行时 硬编码 s2 的值和 base64 编码表的值是否有变化。最终决定在用户输入以后,在对用户输入进行处理以前进行断点观察。
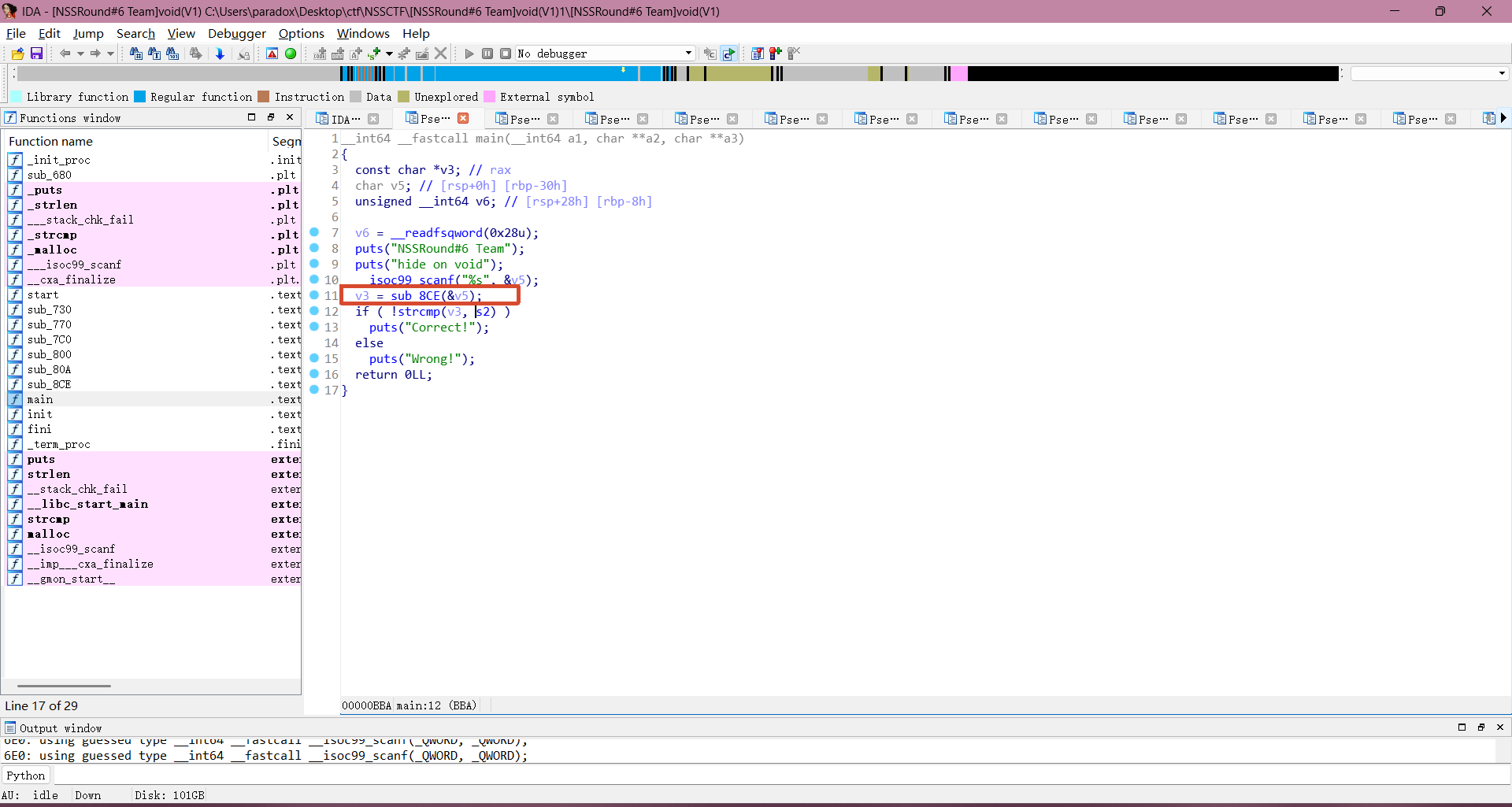
需要断点就需要知道真实地址,在 ida 中,函数偏移量就是 sub_8CE 中的 8CE ,真实地址就是:0x555555400000+ 0x000008CE = 0x5555554008CE
开始在 gdb 中进行断点后,再执行 c (continue)命令继续运行程序
python
b *0x5555554008CE
python
c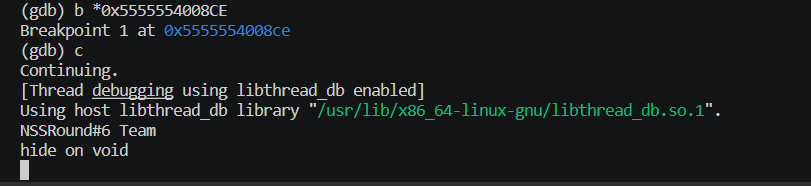
这里提示我们输入一些东西,这里就是程序执行到 main 函数的"用户输入"部分了,随便输入一些东西,让程序继续向下运行后,就会到我们的断点,也就是 "用户输入 base64 处理" 部分
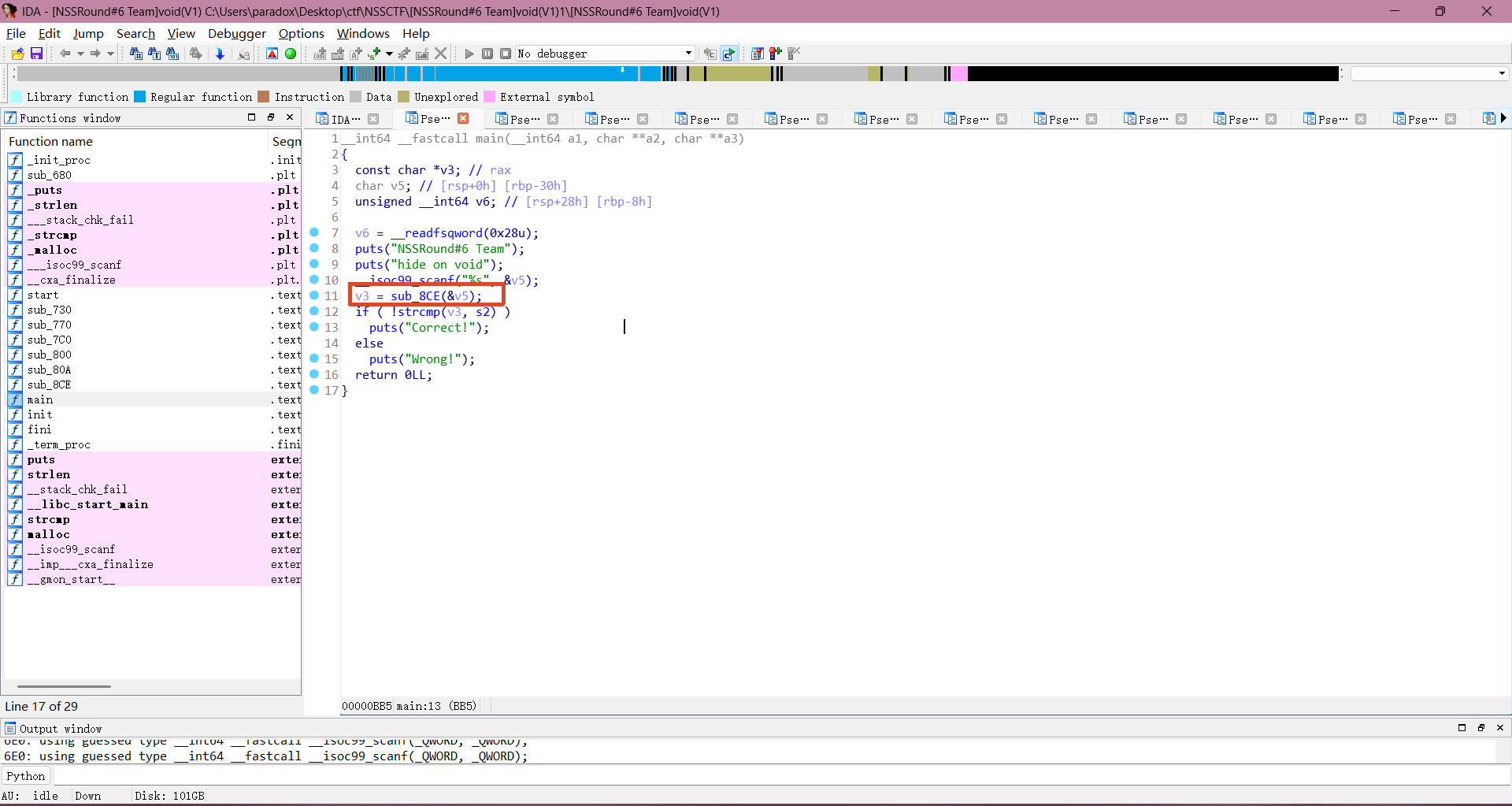
如果程序要调换 base64 编码表的话,内存就应该加载完毕了。此时输入
python
x/s 0x555555602020查看自定义编码表的地址的字符串,发现 base64 编码表真的被替换了!

查看 硬编码 s2 的值,发现是正常的,没有变化
python
x/s 0x555555602080
此时这道题就已经结束了,使用自定义 base64 编码表对 s2 硬编码值进行解码,就可以得到 flag
python
def custom_base64_decode(encoded_str):
# 自定义编码表
custom_table = "W3wp+L4hmzSZOjsR2vkNeBgdirc5uH0x6nIDEfolCVGtyb89Q/qTaFAXY7KJM1UP"
# 移除填充符
if encoded_str.endswith("=="):
encoded_str = encoded_str[:-2]
padding = 1 # 原始长度 % 3 == 1
elif encoded_str.endswith("="):
encoded_str = encoded_str[:-1]
padding = 2 # 原始长度 % 3 == 2
else:
padding = 0 # 原始长度 % 3 == 0
# 将每个字符转换为6位二进制
binary_str = ""
for char in encoded_str:
index = custom_table.index(char)
binary_str += format(index, '06b')
# 移除填充的0(根据原始长度模3的余数)
if padding == 1:
binary_str = binary_str[:-4] # 移除4个填充0
elif padding == 2:
binary_str = binary_str[:-2] # 移除2个填充0
# 将二进制每8位一组转换为字符
result = ""
for i in range(0, len(binary_str), 8):
byte = binary_str[i:i + 8]
if len(byte) == 8:
result += chr(int(byte, 2))
return result
# 目标字符串
target = "NfjN2Fv40AO7rNiXOpjIOT+FrDuXspBniArDiD67jpBION67ONjnx2=="
flag = custom_base64_decode(target)
print(f"Flag: {flag}")运行得到结果:
python
NSSCTF{c9e6703b315f7785acfcb8945b18913a}