目录
[DeepSeek V3](#DeepSeek V3)
[Llama 4](#Llama 4)
[1、全参数微调(Full Fine-tuning)](#1、全参数微调(Full Fine-tuning))
[2、参数高效微调(Parameter-Efficient Fine-tuning, PEFT)](#2、参数高效微调(Parameter-Efficient Fine-tuning, PEFT))
[5、LoRA(Low-Rank Adaptation)](#5、LoRA(Low-Rank Adaptation))
[6、QloRA(Quantized Low-Rank Adaptation)](#6、QloRA(Quantized Low-Rank Adaptation))
[ZeRO(Zero Redundancy Optimizer)](#ZeRO(Zero Redundancy Optimizer))
主流开源LLM架构赏析
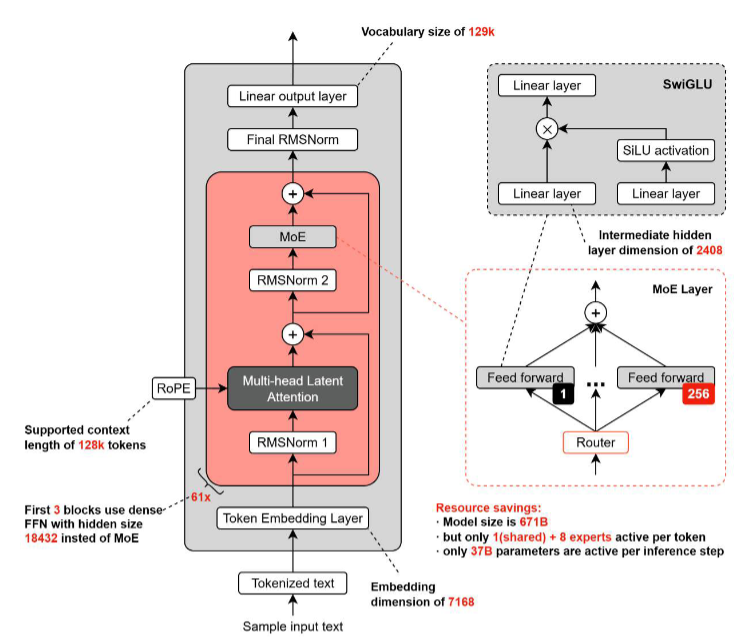
DeepSeek V3
采用稀疏Mixture-of-Experts(MoE)架构,总参数规模约671B,推理时激活约37B,并且有共享
专家。
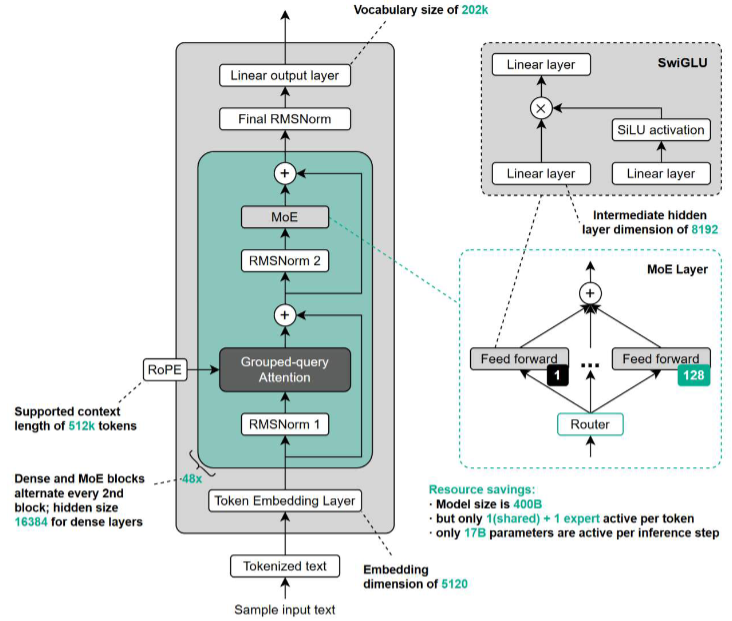
Llama 4
Llama 4 于 2025/04/05 发布,包含 Scout(109B 总参数,1.7B 激活)和 Maverick(400B 总参
数,17B 激活)两个 MoE 版本,兼顾容量与效率。
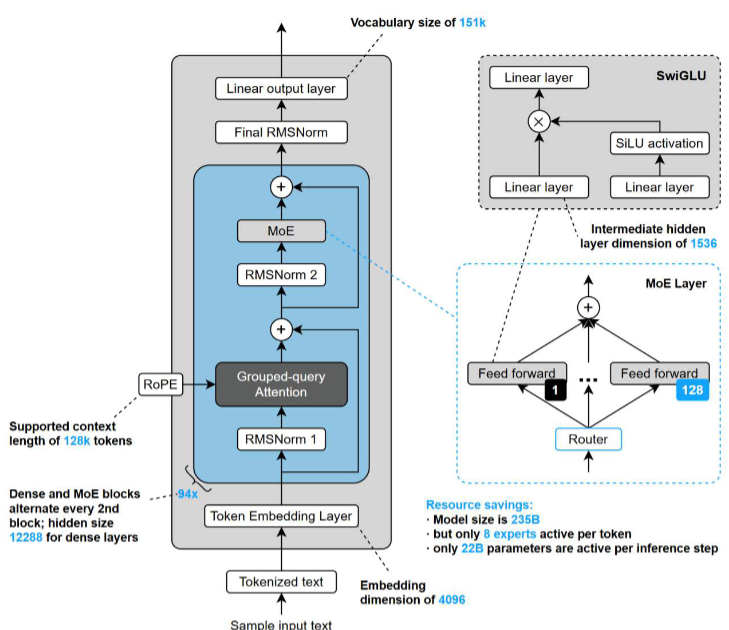
Qwen3
Qwen 3 于 2025/04/29 发布,开源 MoE 与 Dense 两类模型:MoE 包括 235B(激活 22B)和
30B(激活 3B);Dense 提供 32B 到 0.6B 共六个版本,覆盖多种部署需求。
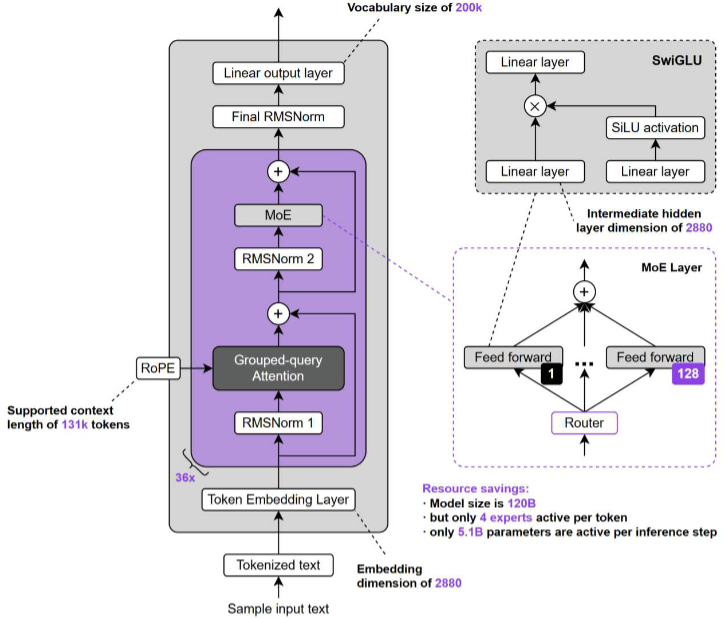
GPT-OSS
GPT-OSS 是 OpenAI 于 2025/08/05 发布的开源 MoE 模型系列,包含 120b(117B 总参数,5.1B
激活)和 20b(21B 总参数,3.6B 激活)两个版本。
LLM适配方法
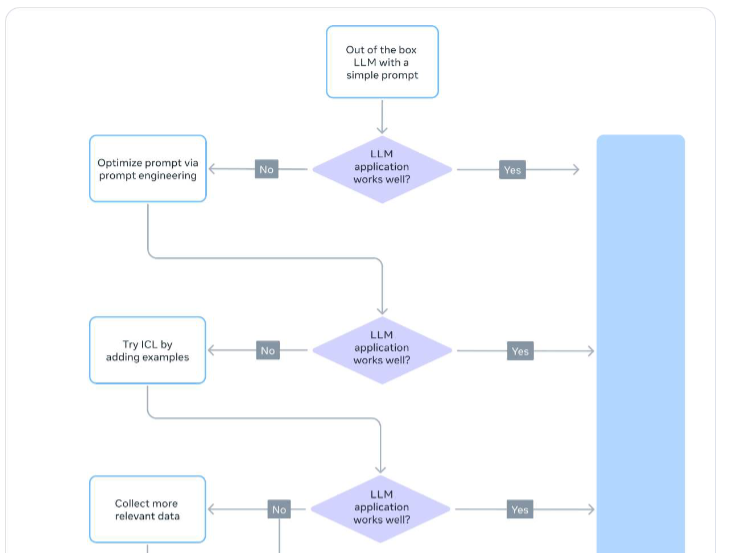
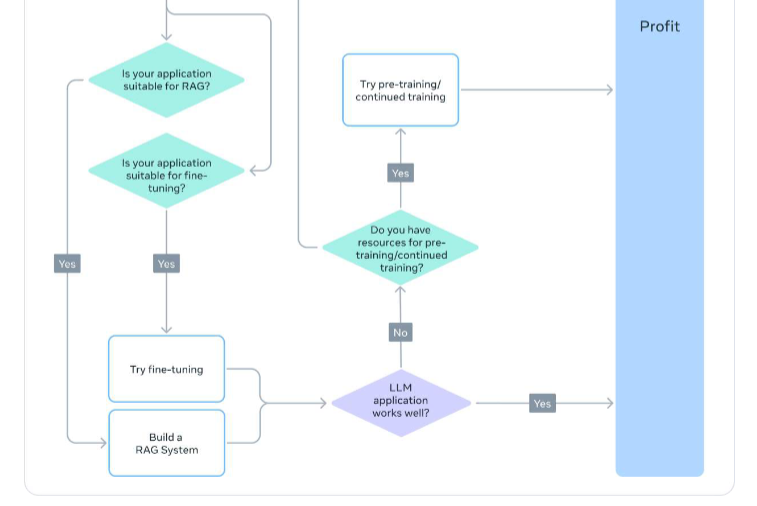
当前大模型在通用场景表现优异,但在特定行业或专业任务中需针对性调整。常见适配方法包括提
示词工程(Prompt Engineering)、微调(Fine-tuning)、检索增强生成(RAG)和继续预训练
(Continued Pre-training),各有适用场景。
LLM微调
本章所提到的都是监督微调SFT

1、模型使用说明
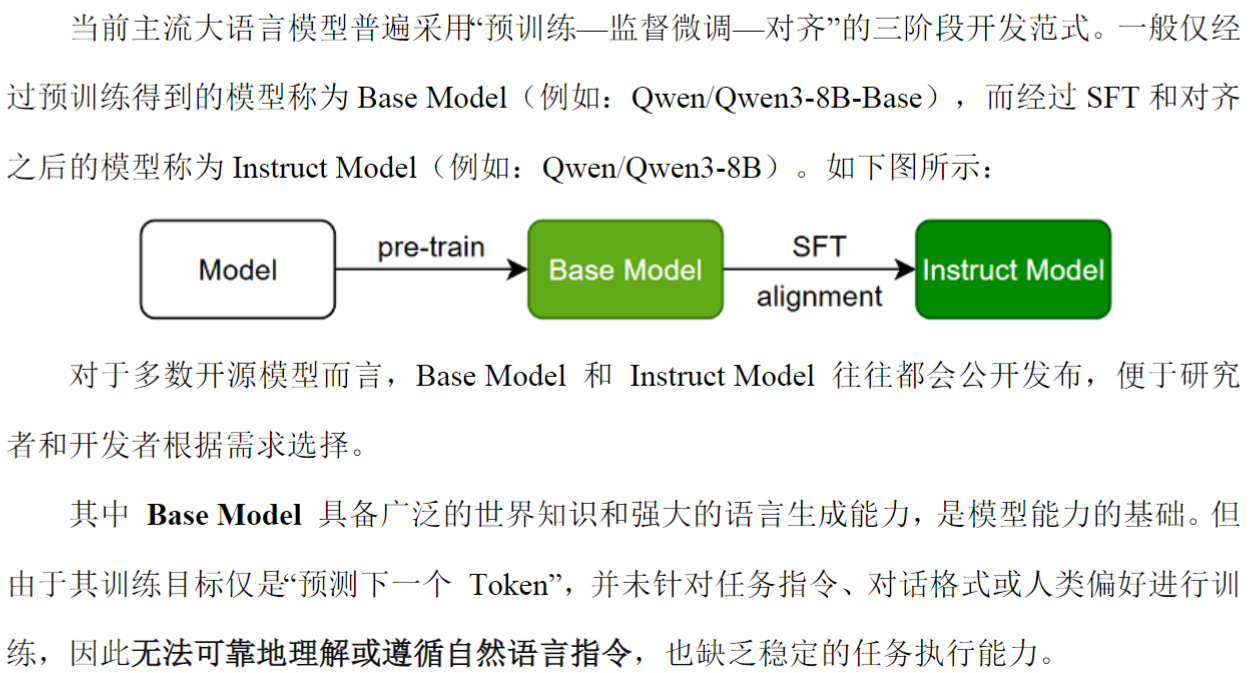

优先选用Instruct Model
注意事项



2、数据来源
公有

私有

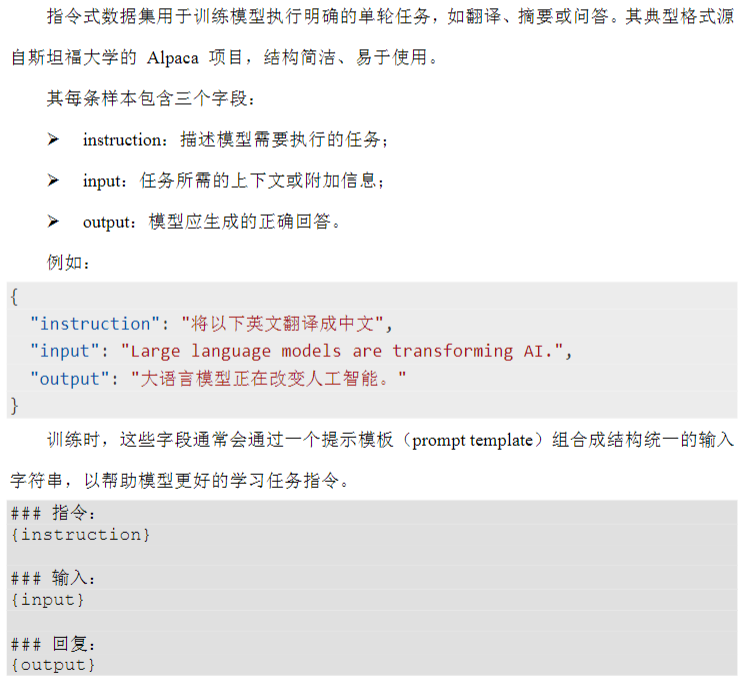
3、数据格式
指令式
对话式


2)OpenAI格式


4、微调方法
1、全参数微调(Full Fine-tuning)
全参数微调更新模型所有参数,性能最优,但对显存、算力和训练时间要求极高,需依赖分布式训
练。适用于资源充足、对性能要求极高的场景,常作为参数高效微调无法满足需求时的高成本备选
方案。
2、参数高效微调(Parameter-Efficient Fine-tuning, PEFT)
参数高效微调(PEFT)仅更新少量参数或引入可训练模块,在降低资源消耗的同时实现与全参微
调相当的性能。随着模型规模扩大,全参微调成本激增,推动了 PEFT 的快速发展,形成了
LoRA、Adapter 等多条技术路线。
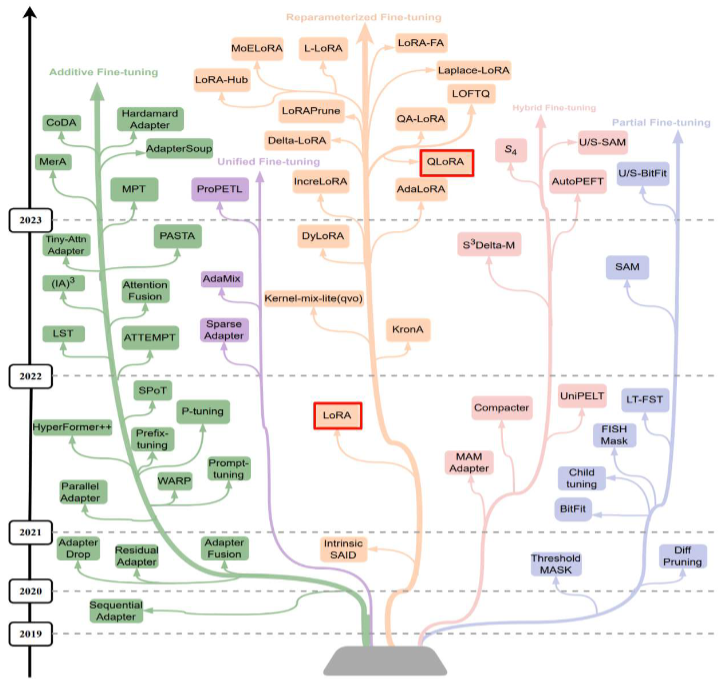
LoRA 因结构简洁、高效稳定,已成为大模型 SFT 的主流方法;其量化版本 QLoRA 进一步降低硬
件门槛。相比之下,其他 PEFT 方法因效率、稳定性或通用性不足,已逐渐边缘化。
5、LoRA(Low-Rank Adaptation)
概念



插入位置

工程实现


6、QloRA(Quantized Low-Rank Adaptation)
QLoRA 是在 LoRA 基础上引入 4-bit 量化 的方法,可在单张消费级 GPU(如 RTX 3090/4090)
上高效微调数十亿参数的大语言模型,且性能几乎不损失。

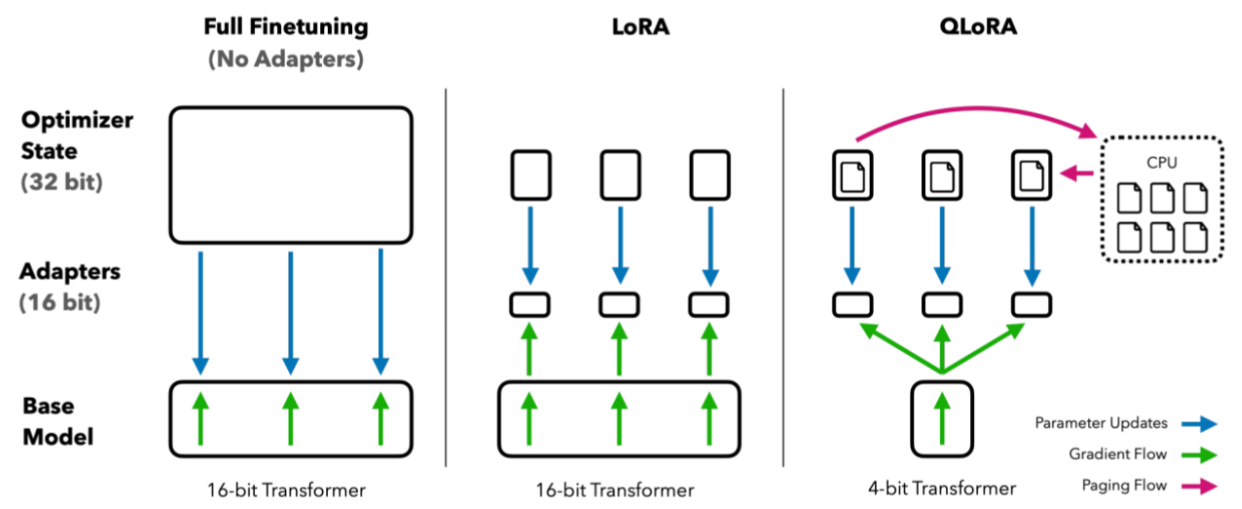
QLoRA 包含三个关键组件:
传统4-bit量化quantities切出来的点是均匀分布,不符合正态分布,如下图:

-
NF4 量化:针对正态分布的权重,在数值密集的 0 附近分配更多量化格点,减少误差。
-
双重量化 :对量化时所需的缩放因子absmax再做一次量化,节省存储开销。
-
分页优化器:将优化器状态分块管理,按需载入显存,用完即释放,降低显存压力。
7、分布式训练
下面三个可以统称为模型并行

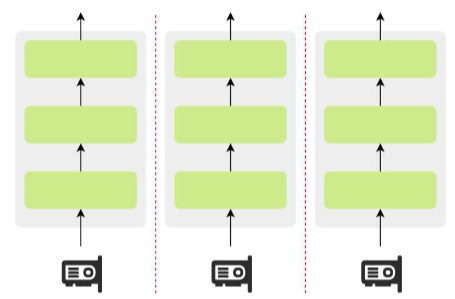
数据并行
每张 GPU 存放完整模型副本,处理不同数据子集。
流程:各 GPU 独立计算梯度 → 跨 GPU 梯度汇总(AllReduce)并取平均 → 各 GPU 用相同全局梯度更新参数。

瓶颈:梯度同步通信开销大,尤其是大模型场景。
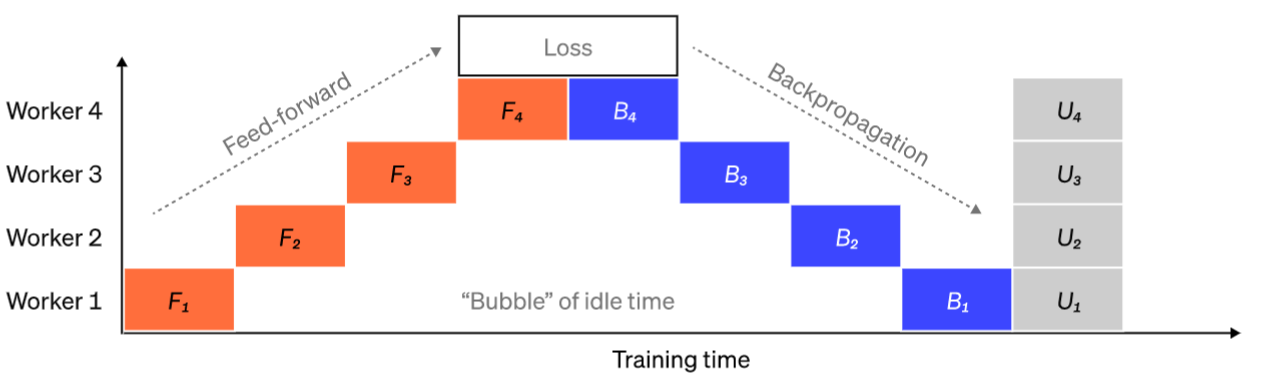
流水线并行
将模型按层纵向切分到多个设备,每个设备负责一个分段,以降低单卡显存占用。
流程:前向逐设备传递激活值,反向逐设备回传梯度。
问题:设备间相互等待产生"气泡",造成计算闲置。
优化:引入微批次(Micro-batches)与流水线调度,让设备在处理完一个微批次后立即切换至下一个,减少空闲,提升利用率。

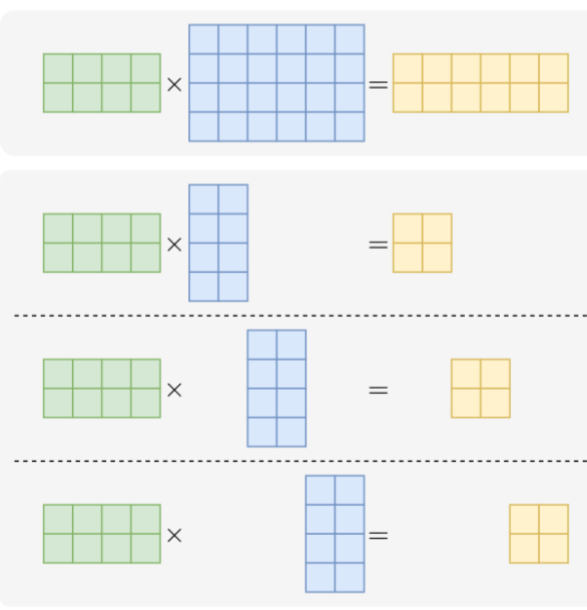
张量并行
将单层内部的张量计算拆分到多个设备上,每个设备持有部分权重和中间结果,以突破单卡显存与
算力限制。
专家并行
将 MoE 模型中的不同专家分配到不同设备上,每个设备仅负责部分专家的存储与计算。由于专家
间彼此独立无依赖,天然适合并行化。
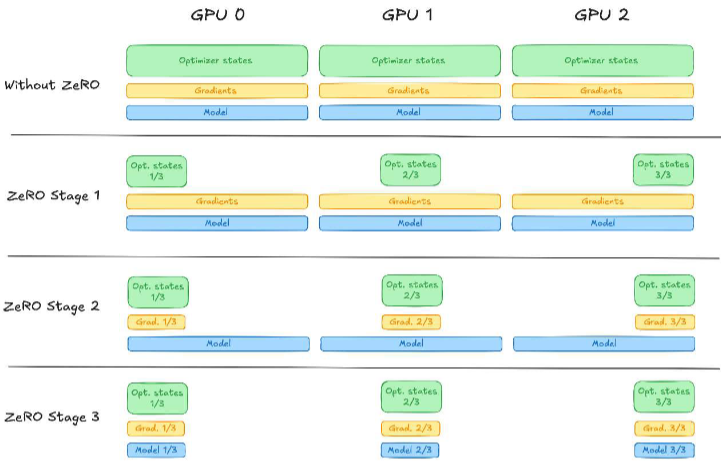
ZeRO(Zero Redundancy Optimizer)
对数据并行的增强,通过分片存储、按需加载模型状态(参数、梯度、优化器状态),消除跨设备
冗余,显著降低单卡显存占用,使超大规模模型训练成为可能。


8、训练设备选择
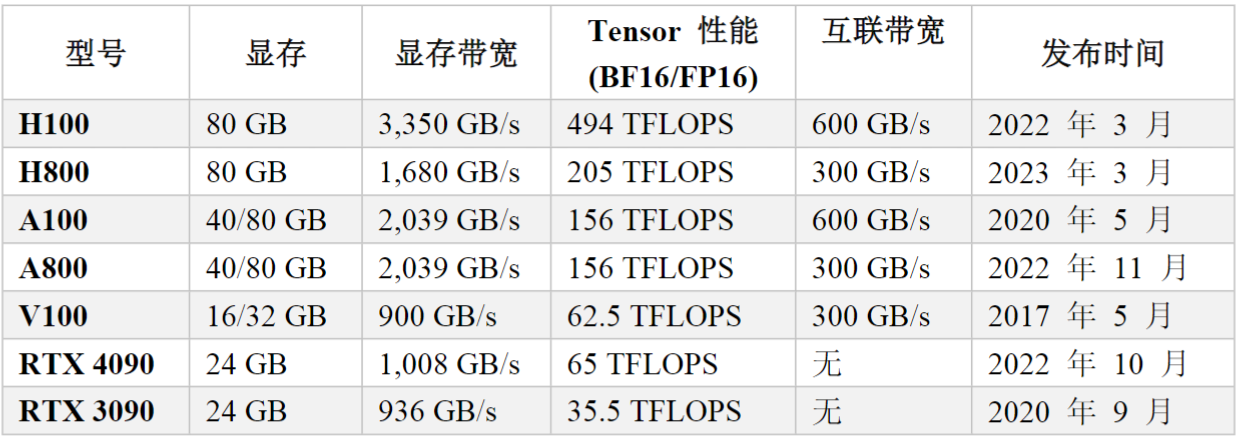
常用GPU型号
微调显存估算

可以借助显存估算工具:https://apxml.com/zh/tools/vram-calculator
9、微调工具
1、分布式训练
-
DeepSpeed:微软的分布式训练框架,集成多种并行策略(数据、流水线、张量、专家并行)及 ZeRO 优化,支持大规模模型训练。
-
Accelerate:Hugging Face 的分布式训练接口,统一封装多设备训练流程,可切换不同后端(如 FSDP、DeepSpeed),与 Transformers 生态无缝兼容,简化分布式训练实现。
2、参数高效微调
-
PEFT:Hugging Face 的参数高效微调框架,冻结预训练模型主体,仅训练少量额外参数。集成 LoRA、QLoRA 等方法,统一接口,降低显存和资源需求。
-
unsloth:针对 LoRA/QLoRA 的高效微调库,通过内核优化和显存管理进一步降低资源占用,支持 Llama、Qwen、Mistral 等模型,适合中低显存设备。可作为 PEFT 的补充。
3、强化学习与微调工具
-
TRL:Hugging Face 的模型训练库,支持 SFT 及 DPO、PPO 等对齐方法,与 Transformers、Accelerate、PEFT 无缝集成,适用于微调与轻量对齐场景。
-
LLaMA Factory:大模型微调一体化框架,提供图形化界面与标准脚本,支持全参微调、LoRA/QLoRA,涵盖数据处理、训练监控、模型导出等全流程,适配主流开源模型。