开篇介绍:
hello 大家,那么在上一篇博客中,我们学习了磁盘如何工作,知道了分块分区的高妙,也了解了文件属性原来是存储inode里面,最后一起去探寻了软链接和硬链接的奇妙,相信大家定是受益颇多,那么大家,接下来在本篇博客中,我们将去真正的探寻和了解Linux系统中文件系统的奥秘,相信我,这段旅程将会非常丰富多彩。
话不多说,我们开始开始~
一、宏观认知:ext2 是 Linux 的 "学校宿舍园区管理体系"
(一)核心逻辑:没有文件系统,磁盘就是 "杂乱的闲置操场"
硬盘分区就像一块没规划的学校闲置操场,你想存文件,就好比把学生的书本、衣物、生活用品随便堆在操场上 ------ 下次找的时候翻半天找不到,还容易和其他人的东西混在一起。格式化就是给操场搭建 "宿舍园区框架",而 ext2 文件系统就是这套框架的 "管理手册",明确规定:
- 床位怎么分(数据块划分);
- 学生信息怎么记(inode 属性记录);
- 找人怎么查住址(目录映射);
- 床位和学号怎么管理(位图管理)。
没有这套 "管理手册",磁盘就只是一堆无序的存储硬件,无法实现文件的有序管理和高效存取。
(二)ext2、ext3、ext4 的关系:同园区 "宿舍翻新升级"
这三个文件系统就像同一所学校宿舍园区的 1.0、2.0、3.0 版本,核心管理逻辑完全一致,只是在后续升级中新增了更便捷的功能,具体对比如下:
| 版本 | 核心定位 | 新增功能 | 类比宿舍升级场景 |
|---|---|---|---|
| ext2(1.0) | 基础版文件系统 | 无日志功能 | 老式宿舍园区,仅记录学生入住和搬离信息,不记录日常出入详情,一旦出现物品丢失,难以追溯原因 |
| ext3(2.0) | 带日志的 ext2 | 日志功能 | 宿舍园区新增 "出入登记本",详细记录学生和访客的进出信息,物品出现问题后,能通过登记本快速追溯源头 |
| ext4(3.0) | 高性能 ext3 | 支持更大文件 / 分区、更快读写速度、延迟分配机制 | 宿舍园区扩容,新增电梯和智能快递柜,不仅能容纳更多学生,还能大幅提升物品存取效率,减少快递积压 |
我们后续将以 ext2 为核心原型进行讲解,因为掌握了它的基础逻辑后,ext3/ext4 的新增功能就像 "给宿舍加个登记本""装个电梯" 一样简单易懂,只需理解新增功能的核心作用即可快速掌握。
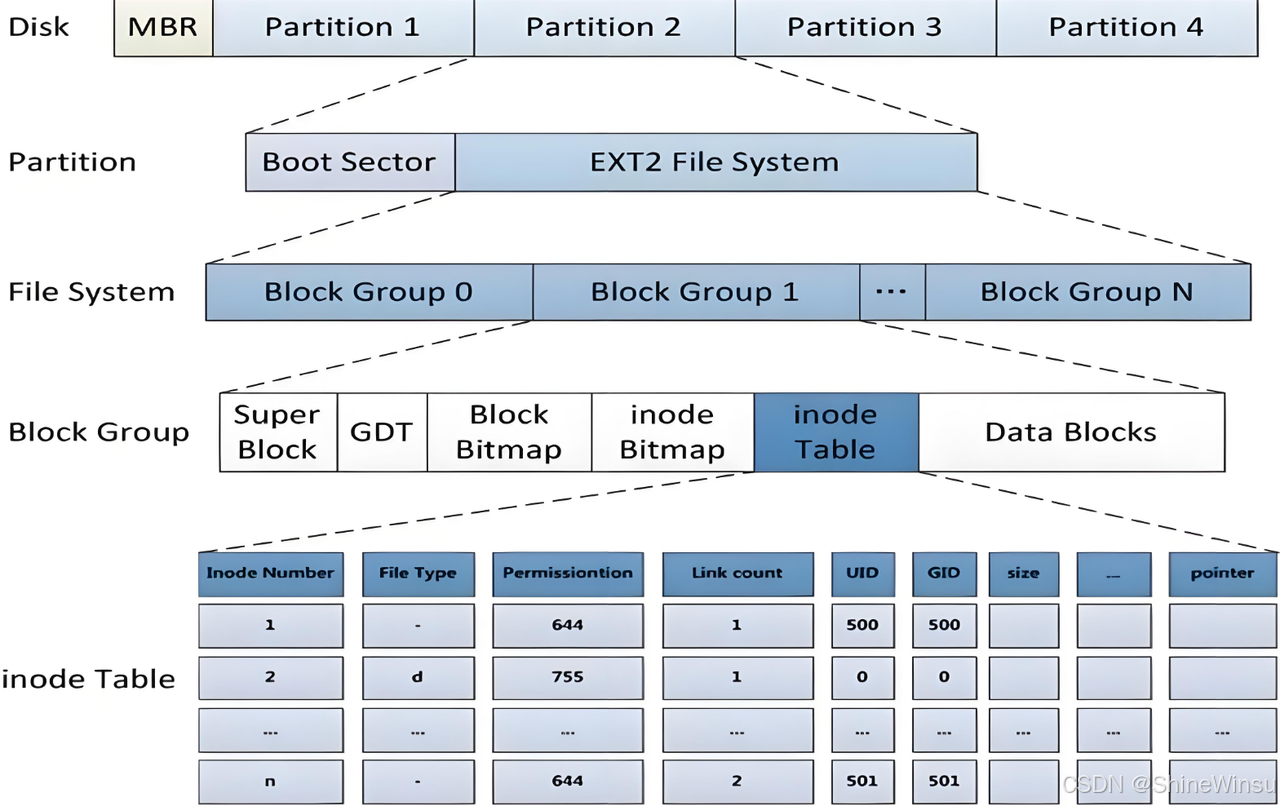
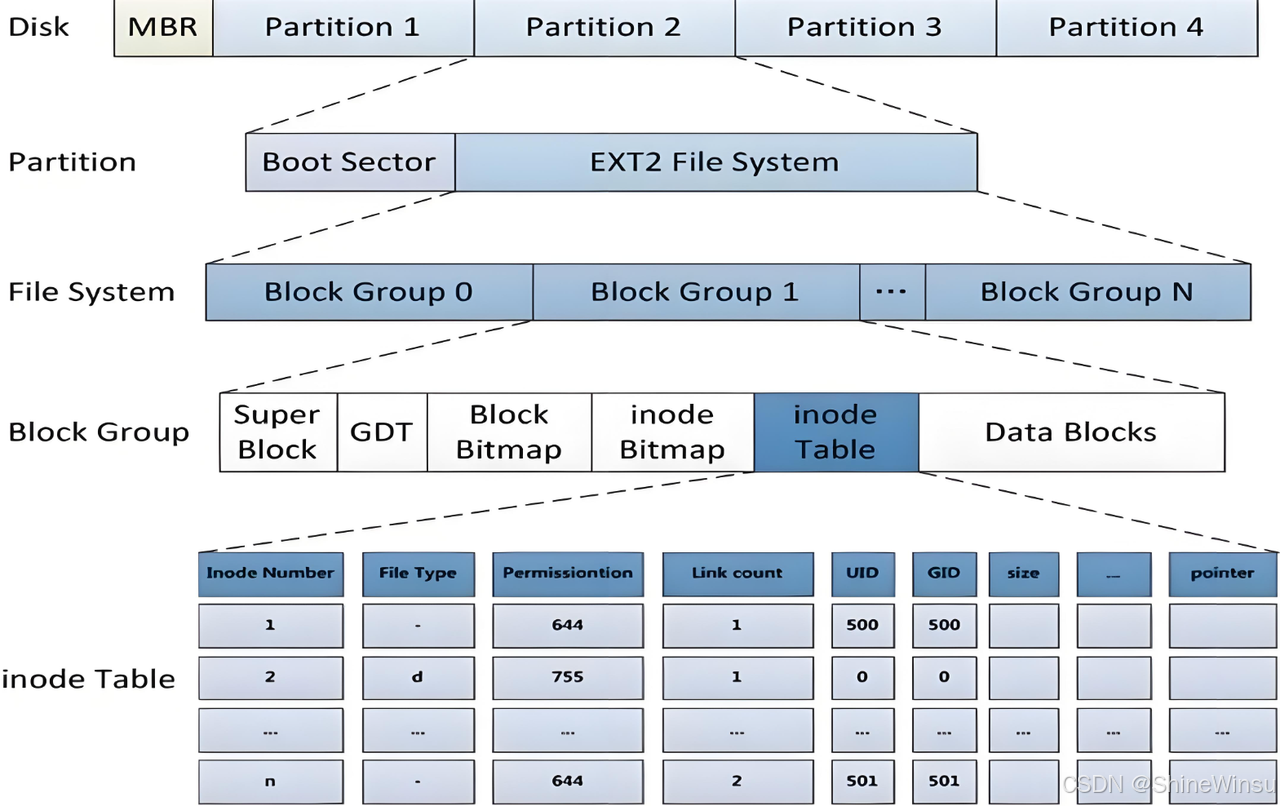
(三)ext2 的整体架构:把 "大园区" 拆成 "多栋宿舍楼"
ext2 会将整个磁盘分区按照固定大小划分为多个独立的块组(Block Group)。比如一个 100GB 的分区,若设置每栋 "宿舍楼" 的大小为 4MB,那么整个分区会被分成 25600 个块组。每个块组都是一栋结构完全相同的 "宿舍楼",这种设计就像宿舍园区的多栋楼宇模式,具有三大核心优势:
- 管理高效:所有楼宇采用统一的管理模式,宿管阿姨只需接受一次培训,就能胜任所有楼宇的管理工作,降低管理成本;
- 容错性强:一栋楼出现问题(比如水管破裂、电路故障),其他楼宇不受影响,仍能正常使用,保障整体系统的稳定性;
- 存取高效:学生物品(文件数据)分散存储在不同楼宇,避免单栋楼的物品积压,减少数据读写时的寻址距离,提升存取速度。
关键前置:启动块(Boot Block)------ 园区的 "大门门禁 + 总导览图"
每个分区最开头的 1KB 空间是启动块,这是 PC 行业的统一标准,相当于宿舍园区大门的 "门禁系统 + 总导览图",主要承担两大核心职责:
- 存储分区基础信息:包括分区大小、分区类型等,相当于 "园区总面积、楼宇分布" 的说明,让系统了解分区的基本属性;
- 存储系统启动数据:电脑开机时,会优先读取启动块中的信息,从而找到系统分区的位置,相当于 "学生进门先看总导览图,明确目标楼宇的位置"。
需要注意的是,启动块是硬件层面的固定区域,任何文件系统都不能对其进行修改 ------ 就像宿舍园区的门禁系统不能随意拆卸,否则会导致系统无法启动,"园区" 无法正常运营。启动块之后的区域,才是 ext2 文件系统的 "真正运营区域"。
(四)格式化的底层过程:给 "闲置操场" 建成宿舍园区的全流程
当你执行 mkfs.ext2 /dev/sdb1 命令对分区进行格式化时,系统会按照以下步骤完成 "宿舍园区搭建",每一步都对应具体的运营准备工作:
- 确定核心运营参数
- 选择 "床位尺寸"(块大小) :通过
mkfs.ext2 -b 块大小 /dev/设备名指定,常见的床位尺寸为 4KB,也可设置为 1KB、2KB 或 8KB。不同尺寸的 "床位" 适配不同的存储场景:- 4KB:适合存储中等大小的文件(比如课本、笔记本),能兼顾空间利用率和存取速度,是最通用的选择;
- 8KB:适合存储大文件(比如被褥、行李箱),一次能存放更多物品,但存储小文件(比如一支笔的记录文件)时,会浪费大量空间;
- 1KB:适合存储大量小文件(比如作业草稿、便签),能避免空间浪费,但存取大文件时需要频繁切换 "床位",导致速度变慢。
- 计算 "楼宇数量"(块组数量):通过 "分区总大小 ÷ 块组大小" 得出,比如 100GB 分区搭配 4MB 块组,可算出 25600 栋 "宿舍楼"。
- 搭建运营管理设施
为每栋 "宿舍楼" 配备核心管理模块,相当于给每栋楼搭建关键管理部门:
- "园区管理处总台账"(超级块):记录全局资源信息;
- "楼宇楼层导视图"(GDT,块组描述符表):标注楼宇内部布局,即文件内容;
- "床位占用指示灯"(块位图):标记数据块的占用状态;
- "学号占用登记表"(inode 位图):标记 inode 的占用状态;
- "学生档案柜"(inode 表):存储文件属性和数据块地址,即文件属性。
- 初始化物品存储区
清空 "床位区"(数据块区)和 "学生档案柜"(inode 表),并在 "指示灯 / 登记表"(位图)上将对应的位置标记为 "空闲",为后续接收 "学生物品"(文件数据)做好准备。
二、块组内部结构:每栋 "宿舍楼" 的 6 大核心管理部门
每栋 "宿舍楼"(块组)内部包含 6 个 "核心管理部门",各司其职、协同工作。我们结合 "宿舍园区日常管理" 场景,逐个拆解它们的作用、工作逻辑和实际操作:
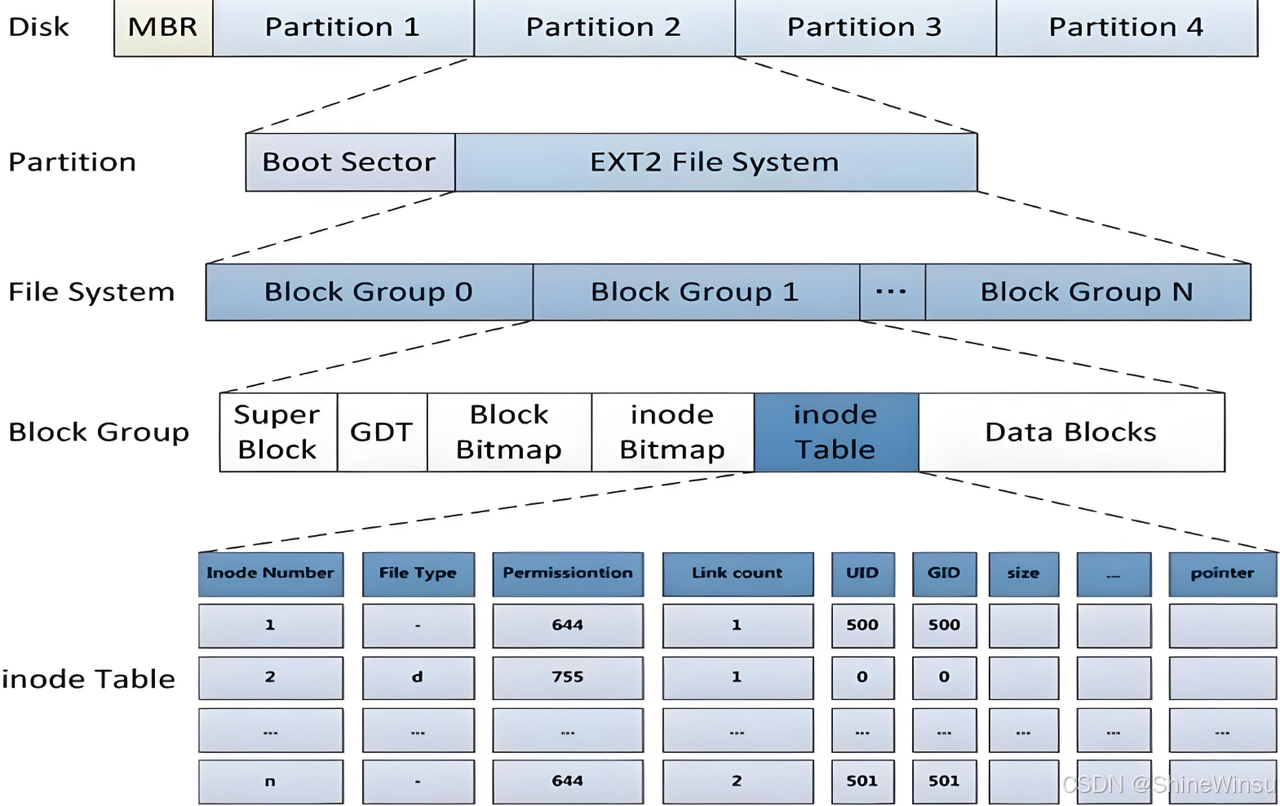
2.1 超级块(Super Block):园区的 "管理处总台账"
核心作用:记录整个 "宿舍园区"(分区)的全局资源与运营情况,相当于园区管理处的 "总台账"。每栋楼的 "宿管值班室" 都会存放一份备份(第一栋楼必须存储,其他楼作为冗余备份),宿管通过它能快速掌握全局情况,具体包括:
- 资源总量:总床位数(block 总量)、总学号数(inode 总量);
- 空闲资源:空闲床位数、空闲学号数;
- 规格参数:床位尺寸(block 大小)、学生档案单尺寸(inode 大小)、每栋楼的床位数 / 学号数;
- 运营记录:最近一次园区开放(分区挂载)时间、最近一次学生入住(写入数据)时间、最近一次园区检修(磁盘校验)时间。
备份机制:防止 "总台账丢失"
如果唯一的总台账损坏(超级块损坏),整个宿舍园区会陷入混乱 ------ 宿管不知道有多少床位和学号可用,学生物品也无法正常查找。因此 ext2 会在多栋楼备份超级块,备份位置按 "2ⁿ -1" 的规律分布(比如楼宇 0、1、3、5、9、17...)。不同块大小对应的首个备份位置不同,例如 4KB 块大小时,第一个备份超级块在 32768 字节处(即 8 个块的位置)。就算某栋楼的台账损坏,也能从其他楼调取备份恢复,保证园区正常运营。
超级块核心信息详解(对应结构体字段)
| 结构体字段 | 通俗含义 | 实际运营场景 |
|---|---|---|
| s_inodes_count | 整个分区的 inode 总数(总学号数) | 管理处掌握 "总共有多少个学号可用",学生入住(创建文件)时先判断是否有学号可分配 |
| s_blocks_count | 整个分区的 block 总数(总床位数) | 知道 "总共有多少个床位",学生存放大件物品(比如行李箱)时,判断是否有足够床位空间 |
| s_free_blocks_count | 空闲 block 数(空闲床位数) | 学生入住时先查询该数值,若为 0 则提示 "园区床位满了,无法入住"(对应磁盘空间不足) |
| s_free_inodes_count | 空闲 inode 数(空闲学号数) | 学生入住时若该数值为 0,就算有空闲床位也无法办理入住(没有学号记录学生信息) |
| s_log_block_size | 块大小(单位:2^ 该数值 字节) | 比如值为 12,即 2¹²=4096 字节 = 4KB,确定每个床位的固定尺寸 |
| s_inodes_per_group | 每个块组的 inode 数(每栋楼的学号数) | 分配学号时,计算目标楼宇位置(比如学号 10000,每栋楼 8192 个学号,就分配到第 2 栋楼) |
| s_mtime | 最近一次挂载时间 | 管理处判断 "园区上次开放是什么时候",若长时间未开放,可能触发磁盘校验(检修园区) |
| s_wtime | 最近一次写入数据时间 | 跟踪 "最近一次学生入住时间",用于制定园区管理策略(比如每月最后一次入住后进行安全检查) |
| s_mnt_count | 挂载次数 | 记录 "园区开放的次数",达到阈值后提示 "需要检修园区" |
| s_max_mnt_count | 最大挂载次数阈值 | 比如设置为 20 次,开放 20 次后,下次开放会自动触发磁盘校验(全面检修) |
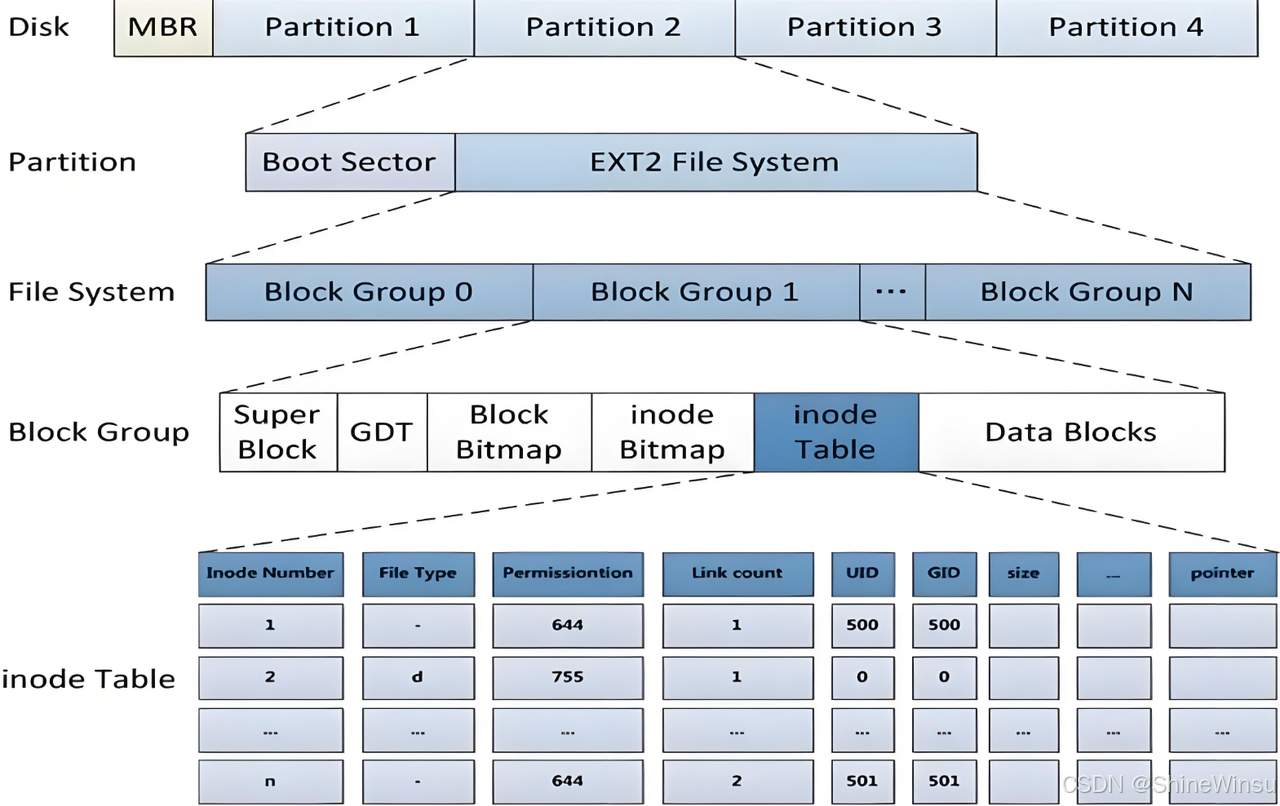
2.2 GDT(块组描述符表):楼宇的 "楼层导视图"
核心作用:记录单栋 "宿舍楼"(块组)的局部布局与资源情况,相当于每栋楼大厅的 "楼层导视图"。学生和宿管通过它能快速定位关键设施的位置,具体包括:
- 床位占用指示灯(Block Bitmap)的位置;
- 学号占用登记表(Inode Bitmap)的位置;
- 学生档案柜(Inode Table)的起始位置;
- 该栋楼的空闲床位数和空闲学号数。
核心信息详解(对应结构体字段)
| 结构体字段 | 通俗含义 | 实际运营场景 |
|---|---|---|
| bg_block_bitmap | Block Bitmap 的起始 block 地址(床位指示灯的位置) | 宿管找空闲床位时,按该地址快速定位 "指示灯",提高寻址效率 |
| bg_inode_bitmap | Inode Bitmap 的起始 block 地址(学号登记表的位置) | 学生入住(创建文件)时,按该地址找到 "学号登记表",快速查找空闲学号 |
| bg_inode_table | Inode Table 的起始 block 地址(学生档案柜的位置) | 找到空闲学号后,按该地址去 "档案柜" 取出档案单并写入学生信息 |
| bg_free_blocks_count | 该块组的空闲 block 数(该栋楼的空闲床位数) | 学生入住时优先选择空闲床位多的楼宇,避免物品集中堆放导致的存取拥堵 |
| bg_free_inodes_count | 该块组的空闲 inode 数(该栋楼的空闲学号数) | 学生入住时优先选择空闲学号多的楼宇,减少跨楼找学号的成本,提升入住效率 |
| bg_used_dirs_count | 该块组的目录数(该栋楼的楼层数) | 记录楼宇有多少个楼层(比如 3 层、5 层),方便分层管理 |
备份机制:和超级块同步备份
GDT 会与超级块在同一批楼宇中进行备份(比如超级块备份在楼宇 0、1、3,GDT 也会在这三栋楼备份)。就算某栋楼的 "楼层导视图" 损坏(比如数据丢失),也能从备份楼宇调取副本恢复,不影响该栋楼的正常运营。
2.3 块位图(Block Bitmap):楼宇的 "床位占用指示灯"
核心作用:用 1 个二进制位(bit)标记 1 个数据块的占用状态,相当于每栋楼楼层的 "床位占用指示灯"。每个 "指示灯" 对应一个 "床位"(数据块),规则简单直观:
- 灯亮(bit=1):床位已被占用,上面存放了学生物品(文件数据);
- 灯灭(bit=0):床位空闲,可存放学生物品(文件数据)。
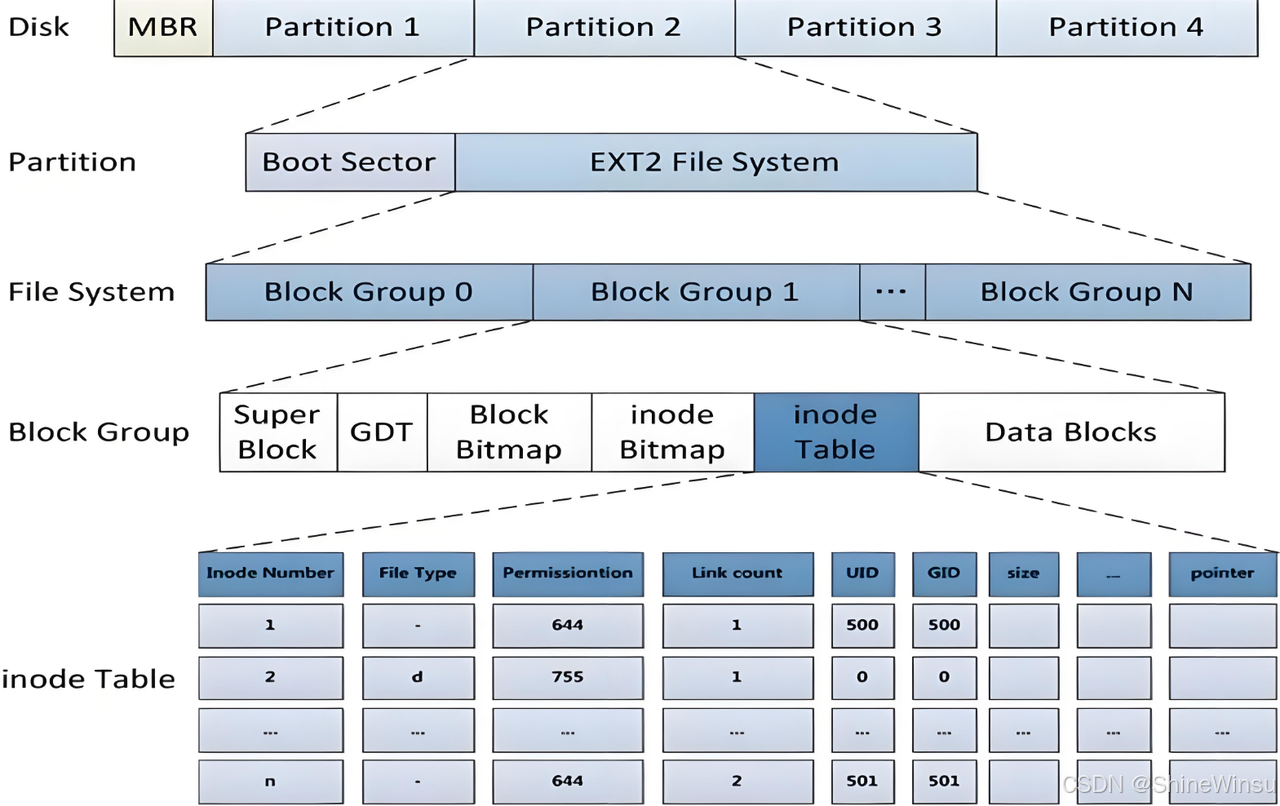
存储与管理逻辑
- 指示灯面板大小:以 4KB 块大小为例,一个块位图占用 4096 字节,相当于 32768 个二进制位,能管理 32768 个数据块(对应 128MB 存储容量);
- 查找空闲床位的逻辑:宿管办理学生入住时,从指示灯面板的第 1 位开始顺序扫描,找到第一个 "灭灯" 的位置(空闲床位),将其改为 "亮灯"(标记为占用),然后安排学生将物品放到这个床位上。
实际运营场景演示
假设指示灯面板的某一段二进制数据为 10010000(共 8 个 bit),对应 8 个床位:
- 第 1 个和第 4 个床位灯亮(bit=1):已存放学生物品(比如第 1 个床位放课本,第 4 个床位放衣物);
- 其余 6 个床位灯灭(bit=0):处于空闲状态;
- 宿管为新入住学生分配床位(需要 1 个床位),会将第 2 个床位的 "指示灯" 改为亮灯(bit=1),然后让学生把物品放到第 2 个床位上。
2.4 inode 位图(Inode Bitmap):楼宇的 "学号占用登记表"
核心作用:用 1 个二进制位(bit)标记 1 个 inode 的占用状态,逻辑与块位图完全一致,相当于 "学号占用登记表"。每个 "登记项" 对应一个 "学号"(inode),规则如下:
- 登记为 "已用"(bit=1):学号已被使用,对应某个学生(文件);
- 登记为 "空闲"(bit=0):学号空闲,可分配给新学生(文件)。
实际运营场景演示
宿管办理学生入住(创建文件)时,需要完成两步关键操作:
- 查看学号占用登记表,找到第一个 "空闲" 的学号,将其标记为 "已用";
- 前往学生档案柜(Inode Table)中找到该学号对应的档案单,写入学生的核心信息(比如姓名、班级、床位号、入住时间等)。
2.5 inode 表(Inode Table):楼宇的 "学生档案柜"
核心作用:存储所有 inode(学生信息 + 床位地址),相当于每栋楼的 "学生档案柜"。每个档案单(inode)对应一个学生(文件),  里面记录两大核心内容,缺一不可:
里面记录两大核心内容,缺一不可:
(1)学生基本信息(档案单的 "基础信息栏")
| 结构体字段 | 通俗含义 | 实际运营场景 |
|---|---|---|
| i_mode | 文件类型 + 访问权限 | 记录是普通学生 / 楼层管理员 / 临时访客(对应文件是普通文件 / 目录 / 软链接),以及谁能查看 / 修改学生物品(所有者 / 组 / 其他人的读写执行权限) |
| i_uid | 所有者 ID | 记录学生的专属标识(比如管理员的 ID 是 0,对应园区管理员) |
| i_gid | 所属组 ID | 记录学生所属的班级(比如管理员组的 ID 是 0,对应管理员班级) |
| i_size | 文件大小(字节) | 记录学生物品的总容量(比如 654 字节的文本文件,相当于 654 页的练习册) |
| i_atime | 最近访问时间 | 记录学生最后一次取用物品的时间(比如用 cat 命令打开文件) |
| i_mtime | 最近修改时间 | 记录学生最后一次更新物品的时间(比如在练习册上新增笔记,对应修改文件内容) |
| i_ctime | 最近属性修改时间 | 记录宿管最后一次修改档案信息的时间(比如调整学生权限,对应修改文件权限) |
| i_links_count | 硬链接数 | 记录学生的 "别名" 数量(比如学生有正式名和昵称,硬链接数 = 2) |
| i_blocks | 占用床位数 | 记录学生物品总共占用的床位数量(比如大件行李占 2 个床位,对应 i_blocks=2) |
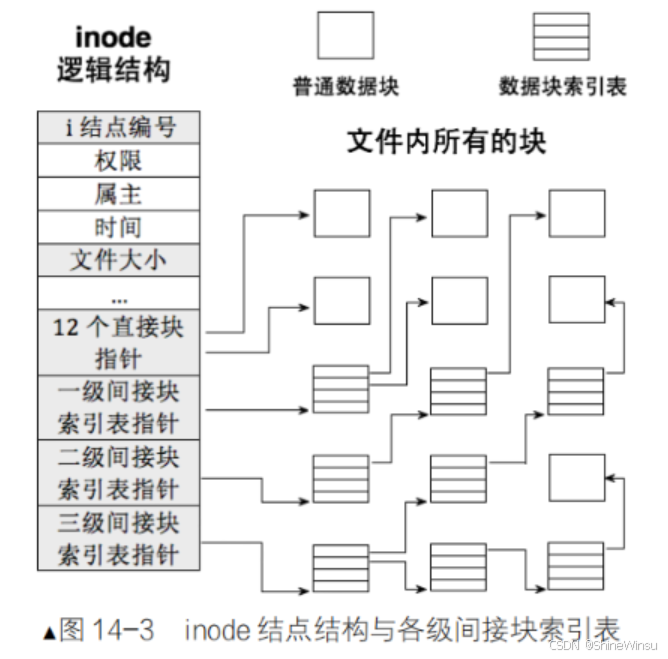
(2)物品存放地址(档案单的 "床位清单")
核心字段是 i_block[15],这是一个长度为 15 的数组,相当于档案单上的 "床位清单",记录学生物品存放在哪些床位上。为了兼顾小件和大件物品的存储效率,15 个 "床位指针" 分为 4 种类型,适配不同容量的物品:
| 指针类型 | 数量 | 存储逻辑 | 最大存储容量(4KB 床位) | 适用物品类型 |
|---|---|---|---|---|
| 直接块 | 前 12 个 | 直接指向物品存放的床位 | 12×4KB=48KB | 小件物品(比如练习册、文具,对应文本文件、配置文件) |
| 一级间接块 | 第 13 个 | 指向 "床位索引表",索引表中记录 1024 个物品床位地址(注:4KB 块可存 4096/4=1024 个 4 字节指针) | 1024×4KB=4GB | 中等物品(比如行李箱、书包,对应高清图片、小型视频) |
| 二级间接块 | 第 14 个 | 指针→一级索引表→二级索引表→物品床位 | 1024×1024×4KB=4TB | 大件物品(比如衣柜、床垫,对应大型数据库文件、电影) |
| 三级间接块 | 第 15 个 | 指针→一级索引表→二级索引表→三级索引表→物品床位 | 1024×1024×1024×4KB=4PB | 超大型物品(比如组合家具,对应企业级数据仓库) |
关键特点
- 档案单大小固定:格式化时可通过
mkfs.ext2 -i inode 大小 /dev/设备名指定,常见 128 字节或 256 字节。大 inode 可存储更多扩展属性,小 inode 则节省空间; - 学号唯一:以整个 "宿舍园区"(分区)为单位进行编号(比如分区内第一个学号是 1 号,第二个是 2 号),不能跨分区重复,相当于学生的 "唯一学籍号",意思就是说在同一个分区内,是不可以有相同的inode,而要是不同的分区,就可以有重复的。
2.6 数据块(Data Block):楼宇的 "学生床位区"
核心作用:存储文件的实际内容,是每栋楼中面积最大的区域,相当于 "学生床位区"。不同类型的文件,床位的使用方式也不同:
| 文件类型 | 床位存储内容 | 类比宿舍场景 |
|---|---|---|
| 普通文件(文本、图片、视频) | 文件的实际内容(二进制数据) | 床位上存放学生的具体物品(课本、衣物) |
| 目录 | "文件名→inode 号" 的映射关系(每个目录项包含 inode 号、文件名长度、文件名) | 床位上存放 "楼层房间号清单",记录该楼层内每个学生的名字和对应的学号(比如 101 房间→学号 100) |
| 软链接(快捷方式) | 目标文件的路径(比如 "3 楼 102 房间→课本") | 床位上存放 "物品领取条",写着目标物品的位置,学生拿条后去对应位置取用物品 |
| 设备文件(键盘、鼠标等) | 不存储实际内容,指向对应的硬件设备 | 床位上存放 "设备领用凭证",记录硬件的领取地址(比如从器材室领取键盘) |
关键特点
- 床位大小固定:格式化时确定(比如 4KB),一旦确定无法修改,所有床位都是统一尺寸;
- 床位编号唯一:以整个 "宿舍园区"(分区)为单位进行编号,不能跨分区重复,相当于床位的 "唯一房间号",和inode同样的道理;
- 空间分配规则:即使文件只有 1 字节(比如一张便签),也会占用一整个床位(比如 1 字节文件存放在 4KB 块中,会浪费 3KB 空间,相当于用大床位放一支笔)。
注意事项:一个文件不一定只对应一个数据块:
一、先理解 "数据块":固定大小的 "储物箱"
硬盘在格式化时,会被划分成一个个大小固定的 "数据块"(比如 4KB、8KB,相当于 "储物箱" 的规格)。每个数据块有唯一编号,是文件存储的 "最小单位"。
- 类比:学校储物间的储物箱,每个箱子大小一样(比如 40L),编号从 1 开始。
二、分情况看 "文件与数据块的关系"
文件是否只对应一个数据块,取决于文件大小 和数据块大小:
情况 1:小文件 → 可能只对应 1 个数据块
如果文件的大小 **≤ 一个数据块的容量 **,那么一个数据块就够装。
- 例子:数据块大小是 4KB(4096 字节),你写了一个只有 100 字节的 "购物清单.txt"(相当于一张小纸条)。这张纸条可以直接放进一个 4KB 的储物箱里,此时文件只对应 1 个数据块。(注意:剩余的 3996 字节空间会被浪费,这是 "块内空间浪费" 的正常现象)
情况 2:大文件 → 对应多个数据块
如果文件的大小 **> 一个数据块的容量 **,就需要多个数据块来装。
- 例子:数据块大小是 4KB,你有一个 10MB 的 "毕业视频.mp4"(相当于一整箱书)。10MB = 10×1024KB = 10240KB,需要的 "储物箱" 数量是
10240KB ÷ 4KB = 2560个,此时文件对应 2560 个数据块。
三、文件系统的 "多块管理技巧":直接块 + 间接块
如果文件很大,光靠 "一个一个数数据块" 效率太低,文件系统会用 **"直接块 + 间接块"** 的方式来管理,就像给储物箱加了 "索引表":
-
直接块:小文件(比如几十 KB)直接在 "文件档案" 里记录数据块编号。类比:你有 5 本小书,直接在 "物品清单" 上写 5 个储物箱的编号(1、2、3、4、5)。
-
一级间接块:中等文件(比如几百 MB)会用一个 "索引块",里面记录了大量数据块的编号。类比:你有 1000 本书,直接写 1000 个编号太麻烦,于是在 "物品清单" 里写一个 "索引箱编号",这个索引箱里存着 1000 个储物箱的编号。
-
二级 / 三级间接块:超大文件(比如几个 GB)会用 "索引块的索引块",层层嵌套管理更多数据块。类比:你有 100 万本书,索引箱也装不下编号了,于是在 "物品清单" 里写 "一级索引箱编号",一级索引箱里写 "二级索引箱编号",二级索引箱里才是 100 万本书的储物箱编号。
四、总结:文件与数据块的关系
- 小文件(≤ 数据块大小):可能只对应 1 个数据块;
- 大文件(> 数据块大小):对应多个数据块,甚至需要 "间接块" 辅助管理。
这就像 "小物品用一个储物箱,大物品用多个储物箱,超大物品用带索引的储物箱组合",文件系统通过这种方式,既能高效存小文件,也能轻松装下大文件~
这一点大家平时可能会忽略,还是比较重要的。
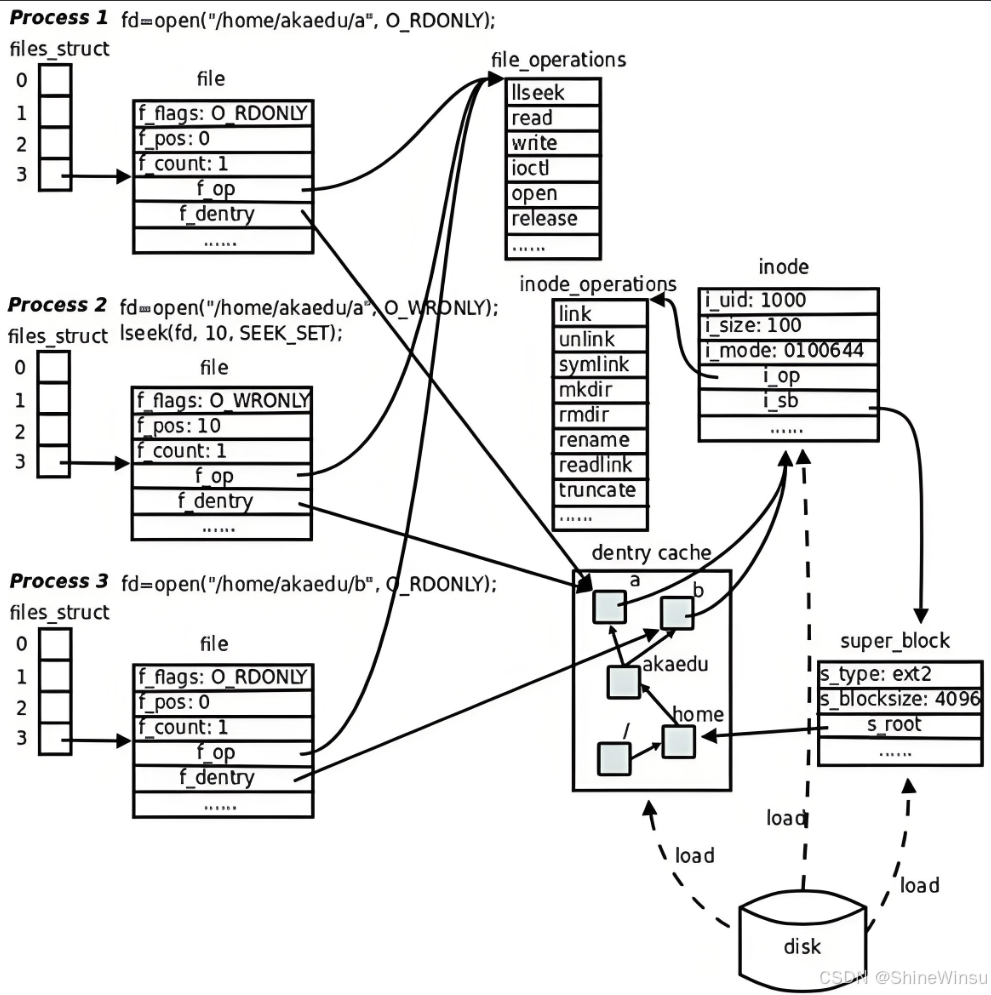
三、文件的增删查改:园区的 "学生物品全生命周期管理"
结合前面介绍的 6 大核心部门,我们以 "入住存物→找物取物→更新物品→搬离清物" 的完整流程,演示 ext2 文件系统的底层操作逻辑,每个步骤都对应宿舍园区的实际运营场景,让抽象的技术操作更易理解: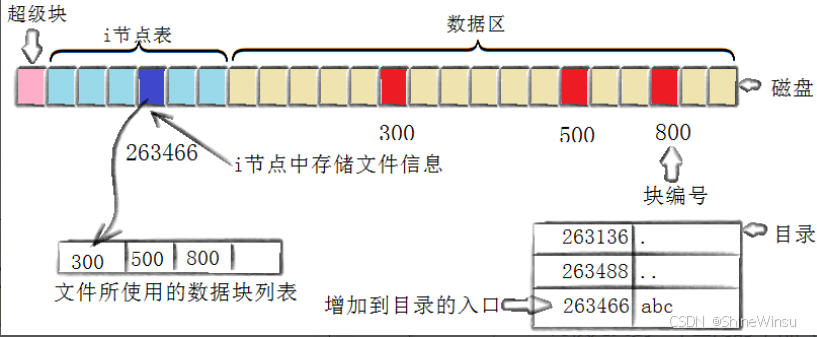
(一)入住存物(创建文件:touch test.txt + echo "hello" > test.txt):4 步标准流程申请 inode(分配 inode 号)
- 系统查看分区全局信息(超级块),筛选出空闲 inode 数量较多的块组(比如块组 0);
- 块组内查询 inode 位图,找到第一个空闲的 inode 号(比如 100),将位图中对应位从 0(空闲)改为 1(占用);
- 系统在该块组的 inode 表中,找到 inode 号 100 对应的 inode 结构体,写入文件核心属性:文件大小 5 字节、所有者 UID 为 0(root)、权限为
rw-r--r--(所有者可读写,组和其他人可读)、创建时间、最近修改时间等。
申请数据块(分配数据块地址)
- 系统查看该块组的块位图,找到第一个空闲的数据块(比如块号 200);若文件大小超过单个数据块容量(如 4KB),则连续或分散分配多个数据块,同时将块位图中对应位从 0(空闲)改为 1(占用);
- 将 "hello" 这 5 字节数据写入数据块 200 中。
关联 inode 与数据块(记录数据块地址)
- 系统在 inode 号 100 的结构体中,通过
i_block[0](直接块指针)记录数据块 200 的地址,建立 inode 与数据块的映射关系,使文件属性与实际数据关联。
更新目录项(写入文件名与 inode 映射)
- 系统找到当前目录的 inode(比如目录 inode 号 50),从该 inode 的
i_block数组中获取目录数据块的地址(比如块号 300); - 在目录数据块 300 中新增一条目录项记录:
test.txt → 100(文件名与 inode 号的映射),完成文件名到 inode 的关联。
(二)找物取物(查询文件:cat test.txt):3 步导航流程查目录项,找 inode 号
- 用户输入文件名 "test.txt",系统找到当前目录的数据块(块号 300),扫描其中的目录项,根据 "test.txt" 匹配到对应的 inode 号 100。
查 inode,验证权限
- 系统根据 inode 号 100 定位到对应块组的 inode 表,读取该 inode 的权限字段(
i_mode),检查当前用户是否有读取权限(此处rw-r--r--允许所有用户读取,权限验证通过)。
通过 inode 找数据块,读取数据
- 系统从 inode 号 100 的
i_block[0]中获取数据块地址 200; - 读取数据块 200 中的内容 "hello",返回给用户。
(三)更新物品(修改文件:echo "world" >> test.txt):2 种场景修改文件内容(更新数据块)
- 原文件 "hello" 为 5 字节,追加 "world" 后变为 10 字节,仍小于单个数据块容量(如 4KB);
- 系统直接在数据块 200 中覆盖写入新内容 "helloworld";
- 同步更新 inode 号 100 的
i_size(文件大小从 5 字节改为 10 字节)和i_mtime(最近修改时间更新为当前时间)。
修改文件属性(更新 inode)
- 执行
chmod 600 test.txt时,系统直接修改 inode 号 100 的i_mode字段,将权限从rw-r--r--改为rw-------(仅所有者可读写); - 同时更新 inode 的
i_ctime(最近属性修改时间更新为当前时间),整个过程不涉及数据块 200 的内容变更,仅修改 inode 的元数据。
(四)搬离清物(删除文件:rm test.txt):3 步标记流程删除目录项中的映射关系
- 系统找到当前目录的数据块 300,删除其中 "test.txt → 100" 的目录项记录,解除文件名与 inode 号的关联。
标记 inode 为空闲
- 系统在块组的 inode 位图中,将 inode 号 100 对应的位从 1(占用)改回 0(空闲),释放该 inode;inode 表中该 inode 的内容不会立即清空,仅标记为可复用。
标记数据块为空闲
- 系统在块组的块位图中,将数据块 200 对应的位从 1(占用)改回 0(空闲),释放该数据块;数据块中的内容 "helloworld" 不会立即删除,仅标记为可覆盖,直到新数据写入时被覆盖。
关键提醒:搬离不是 "销毁物品",而是 "标记床位和学号可用"
删除文件时,物品(数据)本身不会被立即清空,只是标记对应的学号和床位为 "空闲"。只要新学生没有入住 200 号床位,通过数据恢复工具就能找回 "helloworld" 物品 ------ 这就是数据恢复的核心原理,相当于学生搬离后物品暂时遗落在床位上,后续仍能找回并重新存放。数据恢复的时间窗口:直到该数据块被新数据覆盖,一旦覆盖,原有数据将难以恢复。
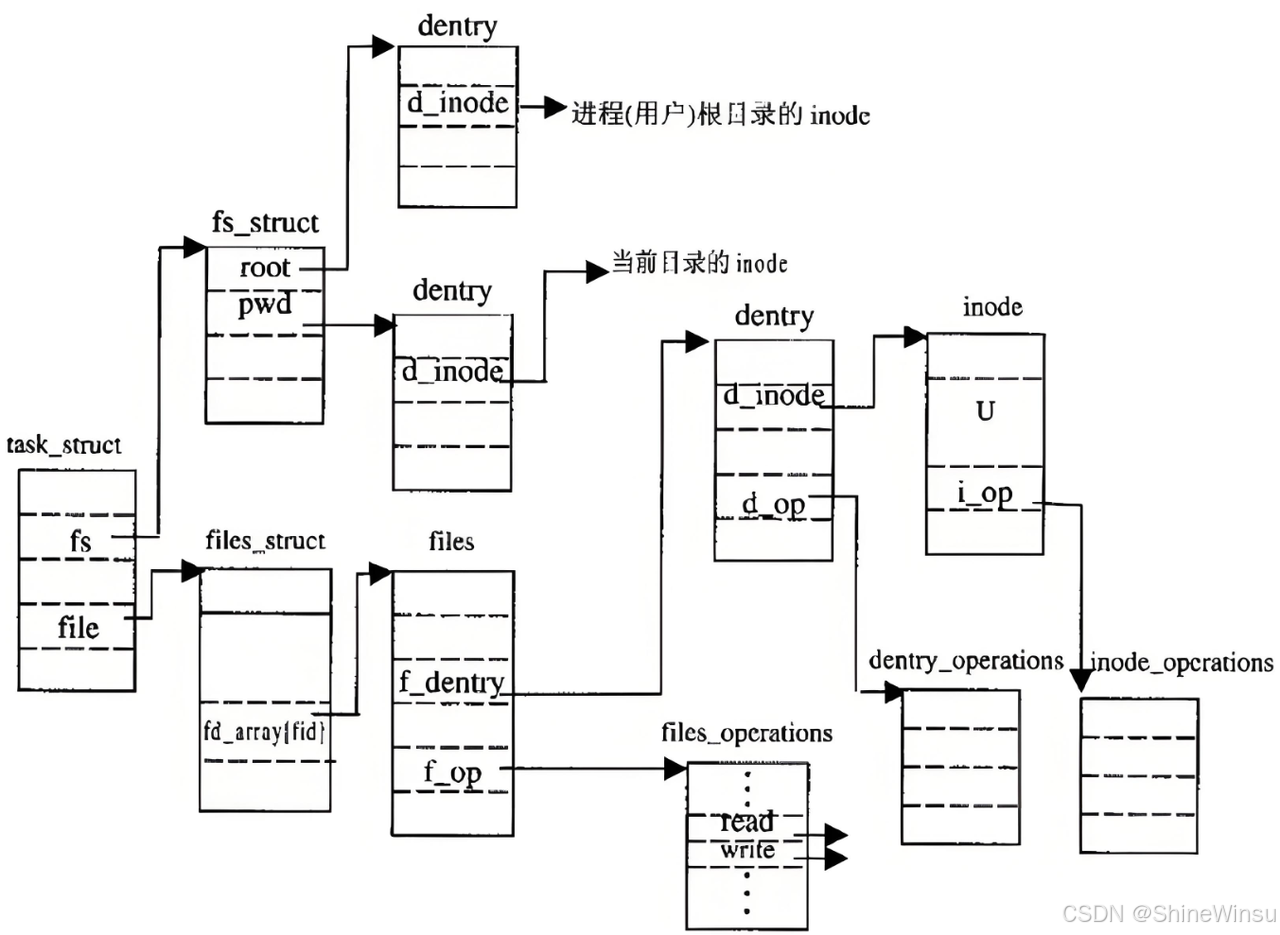
四、目录与文件名:园区的 "楼层房间号清单"
(一)核心真相:目录也是文件,本质是 "楼层房间号清单"
在 Linux 系统中,"目录" 并不是一个特殊的概念,它本质上是一种 "特殊文件":
- 目录的属性(大小、权限、创建时间等)存储在自己的学号(inode)对应的档案单中;
- **目录的床位(数据块)中存储的是 "文件名→inode 号" 的映射关系,相当于 "楼层房间号清单",记录该楼层内所有文件的名字和对应的学号,**这就是我们之前说了,在文件的inode里面是不会存储文件的名字的,文件的名字其实是存储在其所在的目录下的,当我们访问文件的时候,系统会先去找到当前目录,然后查看本目录下数据块中所记录的该文件的文件名,并且通过该文件名与该文件inode的联系,从而找到该文件,因为内核只认inode
(二)目录的硬链接数:为什么新建目录的硬链接数是 2?
普通文件刚创建时,硬链接数是 1(只有一个文件名),但新建目录的硬链接数默认是 2,这与目录的两个 "特殊标识" 密切相关:
.:指向目录自己的硬链接(比如 "3 楼" 的.指向 3 楼自己的 inode),相当于楼层的 "楼层标识",占 1 个硬链接;..:指向父目录的硬链接(比如 "3 楼" 的..指向 "1 号楼" 的 inode),相当于楼层的 "楼宇标识",父目录的硬链接数会 +1,同时目录自己的硬链接数也会 +1。
因此,新建目录的硬链接数 = 1(. 的贡献)+ 1(.. 的贡献)= 2。
运营场景演示:目录硬链接数的变化
# 新建"3 楼"目录(test),硬链接数=2
mkdir test
ls -ld test # 输出:drwxr-xr-x. 2 root root 6 时间 test(第二列数字为2)
# 在"3 楼"里创建"301 宿舍"子目录(sub),3 楼的硬链接数+1(变成3)
mkdir test/sub
ls -ld test # 输出:drwxr-xr-x. 3 root root 18 时间 test(第二列数字为3)
# 删除"301 宿舍"子目录,3 楼的硬链接数-1(恢复为2)
rm -rf test/sub
ls -ld test # 输出:drwxr-xr-x. 2 root root 6 时间 test(第二列数字为2)变化原因:创建子目录时,子目录的 .. 指向父目录,给父目录的硬链接数加 1;删除子目录时,该指向消失,父目录的硬链接数减 1。
路径解析:从 "根目录" 到 "目标文件" 的导航逻辑
我们先解决核心疑问,再拆解路径解析的完整流程,用 "宿舍园区导航" 的类比把抽象逻辑变具体。
一、先解答核心困惑
- 为什么访问当前工作目录也需要解析路径?
当前工作目录(比如/home/win/code)本质是一个 "目录文件",和普通文件一样有自己的inode。你以为 "在当前目录打开文件" 不用解析路径,但系统底层仍需明确 "当前目录到底在哪"------ 就像你在宿舍里找室友,得先知道自己在 "3 号楼 301 宿舍",而 "3 号楼 301" 本身就需要从园区大门(根目录)确认位置。
- 路径解析的 "递归" 问题怎么解决?
访问目录时,确实需要先找它的上级目录,看似会无限递归,但根目录(/)是递归的出口:
- 根目录的
inode号是固定的(通常为 2),系统开机后会直接加载根目录的inode,无需通过其他目录查找; - 所有路径都以根目录为起点,比如
./test.c看似是 "当前目录",底层会被补全为/home/win/code/test.c,从根目录开始解析。
- 路径从哪里来?
路径不是 "凭空产生" 的,而是系统和用户共同构建的目录树结构:
- 系统初始化时,会自动创建根目录及缺省子目录(如
/bin、/home、/etc),构成基础路径框架; - 用户新建目录(如
mkdir code)、创建文件,本质是在这个框架上新增节点,每个文件天然隶属于某个目录,也就有了对应的路径; - 进程访问文件时,路径由进程提供:要么是用户输入的绝对路径(如
/home/whb/code/test.c),要么是基于进程的 "当前工作目录(CWD)" 的相对路径(如./test.c),进程的 CWD 会记录自己当前在目录树中的位置。
二、路径解析的完整流程(以访问/home/win/code/test.c为例)
路径解析就像 "园区导航",宿管(系统)按路径指令一步步找到目标文件,每一步都依赖inode和目录文件的映射关系:
-
起点:根目录(/) 系统直接加载根目录的
inode(固定为 2),从根目录的i_block数组中找到它的数据块地址(比如块号 10)。 -
解析第一个目录 "home" 读取根目录数据块 10,里面存储着 "文件名→inode 号" 的映射,找到 "home" 对应的
inode号(比如 100)。 -
解析第二个目录 "win" 按
inode号 100 找到 "home" 的inode,从其i_block中获取数据块地址(比如块号 200),读取数据块 200,找到 "win" 对应的inode号(比如 200)。 -
解析第三个目录 "code" 按
inode号 200 找到 "win" 的inode,获取其数据块地址(比如块号 300),读取数据块 300,找到 "code" 对应的inode号(比如 300)。 -
解析目标文件 "test.c" 按
inode号 300 找到 "code" 的inode,获取其数据块地址(比如块号 400),读取数据块 400,找到 "test.c" 对应的inode号(比如 400)。 -
访问目标文件 按
inode号 400 找到 "test.c" 的inode,从其i_block中获取数据块地址(比如块号 500),读取数据块 500 中的文件内容,完成访问。
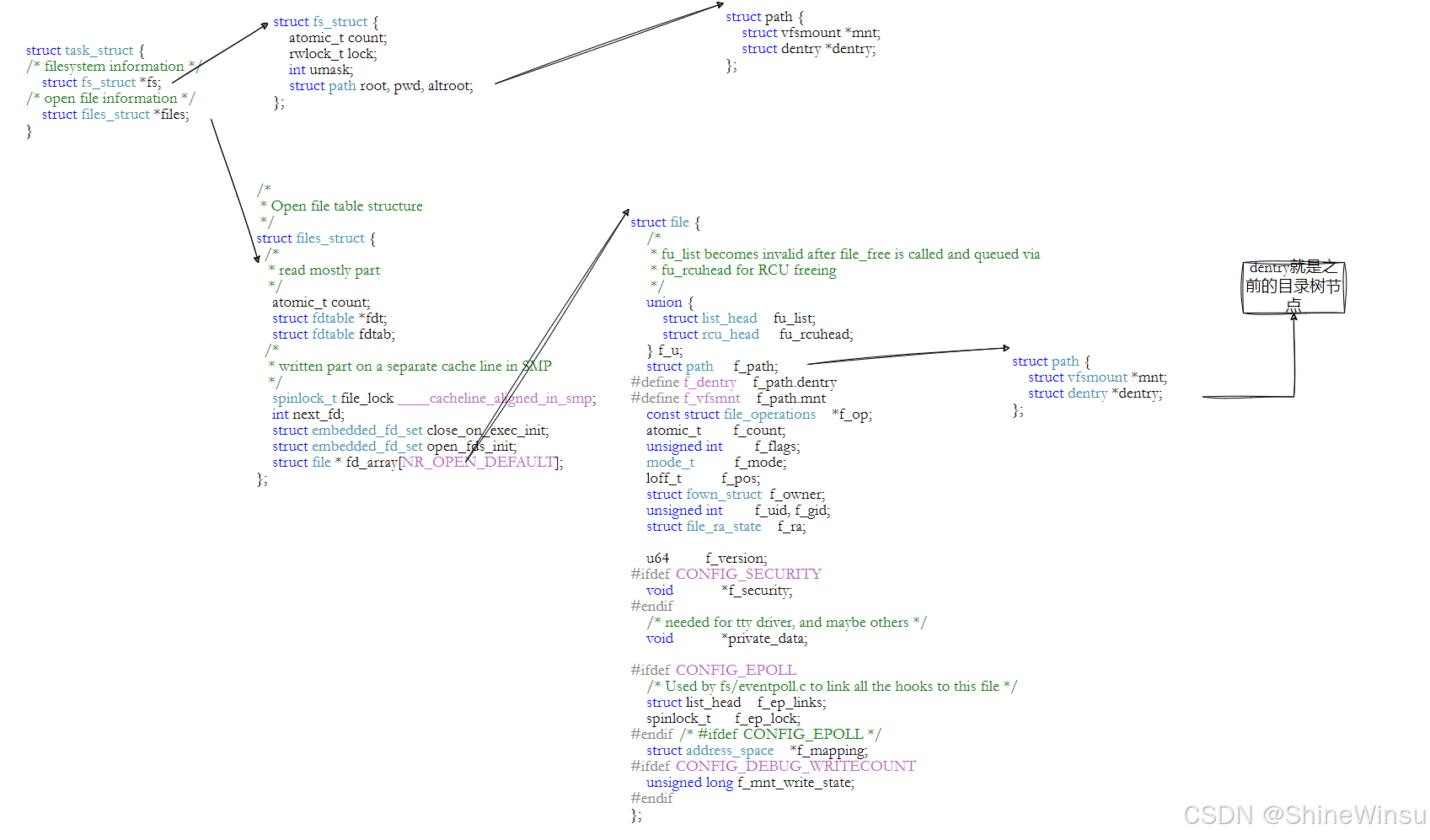
三、路径解析的核心意义
- 路径 = 目录 + 文件名,本质是 "文件在目录树中的坐标";
- 系统通过路径解析,将 "人类易懂的文件名" 转化为 "底层可识别的
inode号",最终定位到文件的数据块; - 根目录的固定
inode设计,打破了 "无限递归查找" 的死循环,是整个路径解析体系的基石。
路径缓存:让 "导航" 更快的内存映射表
每次都从根目录一步步解析路径,就像每次出门都查完整地图,效率很低。Linux 的 "路径缓存" 就是内存中的 "电子导览图",提前记录常用路径的映射关系,提升访问速度。
一、先澄清 2 个关键问题
- 磁盘里有 "真正的目录" 吗?
没有!磁盘上只有 "文件"------ 目录本质是一种 "特殊文件":
- 目录的
inode存储自身属性(大小、权限、创建时间等); - 目录的数据块存储 "文件名→inode 号" 的映射关系(比如
code→300、test.c→400)。
- 为什么需要路径缓存?
原则上所有文件访问都要从根目录解析,但频繁解析相同路径会重复读取磁盘,导致效率低下。路径缓存将 "已解析的路径" 存储在内存中,下次访问时直接从内存查询,避免重复的磁盘 IO 操作。
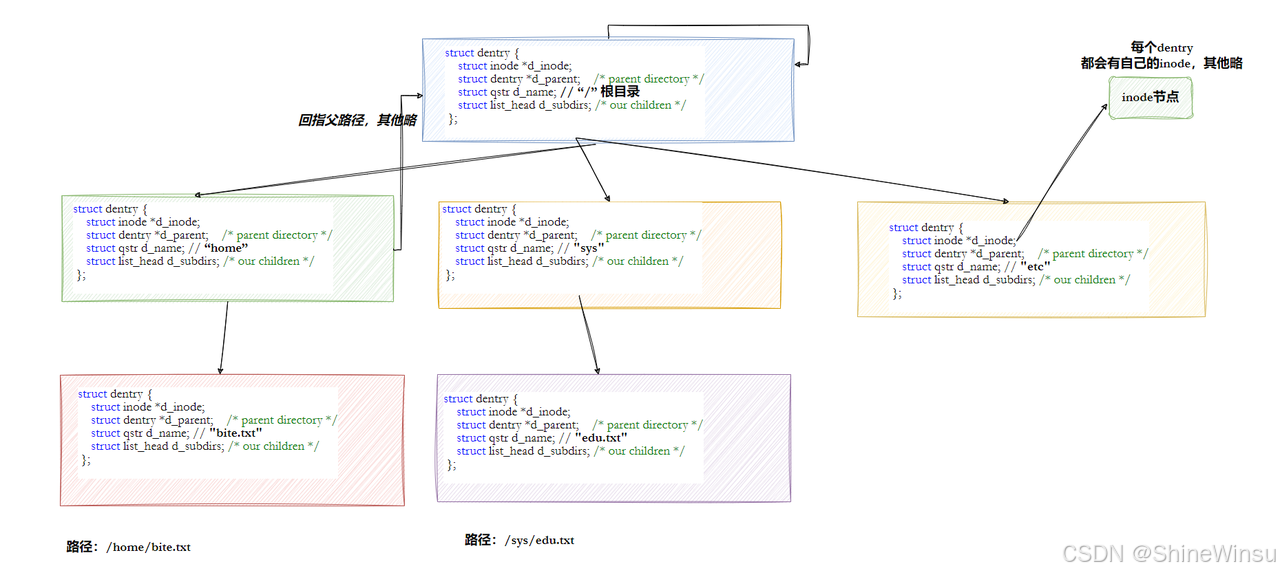
二、路径缓存的核心:struct dentry结构体
Linux 内核用struct dentry(目录项)结构体在内存中维护路径的树形结构,每个文件(包括普通文件、目录)都对应一个dentry节点。我们用 "电子导览图的节点" 来类比dentry的核心字段:
dentry字段 |
通俗含义(电子导览图节点属性) | 核心作用 |
|---|---|---|
d_inode |
关联的文件inode指针(对应 "房间的档案编号") |
建立内存路径节点与磁盘inode的关联,快速定位文件属性和数据块。 |
d_parent |
父目录的dentry指针(对应 "上级楼层的导览节点") |
构建树形结构,比如 "code" 的d_parent指向 "whb" 的dentry。 |
d_name |
文件名(对应 "房间 / 楼层名称") | 存储路径中的节点名称,用于路径匹配。 |
d_subdirs |
子目录的dentry链表(对应 "当前楼层的所有房间列表") |
记录当前目录下的所有子节点,方便遍历子目录。 |
d_lru |
LRU 链表节点(对应 "导览节点的使用频率标记") | 管理缓存淘汰:长期未使用的dentry会被移除,释放内存。 |
d_hash |
哈希表节点(对应 "导览图的快速检索索引") | 将dentry加入哈希表,支持按路径快速查找节点,提升缓存查询效率。 |
三、路径缓存的工作流程
-
缓存命中(快速访问)当用户访问
/home/win/code/test.c时,内核先在dentry树形缓存中按路径查找:- 从根目录的
dentry开始,依次匹配 "home""win""code""test.c" 的dentry节点; - 找到 "test.c" 的
dentry后,直接通过d_inode获取inode,进而访问数据块,无需读取磁盘。
- 从根目录的
-
缓存未命中(加载并缓存)若路径未在缓存中(比如首次访问):
- 内核按传统路径解析流程从磁盘读取路径的映射关系(从根目录一步步解析);
- 为路径上的每个节点(
home"win""code""test.c")创建dentry结构体,构建内存树形结构; - 将新构建的
dentry节点加入哈希表和 LRU 链表,后续访问该路径时直接命中缓存。
-
缓存淘汰(释放内存)当内存不足时,内核通过 LRU 机制淘汰 "最近最少使用" 的
dentry节点,释放内存资源,确保缓存始终存储高频访问的路径。
四、dentry树形结构的核心作用
- 构建内存路径树 :所有
dentry节点通过d_parent和d_subdirs关联,形成与磁盘目录树一致的内存结构,直观反映路径层级; - 加速路径查找:结合哈希表实现路径的快速匹配,避免逐目录解析的磁盘 IO;
- 统一管理文件节点 :普通文件和目录的
dentry统一维护,让内核能高效处理各类文件的访问请求。
总结:路径解析与缓存的核心逻辑
- 路径解析 :以根目录(固定
inode)为起点,通过 "目录文件的数据块→文件名→inode" 的映射关系,递归定位目标文件,解决 "文件在哪" 的问题; - 路径缓存 :用
dentry结构体在内存中构建路径树形缓存,结合哈希表和 LRU 机制,减少重复的磁盘解析操作,提升文件访问效率; - 本质上,两者都是为了 "高效关联文件名与
inode"------ 路径解析是 "基础导航方法",路径缓存是 "优化导航速度的工具",共同支撑 Linux 文件系统的高效运行。
(三)路径解析:学生从 "园区大门" 到 "目标床位" 的导航流程
学生访问文件时使用的路径(比如 /home/user/test.txt),本质是宿管的 "导航指令",宿管需要通过 "路径解析" 找到目标物品,具体流程如下:
- 从园区大门(根目录
/)开始,根目录的学号固定为 2,宿管直接找到根目录的档案单; - 从根目录档案单的 "床位清单" 中获取楼层清单床位地址,找到 "home" 对应的学号(比如 123);
- 宿管找到 "home" 的档案单,从档案单的 "床位清单" 中获取楼层清单床位地址,找到 "user" 对应的学号(比如 456);
- 宿管找到 "user" 的档案单,从档案单的 "床位清单" 中获取楼层清单床位地址,找到 "test.txt" 对应的学号(比如 100);
- 宿管找到 "test.txt" 的档案单,从档案单的 "床位清单" 中获取床位地址,取出文件内容。
根目录的特殊性:路径解析的 "唯一起点"
根目录(/)是所有路径的起点,它的学号固定为 2。园区开放后(系统开机),宿管会直接获取根目录的档案单,无需通过其他分区查找 ------ 这就打破了 "路径解析无限循环" 的问题,避免出现 "找 3 楼要先找 1 号楼,找 1 号楼要先找 3 楼" 的逻辑矛盾。
五、挂载分区:把 "独立宿舍楼" 接入 "园区管理网络"
(一)核心问题:跨分区 "学号" 不通用,多分区怎么协同?
之前我们知道,inode 号(学号)的唯一性是 "分区内唯一",就像 "学校 A 的 1 号学籍" 和 "学校 B 的 1 号学籍" 属于不同学生,分区 A 的 inode 100 和分区 B 的 inode 100 对应不同文件。
这会导致一个关键问题:系统无法直接跨分区访问文件。比如你想从 "1 号宿舍楼(分区 A)" 访问 "2 号宿舍楼(分区 B)" 的文件,宿管(系统)拿着分区 A 的 "学号 100",在分区 B 的 "学生档案柜" 里根本查不到对应的记录 ------ 因为两个分区的 inode 体系是独立的。
这时候就需要 "挂载" 操作:相当于在两个独立宿舍楼之间修一条 "专属通道",并在 1 号宿舍楼的某个角落设一个 "入口",学生(用户 / 进程)通过这个入口,就能进入 2 号宿舍楼,并且用统一的 "园区路径" 访问里面的文件。
(二)挂载的本质:给独立分区开 "园区统一入口"
1. 核心定义
挂载是将一个分区(或存储设备)的文件系统,与根目录树中的某个空目录(挂载点) 建立关联。这个挂载点就像 "园区入口":
- 访问挂载点目录,本质是访问被挂载分区的文件系统;
- 系统会将挂载点的路径,自动映射为被挂载分区的根路径。
2. 关键注意点:挂载点非空会怎样?
如果挂载点目录原本有文件(比如/mnt/mydisk里有old.txt),挂载后这些原有文件会被暂时隐藏------ 就像在原有房间门口挂了一个 "通往新宿舍楼" 的指示牌,你推开房门进入的是新宿舍楼,原有房间的东西要等 "拆了指示牌"(卸载)后才能看到。
3. 类比场景
假设园区有两栋独立宿舍楼:
- 1 号楼(系统分区
/dev/sda1):已接入园区,学生能通过/home"路径" 访问; - 2 号楼(新分区
/dev/sdb1):未接入,学生无法直接访问。
挂载操作就是在 1 号楼的/mnt/mydisk房间设一个入口,学生走进这个房间,就相当于进入了 2 号楼,能访问 2 号楼的所有物品(文件),访问路径统一为/mnt/mydisk/文件。
(三)实操运营场景:手把手搭建 "临时宿舍楼" 并接入园区
我们用具体命令模拟挂载流程,每一步都对应 "宿舍园区" 的实际操作,同时解释命令的核心作用:
步骤 1:搭建模拟宿舍楼(创建虚拟存储文件)
dd if=/dev/zero of=./disk.img bs=1M count=5- 作用 :创建一个 5MB 的普通文件
disk.img,当作 "临时宿舍楼"(虚拟分区)。 - 参数拆解 :
if=/dev/zero:从 "零设备" 读取数据(相当于用空白材料搭建宿舍楼);of=./disk.img:输出到当前目录的disk.img文件(宿舍楼的载体);bs=1M:每次读写 1MB 数据(搭建宿舍楼的 "砖块大小");count=5:总共读写 5 次,总大小 5MB(宿舍楼的总面积)。
步骤 2:制定管理规则(格式化虚拟分区)
mkfs.ext2 disk.img- 作用 :给
disk.img这个 "临时宿舍楼" 制定 ext2 文件系统规则(相当于规定床位大小、学号分配方式、档案柜位置等)。 - 底层操作 :格式化时会在
disk.img中创建超级块、GDT、位图、inode 表、数据块等 ext2 核心结构(之前讲的 "6 大管理部门")。
步骤 3:创建接入入口(创建挂载点目录)
mkdir /mnt/mydisk- 作用 :在园区(根目录
/)的/mnt目录下创建mydisk空目录,作为 "临时宿舍楼" 的接入入口(挂载点)。 - 注意 :必须确保
/mnt/mydisk是空目录,否则挂载后原有文件会被隐藏。
步骤 4:打通入口(执行挂载操作)
mount -o loop disk.img /mnt/mydisk- 作用 :将
disk.img对应的虚拟分区,接入到/mnt/mydisk这个入口。 - 关键参数
-o loop:因为disk.img是普通文件(不是物理分区),loop选项会让系统用 "循环设备" 将其伪装成物理分区(后面详细讲)。
步骤 5:验证入口是否打通(查看挂载结果)
df -h- 作用:查看系统的挂载状态和磁盘使用情况。
- 预期输出 :会显示
/mnt/mydisk对应的设备(比如/dev/loop0)、总大小 5MB、可用空间等信息,说明挂载成功。
步骤 6:使用临时宿舍楼(操作挂载后的分区)
# 在临时宿舍楼创建文件(存放物品)
echo "我是临时文件" > /mnt/mydisk/test.txt
# 查看文件(取用物品)
cat /mnt/mydisk/test.txt- 底层逻辑 :这些操作本质是在
disk.img的虚拟分区中创建文件、写入数据,而非在原/mnt/mydisk目录下。
步骤 7:关闭入口(卸载分区)
umount /mnt/mydisk- 作用 :断开
disk.img与/mnt/mydisk的关联,关闭 "临时宿舍楼" 的入口。 - 验证 :此时再访问
/mnt/mydisk,会发现里面的test.txt文件消失了(虚拟分区已断开);若挂载点原本有文件,此时会恢复可见。
常见错误:卸载失败怎么办?
如果执行umount时提示 "设备正忙",说明有进程正在访问/mnt/mydisk(比如当前目录在/mnt/mydisk下)。解决方法:
- 切换到其他目录(比如
cd /home); - 关闭访问该目录的进程(用
lsof /mnt/mydisk查看进程,再用kill -9 进程ID关闭); - 重新执行
umount /mnt/mydisk。
(四)循环设备:普通文件变 "分区" 的 "适配器"
- 核心问题:为什么需要循环设备?
disk.img本质是普通文件,而mount命令默认只能挂载 "块设备"(比如物理硬盘/dev/sda1、U 盘/dev/sdb1)。就像你想把 USB 接口的设备插到 Type-C 接口的电脑上,需要一个 "转接器"------ 循环设备就是 "普通文件→块设备" 的转接器。
- 循环设备的工作原理
- Linux 系统提供了一系列循环设备文件(
/dev/loop0、/dev/loop1...),它们是内核中的 "虚拟块设备接口"; - 执行
mount -o loop disk.img /mnt/mydisk时,系统会自动分配一个空闲的循环设备(比如/dev/loop0),将disk.img文件与该设备绑定; - 之后系统就会把
/dev/loop0当作物理块设备处理,mount命令就能正常挂载了。
-
查看循环设备关联情况
losetup
- 作用:列出当前系统中循环设备与文件的绑定关系。
- 预期输出 :会显示
/dev/loop0对应的文件路径是./disk.img,说明绑定成功。
- 手动绑定循环设备(进阶操作)
除了让mount自动分配,也可以手动绑定循环设备:
# 手动将disk.img绑定到/dev/loop0
losetup /dev/loop0 disk.img
# 挂载循环设备
mount /dev/loop0 /mnt/mydisk
# 卸载后解除绑定
umount /mnt/mydisk
losetup -d /dev/loop0(五)挂载的实际应用场景
- 多硬盘管理 :电脑装了两块硬盘(
/dev/sda、/dev/sdb),将/dev/sdb1挂载到/home,用户的文件就会存到第二块硬盘,避免第一块硬盘空间不足; - U 盘 / 移动硬盘使用 :插入 U 盘后,系统会自动挂载到
/media/用户名/U盘名称,用户通过该路径访问 U 盘中的文件; - 虚拟光驱挂载 :将 ISO 镜像文件(比如系统安装镜像)挂载到
/mnt/cdrom,无需刻录光盘就能访问镜像中的内容; - 网络存储挂载:将远程服务器的共享目录(比如 NFS、Samba)挂载到本地目录,像访问本地文件一样访问远程文件。
总结:挂载的核心逻辑
- 本质:建立 "独立分区" 与 "根目录树" 的关联,提供统一的访问入口;
- 关键角色:挂载点是 "入口",循环设备是 "普通文件→块设备" 的适配器;
- 核心价值:解决了跨分区 inode 不通用的问题,实现多存储设备的统一管理,让用户无需关心文件存在哪个物理分区,只需通过路径就能访问。
六、常见问题与解决方案:园区运营的 "踩坑指南"
(一)问题 1:学号耗尽,床位空着却不能入住
- 原因:园区的学号总数是固定的,若存储了大量小文件(每个小文件占用 1 个学号,但只占用 1 个床位的一小部分),会导致学号先被耗尽,出现 "床位空闲但无学号可用" 的情况;
- 例子:一个 1GB 的分区,inode 大小为 128 字节,inode 总数约 8000 个。若存储了 10000 个 1 字节的小文件(相当于 10000 张便签),就会提示 "无学号可用,无法创建文件";
- 解决方法 :
- 清理闲置物品:删除无用的小文件,释放空闲学号;
- 重新规划园区:格式化分区并通过
mkfs.ext2 -i 字节数 /dev/设备名调整 inode 密度(字节数越小,inode 总数越多),增加学号总数(需注意格式化会清空所有数据,操作前需备份); - 临时方案:使用符号链接代替硬链接,符号链接不占用独立 inode,可减少 inode 消耗。
(二)问题 2:总台账损坏,园区无法开放
- 原因:磁盘物理损坏(比如宿舍楼墙体倒塌)、意外断电等情况,可能导致总台账(超级块)损坏;
- 解决方法 :
- 查找超级块备份位置:执行
dumpe2fs /dev/sdb1 | grep -i superblock命令,获取超级块备份的块地址; - 用备份恢复:执行
e2fsck -b 备份块地址 /dev/sdb1命令(比如e2fsck -b 32768 /dev/sdb1),用其他宿舍楼备份的台账复印一份,恢复园区的管理数据。
- 查找超级块备份位置:执行
(三)问题 3:物品误搬离,如何找回?
- 原理:物品搬离(删除文件)只是标记学号和床位为空闲,物品数据本身仍存放在床位上,未被立即删除,直到新学生入住该床位覆盖原有数据;
- 工具与方法 :使用
extundelete等数据恢复工具,执行extundelete /dev/sdb1 --restore-file test.txt命令,相当于宿管扫描所有空闲床位,找到未被新物品覆盖的误搬离物品,重新标记学号和床位,实现物品的 "重新入住"。注意:恢复前避免对该分区进行写入操作,防止数据被覆盖。
(四)问题 4:挂载点目录非空,挂载后原有内容消失
- 原因:挂载操作会将挂载点目录与新分区关联,原目录下的内容被新分区的内容覆盖,并非删除;
- 解决方法 :执行
umount /mnt/mydisk命令卸载分区后,原目录下的内容会自动恢复可见。建议挂载前确保挂载点目录为空,避免误操作。
七、ext2 的局限性与适用场景
(一)局限性
- 无日志功能:系统崩溃或意外断电后,数据恢复速度慢,且可能出现数据不一致;
- 不支持大文件 / 分区:32 位系统下,ext2 最大支持 2TB 分区和 2GB 文件,无法满足大容量存储需求;
- 空间利用率一般:小文件会造成块内空间浪费,且不支持稀疏文件优化;
- 性能有限:缺乏延迟分配、日志缓存等优化机制,读写大文件时效率低于 ext4。
(二)适用场景
- 嵌入式系统:占用资源少,适合存储需求简单的嵌入式设备;
- 临时存储分区:比如
/tmp分区,对数据可靠性要求低,无需日志功能; - 学习场景:结构简单,适合理解文件系统的底层原理。
八、ext2 文件系统核心总结
(一)核心运营逻辑链
文件名(学生名字)→ 楼层清单(目录数据块)→ 学号(inode 号)→ 学生档案柜(inode 表)→ 床位地址(数据块地址)→ 床位区(数据块)→ 文件内容(学生物品)(二)六大核心部门分工
- 超级块:园区管理处的总台账,记录全局资源与运营情况;
- GDT:楼宇的楼层导视图,记录楼宇内部布局与局部资源;
- 块位图:楼宇的床位占用指示灯,标记床位的占用状态;
- inode 位图:楼宇的学号占用登记表,标记学号的占用状态;
- inode 表:楼宇的学生档案柜,记录文件属性与床位地址;
- 数据块:楼宇的学生床位区,存储文件的实际内容。
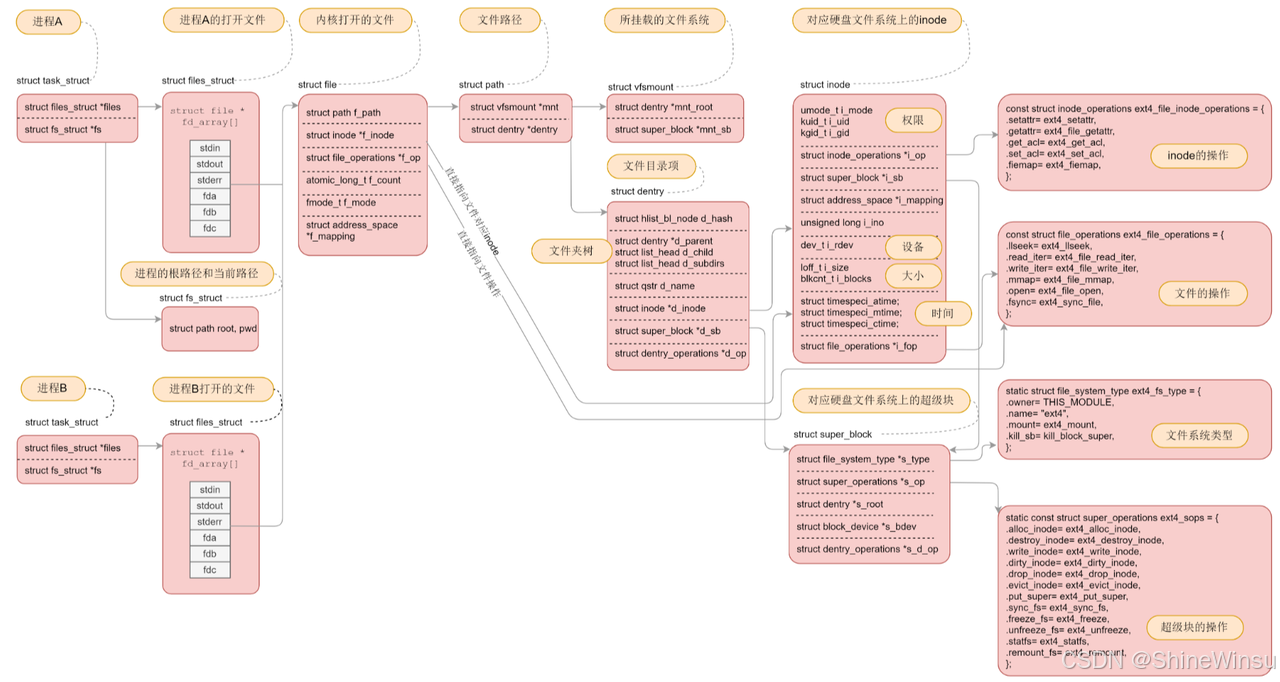
(三)关键运营特性
- 可靠性:总台账(超级块)和楼层导视图(GDT)多份备份,有效防止运营信息丢失;
- 灵活性:通过直接 / 间接块映射机制,适配不同大小的文件存储需求;
- 扩展性:通过挂载操作,将多个独立分区接入根目录树,实现多分区的统一管理,满足海量数据的存储需求。
(四)关键命令速查
| 命令 | 用途 | 常用参数 | 示例 | |
|---|---|---|---|---|
mkfs.ext2 |
格式化分区为 ext2 | -b(块大小)、-i(inode 密度) |
mkfs.ext2 -b 4096 /dev/sdb1 |
|
e2fsck |
检查并修复 ext2 分区 | -b(超级块备份地址) |
e2fsck -b 32768 /dev/sdb1 |
|
mount |
挂载分区 | -o loop(循环设备) |
mount -o loop disk.img /mnt/mydisk |
|
umount |
卸载分区 | - | umount /mnt/mydisk |
|
dumpe2fs |
查看 ext2 分区信息 | - | `dumpe2fs /dev/sdb1 | grep -i superblock` |
extundelete |
恢复 ext2 分区删除的文件 | --restore-file(恢复单个文件) |
extundelete /dev/sdb1 --restore-file test.txt |
掌握 ext2 的核心逻辑后,再学习 ext3、ext4 等高级文件系统时,只需重点关注新增功能(如日志、延迟分配),就能快速理解其底层原理,为后续 Linux 存储管理、系统优化等知识打下基础。
结语:于底层肌理中,窥见 Linux 的秩序之美
亲爱的读者朋友们,当你读到这里时,我们关于 ext2 文件系统的探索之旅也即将画上句点。从开篇对 "磁盘与文件系统关系" 的懵懂好奇,到逐步拆解 "宿舍园区" 的六大核心管理部门,再到亲历文件 "增删查改" 的完整生命周期,我们用一个个生活化的类比,将抽象的底层技术转化为可感知的运营场景,终于揭开了 Linux 文件系统的神秘面纱。这段旅程或许充满了概念的碰撞与逻辑的缠绕,但我相信,当你真正理解 "inode 与数据块的关联""路径解析的递归逻辑""挂载操作的跨区协同" 时,心中一定满是豁然开朗的喜悦。
回望我们走过的路,ext2 文件系统的每一个设计都闪耀着工程师的智慧光芒。超级块作为 "园区总台账" 的全局把控,块位图与 inode 位图如同 "占用指示灯" 般的精准标记,inode 表对文件属性与数据地址的细致记录,数据块对不同类型文件的灵活适配,这六大核心部门各司其职、协同运转,构建起一套高效、可靠的存储管理体系。我们曾为 "小文件浪费块空间" 的设计权衡而思考,为 "大文件通过间接块拓展存储" 的巧妙构思而赞叹,也为 "删除文件仅标记空闲" 的数据恢复原理而惊叹 ------ 这些细节不仅是技术的堆砌,更是对 "如何平衡效率与可靠性" 这一核心问题的完美回应。
在探索过程中,我们也逐渐摸清了 Linux 文件系统的底层逻辑脉络:文件名通过目录项映射到 inode,inode 通过数据块地址定位到文件内容,路径解析以根目录为起点层层递归,路径缓存则通过内存结构提升访问效率,挂载操作打破了分区壁垒实现统一管理。这条逻辑链就像一根无形的丝线,将分散的知识点串联成完整的体系,也让我们明白,Linux 系统的强大并非源于零散功能的叠加,而是建立在这种严谨有序的底层架构之上。
掌握 ext2 文件系统的原理,对我们而言更是打开了 Linux 世界的一扇新大门。后续学习 ext3、ext4 等高级文件系统时,你会发现它们不过是在 ext2 的基础上新增了日志功能、延迟分配等优化特性,核心逻辑一脉相承;深入学习进程通信、网络编程时,你会理解文件描述符如何成为跨模块交互的关键载体;进行系统优化与故障排查时,你能快速定位 "inode 耗尽""超级块损坏" 等底层问题的根源。这些知识就像坚实的基石,支撑着我们在 Linux 技术的海洋中更从容地航行。
我深知,学习底层技术的过程从来不是一帆风顺的。或许你曾为 "dentry 结构体的字段含义" 反复琢磨,曾为 "路径缓存的工作流程" 陷入困惑,也曾为 "挂载操作的设备绑定逻辑" 屡屡碰壁。但请你相信,每一次的思考与尝试都是成长的积淀。技术的探索本就是一场持久战,那些看似枯燥的概念、复杂的流程,终会在反复推敲中内化为你的专业能力,成为你解决实际问题的底气。
Linux 世界的探索之路永无止境。ext2 文件系统只是我们迈出的第一步,接下来还有日志文件系统的故障恢复机制、分布式文件系统的跨节点协同、存储虚拟化的底层实现等更广阔的领域等待我们去开拓。希望这段关于 ext2 的学习经历,能让你收获的不仅是具体的技术知识,更有一种 "拆解复杂问题、回归事物本质" 的思维方式 ------ 用生活化的类比化解抽象概念,用逻辑链条串联零散知识点,用实际操作验证理论原理。
最后,我想向每一位坚持读完本文的读者致以最诚挚的敬意。在这个追求 "速成" 的时代,你愿意沉下心来探索技术的底层肌理,这份耐心与求知欲本身就是最宝贵的财富。请保持这份对技术的热爱与敬畏,继续在 Linux 的世界里深耕细作。或许未来的某一天,当你面对复杂的系统问题时,会想起这段 "拆解宿舍园区" 的经历,想起那些关于 inode、数据块与路径的底层逻辑,从而找到解决问题的关键线索。
技术之路,道阻且长,行则将至;行而不辍,未来可期。愿你在后续的学习中不断突破自我,在探索底层技术的过程中收获更多成长与喜悦,最终成为一名能够驾驭技术、创造价值的开发者。我们下一段技术旅程,再见!