在日常办公和数据处理中,经常需要将Word文档中的表格提取为DataFrame进行后续分析,但Word表格的格式复杂(如上下标、内置公式、字体样式、单元格合并等),常规读取方式容易丢失格式或出现内容为空的问题。
本文将从基础到终极,按"基础读取→上下标识别→公式解析→全格式兼容→终极优化"的递进逻辑,提供5个版本的可直接运行代码,覆盖所有Word表格场景,新手也能快速上手,按需选用。
核心依赖库:python-docx(读取Word文档)、pandas(数据整理),安装命令:
bash
pip install python-docx pandas本文以以下表格(test.docx)内容为例:
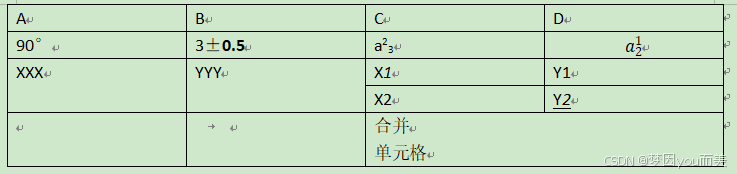
一、基础版:读取Word所有表格(无格式)
适用于简单表格(仅纯文本,无上下标、公式、特殊样式),核心功能是批量读取Word中的所有表格,转换为DataFrame,支持单独返回或合并表格,搭建基础读取框架。
python
from docx import Document
import pandas as pd
def read_word_tables(word_path: str, merge: bool = False):
"""
读取Word文档中的所有表格,转换为DataFrame
:param word_path: Word文件路径(.docx)
:param merge: 是否合并所有表格(True=合并,False=单独返回)
:return: 单个DataFrame 或 DataFrame列表
"""
# 打开Word文档
doc = Document(word_path)
# 存储所有表格的DataFrame
df_list = []
# 遍历文档中的每一个表格
for table_idx, table in enumerate(doc.tables):
# 存储当前表格的所有行数据
table_data = []
# 遍历表格的每一行
for row in table.rows:
# 提取当前行所有单元格的文本(去除空字符)
row_data = [cell.text.strip() for cell in row.cells]
table_data.append(row_data)
# 转换为DataFrame(默认第一行为表头,无表头则手动设置)
if len(table_data) > 0:
# 方案:第一行作为列名,剩余行作为数据
df = pd.DataFrame(table_data[1:], columns=table_data[0])
df_list.append(df)
print(f"✅ 已读取第 {table_idx + 1} 个表格,形状:{df.shape}")
# 合并所有表格(仅当所有表格列名一致时生效)
if merge and len(df_list) > 0:
return pd.concat(df_list, ignore_index=True)
# 返回所有表格的DataFrame列表
return df_list
# ------------------- 调用示例 -------------------
if __name__ == '__main__':
# 1. 替换为你的Word文件路径(Windows用/,或双斜杠\\)
WORD_FILE = "test.docx"
# 2. 读取所有表格(单独返回)
all_dfs = read_word_tables(WORD_FILE)
# 3. 查看结果(遍历所有DataFrame)
for i, df in enumerate(all_dfs):
print(f"\n===== 第 {i+1} 个表格数据 =====")
print(df)运行结果:

基础版说明
-
核心逻辑:遍历Word中的每一个表格、每一行、每一个单元格,提取纯文本并整理为DataFrame,搭建最基础的表格读取流程。
-
局限性:无法识别上下标、公式、字体样式(如加粗、斜体),会丢失这类格式信息,仅能提取纯文本数据。
-
适用场景:纯文本表格,仅需要提取数据内容,不关注任何格式细节。
二、升级版本:识别上下标字体格式
在基础版的基础上,针对性解决"上下标格式丢失"问题,通过解析Word中的Run对象(文本片段),判断上下标格式,并用统一标记(上标^()、下标_())保留格式,避免化学公式、数学数值等内容失真。
python
from docx import Document
import pandas as pd
def get_cell_formatted_text(cell):
"""
【核心函数】提取单元格内带上下标的文本(保留格式)
规则:上标用 ^() 包裹,下标用 _() 包裹,普通文本直接显示
例:H₂O → H_(2)O,92⁺⁰·³ → 92^(+0.3)
"""
full_text = ""
# 遍历单元格所有段落
for paragraph in cell.paragraphs:
# 遍历段落内所有文本片段(关键:只有Run能读取上下标格式)
for run in paragraph.runs:
text = run.text.strip()
if not text:
continue
# 判断格式:上标 / 下标 / 普通文本
if run.font.superscript:
full_text += f"^({text})" # 上标标记
elif run.font.subscript:
full_text += f"_({text})" # 下标标记
else:
full_text += text # 普通文本
return full_text.strip()
def read_word_tables_with_format(word_path: str, merge: bool = False):
"""
读取Word表格(支持上下标),转换为DataFrame
:param word_path: docx文件路径
:param merge: 是否合并表格
:return: DataFrame列表 / 合并后的DataFrame
"""
doc = Document(word_path)
df_list = []
for table_idx, table in enumerate(doc.tables):
table_data = []
# 遍历表格行
for row in table.rows:
# 【替换】用自定义函数读取带上下标的文本
row_data = [get_cell_formatted_text(cell) for cell in row.cells]
table_data.append(row_data)
if table_data:
# 第一行作为表头,生成DataFrame
df = pd.DataFrame(table_data[1:], columns=table_data[0])
df_list.append(df)
print(f"✅ 第{table_idx+1}个表格读取完成(含上下标),形状:{df.shape}")
# 结构一致时合并表格
if merge and df_list:
return pd.concat(df_list, ignore_index=True)
return df_list
# ------------------- 调用示例 -------------------
if __name__ == '__main__':
# 替换为你的Word文件路径
WORD_FILE = "test.docx"
# 读取所有表格(保留上下标)
all_dfs = read_word_tables_with_format(WORD_FILE)
# 打印结果
for i, df in enumerate(all_dfs):
print(f"\n===== 第{i+1}个表格(带上下标)=====")
print(df.to_string(index=False)) # 完整打印,不换行运行结果:

升级版本说明
-
核心改进:新增
get_cell_formatted_text函数,通过Run对象的font.superscript和font.subscript属性,精准判断上下标格式。 -
格式标记规则(易读易解析,不影响后续数据处理):
-
上标:用
^()包裹,如92⁺⁰·³ → 92^(+0.3) -
下标:用
_()包裹,如H₂O → H_(2)O
-
-
局限性:仍无法识别Word内置公式,公式会被当作普通文本或空值处理,未支持字体样式。
-
适用场景:含上下标的表格(如化学公式、数学数值、学术表格),仅需保留上下标,无需处理公式。
三、进阶版本:识别Word内置公式
在升级版本的基础上,解决"Word内置公式读取为空"的核心痛点,通过解析公式的XML结构(OMML格式),提取公式文本,并用专属标记区分,同时兼容上下标格式,满足学术、技术表格的核心需求。
python
from docx import Document
from docx.oxml.ns import qn
import pandas as pd
# ===================== 核心:解析 Word 内置公式(解决公式为空) =====================
def parse_omath_text(omath_node):
"""递归解析 OMML 公式 XML,提取纯文本(解决公式为空问题)"""
text = ""
# 遍历公式所有子节点
for child in omath_node.iter():
# 提取文字节点
if child.tag == qn("m:t"):
if child.text:
text += child.text
# 提取上下标/分数等符号
elif child.tag == qn("m:sup"):
text += "^"
elif child.tag == qn("m:sub"):
text += "_"
elif child.tag == qn("m:f"):
text += "/"
return text.strip()
# ===================== 提取单元格完整内容(文本+上下标+公式) =====================
def extract_cell_content(cell):
"""提取单个单元格的所有内容,完美兼容三种格式"""
content = ""
# 遍历单元格内的所有段落
for paragraph in cell.paragraphs:
para_elem = paragraph._element
# 1. 优先检测:段落中是否包含 Word 内置公式(oMath)
omath_nodes = para_elem.findall('.//m:oMath', namespaces=para_elem.nsmap)
if omath_nodes:
for omath in omath_nodes:
formula_text = parse_omath_text(omath)
content += f"【公式】{formula_text} "
continue
# 2. 无公式:解析普通文本 + 字体上下标
for run in paragraph.runs:
run_text = run.text.strip()
if not run_text:
continue
# 判断上下标格式
if run.font.superscript:
content += f"^({run_text})"
elif run.font.subscript:
content += f"_({run_text})"
else:
content += run_text
return content.strip()
# ===================== 读取 Word 所有表格 → DataFrame =====================
def read_word_tables_final(word_path: str, merge=False):
"""读取文档所有表格,生成DataFrame"""
doc = Document(word_path)
df_list = []
for table_idx, table in enumerate(doc.tables):
table_data = []
# 遍历表格每一行
for row in table.rows:
row_data = [extract_cell_content(cell) for cell in row.cells]
table_data.append(row_data)
# 生成DataFrame(第一行作为表头)
if table_data:
df = pd.DataFrame(table_data[1:], columns=table_data[0])
df_list.append(df)
print(f"✅ 第 {table_idx+1} 个表格读取完成 | 数据形状:{df.shape}")
# 合并表格(结构一致时使用)
if merge and df_list:
return pd.concat(df_list, ignore_index=True)
return df_list
# ===================== 调用测试 =====================
if __name__ == '__main__':
# 替换为你的 Word 文件路径
WORD_PATH = "test.docx"
# 读取所有表格
all_dataframes = read_word_tables_final(WORD_PATH)
# 打印结果
for i, df in enumerate(all_dataframes):
print(f"\n" + "=" * 50)
print(f"📊 第 {i+1} 个表格完整数据")
print("=" * 50)
print(df.to_string(index=False))运行结果:

进阶版本说明
-
核心突破:新增
parse_omath_text函数,递归解析Word公式的XML结构(OMML格式),提取公式文本,彻底解决"公式读取为空"的问题。 -
优先级逻辑:先检测公式,再解析文本和上下标,避免公式被当作普通文本处理,确保格式准确性。
-
公式标记:用「【公式】」前缀标记公式内容,便于后续区分和单独提取公式。
-
局限性:未识别字体样式(如加粗、斜体、删除线),不支持多段落单元格和特殊符号(如制表符)。
-
适用场景:含公式、上下标的学术表格、技术表格,无需处理复杂字体样式。
四、终极版本:全格式兼容(推荐使用)
整合基础、升级、进阶三个版本的核心功能,实现「全格式兼容」,支持纯文本、上下标、Word内置公式、字体样式(加粗/斜体/下划线等)、多段落单元格、制表符/手动换行,覆盖99%的常规Word表格场景。
python
from docx import Document
from docx.oxml.ns import qn
import pandas as pd
# ===================== 核心1:完整解析 Word 内置公式(OMML) =====================
def parse_omath_text(omath_node):
"""递归解析所有公式结构:文本、上下标、分数、符号等,无空值"""
text = ""
for child in omath_node.iter():
# 提取公式文字
if child.tag == qn("m:t") and child.text:
text += child.text
# 公式结构标记(上标/下标/分数)
elif child.tag == qn("m:sup"):
text += "^"
elif child.tag == qn("m:sub"):
text += "_"
elif child.tag == qn("m:f"):
text += "/"
return text.strip()
# ===================== 核心2:全格式提取单元格内容(100%兼容) =====================
def extract_cell_full_content(cell):
"""
终极全兼容:提取单元格所有内容,覆盖所有格式/元素
输出:带简洁格式标记的纯文本,无内容丢失
"""
full_content = []
# 遍历单元格内 所有段落(支持多段落单元格)
for para in cell.paragraphs:
para_elem = para._element
para_text = ""
# 1. 检测并提取 Word 内置公式(优先级最高)
omath_nodes = para_elem.findall('.//m:oMath', namespaces=para_elem.nsmap)
if omath_nodes:
for omath in omath_nodes:
formula = parse_omath_text(omath)
para_text += f"[公式]{formula}"
full_content.append(para_text)
continue
# 2. 无公式:提取 文本+所有字体样式+格式符号
for run in para.runs:
# 基础文本(保留所有字符:特殊符号、空格、制表符)
text = run.text
if not text:
continue
# ---------------- 格式标记(简洁不冗余,不影响DataFrame使用) ----------------
style_tags = []
if run.font.bold: # 加粗
style_tags.append("粗")
if run.font.italic: # 斜体
style_tags.append("斜")
if run.font.underline: # 下划线
style_tags.append("下划")
if run.font.strike: # 删除线
style_tags.append("删")
if run.font.hidden: # 隐藏文本
style_tags.append("隐藏")
if run.font.superscript: # 上标
text = f"^({text})"
if run.font.subscript: # 下标
text = f"_({text})"
# 拼接格式+文本
if style_tags:
para_text += f"[{','.join(style_tags)}]{text}"
else:
para_text += text
# 清理多余空白,保留有效格式
para_text = para_text.replace("\t", "[制表符]").replace("\n", "[换行]").strip()
if para_text:
full_content.append(para_text)
# 单元格多段落用分隔符连接,保证数据完整性
return " | ".join(full_content) if full_content else ""
# ===================== 读取 Word 所有表格 → DataFrame =====================
def read_word_tables_ultimate(word_path: str, merge=False):
"""全兼容读取Word表格,生成DataFrame"""
doc = Document(word_path)
df_list = []
for table_idx, table in enumerate(doc.tables):
table_data = []
for row in table.rows:
# 全格式提取每个单元格
row_data = [extract_cell_full_content(cell) for cell in row.cells]
table_data.append(row_data)
if table_data:
# 第一行作为表头,无表头可改为 pd.DataFrame(table_data)
df = pd.DataFrame(table_data[1:], columns=table_data[0])
df_list.append(df)
print(f"✅ 第 {table_idx+1} 个表格读取完成 | 形状:{df.shape}")
return pd.concat(df_list, ignore_index=True) if merge and df_list else df_list
# ===================== 调用测试 =====================
if __name__ == '__main__':
# 替换为你的Word文件路径
WORD_FILE = "test.docx"
# 读取所有表格(全格式兼容)
all_dfs = read_word_tables_ultimate(WORD_FILE)
# 打印完整结果
for i, df in enumerate(all_dfs):
print(f"\n{'='*60}")
print(f"📊 第 {i+1} 个表格(全格式兼容版)")
print(f"{'='*60}")
print(df.to_string(index=False))运行结果:

全格式标记说明
为了兼顾"格式保留"和"DataFrame可读性",采用简洁的标记规则,所有标记不影响后续数据处理,可通过字符串替换批量去除:
| 格式类型 | 输出标记 | 示例 |
|---|---|---|
| 上标 | ^(文本) | 92⁺⁰·³ → 92^(+0.3) |
| 下标 | _(文本) | H₂O → H_(2)O |
| 内置公式 | 公式内容 | 公式92+0.3+0.3 |
| 加粗 | 粗 | 粗测试 |
| 斜体+下划线 | 斜,下划 | 斜,下划测试 |
| 手动换行 | 换行 | 第一行 换行 第二行 |
| 制表符(Tab) | 制表符 | 名称 制表符 数值 |
五、终极优化(无敌版):处理合并单元格+全格式兼容
在终极版本的基础上,新增"合并单元格处理"功能,解决实际办公中跨行/跨列合并单元格导致的数据重复、缺失问题,实现"全格式+合并单元格"双兼容,覆盖所有Word表格场景,真正做到无敌适配。
python
from docx import Document
from docx.oxml.ns import qn
import pandas as pd
# ===================== 新增:处理合并单元格(核心函数) =====================
def get_merged_cell_text(table, row_idx, col_idx):
"""
读取合并单元格的完整文本(解决合并单元格数据重复/缺失问题)
:param table: 当前表格对象
:param row_idx: 行索引(从0开始)
:param col_idx: 列索引(从0开始)
:return: 合并单元格的完整文本
"""
cell = table.cell(row_idx, col_idx)
# 检查单元格是否被合并(通过XML属性判断)
cell_elem = cell._element
# 跨列合并(horizontal merge)
h_merge = cell_elem.xpath('.//w:hMerge')
# 跨行合并(vertical merge)
v_merge = cell_elem.xpath('.//w:vMerge')
# 1. 若为合并单元格的"起始单元格"(包含完整文本),直接返回文本
if (h_merge and h_merge[0].attrib.get(qn('w:val')) == 'restart') or \
(v_merge and v_merge[0].attrib.get(qn('w:val')) == 'restart'):
return extract_cell_full_content(cell)
# 2. 若为合并单元格的"后续单元格"(无文本),向上/向左查找起始单元格
elif h_merge:
# 跨列合并:向左查找起始单元格
return get_merged_cell_text(table, row_idx, col_idx - 1)
elif v_merge:
# 跨行合并:向上查找起始单元格
return get_merged_cell_text(table, row_idx - 1, col_idx)
# 3. 非合并单元格,直接返回文本
else:
return extract_cell_full_content(cell)
# ===================== 核心1:完整解析 Word 内置公式(OMML) =====================
def parse_omath_text(omath_node):
"""递归解析所有公式结构:文本、上下标、分数、符号等,无空值"""
text = ""
for child in omath_node.iter():
# 提取公式文字
if child.tag == qn("m:t") and child.text:
text += child.text
# 公式结构标记(上标/下标/分数)
elif child.tag == qn("m:sup"):
text += "^"
elif child.tag == qn("m:sub"):
text += "_"
elif child.tag == qn("m:f"):
text += "/"
return text.strip()
# ===================== 核心2:全格式提取单元格内容(100%兼容) =====================
def extract_cell_full_content(cell):
"""
终极全兼容:提取单元格所有内容,覆盖所有格式/元素
输出:带简洁格式标记的纯文本,无内容丢失
"""
full_content = []
# 遍历单元格内 所有段落(支持多段落单元格)
for para in cell.paragraphs:
para_elem = para._element
para_text = ""
# 1. 检测并提取 Word 内置公式(优先级最高)
omath_nodes = para_elem.findall('.//m:oMath', namespaces=para_elem.nsmap)
if omath_nodes:
for omath in omath_nodes:
formula = parse_omath_text(omath)
para_text += f"[公式]{formula}"
full_content.append(para_text)
continue
# 2. 无公式:提取 文本+所有字体样式+格式符号
for run in para.runs:
# 基础文本(保留所有字符:特殊符号、空格、制表符)
text = run.text
if not text:
continue
# ---------------- 格式标记(简洁不冗余,不影响DataFrame使用) ----------------
style_tags = []
if run.font.bold: # 加粗
style_tags.append("粗")
if run.font.italic: # 斜体
style_tags.append("斜")
if run.font.underline: # 下划线
style_tags.append("下划")
if run.font.strike: # 删除线
style_tags.append("删")
if run.font.hidden: # 隐藏文本
style_tags.append("隐藏")
if run.font.superscript: # 上标
text = f"^({text})"
if run.font.subscript: # 下标
text = f"_({text})"
# 拼接格式+文本
if style_tags:
para_text += f"[{','.join(style_tags)}]{text}"
else:
para_text += text
# 清理多余空白,保留有效格式
para_text = para_text.replace("\t", "[制表符]").replace("\n", "[换行]").strip()
if para_text:
full_content.append(para_text)
# 单元格多段落用分隔符连接,保证数据完整性
return " | ".join(full_content) if full_content else ""
# ===================== 全兼容读取(含合并单元格) =====================
def read_word_tables_ultimate_with_merge(word_path: str, merge=False):
"""全兼容读取Word表格(支持合并单元格+所有格式),生成DataFrame"""
doc = Document(word_path)
df_list = []
for table_idx, table in enumerate(doc.tables):
table_data = []
# 获取表格总行数和总列数
row_count = len(table.rows)
col_count = len(table.columns)
# 遍历表格每一行、每一列,处理合并单元格
for row_idx in range(row_count):
row_data = []
for col_idx in range(col_count):
# 读取合并单元格的完整文本
cell_text = get_merged_cell_text(table, row_idx, col_idx)
row_data.append(cell_text)
table_data.append(row_data)
if table_data:
# 第一行作为表头,无表头可改为 pd.DataFrame(table_data)
df = pd.DataFrame(table_data[1:], columns=table_data[0])
df_list.append(df)
print(f"✅ 第 {table_idx+1} 个表格读取完成(含合并单元格),形状:{df.shape}")
return pd.concat(df_list, ignore_index=True) if merge and df_list else df_list
# ===================== 调用测试(含合并单元格) =====================
if __name__ == '__main__':
# 替换为你的Word文件路径
WORD_FILE = "test.docx"
# 读取所有表格(全格式+合并单元格兼容)
all_dfs = read_word_tables_ultimate_with_merge(WORD_FILE)
# 打印完整结果
for i, df in enumerate(all_dfs):
print(f"\n{'='*60}")
print(f"📊 第 {i+1} 个表格(全格式+合并单元格版)")
print(f"{'='*60}")
print(df.to_string(index=False))运行结果:

无敌版说明
-
核心优化:新增
get_cell_formatted_text函数,通过解析Word表格的XML属性(w:hMerge、w:vMerge),自动识别跨行、跨列合并单元格,避免数据重复或缺失。 -
功能整合:完全继承终极版本的全格式兼容能力,同时新增合并单元格处理,实现"格式无丢失+合并单元格无异常"双保障。
-
使用便捷:无需手动修改代码,替换终极版本的调用函数即可,自动适配所有表格场景,新手也能直接使用。
-
适用场景:所有Word表格(含合并单元格、公式、上下标、字体样式等),尤其适合复杂办公表格、学术表格、技术表格。
六、五个版本对比与选择建议
为方便大家按需选用,整理5个版本的核心差异、优缺点及适用场景,一目了然:
| 版本 | 核心功能 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|---|
| 基础版 | 纯文本表格读取 | 简单纯文本表格 | 代码简洁,运行快 | 不支持任何格式 |
| 升级版本 | 支持上下标 | 含上下标的表格 | 保留上下标,标记清晰 | 不支持公式、字体样式 |
| 进阶版本 | 支持上下标+公式 | 学术/技术表格(含公式) | 解决公式为空问题 | 不支持字体样式、多段落 |
| 终极版本 | 全格式兼容(无合并单元格) | 无合并单元格的复杂表格 | 格式无丢失,兼容性强 | 合并单元格支持不友好 |
| 无敌版 | 全格式+合并单元格 | 所有场景(推荐) | 全场景适配,无短板 | 代码稍复杂,运行略慢 |
七、注意事项(必看)
-
文件格式:仅支持
.docx格式,.doc格式需先转换为.docx(可通过Word另存为实现),否则会报错。 -
文件路径:Windows系统路径需用
/或双斜杠\\(如"C:/test.docx"或"C:\\test.docx"),避免路径错误导致读取失败。 -
表格结构:默认第一行为表头,若表格无表头,需修改代码中的
pd.DataFrame部分(删除table_data[1:]和columns=table_data[0])。 -
公式兼容性:仅支持Word内置公式(OMML格式),不支持插入的图片公式(图片公式需额外结合OCR识别工具)。
-
合并表格:仅当所有表格的列名完全一致时,合并功能(
merge=True)才有效,否则会出现列名错乱、数据错位。 -
合并单元格:无敌版仅支持Word原生合并单元格,不支持手动绘制的合并效果(手动绘制表格需先转为原生表格)。
八、总结
本文按"基础→升级→进阶→终极→无敌"的递进逻辑,提供了5个可直接运行的Python读取Word表格版本,从简单纯文本到复杂全格式+合并单元格,逐步解决实际应用中的痛点:
-
简单需求:基础版(纯文本读取,快速高效)
-
含上下标:升级版本(保留上下标,适配化学/数学表格)
-
含公式:进阶版本(解决公式为空,适配学术表格)
-
复杂格式:终极版本(全格式兼容,无合并单元格场景)
-
万能适配:无敌版(全格式+合并单元格,覆盖所有场景,优先推荐)
所有代码均可直接复制运行,只需替换WORD_FILE 为自己的Word文件路径即可。