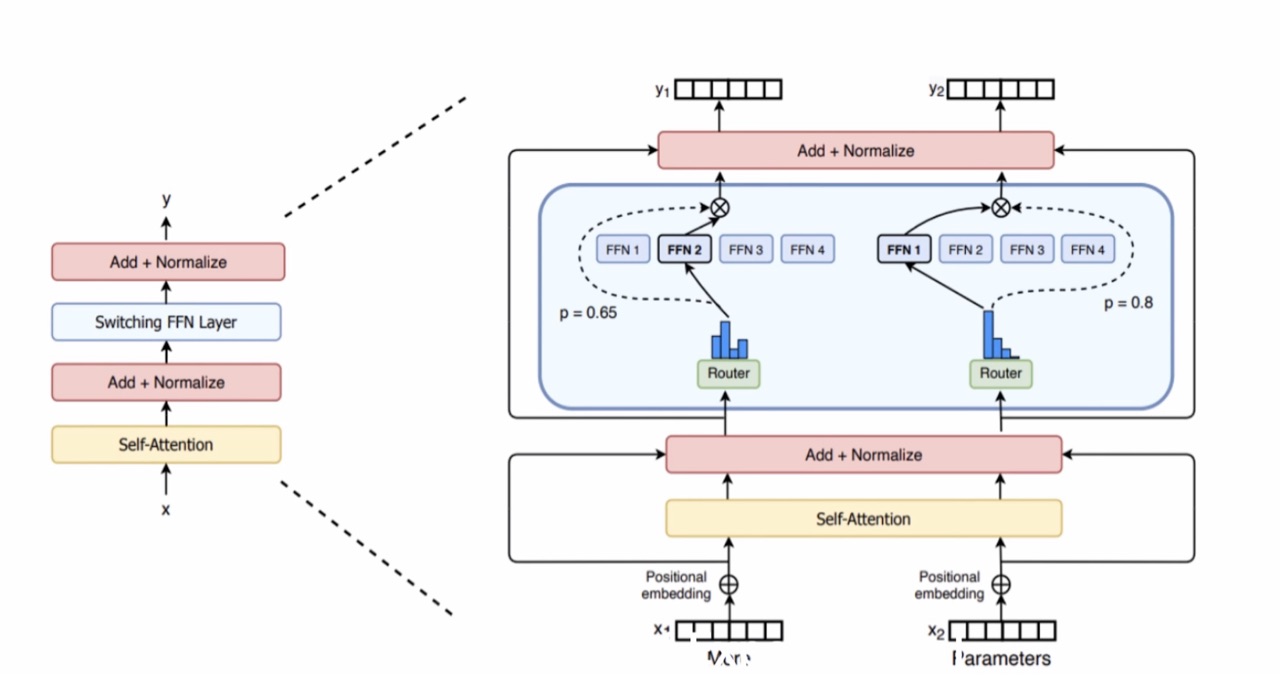
MoE(Mixture of Experts,混合专家模型)是一种"高参数、低计算"的神经网络架构。它通过"分治+条件计算"的策略,在不显著增加计算成本的前提下,将模型总参数量推向极致。
一、 运作机制:路由与稀疏激活
MoE 架构包含三个核心组件:
- 专家(Experts):多个并行的子网络(如 FFN),每个专家在训练中自然演化出处理特定数据模式的能力。
- 门控网络(Gating Network):智能路由器,根据输入内容计算每个专家的权重分数。
- 稀疏激活(Sparse Activation):采用 Top-k 策略(通常 k=1 或 2),只将输入发送给得分最高的 k 个专家进行计算,其余专家保持"休眠"。
- 类比理解:传统模型是"全科医生"看所有病,MoE 则是建立一家"专科医院",由分诊台(门控网络)根据病情(输入)将病人精准分配给对应的专科医生(专家),极大提升了效率。
二、 在大模型中的具体实现
在 Transformer 架构中,MoE 通常用于替换原本的前馈神经网络(FFN)层。
- 共享部分:自注意力(Attention)层通常是共享的,所有 Token 都必须经过。
- MoE 部分:FFN 层被替换为 MoE-FFN 层。每个 Token 经过 Attention 后,由门控网络决定它去往哪个专家 FFN。例如 Mixtral 8x7B 模型,总参数量虽大,但每个 Token 实际只经过约 13B 参数的计算。
三、 核心优势
- 计算效率高:FLOPs(浮点运算量)仅与激活的专家数相关,而非总参数数,推理速度远快于同参数量级的稠密模型。
- 规模易扩展:通过增加专家数量(而非加深网络)来扩容,是构建万亿参数模型的关键技术。
四、Deepseek-V3
DeepSeek 官方论文详细披露了其 MoE 架构,数据最为准确。
- 总专家数:约 1.4 万个(这是一个惊人的"细粒度"设计)。
具体构成:
- 模型共有 61 层,其中 58 层是 MoE 层。
- 每一层包含 1 个共享专家 + 256 个路由专家 = 257 个专家。
- 计算:58 层 × 257 个/层 ≈ 14,906 个专家。
- 激活策略:每个 Token 激活 Top-8 个路由专家(加上共享专家)。
- 特点:采用"小专家、高稀疏"策略,总参数量 671B,但激活量仅 37B。