目录
视图
视图(View)是 数据库中的虚拟表,基于一个或多个实际表的查询结果。
视图 不存储数据,只保存查询定义,每次访问视图时动态生成数据。
视图 不大严谨地讲 可以称作为对于查询结果的进行了一层 封装
<(ºOº)>
视图的语法总体上来讲 其实和 之前的大同小异
创建视图
CREATE VIEW view_name AS
SELECT column1, column2, ...
FROM 表名
WHERE 条件;
SELECT语句:定义视图的查询逻辑- 可以包含多表连接、聚合函数、子查询等
注意 : CREATE VIEW view_name(id, name,gender,age ) AS
当视图中创建了指定列时 这是查询结果中的是否存在重名时就 无关紧要了
修改视图
ALTER VIEW view_name AS
SELECT new_column_list
FROM 表名
WHERE 条件**;**
删除视图
DROP VIEW view_name;
更新视图
UPDATE 视图名 SET 列名 WHERE 条件;
此外在更新时视图有以下的条件
- 视图 必须 基于单个表
- 不能包含聚合函数
- 不能包含 DISTINCT 、GROUP BY 或 HAVING 子句
- 不能包含 子查询
- 不能包含 UNION 操作
无论是在 基础表 还是 在 虚拟表 上的 更新是相互影响的 查询出的结果都是最新的数据
视图优点
-
简单性 : 视图 将频繁使用的复杂查询 封装 一个简单的查询
-
安全性 : 通过视图 限制 用户访问敏感列 隐藏了敏感数据
-
逻辑数据独立性 :视图 提供了 逻辑数据独立性 即使基础表的底层结构发生了改变,也只是通过修改视图定义 而无需使用视图的应用程序 ,将 应用程序 与 数据库 进行了 解耦
-
重命名列 :视图 通过重命名增加了 用户的可读性
索引
概念
索引是一种数据结构,用于加速数据库表中数据的检索速度。
它类似于书籍的目录,通过预先建立关键字段的映射关系,减少查询时需要扫描的数据 量。
优点
索引是数据库和数据结构中用于 提升 数据检索 效率 的重要机制
MySQL 实现的关键目标中 : 安全 与 效率
索引底层结构
索引的底层结构通常由 数据结构与存储方式决定,常见类型包括 B树 、 B+树 、 哈希表 等,不同结构适用于不同场景
HASH
时间复杂度:理想情况下查询为 O(1)
但不支持 范围查询。
二叉搜索树
当为 中序遍历 时 会是一个有序序列---------> 支持 范围查询
但是二叉搜索树 在最极端的情况下退化为 链表
树的高度不确定 时间复杂度为 O(n)
由于数据库的内存 存放在磁盘中的 ,所以每一次子节点的访问都是调用磁盘 IO
磁盘IO是制约 数据库性能的主要因素
N叉树
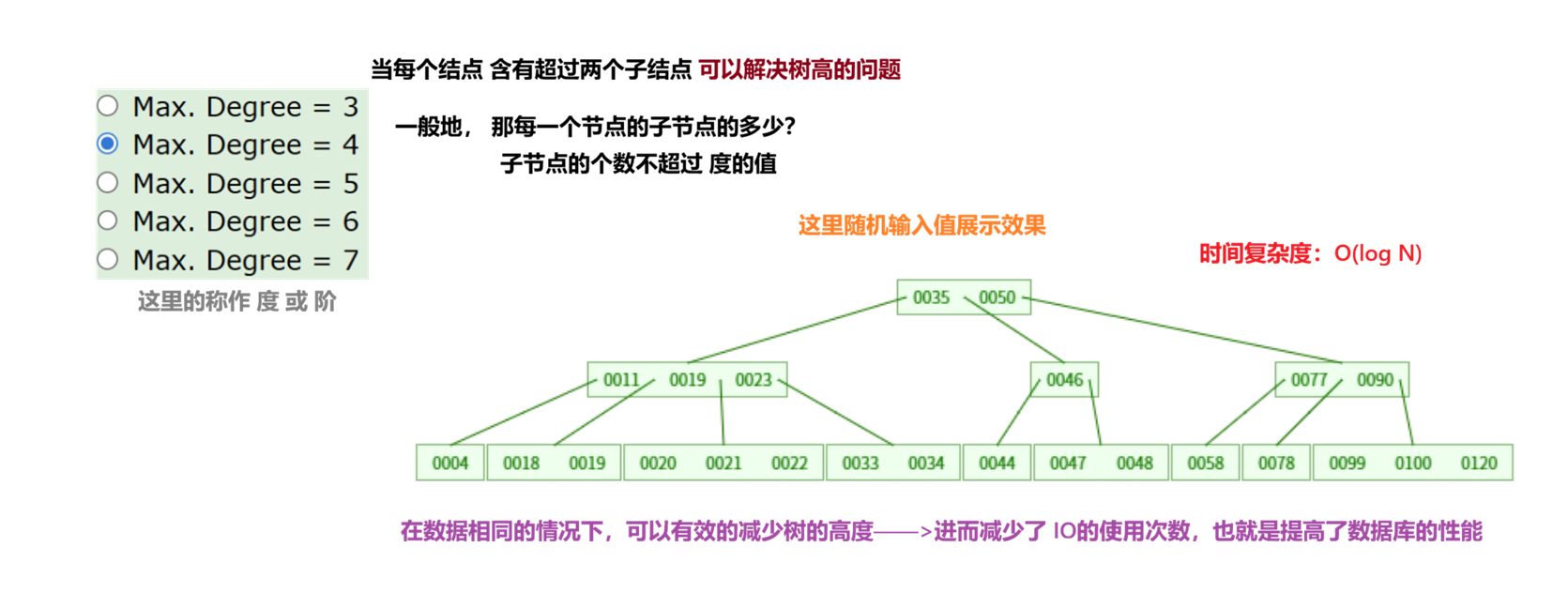
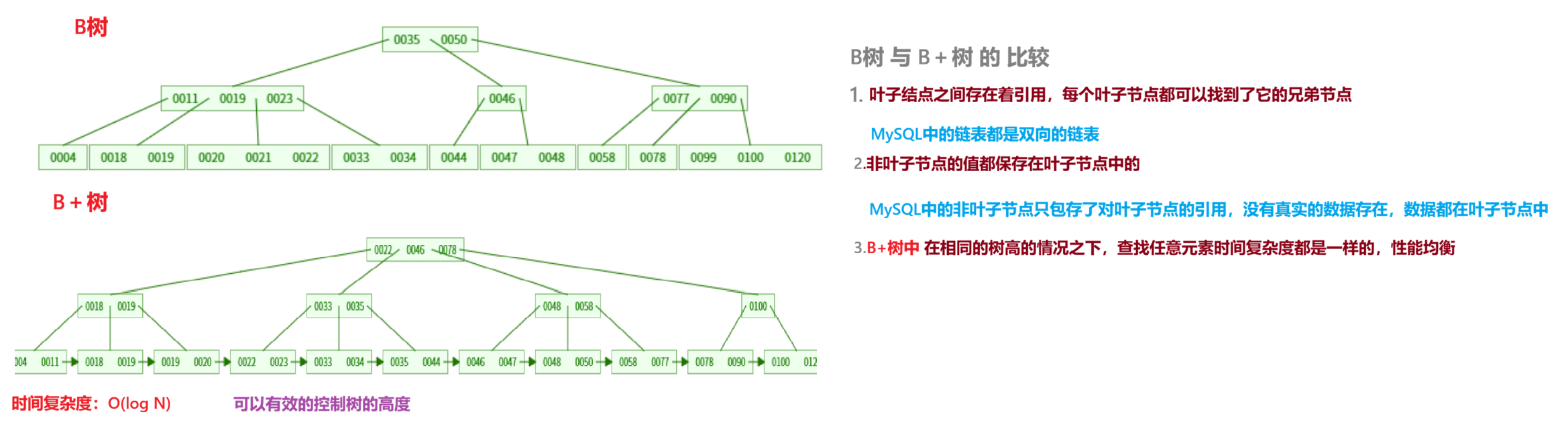
B+树
B+ 又再此处基础上做出了提升
B+树 是 B树 的变种, 优化了范围查询和 磁盘I/O效率
索引原理
要想了解索引的工作原理,那都得从MySQL的存储结构说起
使用页的优势
提高 I/O 效率 优化内存管理 支持事务与锁的粒度
MySQL的页结构
MySQL的 InnoDB 存储引擎 使用 页(Page)作为磁盘和内存交互的基本单位
****默认大小为16KB。
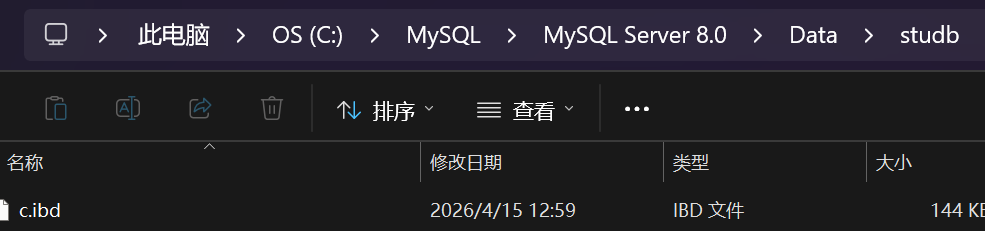
InnoDB 存储引擎 成的表空间的后缀 为 ibd
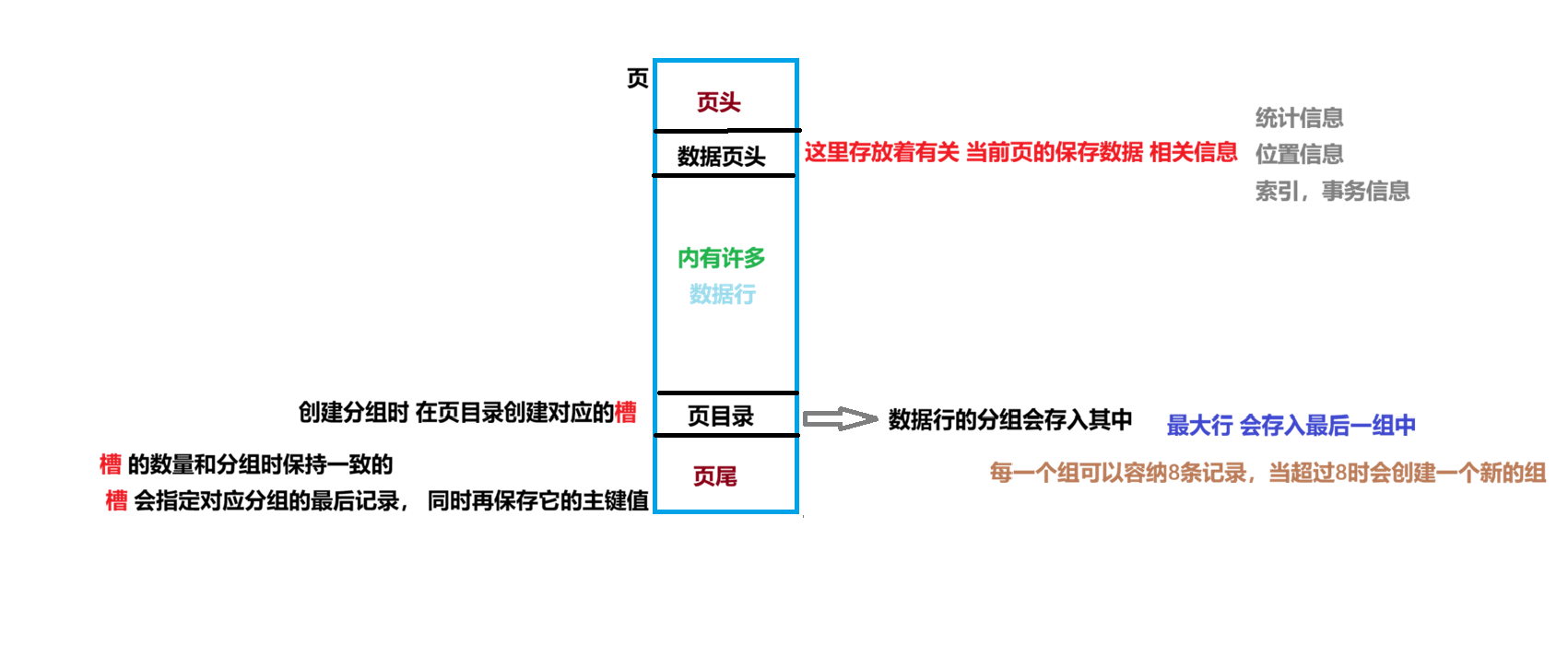
页是数据存储、索引管理以及事务操作的底层载体,其结构设计 直接影响数据库性能。
每一页的存储空间 为16KB (即使内部无数据) 同时会与索引的B+树内节点相互对应
在从内存中 往磁盘写入时 在落盘前都会在日志中一一记录,保证重启时落盘数据不会丢失
MySQL中的页 类型繁多 这里主要使用 数据页(又称索引页) :存储表数据。

简单地说
上页页号 和 下页页号 构成了 双向链表
通过页号 与 页的大小 可以计算出的下一页 与 上一页 在磁盘的偏移量
在页中的数据行 是 一个单向链表
索引分类
在创建索引 时 也会生成 索引树 会占据磁盘内部的内存空间
所以 创建索引时 要确认自己建立索引的数量
数量 过多 会影响增删改查 的效率
主键索引
主键索引 基于 主键(Primary Key )自动创建 索引
-- 创建表时定义主键索引
CREATE TABLE users (
id INT PRIMARY KEY,
name VARCHAR(50)
-- 或通过ALTER TABLE添加主键索引
ALTER TABLE users ADD PRIMARY KEY (id);普通索引
为了提升效率 一般 最常见创建索引的方法
-- 在已有表上添加索引CREATE INDEX 索引名 ON 表名 (字段);
-- 创建表时直接定义索引
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
INDEX index_name (column1)
);
-- 使用ALTER TABLE添加索引
ALTER TABLE table_name ADD INDEX index_name (column1); 唯一索引
CREATE UNIQUE INDEX 索引名 ON 表名 (字段 1, 字段2, ...);
建表创立:
CREATE TABLE 表名 (
column1 datatype,
column2 datatype,
UNIQUE (column1)
);
全文索引
CREATE FULLTEXT INDEX 索引名tON articles(content);
聚集索引
1.与主键索引 为同义词
2.若 表中没有主键的存在 回寻找到第一个UNIQUE or NOT NULL 的列 作为 聚集索引
3.如果既没有 主键 也 没有 合适的 UNIQUE or NOT NULL 那么Innodb 会自动新增插入 ROW_ID字段记录(6字节) 并使用 ROW_ID 作为索引
非聚集索引
聚集索引除外 索引 称为 非聚集索引 或 二次索引
二次索引的每次记录都包含该行列的主键列 , 以及二次索引指定列
Innodb 会根据指定的主键搜索 聚集索引的行,这个行为叫做 回表查询
索引覆盖
非聚集索引的查询过程1.通过索引叶子节点中的索引记录
2.通过索引记录找到索引的主键 ,在主键索引树中找到了相应的完整记录
但是如果
通过索引查询的列 包含 在索引中 就不再到表中 查找 直接在索引里查找
这时就叫做 索引覆盖
删除索引
-- 方式1(通用)
DROP INDEX 索引名
-- 方式2(ALTER TABLE)
ALTER TABLE 表名 DROP INDEX 索引名;N 表名;
查看索引
SHOW INDEX FROM 表名;
与先前查询表 视图 相同