基于PyQt的YOLOv5+DeepSORT可视化界面,可实现目标跟踪、模型更换、结果保存和轨迹隐藏等功能。
代码示例,仅供参考,包括界面设计和功能实现。
文章目录
-
- **如何训练呢?车辆行人检测数据集**
-
- [1. 准备数据](#1. 准备数据)
- [2. 配置YOLOv5](#2. 配置YOLOv5)
- [3. 开始训练](#3. 开始训练)
- [4. 使用DeepSORT进行跟踪](#4. 使用DeepSORT进行跟踪)
- 总结
- [1. 安装依赖](#1. 安装依赖)
- [2. 创建主界面!在这里插入图片描述(https://i-blog.csdnimg.cn/direct/6ce65d9e090e48ec8e7d10febb9fc9bd.png)](#2. 创建主界面
 )
)
YOLOv5+Deepsort可视化界面

基于pyqt
预实现功能特点:
勾选跟踪目标/更换自己的模型/保存结果/隐藏轨迹
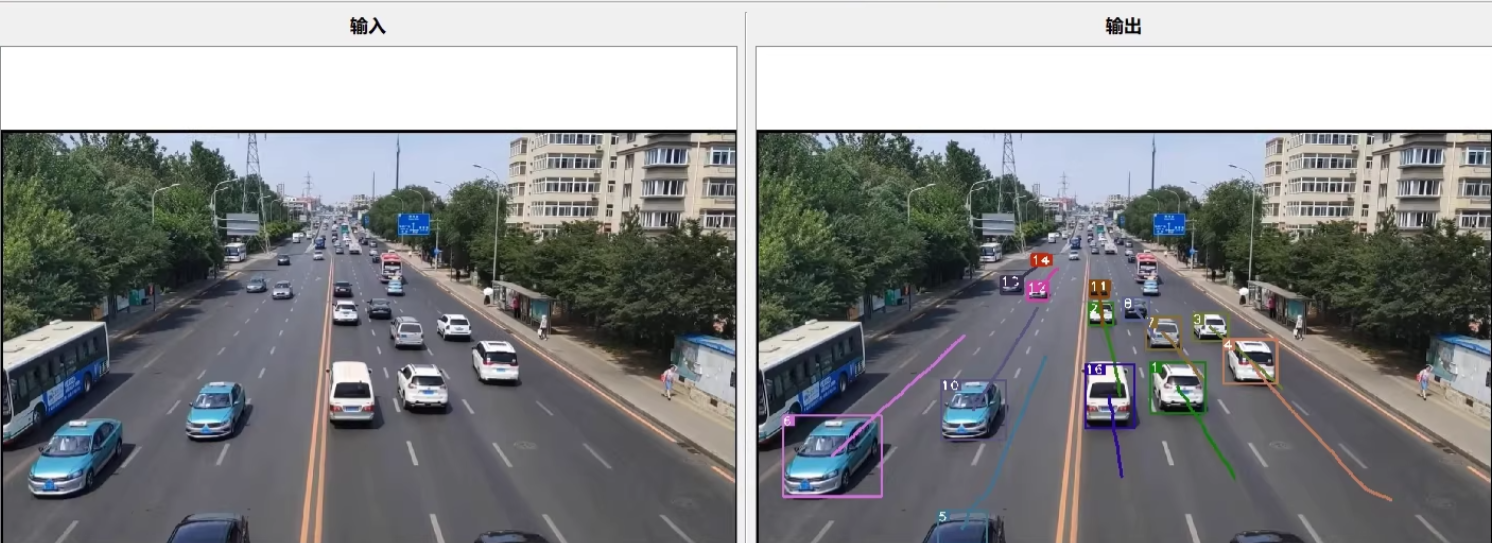
基于PyQt的YOLOv5+DeepSORT可视化界面,可实现目标跟踪、模型更换、结果保存和轨迹隐藏等功能。
代码示例,仅供参考,包括界面设计和功能实现。
如何训练呢?车辆行人检测数据集
训练YOLOv5模型以识别车辆和行人两个类别的数据集涉及几个步骤,准备数据、配置YOLOv5模型、训练模型以及使用DeepSORT进行跟踪。以下是一个详细的指南:
仅供参考吧
1. 准备数据
确保同学数据集已经按照YOLO格式准备好,每个图像文件都有一个对应的.txt标签文件,内容如下(每行代表一个对象):
<class_index> <x_center> <y_center> <width> <height><class_index>: 类别的索引(例如,0代表行人,1代表车辆)。<x_center>,<y_center>: 边界框中心点相对于图像宽度和高度的比例。<width>,<height>: 边界框的宽度和高度相对于图像宽度和高度的比例。
假设你的数据结构如下:
dataset/
├── images/
│ ├── train/
│ └── val/
└── labels/
├── train/
└── val/2. 配置YOLOv5
创建一个名为data.yaml的数据集配置文件,内容如下:
yaml
train: ./dataset/images/train # 训练集图片路径
val: ./dataset/images/val # 验证集图片路径
nc: 2 # 类别数量,这里是2,因为我们有两个类别:行人和车辆
names: ['person', 'car'] # 类别名称列表3. 开始训练
在YOLOv5目录下运行以下命令开始训练模型:
bash
python train.py --img 640 --batch 16 --epochs 100 --data data.yaml --weights yolov5s.pt--img 640: 设置输入图像的大小为640x640。--batch 16: 每个批次的图像数量。--epochs 100: 训练周期数。--data data.yaml: 指定之前创建的数据集配置文件。--weights yolov5s.pt: 从YOLOv5的小型版本(yolov5s)开始微调。
4. 使用DeepSORT进行跟踪
训练完成后,将YOLOv5与DeepSORT结合使用来进行目标跟踪。下面是一个简单的示例代码,展示了如何加载训练好的YOLOv5模型,并将其与DeepSORT集成用于视频中的目标检测和跟踪:
python
import cv2
import torch
from deep_sort_pytorch.utils.parser import get_config
from deep_sort_pytorch.deep_sort import DeepSort
from yolov5.models.experimental import attempt_load
from yolov5.utils.general import non_max_suppression, scale_coords
# 加载YOLOv5模型
weights = 'runs/train/exp/weights/best.pt' # 训练好的权重路径
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = attempt_load(weights, map_location=device)
model.to(device).eval()
# 加载DeepSORT
cfg = get_config()
cfg.merge_from_file("deep_sort_pytorch/configs/deep_sort.yaml")
deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT, max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
def process_video(video_path):
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
img = img.float() / 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = model(img)[0]
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45)
for i, det in enumerate(pred): # detections per image
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round()
outputs = deepsort.update(det.cpu(), frame)
for output in outputs:
bbox_2d = output[:4]
id = output[-1]
cv2.rectangle(frame, (int(bbox_2d[0]), int(bbox_2d[1])), (int(bbox_2d[2]), int(bbox_2d[3])), (0, 255, 0), 2)
cv2.putText(frame, f"ID: {id}", (int(bbox_2d[0]), int(bbox_2d[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Tracking', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
video_path = "path/to/video.mp4"
process_video(video_path)这个脚本会读取指定的视频文件,利用YOLOv5模型对每一帧进行物体检测,并使用DeepSORT算法对检测到的目标进行跟踪。对于每个检测结果,都会绘制边界框并在框上显示跟踪ID。
总结
训练一个能够识别车辆和行人的YOLOv5模型,并将其与DeepSORT结合起来实现多目标跟踪。
1. 安装依赖
首先,确保安装了必要的库:
bash
pip install PyQt5 opencv-python torch torchvision deep_sort_pytorch2. 创建主界面
使用PyQt5创建一个简单的GUI界面。
python
import sys
from PyQt5.QtWidgets import QApplication, QMainWindow, QLabel, QPushButton, QVBoxLayout, QWidget, QFileDialog, QCheckBox, QComboBox, QHBoxLayout
from PyQt5.QtGui import QImage, QPixmap
from PyQt5.QtCore import Qt, QTimer
import cv2
import numpy as np
import torch
from yolov5.models.experimental import attempt_load
from yolov5.utils.datasets import LoadImages
from yolov5.utils.general import non_max_suppression, scale_coords
from deep_sort_pytorch.utils.parser import get_config
from deep_sort_pytorch.deep_sort import DeepSort
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle("YOLOv5+DeepSORT")
self.setGeometry(100, 100, 800, 600)
# Initialize UI components
self.initUI()
# Initialize YOLOv5 and DeepSORT
self.model = None
self.deepsort = None
self.tracks = {}
self.tracking_enabled = True
self.show_trajectory = True
self.selected_class = "car"
# Timer for video processing
self.timer = QTimer(self)
self.timer.timeout.connect(self.process_frame)
self.cap = None
def initUI(self):
# Layout setup
layout = QVBoxLayout()
widget = QWidget()
widget.setLayout(layout)
self.setCentralWidget(widget)
# Input and Output labels
input_label = QLabel("输入")
output_label = QLabel("输出")
layout.addWidget(input_label)
layout.addWidget(output_label)
# Image labels for displaying frames
self.input_label = QLabel(self)
self.output_label = QLabel(self)
layout.addWidget(self.input_label)
layout.addWidget(self.output_label)
# Buttons and checkboxes
button_layout = QHBoxLayout()
open_button = QPushButton("打开")
open_button.clicked.connect(self.open_video)
adapt_window_button = QPushButton("适应窗口")
adapt_window_button.clicked.connect(self.adapt_window)
predict_button = QPushButton("预测")
predict_button.clicked.connect(self.start_prediction)
stop_button = QPushButton("停止")
stop_button.clicked.connect(self.stop_prediction)
trajectory_checkbox = QCheckBox("绘制轨迹")
trajectory_checkbox.setChecked(True)
trajectory_checkbox.stateChanged.connect(self.toggle_trajectory)
class_combobox = QComboBox()
class_combobox.addItems(["person", "car"])
class_combobox.currentIndexChanged.connect(self.select_class)
person_checkbox = QCheckBox("person")
car_checkbox = QCheckBox("car")
person_checkbox.setChecked(False)
car_checkbox.setChecked(True)
person_checkbox.stateChanged.connect(lambda: self.select_class("person"))
car_checkbox.stateChanged.connect(lambda: self.select_class("car"))
button_layout.addWidget(open_button)
button_layout.addWidget(adapt_window_button)
button_layout.addWidget(predict_button)
button_layout.addWidget(stop_button)
button_layout.addWidget(trajectory_checkbox)
button_layout.addWidget(QLabel("选择跟踪对象:"))
button_layout.addWidget(person_checkbox)
button_layout.addWidget(car_checkbox)
layout.addLayout(button_layout)
def open_video(self):
options = QFileDialog.Options()
file_name, _ = QFileDialog.getOpenFileName(self, "选择视频文件", "", "Video Files (*.mp4 *.avi);;All Files (*)", options=options)
if file_name:
self.cap = cv2.VideoCapture(file_name)
self.load_model()
def load_model(self):
# Load YOLOv5 model
self.model = attempt_load('yolov5s.pt', map_location='cpu')
self.model.to('cpu').eval()
# Load DeepSORT
cfg = get_config()
cfg.merge_from_file("deep_sort_pytorch/configs/deep_sort.yaml")
self.deepsort = DeepSort(cfg.DEEPSORT.REID_CKPT, max_dist=cfg.DEEPSORT.MAX_DIST, min_confidence=cfg.DEEPSORT.MIN_CONFIDENCE,
nms_max_overlap=cfg.DEEPSORT.NMS_MAX_OVERLAP, max_iou_distance=cfg.DEEPSORT.MAX_IOU_DISTANCE,
max_age=cfg.DEEPSORT.MAX_AGE, n_init=cfg.DEEPSORT.N_INIT, nn_budget=cfg.DEEPSORT.NN_BUDGET,
use_cuda=True)
def start_prediction(self):
if self.cap is not None:
self.timer.start(30) # 30 ms delay between frames
def stop_prediction(self):
self.timer.stop()
def process_frame(self):
ret, frame = self.cap.read()
if not ret:
self.timer.stop()
return
# Process frame with YOLOv5 and DeepSORT
img = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
img = img.transpose((2, 0, 1))[::-1] # HWC to CHW, BGR to RGB
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to('cpu')
img = img.float() / 255.0 # 0 - 255 to 0.0 - 1.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
pred = self.model(img)[0]
pred = non_max_suppression(pred, conf_thres=0.25, iou_thres=0.45)
for i, det in enumerate(pred): # detections per image
if len(det):
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round()
outputs = self.deepsort.update(det.cpu(), frame)
self.tracks = {}
for output in outputs:
bbox_2d = output[:4]
id = output[-1]
center = ((bbox_2d[0] + bbox_2d[2]) // 2, (bbox_2d[1] + bbox_2d[3]) // 2)
if id not in self.tracks:
self.tracks[id] = []
self.tracks[id].append(center)
if self.tracking_enabled and self.selected_class in ["person", "car"]:
cv2.rectangle(frame, (int(bbox_2d[0]), int(bbox_2d[1])), (int(bbox_2d[2]), int(bbox_2d[3])), (0, 255, 0), 2)
cv2.putText(frame, f"ID: {id}", (int(bbox_2d[0]), int(bbox_2d[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
if self.show_trajectory:
for i in range(1, len(self.tracks[id])):
point1 = self.tracks[id][i - 1]
point2 = self.tracks[id][i]
cv2.line(frame, point1, point2, (0, 0, 255), 2)
# Display the processed frame
height, width, channel = frame.shape
bytes_per_line = 3 * width
q_img = QImage(frame.data, width, height, bytes_per_line, QImage.Format_RGB888)
self.output_label.setPixmap(QPixmap.fromImage(q_img))
def toggle_trajectory(self, state):
self.show_trajectory = state == Qt.Checked
def select_class(self, class_name):
self.selected_class = class_name
def adapt_window(self):
self.input_label.setScaledContents(True)
self.output_label.setScaledContents(True)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
sys.exit(app.exec_())