如果你在 AWS 或 GCP 上运行 Kafka 集群,现在就可以做一件事:打开你的云账单,找到 "Data Transfer" 那一行。
你可能会发现一个不该出现在那里的数字。不是几十美元的零头,而是几千甚至上万美元的月度支出,安静地躺在那里,月复一月。
根据 Confluent 的观察数据,跨可用区(AZ)流量费可以占到 Kafka 总账单的 50% 以上。一个典型的 3 节点生产集群(100 MiB/s 写入,3 个 Consumer Group),每月跨 AZ 流量费在 14,000 到 24,000 美元之间,取决于是否做了 Fetch from Follower 等优化。这笔钱不会出现在你的 Kafka 监控面板上,它被归入了 AWS 账单的 "EC2-Other" 分类,和 RDS、ElastiCache、ELB 的流量费混在一起。
这笔钱从哪来?为什么你一直没发现?有没有办法从根本上消除它?
跨 AZ 流量费:写进 Kafka 基因里的"税"
先说一个客观事实:主流云厂商对跨可用区的数据传输收费。AWS 在 EC2 定价页面中明确标注,同一区域内不同可用区之间的数据传输费用为 0.01/GB,**发送和接收双向计费** ------也就是说,每 1 GB 数据跨 AZ 传输,发送方付 0.01,接收方也付 0.01,实际有效费率是 **0.02/GB** 。GCP 在 VPC 网络定价页面中同样列出了跨可用区出站流量 $0.01/GB 的费率。不是隐藏条款,写在官方定价文档里,只是大多数人在评估 Kafka 成本时从来没把它算进去。
Kafka 为了保证高可用,要求集群跨多个可用区部署,生产环境通常部署在至少 3 个 AZ。多 AZ 本身没问题,是云上生产系统的标配。问题在于 Kafka 的数据复制机制和这个部署模型组合在一起时,会在三个地方产生大量跨 AZ 数据传输。一分钱一 GB 听起来不多,但集群每秒处理上百兆字节数据时,这个数字膨胀得很快。
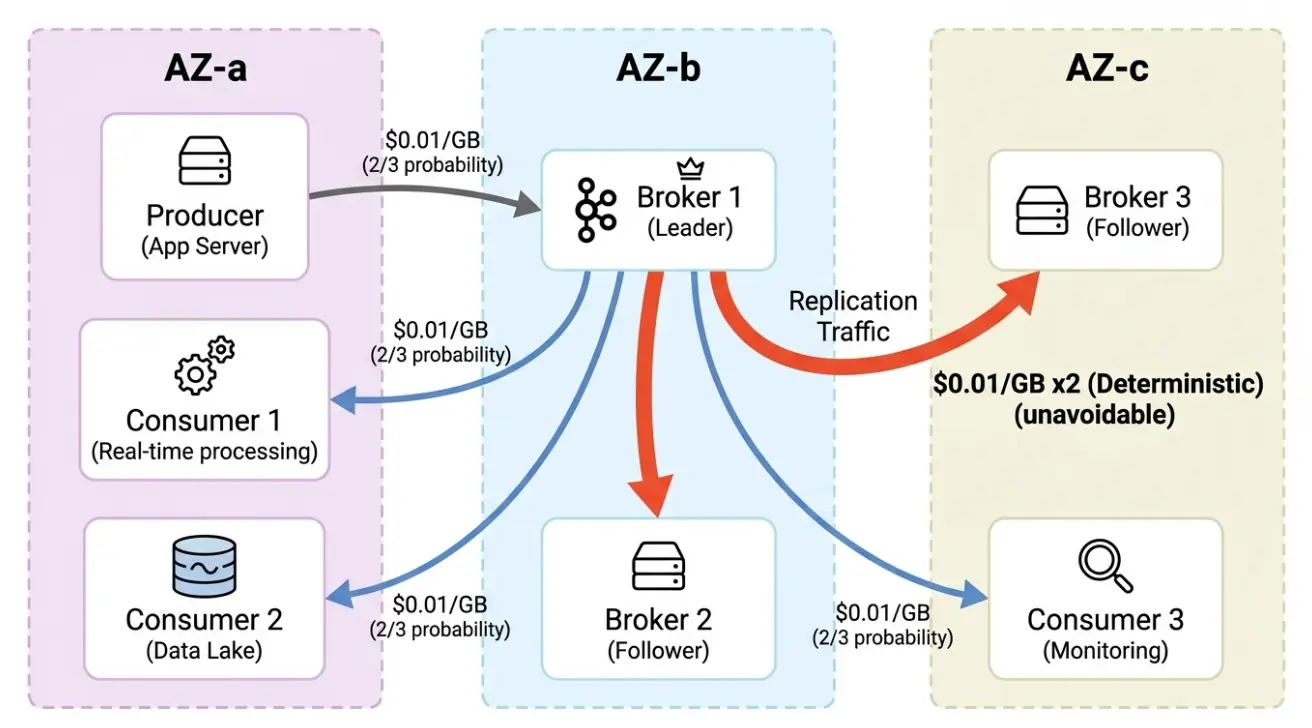
跨 AZ 流量来自三个地方:
- Producer → Leader Broker:每个 Partition 只有一个 Leader,分布在不同 AZ 上。3 AZ 部署中,Producer 有约 2/3 的概率需要跨 AZ 写入。每条消息,三分之二的概率交一次"过路费"。
- Leader → Follower 副本复制:最大的流量来源。Kafka 默认 3 副本,Leader 必须将数据复制到另外两个 AZ 的 Follower。每写入 1 GB,确定性地产生 2 GB 跨 AZ 流量。无法关闭,无法绕过。
- Broker → Consumer 读取:Consumer 默认从 Leader 拉取数据,同样面临 2/3 的跨 AZ 概率。3 个 Consumer Group(实时处理、数据湖、监控),流量再乘以 3。
三跳叠加,流量费滚雪球一样越滚越大。副本复制是确定性的、不可避免的。只要 Kafka 还在用"每个 Broker 存自己的数据副本"这个模型,这笔钱就是铁打的。
算一笔账
数字比文字有说服力。用一个中等规模的生产场景,在很多互联网公司的核心业务集群里很常见:
| 参数 | 值 |
|---|---|
| 写入吞吐量 | 100 MiB/s(持续) |
| 副本数 | 3(Kafka 默认) |
| Consumer Group | 3 个(实时处理 + 数据湖 + 监控) |
| 数据保留 | 72 小时 |
| 部署模式 | 3 AZ(生产环境标准配置) |
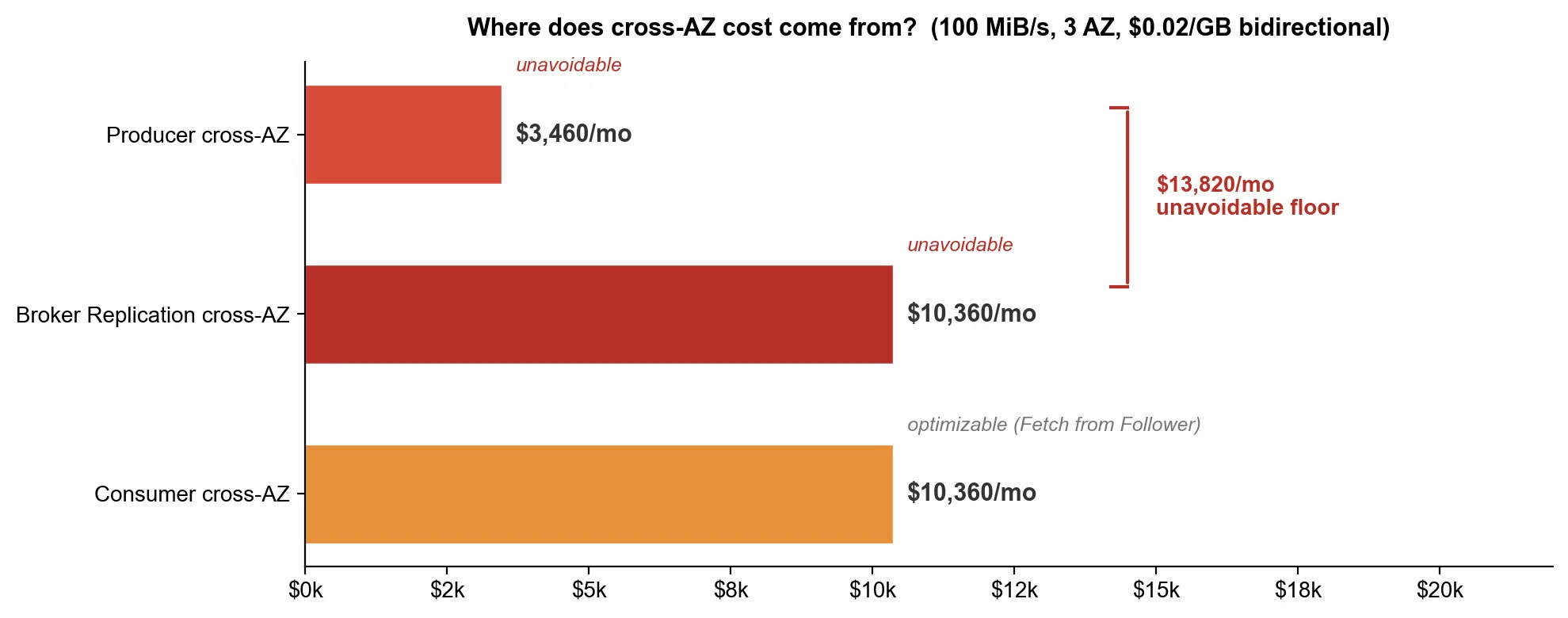
Producer 端:100 MiB/s 持续写入,一个月大约 259 TB 总流量(100 × 86,400 × 30 ÷ 1,000,000),三分之二跨 AZ,约 173 TB。AWS 跨 AZ 双向收费,有效费率 $0.02/GB,大约 3,460 美元/月。听起来还行?别急。
副本复制才是大头。每写入 1 GB,Leader 向两个 Follower 各复制一份,产生 2 GB 跨 AZ 流量。一个月约 518 TB,双向计费折合 10,360 美元/月。这笔费用是确定性的,除非你愿意把副本数降到 1,但没人会在生产环境这么做。这还只是写入端------Consumer 端同样不便宜,3 个 Consumer Group 各自读取全量数据,三分之二跨 AZ,又是约 518 TB,再花 10,360 美元/月。
三项加起来,理论上限约 24,000 美元/月。Fetch from Follower(KIP-392)可以让 Consumer 从同 AZ 的 Follower 读取,大幅减少第三项;Rack-Aware 配置也能帮上一些忙。但 Producer 写入和副本复制仍然无法避免,这两项加起来就是约 13,800 美元/月。所以即便把 Consumer 端优化做到极致,跨 AZ 流量费的下限仍在 14,000 美元左右:
| 费用项 | 月费用 | 是否可优化 |
|---|---|---|
| Producer 跨 AZ | ~$3,460 | 有限(Rack-Aware 可部分缓解) |
| 副本复制跨 AZ | ~$10,360 | 不可避免(架构决定) |
| Consumer 跨 AZ (3 groups) | ~$10,360 | 可大幅减少(Fetch from Follower) |
| 未优化合计 | ~$24,000 | --- |
| 优化后下限 | ~$14,000 | Producer + 副本复制不可避免 |
| EC2 实例费(对比) | ~$3,000 | --- |
| EBS 存储费(对比) | ~$2,000 | --- |
花在"看不见的流量"上的钱,比花在"看得见的服务器"上的钱还多。那为什么大多数团队从来没注意到?
一笔被精心"藏"起来的费用
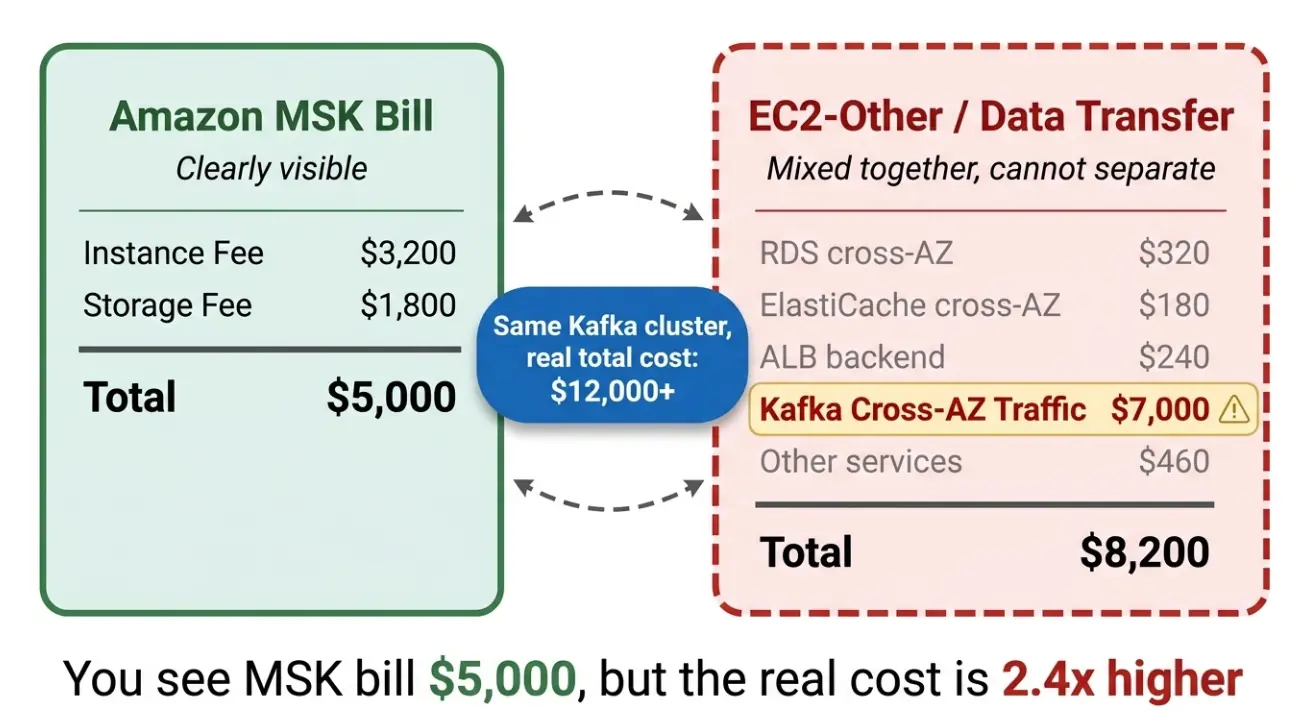
因为账单结构天然地把这笔费用藏起来了。
AWS 将跨 AZ 流量费归入 "EC2-Other" 或 "Data Transfer" 大类,和账号下所有服务的网络流量混在一起。RDS 的跨 AZ 读写、ElastiCache 的集群同步、ALB 的后端通信,全部汇总在同一行。想拆出 Kafka 贡献了多少?几乎不可能。
自建 Kafka 的情况尤其隐蔽。你看到的 EC2 实例费和 EBS 存储费加起来可能只有 5,000 美元,觉得"还行"。但另外 14,000 到 24,000 美元的跨 AZ 流量费正安静地躺在 EC2 账单的某个角落里,和其他几十个服务的网络费用混在一起,谁也说不清它属于谁。
三个原因让这笔费用"隐形":
- 账单归类模糊:跨 AZ 流量费归入 "EC2-Other",和几十个服务的网络费混在一起
- 与 Kafka 账单分离:EC2 实例费和 EBS 存储费看起来清清楚楚,但跨 AZ 流量费被归到通用的 EC2 网络费用下,不会和 Kafka 集群关联
- 账号级别汇总:无法按服务或集群拆分,多团队共享账号时分账几乎不可能
不是 AWS 故意隐藏,是账单结构天然地让这笔费用不可见。
配置调优救不了你
能不能通过调优配置来解决?能做的有限。
Fetch from Follower 可以减少 Consumer 端的跨 AZ 流量,确实有帮助。但 Producer 写入和副本复制加起来占了跨 AZ 流量费的大头,是 Kafka 架构决定的,配置层面无解。你可以调整 replica.selector.class 让 Consumer 就近读取,但你没办法让 Leader 不向 Follower 复制数据,也没办法让 Producer 只写入同 AZ 的 Partition。这不是配置问题,是架构问题。
根本原因在于 Kafka 的存储模型:每个 Broker 在本地磁盘上维护自己的数据副本,Broker 之间通过网络同步。这个模型在数据中心时代是合理的,机器之间的网络流量不收费。但在云上,跨 AZ 流量要花钱,而且不便宜。Kafka 的架构是为一个网络免费的世界设计的,现在运行在一个网络收费的世界里。
要从根本上消除这笔费用,需要回答一个问题:在云上,Kafka 真的还需要在应用层做多副本复制吗?
重新思考存储:我们为什么要重新设计 Kafka
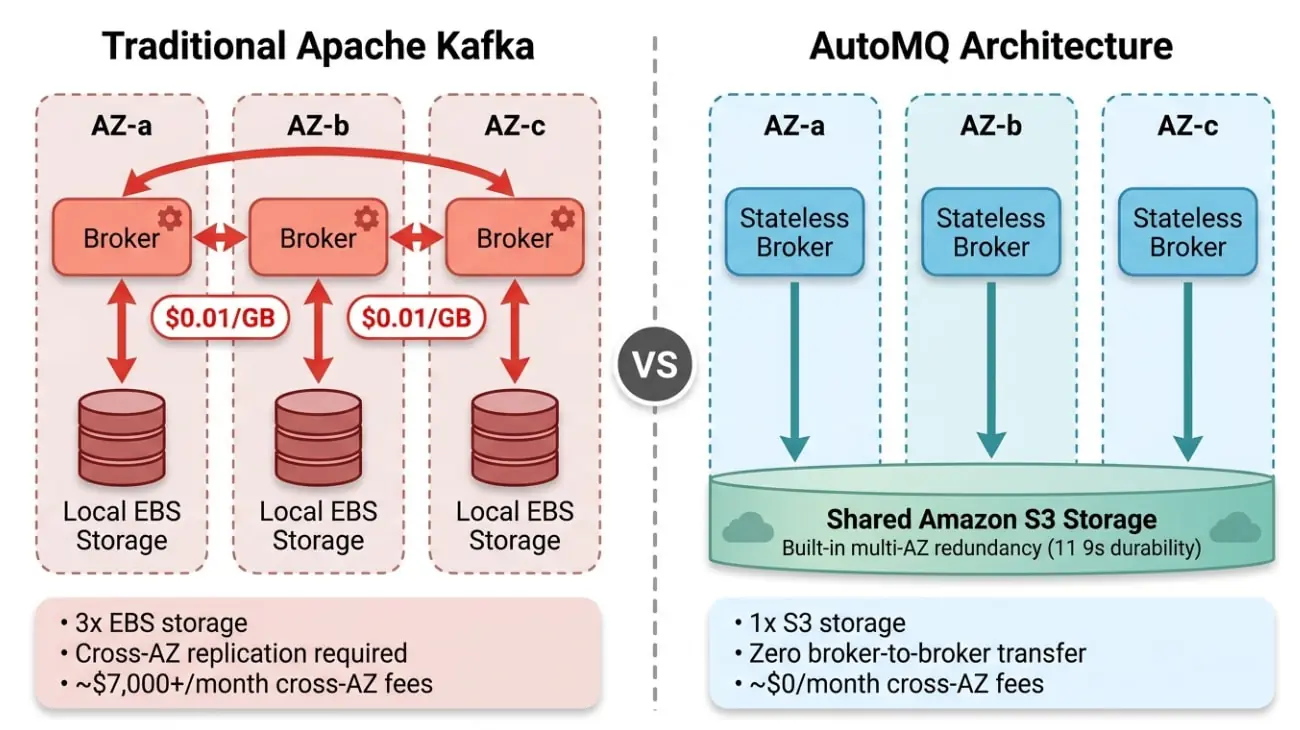
AWS S3 提供 99.999999999%(11 个 9)的数据持久性,内置多 AZ 冗余。数据写入 S3 后,AWS 自己在多个 AZ 之间做冗余存储,对用户完全透明,不收取跨 AZ 流量费。S3 已经在做 Kafka 副本复制想做的事情,跨 AZ 保证数据不丢,而且做得更好、更便宜。既然云厂商已经在基础设施层解决了数据持久性问题,应用层再做一遍多副本复制,不仅是重复劳动,还要为此付出高昂的跨 AZ 流量费。
我们做 AutoMQ,就是因为这些问题。Kafka 诞生于 LinkedIn 的数据中心,它的架构假设(本地磁盘便宜、网络流量免费、机器是长期运行的宠物)在云上全部失效了。跨 AZ 流量费只是其中一个症状,背后是存储架构和云环境的错位。与其在一个数据中心时代的架构上不断打补丁,不如从存储层开始重新设计。通过技术创新降低用户在云上运行 Kafka 的成本,是我们最看重的事情之一。
AutoMQ 保持 100% 的 Apache Kafka 协议兼容,你现有的所有 Kafka 客户端、Connect、Streams 都可以直接对接,但从底层重新设计了存储架构。核心变化只有一个:把数据持久化从 Broker 本地磁盘(EBS)迁移到对象存储(S3),让 S3 来承担数据持久性和多 AZ 冗余的职责。
这里需要澄清一个常见的混淆。这不是 Kafka 社区的 Tiered Storage(KIP-405)方案,两者区别是根本性的:
| Tiered Storage (KIP-405) | AutoMQ Diskless | |
|---|---|---|
| 思路 | "少一些磁盘" | "零磁盘" |
| 热数据 | 仍在本地 EBS | 不存在本地持久数据 |
| S3 角色 | 仅存冷数据 | 唯一持久化层 |
| Broker 间复制 | 仍然需要 | 完全消除 |
| 跨 AZ 流量费 | 没有减少 | 接近 $0 |
| 扩缩容 | 仍需迁移热数据 | 秒级,只涉及元数据 |
Tiered Storage 把冷数据搬到 S3,热数据仍然在本地磁盘上,Broker 之间的副本复制依然存在,跨 AZ 流量费一分钱没少。AutoMQ 更彻底:S3 是唯一的持久化层,Broker 本地不保留任何持久数据。没有本地数据,就没有什么需要在 Broker 之间"同步"的,副本复制从架构层面被消除了。
直接写 S3 延迟不会很高吗?会。S3 的写入延迟在百毫秒级别,对 Kafka 不可接受。AutoMQ 的解法是在 Broker 本地使用一个小型云存储卷(如 EBS,默认 20GB)作为 Write-Ahead Log(WAL)。数据先写入 WAL 即可返回 ACK,写入延迟控制在 10ms 以内,然后异步批量刷入 S3。WAL 本身是持久化的(EBS 自带持久性),但它的角色是写缓冲而非长期存储,数据最终归宿是 S3。
关键在于 WAL 只存在于单个 Broker 本地,不需要和其他 Broker 同步,所以不引入跨 AZ 复制。额外的好处是它把大量小写入聚合成大批次再刷入 S3,降低了 S3 API 调用次数和成本。这个低延迟 EBS WAL 是 AutoMQ 商业版的能力;开源版本使用 S3 WAL,延迟稍高但同样消除了跨 AZ 复制。
存储委托给 S3 之后,Broker 变成了真正的无状态计算节点。Broker 挂了,新 Broker 从 S3 读数据,秒级恢复,不需要从其他 Broker "追赶"几个小时。扩容,加一个 Broker 立刻可以服务任何 Partition,因为数据在 S3 上所有 Broker 都能访问。缩容,直接下线,不需要先迁移数据。AutoMQ 甚至可以跑在 Spot 实例上,传统 Kafka 做不到这一点。
在这个架构下,之前的三个流量来源被逐一消除:
- Producer → Broker:通过 AZ-Aware 调度,Producer 优先写入同 AZ 的 Broker
- 副本复制:不再存在,S3 自带多 AZ 冗余
- Consumer ← Broker:同样通过 AZ-Aware 调度,Consumer 优先从同 AZ 的 Broker 读取
跨 AZ 流量费从每月 14,000 ~ 24,000 美元,降至接近零。 你现有的 Producer、Consumer、Kafka Connect、Kafka Streams、Flink 作业,全部可以无缝切换,不需要改一行代码。
架构分析到这里,剩下的问题是:在真实的生产环境里,这套方案跑起来到底怎么样?
从 MSK 到 AutoMQ:FunPlus 如何把 Kafka 成本砍掉 60%+
FunPlus 是一家总部在瑞士的全球游戏公司,员工超过 2000 人,旗下 State of Survival 超过 1.5 亿次下载。他们的数据基础设施跑在 AWS 上,Kafka 集群支撑着日均数十亿条消息的实时数据管道:玩家行为分析、实时反作弊、游戏内推荐、运营数据看板,全部依赖这条管道。

游戏行业把跨 AZ 流量费的放大因素都踩到了:流量大、多 AZ 高可用部署、全球多区域。一个热门游戏的后端,Kafka 集群必须跨 3 个 AZ 部署来保证高可用,而传统 Kafka 的多副本复制机制意味着每条消息都要在 AZ 之间复制两次。再加上 Producer 和 Consumer 的跨 AZ 通信,流量费迅速累积。
FunPlus 的基础设施团队在做成本审计时发现:跨 AZ 流量费已经成为 Kafka 基础设施成本的最大单项支出。不是实例费,不是存储费,而是那笔藏在 EC2 账单里、谁也说不清归属的网络流量费。多 AZ 部署是高可用的刚需,不能砍;多副本复制是 Kafka 保证数据不丢的核心机制,也不能关。问题卡在这里:高可用和低成本在传统 Kafka 架构下是矛盾的。
他们评估了几个方案。Fetch from Follower 可以让 Consumer 就近读取,减少一部分流量,但集群内部的副本复制才是大头,这笔费用是架构决定的,配置层面无解。减少副本数?日均处理数十亿条消息的生产环境,没人敢冒这个险。最终他们选择从架构层面解决,切换到 AutoMQ。
迁移完成后,整体 Kafka 基础设施成本降低了 60% 以上,其中跨 AZ 流量费从最大支出项大幅缩减是关键贡献因素。存储成本也显著下降,从 EBS 三副本到 S3 单份存储。目前 FunPlus 的 AutoMQ 集群跑在 AWS us-west-2,日均处理约 70 亿条消息,峰值 QPS 超过 15K,管道全程平稳运行,上下游的 Flink 作业、数据湖写入、实时分析服务没有做任何改动。
"切换到 AutoMQ 后,整体成本降低了 60% 以上,跨 AZ 流量费不再是我们最头疼的账单项。" --- FunPlus 基础设施团队
这个案例值得讲,不只是因为 60% 的成本降幅,更因为游戏行业恰好把跨 AZ 流量费的每一个放大因素都踩到了:高吞吐、多 Consumer、全球部署。但这个问题不局限于游戏行业。任何在云上运行中大规模 Kafka 集群的团队,电商的订单流、金融的交易管道、物联网的设备数据、SaaS 的事件总线,都面临同样的账单结构,只是程度不同。
你该怎么做
如果你开始怀疑自己的 Kafka 账单里也藏着类似的"惊喜",有三件事可以立刻做:
1. 查一下你的账单。 登录 AWS Cost Explorer,筛选 "EC2-Other" 类别下的 "Data Transfer" 费用,看看那个数字是不是比你预期的大。GCP 用户可以在 Billing 的 Network 分类下找到类似信息。如果数字意外地大,Kafka 很可能是主要贡献者。
2. 估算你的跨 AZ 流量费。 用这个简化公式:
plaintext
月跨 AZ 流量费 ≈ 写入吞吐(MiB/s) × 2,628,000 × (2/3 + 2 + fanout × 2/3) × $0.02/GB ÷ 102450 MiB/s 写入、2 个 Consumer Group,未优化的月跨 AZ 流量费大约 10,000 美元;即便 Consumer 端做了 Fetch from Follower 优化,Producer + 副本复制仍然要花约 6,700 美元。
3. 评估架构级方案。 跨 AZ 流量费占到 Kafka 总成本 30% 以上时,配置层面的优化已经不够了。是时候从存储架构层面解决,把数据持久性交给 S3,让 Broker 回归它本该扮演的角色:一个高效的消息路由节点,而不是一个昂贵的数据存储节点。
AutoMQ 提供了一个无需信用卡的免费托管体验环境,几分钟内创建一个真实的 Kafka 集群,亲自验证零跨 AZ 流量费的效果。欢迎注册试用。
回到你的 AWS 账单,Data Transfer 那一行。现在你知道那个数字是怎么来的了。
本文数据基于 AWS 公开定价(us-east-1 区域,2026 年 4 月)。实际费用因区域、流量模式和配置而异。