标题:DAGE: Dual-Stream Architecture for Efficient and Fine-Grained Geometry Estimation
作者:Tuan Duc Ngo, Jiahui Huang, Seoung Wug Oh, Kevin Blackburn-Matzen, Evangelos Kalogerakis, Chuang Gan, Joon-Young Lee
机构:UMass Amherst 2Adobe Research 3TU Crete
原文链接:https://arxiv.org/abs/2603.03744
代码链接:https://ngoductuanlhp.github.io/dage-site/
导读
从未经校准的多视图/视频输入中精确估计出与视图一致的几何结构和相机姿态仍然具有挑战性------尤其是在高空间分辨率和长序列情况下。我们提出了DAGE,这是一种双流Transformer模型,其创新之处在于能够将全局一致性与细节信息分离处理。低分辨率流对大幅降采样的帧进行处理,通过交替使用帧级和全局注意力机制来构建与视图一致的表示,并高效估计相机参数;而高分辨率流则对原始图像进行逐帧处理,以保留清晰的边界和小结构。一个轻量级的适配器通过交叉注意力将这两条流融合在一起,从而在不干扰预训练的单帧处理路径的情况下引入全局上下文信息。该设计能够独立调节分辨率和片段长度,支持最高2K的输入格式,并保持合理的推理成本。DAGE能够生成清晰的深度/点云图、强大的跨视图一致性以及精确的姿态信息,为视频几何结构和多视图重建领域带来了新的最佳成果。
效果展示
DAGE能够生成高分辨率、精细粒度、度量级和跨视角一致的3D几何模型,同时还能根据视觉输入获取准确的相机姿态。其运行速度显著快于先前的模型,并可处理长序列数据(最多可达1000帧)。
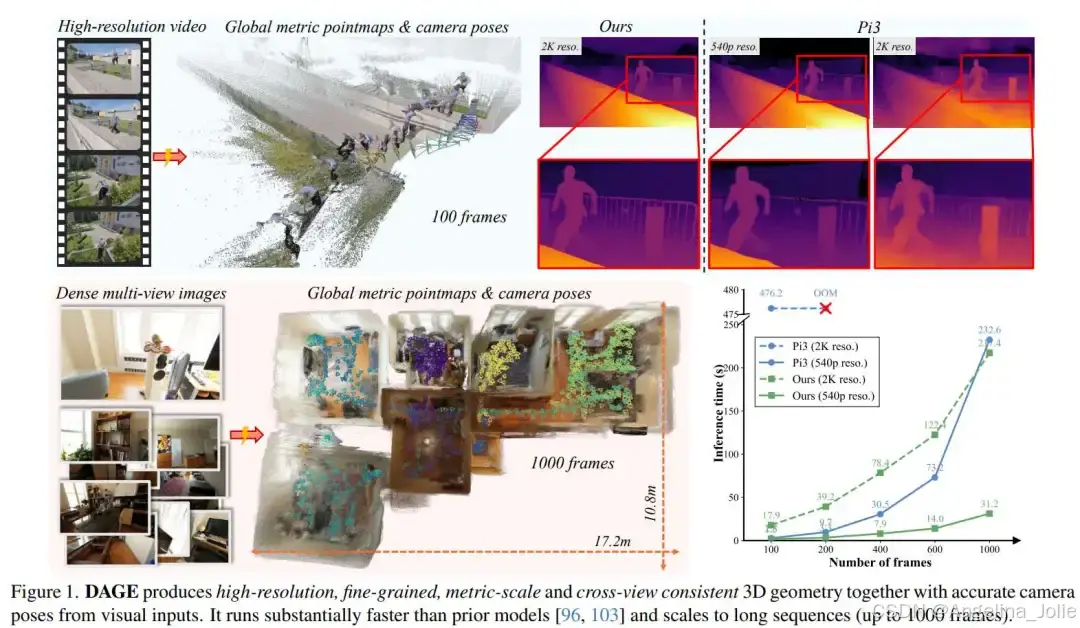
引言
从多视角图像估计3D几何和相机位姿是计算机视觉中的一个基本问题。我们针对的是具有挑战性的场景:未标定的、高分辨率输入,可能包含数千帧。这项任务尤其困难,因为模型必须同时(i)强制跨视图的全局一致性,(ii)在高分辨率下保留精细细节,以及(iii)在长序列中保持运行时和内存的可行性。
一方面,前馈视觉几何网络在全局一致的多视图几何估计方面取得了显著进展,在包括视频深度估计、3D重建和相机位姿预测在内的各种基准测试上树立了新的最先进结果。然而,它们通常沉重的网络架构限制了训练和推理只能在适中的图像分辨率(例如长边≤518像素)和少量输入视图下进行,导致细薄结构模糊和物体边界不清晰。一些工作采用了训练后加速策略来降低计算成本并在推理期间支持更多视图,但它们并未解决高频细节的丢失或边缘和小物体附近表面过度平滑的倾向。
另一方面,单视图几何估计器能够灵活地在高分辨率下运行,并从单张图像生成清晰、细节丰富的深度/点图,但它们设计上缺乏时间一致性和多视图一致性。试图调整这些模型以处理视频的工作引入了繁重的流程,并且通常无法恢复准确的相机位姿。因此,它们无法直接从前馈预测中组装出全局一致的3D场景几何。
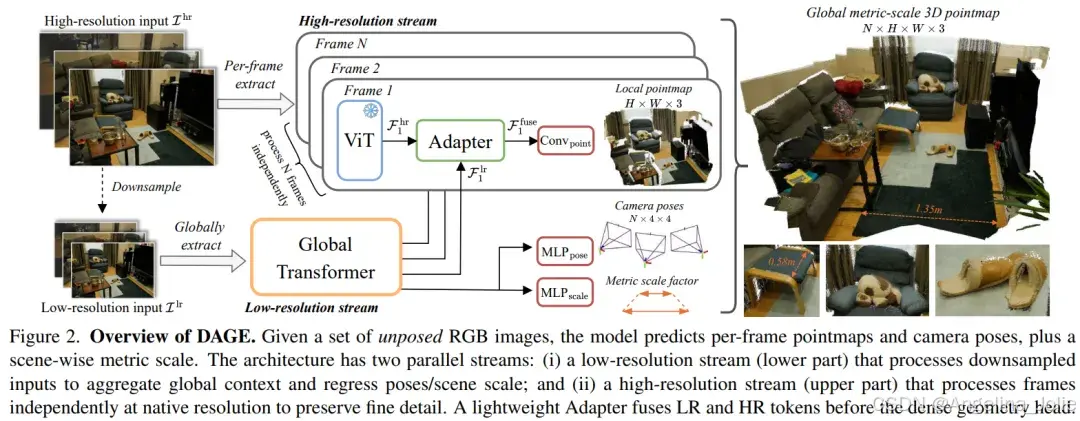
基于这一观察,我们提出了DAGE,一种满足上述标准的、用于高效且精细几何估计的双流架构。它包含两个并行流和一个轻量级融合适配器。低分辨率流专注于提取全局一致的特征并预测相机位姿。它由一个ViT主干网络和一个带有交替帧-全局注意力的全局Transformer组成,后者以较低的空间分辨率处理整个序列。尽管全局Transformer计算密集,但在低分辨率下运行使其保持可行性,同时保留全局上下文。高分辨率流旨在捕捉高频细节和精细特征。它采用ViT,以原始分辨率独立处理每张图像。最后,我们提出的轻量级适配器在密集头之前同步并融合低分辨率和高分辨率标记,生成既全局一致又细节丰富的几何。
这种解耦设计带来了两个关键优势。首先,它实现了全局一致性和可行性。通过将计算量大的全局注意力限制在低分辨率流中,我们缓解了全局Transformer的二次缩放瓶颈。这显著减少了运行时,在540p和2K分辨率下分别减少了2倍和28倍,使我们的模型能够处理数千帧。其次,它保留了高保真细节。高分辨率流逐帧操作,使其能够扩展到任何分辨率(例如,高达2K),并利用最先进的单图像模型的先验知识,以获得清晰的细节和强大的现实世界泛化能力。与将图像分辨率与序列长度耦合的标准流程相比,DAGE将两者解耦,从而能够在可行的运行时间内独立控制空间细节和多视图一致性。
主要贡献
我们通过大量实验验证了我们的方法和设计选择。DAGE在视频几何和深度清晰度基准上取得了最先进的性能,在3D重建和相机位姿估计方面也具有竞争力,同时提供了更高的吞吐量和更低的GPU内存占用。总之,我们的技术贡献有两方面:
-
一种双流Transformer,它将逐帧高分辨率细节路径与多视图低分辨率全局注意力路径相结合。
-
一种轻量级适配器,融合两个流以生成清晰且全局一致的几何。
方法
给定一组无位姿的RGB图像,模型预测每帧的点图和相机位姿,以及场景度量尺度。该架构有两个并行流:(i)低分辨率流(下部)处理下采样输入以聚合全局上下文并回归位姿/场景尺度;(ii)高分辨率流(上部)以原始分辨率独立处理帧以保留精细细节。一个轻量级适配器在密集几何头之前融合低分辨率和高分辨率标记。
实验结果
遵循先前工作,我们在稀疏和密集设置下,在7-Scenes和NRGBD数据集上评估重建的多视点图。首先通过Umeyama Sim(3)将预测与真值对齐,然后使用ICP细化。我们在表3中报告精度Acc.↓、完整度Comp.↓和法向一致性NC↑。比较对象包括最近的前馈视觉几何方法。我们还通过刚性变换SE(3)对齐来评估度量尺度重建,并与度量点图方法进行比较。在稀疏和密集设置中,DAGE达到了与最先进方法相当的性能,同时恢复了度量精确的几何。图5显示我们的模型生成了全局一致的点图,同时保留了精细细节。
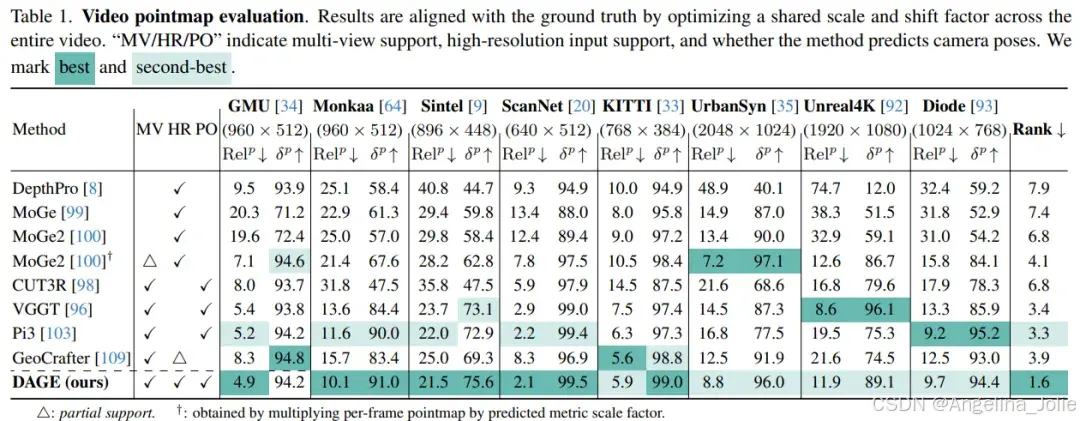
我们在合成的Sintel数据集和两个真实世界数据集TUM-Dynamics和ScanNet上进行评估。我们报告绝对轨迹误差(ATE)以及平移/旋转的相对位姿误差(RPET/RPER)。预测的相机轨迹通过Sim(3)对齐与真值配准。我们在表4中总结了性能。值得注意的是,我们在低分辨率流中使用252像素(长边)来高效估计位姿。竞争方法通常需要518像素才能获得准确的预测。尽管使用较低分辨率输入,DAGE在高分辨率设置下与它们的性能相当,并且在相同的低分辨率设置下评估时表现更优。


总结 & 未来工作
我们介绍了DAGE,一种双流视觉几何Transformer。低分辨率流高效估计相机并强制执行跨视图一致性,而高分辨率流保留清晰细节;轻量级适配器融合它们。这将分辨率与序列长度解耦,以实用成本支持2K输入和长视频。实验证明,DAGE生成更清晰的点图,并优于先前的视频几何方法。它在运行速度显著更快的同时,匹配了最先进模型的3D重建和位姿精度。局限性:在极低重叠或快速非刚性运动下性能可能下降;高分辨率流在极高分辨率下内存密集;当前方法无法恢复动态运动。