大家好,我是双越。wangEditor 作者,前百度 滴滴 资深前端工程师,慕课网金牌讲师,PMP,前端面试派 作者。
我正致力于两个项目的开发和升级,感兴趣的可以私信我,加入项目小组。
本文是我 openclaw 的真实使用记录,我用它来搜索、分析和整理 前端 vs 全栈 的招聘岗位。
现在 AI 编程普及,前端转全栈是一个整体趋势,我们看看网上真实的招聘数据如何。
适合 OpenClaw 的应用场景
OpenClaw 最适合的场景之一就是:搜索 整理 分析
如果用人工操作,首先成本太高,要搜很多资料,整理很多数据,做很多纬度的分析,而 AI 可以自动处理,效率高。其次不同人,执行能力和理解能力都不一样,输出的数据也会参差不齐,而 AI 就可以标准化。
如果用其他 AI 工具,如豆包 千问等,它们的搜索质量不好把控,因为现在搜索 API 都是要付费的,它们内部都是免费的。而且,我们不太好自己控制流程和要求,非常依赖于这 app 自己的理解能力。而 OpenClaw 可以使用本地浏览器搜索,搜索质量和人工相似,我们还可以自定义 Skill 来规定流程和要求,让 AI 能更好的理解需求。
创建 skill
这是一个比较复杂的任务,先不急于操作,先创建 Skill 。给 openclaw 输入
在当前 AI 编程普及的情况下,前端工程师 纷纷转行为 全栈工程师。
我想让我帮我搜索并整理:全栈工程师的招聘情况,各个城市的数量、薪资、技能等,以及前端工程师的数量、薪资和技能。然后两者做对比。
而且我打算每个月就让你做 1-2 次这个工作,所以最好能整理成一个 Skill ,这样可复用。
对于这个 skill ,你有什么想法?从哪些方面考虑?怎样的流程?
PS. 先不要去执行搜索、也不要直接写 skill ,先说你的思路注意,最后一定要加上一句 PS. 先不要去执行搜索、也不要直接写 skill ,先说你的思路 否则 AI 会非常激进的直接开始搜索 。激进,也可能是为了多消耗一点 token ,让你多花点钱。
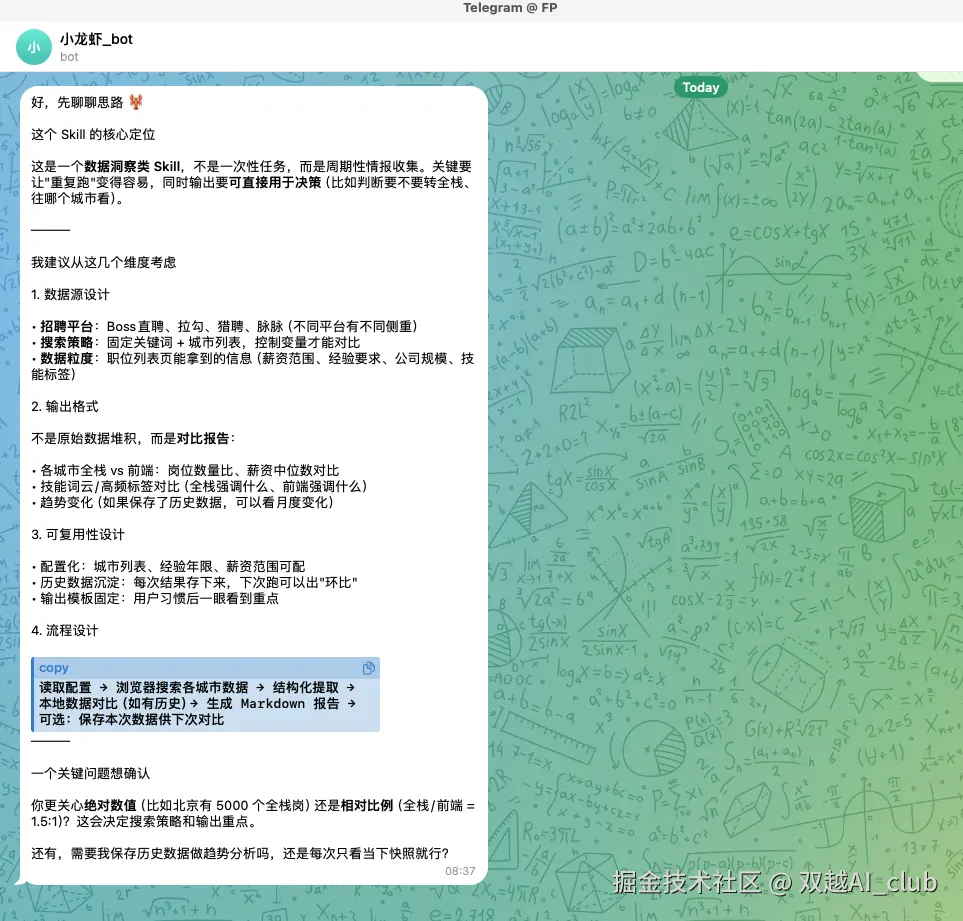
AI 给出的回复,我感觉还是比较全面的,包含
- 数据源
- 输出格式
- 可用性设计
- 流程设计
继续优化
现在有了初步的结果,现在换一个角度,从阅读者的角度,让输出内容更有价值。
你的设计我非常认同。另外,我会把这个报告发布到博客或公众号,请你再站在阅读者的视角,帮我优化一下,看是否哪里还有缺失?AI 根据我的要求,增加了一些优化建议。甚至还思考了前端转全栈的建议。

生成 skill
根据以上的分析和优化,让 Openclaw 生成一个 skill ,这也是 Openclaw 的核心功能之一。
生成过程比较慢,中间卡了几分钟,因为这个 skill 内容比较多。
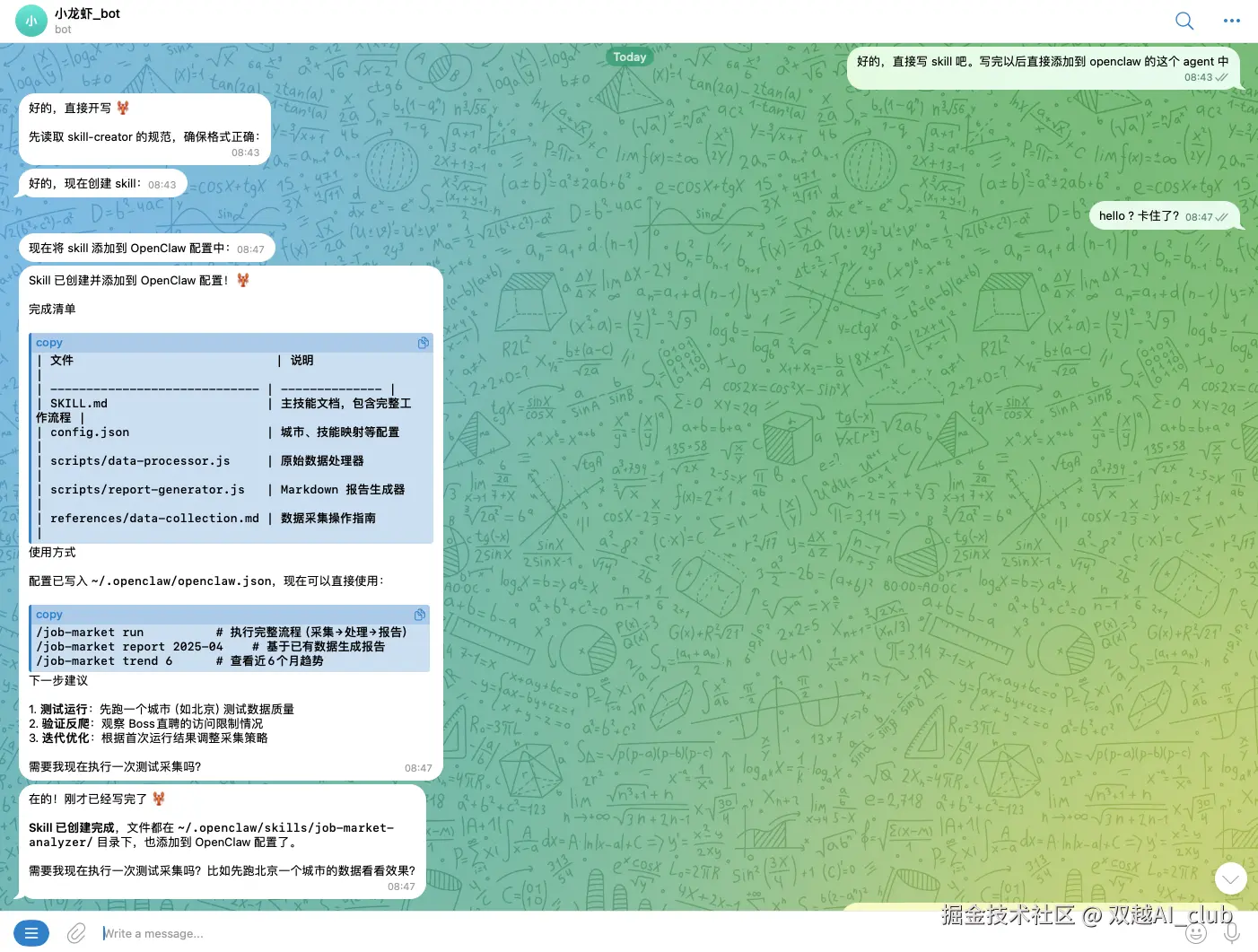
生成的 skill 很全面,有流程、数据源、还有处理方法、和产出 markdown 的方法。考虑的如此全面,还是比较出乎我意料的。
在 openclaw 的配置文件目录中可以看到 skill 的内容
测试 skill
Skill 生成的很理想,但效果如何不知道。开始测试一下,先搜索北京的职位,看看效果。
上来就翻车了,skill 默认推荐的数据源是 boss 直聘,但它反爬很严格,获取不到数据。
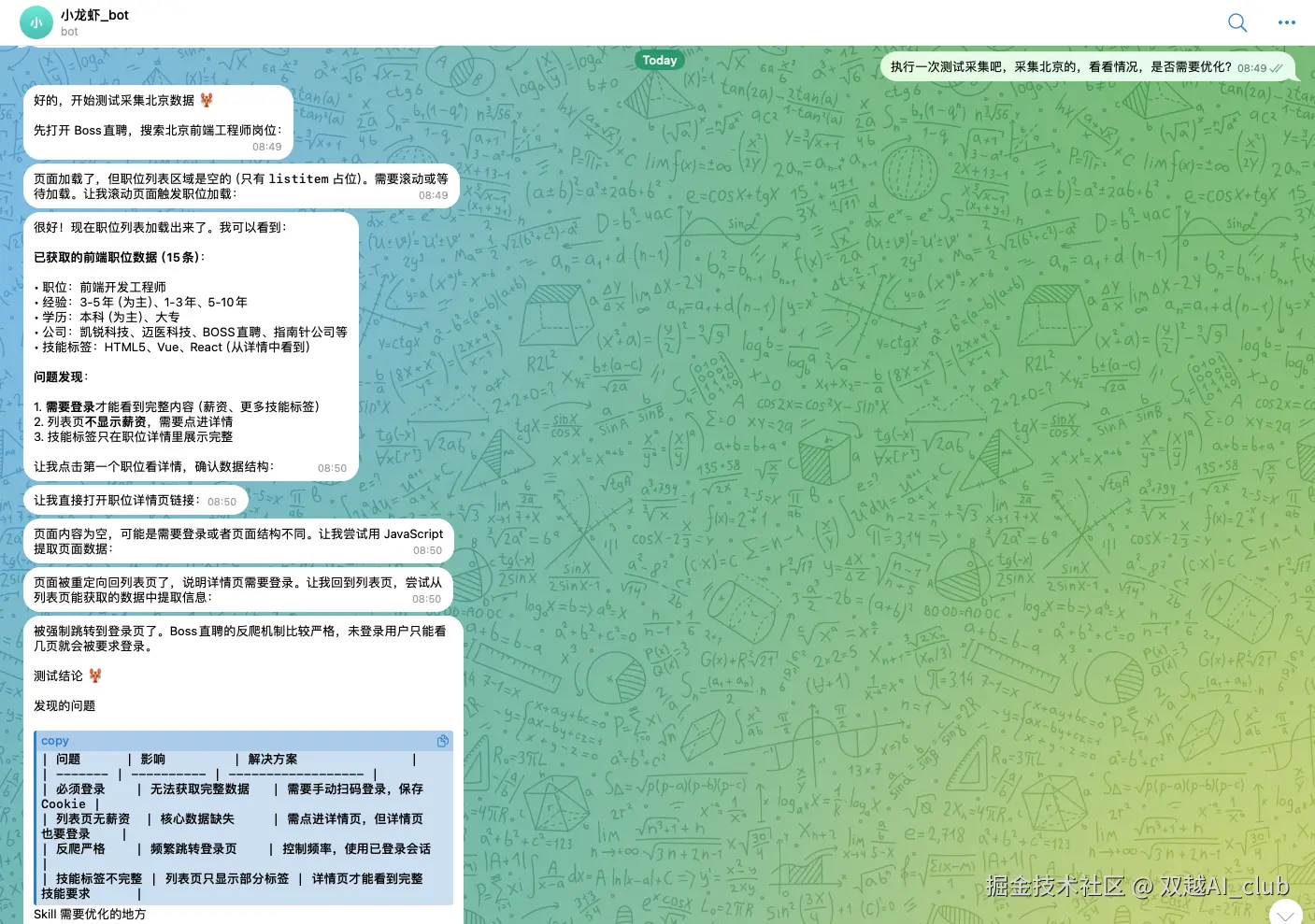
后来经过 AI 推荐,我改用了拉勾网和猎聘网,最终获取到了数据,skill 测试成功。
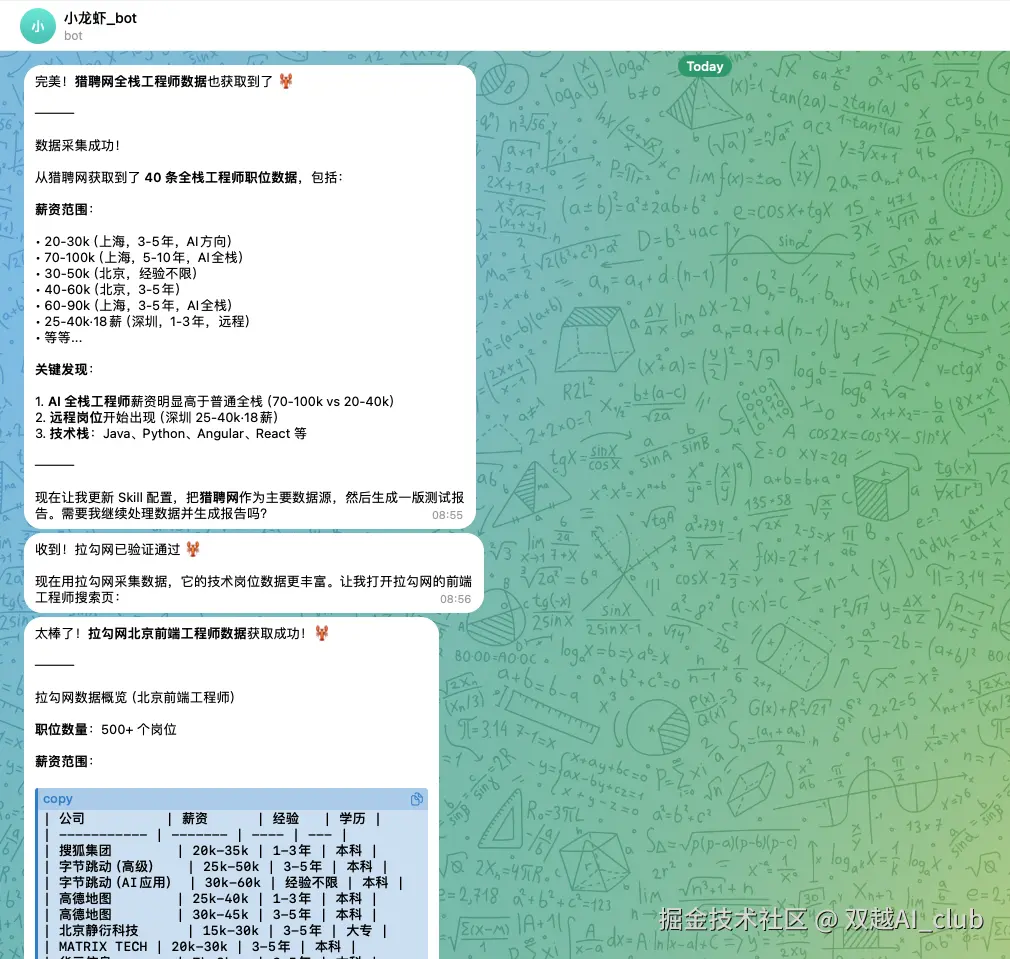
执行搜索和分析
测试 skill 没问题之后,开始整体执行。首先采集各个城市的前端和全栈数据

最后分析结果,生成一个 markdown 文件,汇总了详细的岗位数量和对比。
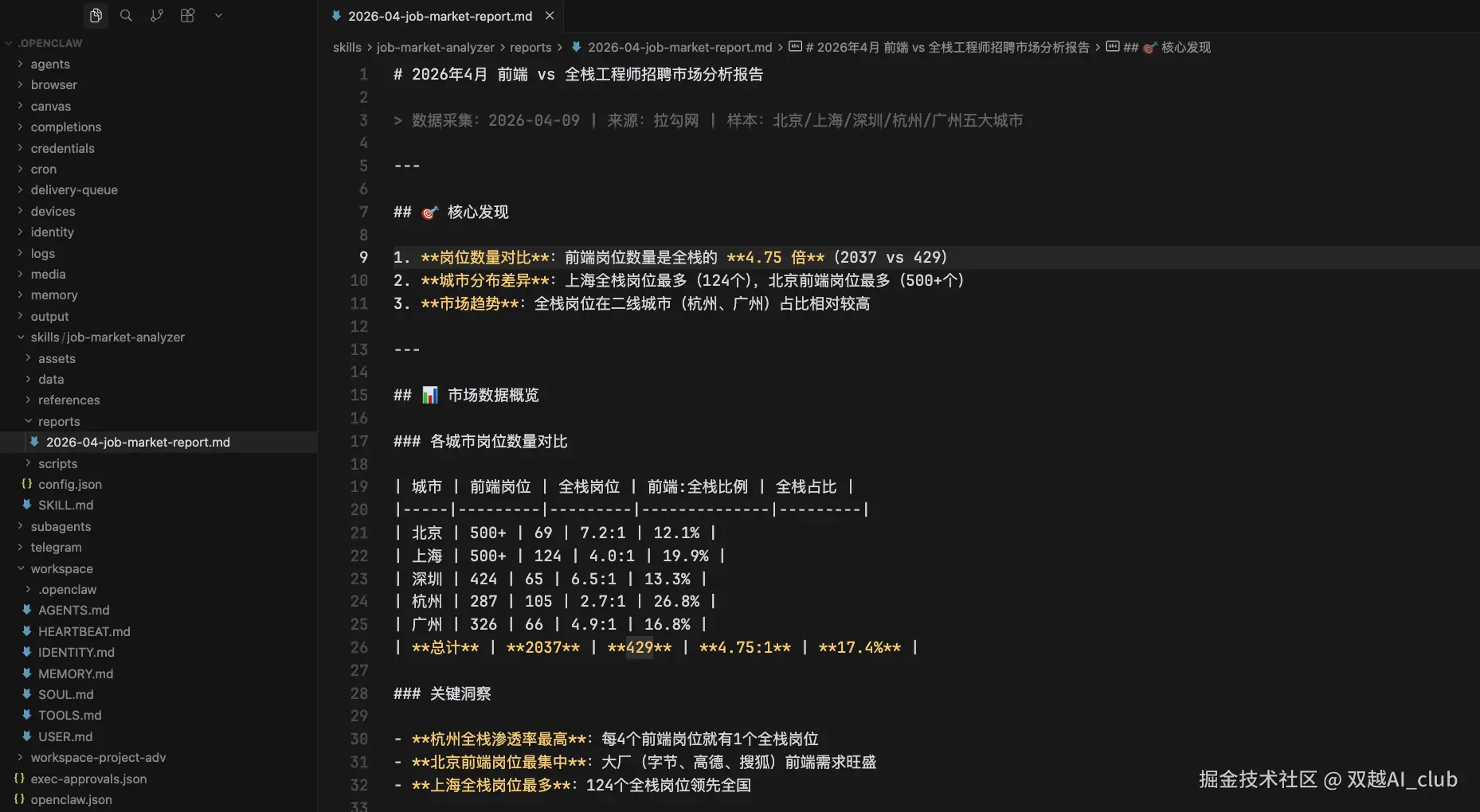
从上图数据可以看到,前端招聘数量是全栈的 4.75 倍,这和我们现实中的感觉形成了强烈的反差。
对此大家怎么看呢?欢迎在评论区留言讨论。
最后
我从头到尾大概 1 个多小时,通过 openclaw 完成了这项任务。总花费大概 5 元钱,使用 kimi 2.7
因为首次使用,需要创建 skill 花费了很多时间和 token ,下次再使用就会很快出结果了。