1 引言
在 Oracle 数据库的日常运维中,ORA-00600 内部错误是最令人紧张的一类故障。尤其是当数据库因异常断电、硬件故障或 Bug 导致崩溃后,在启动时遇到 ORA-00600 4193 错误,往往意味着 Undo 段与 Redo 记录之间出现了严重的不一致。
ORA-00600: internal error code, arguments: [4193], [65], [71], [], [], [], [], []很多 DBA 在面对这个错误时感到无从下手------既担心数据丢失,又担心错误的操作会让情况更糟。实际上,ORA-00600 4193 是一个与 Undo/Redo 不一致相关的错误,它表明数据库在启动时的回滚阶段,无法正常回滚事务,因为 Undo 块中记录的序列号与 Redo 日志中记录的序列号不匹配。
本文基于 Oracle 19.29 版本,系统性地讲解:
-
ORA-00600 4193 错误的定义与成因
-
两个参数的含义解读(
[a]与[b]) -
从 Alert Log 到 Trace 文件的完整分析流程
-
多种恢复方案(从备份恢复到隐藏参数强制打开)
-
数据导出与重建(善后处理)
-
19.29 版本的注意事项与风险提示
适用版本 :Oracle Database 19c(19.29 及更高版本)
参考文档:Oracle Doc ID 39282.1、Doc ID 1428786.1、Doc ID 106638.1、KB145377、KB86914 等
⚠️ 重要警告
在尝试任何恢复操作之前,请务必备份所有数据文件、控制文件和联机 Redo 日志。本文介绍的某些恢复方法(尤其是使用隐藏参数)属于最后手段,可能导致数据字典逻辑讹误,需要在打开数据库后立即导出数据并重建数据库。操作前请仔细评估风险,并确保有完整的回退方案。
2 错误定义与成因分析
2.1 ORA-00600 错误的本质
ORA-00600 是 Oracle 的一个通用内部错误码,表示数据库进程遇到了一个低级的、意外的条件。大部分 ORA-00600 错误由 Oracle 软件的 Bug 导致,但也有部分由数据库文件损坏、内存讹误或硬件故障引起。
该错误信息包括方括号中的参数列表:
ORA-00600: internal error code, arguments: [%s], [%s], [%s], [%s], [%s]第一个参数是内部信息编号或字符串,用于帮助确定问题的根本原因。
2.2 ORA-00600 4193 的字面含义
对于 **ORA-00600 4193**,其完整格式为:
ORA-00600: internal error code, arguments: [4193], [a], [b], [], [], [], [], []根据 Oracle 官方文档(Doc ID 39282.1),该错误的描述为 **"seq# mismatch while adding undo record"**(在添加 Undo 记录时序列号不匹配)。其中两个参数的含义为:
-
[a]:Undo 块中记录的序列号(Undo Block Sequence Number) -
[b]:Redo 日志中记录的该 Undo 块的序列号(Redo Block Sequence Number)
例如,当出现 ORA-00600: internal error code, arguments: [4193], [8023], [8068] 时,表示 Undo 块的序列号为 8023,而 Redo 日志记录的序列号为 8068。
2.3 错误的成因:Undo 与 Redo 的序列号不匹配
ORA-00600 4193 错误从 Oracle 6.0 版本开始被引入,属于 Oracle 内核的事务 Undo 管理层。该错误的出现可能导致 Oracle 实例崩溃。
当 Oracle 尝试向 Undo 块添加新的 Undo 记录时,会进行一项关键校验:新记录号应当等于 Undo 块中最大记录号加 1。在应用 Redo 到 Undo 块时,Oracle 会校验 Undo 块中的 Undo 记录数与 Redo 记录中的记录数是否匹配。如果不匹配,就会产生该错误。
具体来说:
-
ORA-00600 4193 发生在 Undo 块的序列号与 Redo 日志中记录的序列号不匹配时
-
ORA-00600 4194 则更为具体,发生在 Undo 块中的最大 Undo 记录数与 Redo 块中的记录数不匹配时
2.4 触发场景
以下场景容易触发 ORA-00600 4193:
场景一:异常断电或硬件故障
当服务器突然断电或发生硬件故障导致数据库崩溃后,数据库在启动时会先进行正常的前滚(Redo),然后再进行回滚(Undo)。如果在回滚时发现 Redo 与 Undo 记录不匹配,就会生成此错误。
场景二:Bug 8240762(已修复)
该 Bug 的详细信息:执行 SHRINK 操作后可能导致 Undo 损坏,同一个 Undo 块可能被两个不同的事务使用,从而引发 ORA-600 4193、ORA-600 4194 或 ORA-600 4137 等错误。该 Bug 已在 10.2.0.5、11.1.0.7.10、11.2.0.1 等版本中修复。
场景三:表空间备份模式下的错误操作
如果在源数据库处于打开状态时复制了在线 Redo 日志,可能导致目标数据库在打开时出现 ORA-00600 4193 错误。在线 Redo 日志只应在源数据库关闭后才复制。
场景四:RAC 滚动升级中的 Bug(19.29 版本相关)
在 RAC 集群上滚动更新至 19.29 和 19.30 DBRU 后,少数情况下可能出现主数据库块损坏和重做日志损坏。如果数据库日志中报错 ORA-00600 4193 等错误,很可能就是遇到了此问题。有关该问题的详细信息,请参见本文第 6 节"Oracle 19.29 版本注意事项"。
2.5 Trace 文件分析:定位损坏的回滚段
当遇到 ORA-00600 4193 错误时,必须查看相应的 Trace 文件来确定损坏的回滚段。
获取 Trace 文件位置:
-- 查看 Alert Log 中的 Trace 文件路径
SELECT value FROM v$diag_info WHERE name = 'Diag Trace';示例输出:
VALUE
--------------------------------------------------------------------------------
/u01/app/oracle/diag/rdbms/orcl/orcl/trace在 Trace 文件中搜索关键信息:
grep -i "ktudb\|ktubl\|_SYSSMU" /u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_12345.trc示例输出:
ktudb redo: ... seq: 0x0047 ...
UNDO BLK: ... seq: 0x0041 ...
_SYSSMU10_1234567890$ (回滚段名称)解读:
-
seq: 0x0047→ 十六进制 0x47 转换为十进制是 71(对应参数 b) -
seq: 0x0041→ 十六进制 0x41 转换为十进制是 65(对应参数 a)
这证实了 Undo 块中的数据落后于 Redo 日志的记录。Trace 文件通常还会显示 Undo 段的名称(例如 _SYSSMU10_1234567890$),这就是损坏的回滚段。
3 恢复前的准备工作
在执行任何恢复操作之前,务必完成以下准备工作。
3.1 确认当前 Undo 配置
命令:
SHOW PARAMETER undo;示例输出:
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_management string AUTO
undo_retention integer 900
undo_tablespace string UNDOTBS13.2 确认数据库版本
命令:
SELECT banner_full FROM v$version;示例输出:
BANNER_FULL
--------------------------------------------------------------------------------
Oracle Database 19c Enterprise Edition Release 19.11.0.0.0 - Production
Version 19.11.0.0.03.3 判断是否有可用的备份
这是最重要的准备工作。如果数据库有可用的 RMAN 备份,从备份中恢复是最安全、最推荐的方法。
命令:
rman target /
LIST BACKUP OF DATABASE;示例输出:
List of Backup Sets
-------------------
BS Key Type LV Size Device Type Elapsed Time Completion Time
------- ---- -- ---------- ----------- ------------ ---------------
1 Incr 0 45.67G DISK 00:02:15 09-APR-26重要提醒 :如果存在有效的备份,优先选择从备份恢复,而不是使用隐藏参数强制打开数据库。
3.4 准备一份备份
在执行任何操作之前,强烈建议对当前数据库状态进行备份。如果数据库无法打开,可以通过冷备份的方式备份所有数据文件和控制文件。
命令(数据库处于 MOUNT 或 NOMOUNT 状态):
cp /u01/app/oracle/oradata/orcl/*.dbf /backup/orcl/
cp /u01/app/oracle/oradata/orcl/control*.ctl /backup/orcl/
cp /u01/app/oracle/fast_recovery_area/orcl/*.log /backup/orcl/4 恢复方案
以下恢复方案按推荐优先级排列。方案一(从备份恢复)是最安全的选择,方案三(使用隐藏参数)是最后手段。
4.1 方案一:从备份恢复(推荐)
如果存在可用的 RMAN 备份,直接从备份恢复是最简单、最安全的方法。
步骤:
rman target /
STARTUP MOUNT;
RESTORE DATABASE;
RECOVER DATABASE;
ALTER DATABASE OPEN RESETLOGS;示例输出:
Starting restore at 13-APR-26
using channel ORA_DISK_1
...
Finished restore at 13-APR-26
Starting recover at 13-APR-26
...
Media recovery complete.
Finished recover at 13-APR-26
Statement processed.4.2 方案二:重建 Undo 表空间(标准方法)
如果无法从备份恢复,可以尝试使用标准方法重建 Undo 表空间。这是 Oracle 官方支持的方法,无需使用不受支持的隐藏参数。
4.2.1 步骤一:从 SPFILE 创建 PFILE
命令:
-- 查看当前 SPFILE 位置
SHOW PARAMETER spfile;
-- 创建 PFILE
CREATE PFILE='/tmp/initorcl.ora' FROM SPFILE;示例输出:
SQL> CREATE PFILE='/tmp/initorcl.ora' FROM SPFILE;
File created.4.2.2 步骤二:修改 PFILE 参数
编辑 PFILE:
vi /tmp/initorcl.ora添加/修改以下参数:
undo_management=manual
event='10513 trace name context forever, level 2'参数说明:
-
undo_management=manual:将 Undo 管理切换到手动模式 -
event='10513 trace name context forever, level 2':禁用事务恢复(Transaction Recovery)
注意:在某些情况下,如果仍然遇到 ORA-00600 4193,可能需要添加更多事件来禁用回滚操作:
undo_management=manual
event='10513 trace name context forever, level 2'
event='10512 trace name context forever, level 1'
event='10511 trace name context forever, level 2'
event='10510 trace name context forever, level 1'这些事件的作用是逐步禁用事务恢复的各个环节,以绕过损坏的 Undo 段。
4.2.3 步骤三:以 RESTRICT 模式启动数据库
命令:
STARTUP RESTRICT PFILE='/tmp/initorcl.ora';示例输出:
ORACLE instance started.
Total System Global Area 4294967296 bytes
Fixed Size 9135744 bytes
Variable Size 1040187392 bytes
Database Buffers 3229614080 bytes
Redo Buffers 7630848 bytes
Database mounted.
Database opened.4.2.4 步骤四:检查回滚段状态
命令:
SELECT segment_name, status, tablespace_name
FROM dba_rollback_segs
WHERE status != 'OFFLINE';示例输出:
SEGMENT_NAME STATUS TABLESPACE_NAME
------------------------------ ------------ ------------------------------
SYSTEM ONLINE SYSTEM
_SYSSMU10_1234567890$ ONLINE UNDOTBS1
_SYSSMU9_1234567891$ ONLINE UNDOTBS1
...关键检查:
-
SYSTEM 段始终是 ONLINE 的,这是正常的
-
如果任何 Undo 段的状态是
PARTLY AVAILABLE或NEEDS RECOVERY,请联系 Oracle 支持 -
如果所有 Undo 段都是 OFFLINE 状态,则继续下一步
4.2.5 步骤五:创建新的 Undo 表空间
命令:
CREATE UNDO TABLESPACE undotbs2
DATAFILE '/u01/app/oracle/oradata/orcl/undotbs2_01.dbf'
SIZE 10G AUTOEXTEND ON NEXT 1G MAXSIZE 32G;示例输出:
Tablespace created.4.2.6 步骤六:切换至新的 Undo 表空间并删除旧的
命令:
-- 切换到新的 Undo 表空间
ALTER SYSTEM SET undo_tablespace=undotbs2 SCOPE=BOTH;
-- 确认切换成功
SHOW PARAMETER undo_tablespace;
-- 删除旧的 Undo 表空间(等待一段时间,确保没有活动事务指向旧表空间)
DROP TABLESPACE undotbs1 INCLUDING CONTENTS AND DATAFILES;示例输出:
System altered.
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
undo_tablespace string undotbs2
Tablespace dropped.4.2.7 步骤七:恢复 UNDO_MANAGEMENT 为 AUTO
命令:
-- 关闭数据库
SHUTDOWN IMMEDIATE;
-- 修改 PFILE,注释或删除 event 行,将 undo_management 改回 AUTO
-- 编辑 /tmp/initorcl.ora,设置:
-- undo_management=AUTO
-- # event='10513 trace name context forever, level 2' (注释掉)
-- 重新启动数据库
STARTUP PFILE='/tmp/initorcl.ora';
-- 如果正常,创建 SPFILE
CREATE SPFILE FROM PFILE='/tmp/initorcl.ora';
-- 重启数据库使用 SPFILE
SHUTDOWN IMMEDIATE;
STARTUP;4.3 方案三:使用隐藏参数强制打开数据库(最后手段)
如果方案一和方案二都无效,且没有可用的备份,可以尝试使用隐藏参数强制打开数据库。这是死马当作活马医的最后步骤,在生产环境中是不可逆的,操作前必须做好备份。
4.3.1 _OFFLINE_ROLLBACK_SEGMENTS 与 _CORRUPTED_ROLLBACK_SEGMENTS 的区别
这两个隐藏参数用于回滚段异常导致数据库无法正常工作的特殊恢复场景,主要包括:数据库打开、一致读和块清除、回滚段删除。
| 参数 | 行为 | 风险 |
|---|---|---|
_OFFLINE_ROLLBACK_SEGMENTS |
仅将指定的回滚段暂时离线,将来可能可以再次 ONLINE。实例启动时仍会读取这些段,如果访问出现问题会在 Alert Log 中体现,但不影响启动进程 | 如果这些段上有活动事务,DML 更新可能导致服务进程进入死循环消耗大量 CPU |
_CORRUPTED_ROLLBACK_SEGMENTS |
将指定的回滚段标记为损坏,启动时不会访问读取这些段。所有指向这些段的事务都被认为已提交 | 可能导致严重的逻辑讹误。如果数据字典上有活跃事务,可能导致 ORA-00704 bootstrap process failure 错误 |
两个参数的共同点:所列出的 Undo Segments 在实例生命周期中将不会被分配给新的事务使用。
注意 :当数据库使用 _corrupted_rollback_segments 参数强制打开后,Oracle 公司内部有叫做 TXChecker 的工具可以检查问题事务。强烈建议打开数据库后导出数据并重建数据库。
4.3.2 操作步骤
步骤一:确定损坏的回滚段名称
从 Trace 文件中提取损坏的回滚段名称,通常是 _SYSSMU 开头的段名。例如:_SYSSMU10_1234567890$。
步骤二:从 SPFILE 创建 PFILE 并修改
命令:
CREATE PFILE='/tmp/force_open.ora' FROM SPFILE;编辑 PFILE:
vi /tmp/force_open.ora添加以下参数 (根据需要使用 _offline_rollback_segments 或 _corrupted_rollback_segments):
# 假设损坏的是 _SYSSMU10$ 和 _SYSSMU9$
_corrupted_rollback_segments=('_SYSSMU10_1234567890$','_SYSSMU9_1234567891$')或者使用 _offline_rollback_segments(风险相对较低):
_offline_rollback_segments=('_SYSSMU10_1234567890$','_SYSSMU9_1234567891$')步骤三:尝试打开数据库
命令:
STARTUP MOUNT PFILE='/tmp/force_open.ora';
ALTER DATABASE OPEN;示例输出(成功时):
Database mounted.
Database opened.步骤四:如果仍然失败,添加事件参数
如果使用上述参数后仍然报错,可以结合方案二中的事件参数:
undo_management=manual
_corrupted_rollback_segments=('_SYSSMU10_1234567890$','_SYSSMU9_1234567891$')
event='10513 trace name context forever, level 2'
event='10512 trace name context forever, level 1'
event='10511 trace name context forever, level 2'
event='10510 trace name context forever, level 1'步骤五:数据库打开后的善后处理
⚠️ 极其重要 :使用 _corrupted_rollback_segments 打开数据库后,必须立即导出数据并重建数据库。
命令:
# 使用 expdp 导出全部数据
expdp system/password directory=DATA_PUMP_DIR dumpfile=full_export.dmp full=Y
# 重建数据库(DBCA 或手动创建)
# 将导出的数据导入新数据库
impdp system/password directory=DATA_PUMP_DIR dumpfile=full_export.dmp full=Y5 恢复后的验证与善后
无论使用哪种方案成功打开数据库后,都必须进行全面的数据验证。
5.1 检查 Alert Log
命令:
SELECT originating_timestamp, message_text
FROM v$diag_alert_ext
WHERE message_text LIKE '%ORA-00600%' OR message_text LIKE '%ORA-12751%'
ORDER BY originating_timestamp DESC
FETCH FIRST 20 ROWS ONLY;5.2 检查 Undo 段状态
命令:
SELECT segment_name, status, tablespace_name
FROM dba_rollback_segs
ORDER BY segment_name;期望输出:所有 Undo 段的状态应为 ONLINE 或 OFFLINE,不应有 NEEDS RECOVERY 或 PARTLY AVAILABLE。
5.3 验证关键数据
命令:
-- 检查是否有无效对象
SELECT owner, object_name, object_type, status
FROM dba_objects
WHERE status != 'VALID'
ORDER BY owner, object_type;
-- 运行 DBMS_REDEFINITION 或其他工具验证数据一致性(可选)5.4 创建新的 Undo 表空间(如尚未执行)
如果方案三中使用了隐藏参数打开数据库,且尚未创建新的 Undo 表空间,应立即执行:
命令:
CREATE UNDO TABLESPACE undotbs_new
DATAFILE '/u01/app/oracle/oradata/orcl/undotbs_new_01.dbf'
SIZE 10G AUTOEXTEND ON NEXT 1G MAXSIZE 32G;
ALTER SYSTEM SET undo_tablespace=undotbs_new SCOPE=BOTH;
-- 删除旧的 Undo 表空间
DROP TABLESPACE undotbs1 INCLUDING CONTENTS AND DATAFILES;6 Oracle 19.29 版本注意事项
6.1 19.29/19.30 RU 的已知问题
在 RAC 集群上滚动更新至 19.29 和 19.30 DBRU 后,少数情况下可能出现主数据库块损坏和重做日志损坏,这可能会影响备用数据库的恢复。此问题会影响 19.29 和 19.30 DBRU,但不会影响 Grid Infrastructure 或客户端主目录。
受影响的错误:如果数据库日志中报错 ORA-00600 4193、ORA-00600 kclchkblk_3、ORA-00600 kclcfusion_17 等错误,很可能就是遇到了此问题。
问题的根本原因:在 19.29 DBRU 中,Bug 34352668 的修复可能导致某些实例在滚动更新期间禁用 RAC 锁状态错误处理。在某些全局缓存挂起的情况下,这可能会导致锁状态不一致,并且在极少数情况下会导致数据块损坏。
解决方案:
-
如果已经安装 19.29~19.30,可以直接安装 one-off 补丁 38854064 进行修复
-
根据 Mike Dietrich 的信息,19.30 RU 已经重新上传并修复了此问题,而 19.29 RU 仍然保持密码保护状态,以防止用户遇到该问题
-
受影响范围 :此问题仅影响进行 RAC 滚动更新的环境,不影响单实例、standby-first 补丁应用或 Transient Logical Standby 更新
6.2 19.29 版本的其他注意事项
部分客户从 19.28 升级到 19.29 后,diagnostic_dest 目录被大量包含 "Dump of memory" 内容的跟踪文件填满。这可能与应用上下文等操作有关,需要额外排查。
6.3 版本建议
-
如果您的数据库版本低于 19.20,建议升级到 19.29 以获得最新的 Bug 修复
-
在 RAC 环境中升级到 19.29 之前,请仔细评估滚动升级的风险
-
升级前请务必备份数据库
7 完整诊断脚本(一键收集)
将以下内容保存为 diag_ora600_4193.sql,以 SYSDBA 执行:
SET ECHO OFF FEEDBACK OFF TERMOUT OFF
SPOOL diag_ora600_4193_$(date +%Y%m%d_%H%M%S).log
PROMPT ==================== 1. Database Version ====================
SELECT banner_full FROM v$version;
PROMPT ==================== 2. Undo Configuration ====================
SHOW PARAMETER undo;
PROMPT ==================== 3. Alert Log ORA-00600 [4193] ====================
SELECT originating_timestamp, message_text
FROM v$diag_alert_ext
WHERE message_text LIKE '%ORA-00600%4193%' OR message_text LIKE '%ORA-00600%4194%'
ORDER BY originating_timestamp DESC
FETCH FIRST 50 ROWS ONLY;
PROMPT ==================== 4. Recent Trace Files ====================
SELECT name, modification_time, size/1024/1024 AS size_mb
FROM v$diag_trace_file
WHERE modification_time > SYSDATE - 7
ORDER BY modification_time DESC;
PROMPT ==================== 5. Rollback Segments Status ====================
SELECT segment_name, status, tablespace_name
FROM dba_rollback_segs
ORDER BY segment_name;
PROMPT ==================== 6. Current Database Open Mode ====================
SELECT open_mode FROM v$database;
PROMPT ==================== 7. Hidden Parameters Related to Rollback ====================
SELECT ksppinm, ksppstvl, ksppdesc
FROM x$ksppi x, x$ksppsv y
WHERE x.indx = y.indx
AND ksppinm IN ('_offline_rollback_segments', '_corrupted_rollback_segments',
'_smu_debug_mode', '_disable_undo_check');
SPOOL OFF
PROMPT Diagnostic completed. Check the spool file diag_ora600_4193_*.log执行命令:
sqlplus / as sysdba @diag_ora600_4193.sql8 总结
8.1 核心要点回顾
-
ORA-00600 4193 是 Undo 与 Redo 记录不匹配导致的内部错误,参数
[a]是 Undo 块中的序列号,[b]是 Redo 日志中记录的序列号。该错误从 Oracle 6.0 开始被引入,属于内核事务 Undo 管理层。 -
该错误通常由异常断电、硬件故障、Bug 或操作错误引发。
-
恢复方法(按推荐顺序):
-
从备份恢复(最安全)
-
重建 Undo 表空间(标准方法,无需不受支持的隐藏参数)
-
使用隐藏参数强制打开(最后手段,风险极高)
-
-
使用
_corrupted_rollback_segments后必须导出数据并重建数据库,否则可能留下顽固的逻辑讹误。 -
Oracle 19.29/19.30 RU 在 RAC 滚动更新场景下存在已知问题,需谨慎评估。19.29 RU 仍然保持密码保护状态,19.30 RU 已重新上传修复。
8.2 决策树
当遇到 ORA-00600 4193 时:
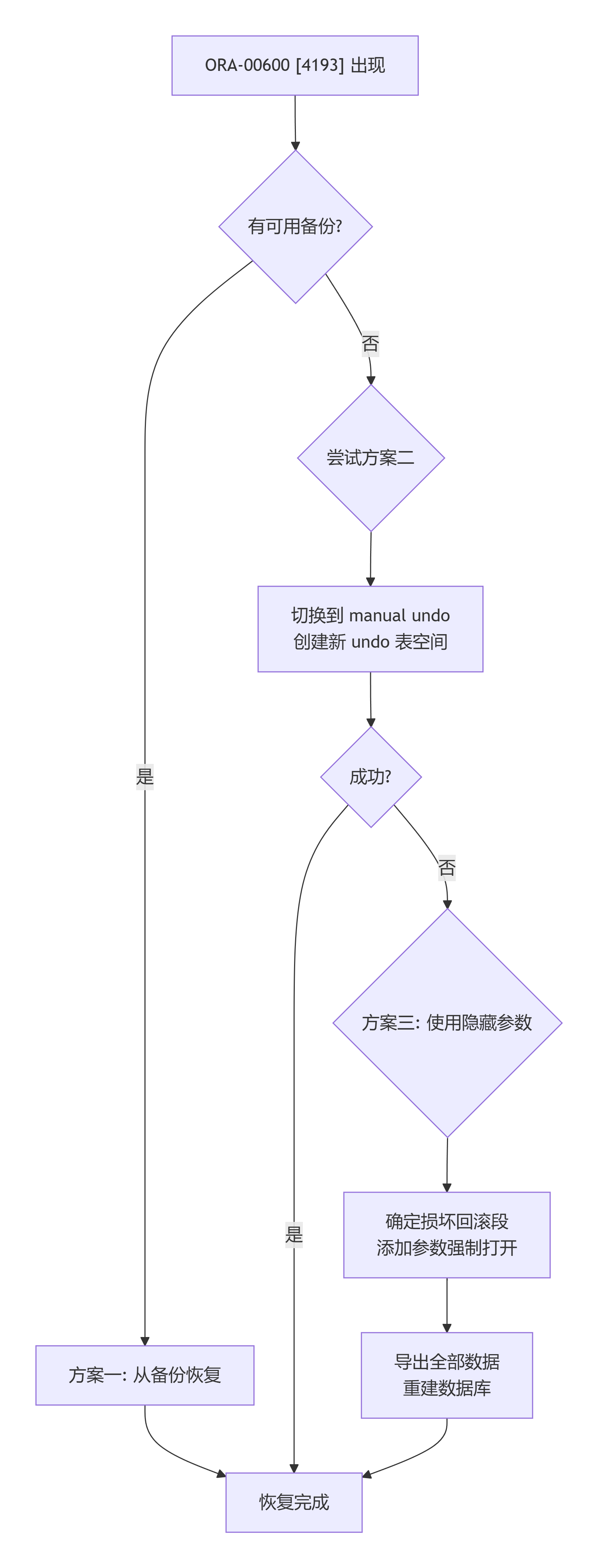
8.3 最终建议
-
优先备份:在尝试任何恢复操作前,先对当前数据库状态进行冷备份
-
优先选择标准方法:方案二(重建 Undo 表空间)是 Oracle 官方文档中推荐的标准方法,无需使用不受支持的隐藏参数
-
隐藏参数是最后手段 :使用
_corrupted_rollback_segments打开数据库后,必须导出数据并重建数据库 -
版本管理:升级到 19.29 前请仔细评估风险,特别是 RAC 环境中的滚动升级。如果只需要单实例升级,则不受 Bug 34352668 影响
-
联系支持:如果无法自行恢复,请及时联系 Oracle 技术支持
文档版本 :1.0
整合自 :Oracle Doc ID 39282.1、Doc ID 1428786.1、Doc ID 106638.1
适用版本 :Oracle Database 19.29+
最后更新 :2026-04-15
示例输出基于:Oracle 19.29 模拟环境