文章目录
-
- 前言:为什么我会学这个问题
- 一、问题背景
- 二、核心概念
-
- [Checkpoint 是什么?](#Checkpoint 是什么?)
- [LangGraph Checkpoint 机制](#LangGraph Checkpoint 机制)
- [Checkpoint 的存储方式](#Checkpoint 的存储方式)
- [三、错误理解 / 常见误区](#三、错误理解 / 常见误区)
- 四、正确实现思路
-
- [步骤1:设计可恢复的 State](#步骤1:设计可恢复的 State)
- [步骤2:每个 Node 检查进度再执行](#步骤2:每个 Node 检查进度再执行)
- [步骤3:配置 Checkpoint 并执行](#步骤3:配置 Checkpoint 并执行)
- 五、代码示例
- [六、运行结果 / 流程图](#六、运行结果 / 流程图)
- 七、项目中怎么用
- [八、总结 + 下篇预告](#八、总结 + 下篇预告)
前言:为什么我会学这个问题
上篇我们讲了 LangGraph 里 State、Node、Edge 怎么配合完成多步骤任务。主包在学习Langgraph的时候准备构建一个客服Agent,跑完一个客服流程需要 5-6 步,但如果执行到一半服务器崩了呢?或者用户突然关闭页面?所有 State 都没了,流程只能从头再来。
这就很蛋疼了------用户问了个复杂问题,Agent 查了半天文档,刚要返回结果时网络断了。用户重新打开页面,发现一切要从头开始,肯定骂街。
Checkpoint 就是来解决这个问题的。它是 Agent 执行过程的"存档点"。
前文关联:本文接续《LangGraph 中 State、Node、Edge 是怎么协作的?》,在前文理解 State 流转的基础上,探讨如何让 State 持久化、不怕中断。
一、问题背景
假设一个复杂的数据分析 Agent,执行流程是这样的:
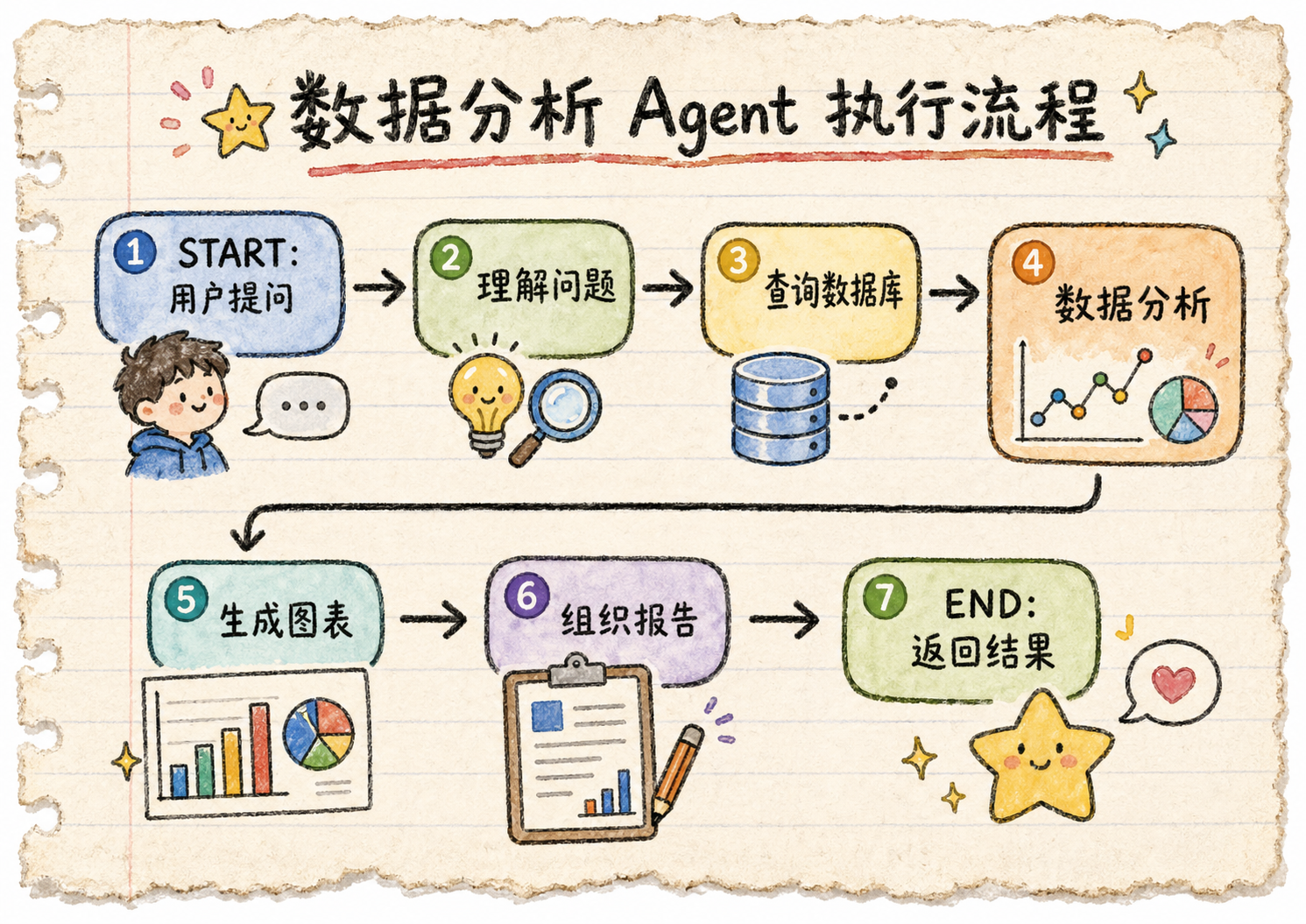
跑了 4 步,刚到"生成图表"这一步,突然:
- 服务器重启了
- 用户关掉了浏览器
- 网络断了
- 进程被 OOM Kill 了
没有 Checkpoint = 从头来过。用户得重新等 4 步重新跑一遍,浪费时间和资源。
二、核心概念
Checkpoint 是什么?
Checkpoint = State 的快照。在某个 Node 执行完成后,把当前的 State 完整保存下来。
就像游戏存档:打到 BOSS 血剩一半,保存一下。哪天游戏崩了,从存档点恢复,不用从头打。
python
# 伪代码:Checkpoint 本质就是保存 State
checkpoint = {
"step": 4,
"state": {
"user_question": "分析Q2销售额",
"retrieved_data": {...},
"analysis_result": {...},
"chart_data": {...}, # 已生成,还没用来生成报告
"response": ""
},
"node_history": ["understand", "query", "analyze", "generate_chart"]
}LangGraph Checkpoint 机制
LangGraph 的 Checkpoint 在每个 Node 执行完成后自动保存。恢复时从最近的 Checkpoint 开始,不用重新跑。
python
from langgraph.checkpoint import MemorySaver
from langgraph.graph import StateGraph
# 创建带 Checkpoint 的 Graph
checkpointer = MemorySaver()
graph = StateGraph(DataAnalysisState)
# ... 添加 Node 和 Edge ...
app = graph.compile(checkpointer=checkpointer)
# 正常执行(每个 Node 完成后自动保存 Checkpoint)
config = {"configurable": {"thread_id": "user-123-session-1"}}
result = app.invoke(initial_state, config)
# 中断后恢复(从最近 Checkpoint 继续)
restored_result = app.invoke(None, config) # 传 None 表示从存档点恢复Checkpoint 的存储方式
| 存储方式 | 适用场景 | 特点 |
|---|---|---|
| MemorySaver | 开发测试 | 内存存储,重启丢失 |
| SqliteSaver | 单机部署 | SQLite 文件持久化 |
| PostgresSaver | 生产环境 | PostgreSQL,支持多实例 |
生产环境推荐 PostgresSaver,多个 Agent 实例可以共享同一个 Checkpoint 存储。
三、错误理解 / 常见误区
误区1:Checkpoint 会拖慢执行速度
错。Checkpoint 保存是异步的,不阻塞 Node 执行。而且只有 State 变化时才保存,不是每次都全量写入。
误区2:有了 Checkpoint 就不用担心数据丢失
不完全对。Checkpoint 保存的是 Node 执行完成后的 State,如果 Node 执行到一半崩溃,那一步的修改会丢失。所以要保证 Node 的原子性------每个 Node 要么完全成功,要么完全失败,不要有中间状态。
误区3:Checkpoint 可以无限恢复
不对。Checkpoint 存储会消耗资源,生产环境通常只保留最近 N 个版本。或者设置过期时间,比如只保留 24 小时内的 Checkpoint。
误区4:所有 State 都需要 Checkpoint
错。只保存关键数据就行,比如中间结果、用户输入、配置参数。不需要保存的是:临时变量、缓存数据、日志等。
四、正确实现思路
步骤1:设计可恢复的 State
State 要设计成可以"从哪里继续"的样子:
python
class DataAnalysisState(TypedDict):
# 用户原始问题(不变)
user_question: str
# 流程进度(关键!用于判断从哪继续)
current_step: str # understand / query / analyze / chart / report
completed_steps: list[str]
# 各步骤的结果(保存中间产物)
understanding: str
query_result: str
analysis_result: str
chart_data: dict
response: str步骤2:每个 Node 检查进度再执行
python
def analyze_data(state: DataAnalysisState) -> DataAnalysisState:
# 如果已经分析过了,直接返回(防止重跑)
if "analyze" in state["completed_steps"]:
print(" [analyze] 已完成,跳过")
return state
# 正常执行分析逻辑
print(" [analyze] 执行数据分析...")
result = do_analysis(state["query_result"])
return {
"analysis_result": result,
"current_step": "analyze",
"completed_steps": state["completed_steps"] + ["analyze"]
}步骤3:配置 Checkpoint 并执行
python
from langgraph.checkpoint import PostgresSaver
import psycopg2
# 生产环境:PostgreSQL 存储
conn = psycopg2.connect(os.getenv("DATABASE_URL"))
checkpointer = PostgresSaver(conn)
# 开发环境:内存存储
# checkpointer = MemorySaver()
app = graph.compile(checkpointer=checkpointer)
# 第一次执行
config = {"configurable": {"thread_id": "user-123"}}
result = app.invoke(initial_state, config)
# 模拟中断后恢复
# (同一个 thread_id 会自动找到最近的 Checkpoint)
result = app.invoke(None, config) # None 表示从存档点继续五、代码示例
python
"""
LangGraph Checkpoint 完整示例
演示:执行中断 → 自动从 Checkpoint 恢复
"""
from typing import TypedDict, Literal
from langgraph.graph import StateGraph
from langgraph.checkpoint import MemorySaver
class ShoppingAgentState(TypedDict):
"""购物 Agent 状态"""
user_request: str
current_step: Literal["understand", "search", "compare", "recommend", "done"]
completed_steps: list[str]
products: list[str]
recommendation: str
def understand(state: ShoppingAgentState) -> ShoppingAgentState:
"""理解用户需求"""
print(f" [understand] 理解需求: {state['user_request']}")
return {
"current_step": "understand",
"completed_steps": ["understand"]
}
def search(state: ShoppingAgentState) -> ShoppingAgentState:
"""搜索商品"""
if "search" in state["completed_steps"]:
print(" [search] 已完成,跳过")
return state
print(" [search] 搜索商品中...")
return {
"products": ["商品A", "商品B", "商品C"],
"current_step": "search",
"completed_steps": state["completed_steps"] + ["search"]
}
def compare(state: ShoppingAgentState) -> ShoppingAgentState:
"""对比商品"""
if "compare" in state["completed_steps"]:
print(" [compare] 已完成,跳过")
return state
print(" [compare] 对比商品...")
return {
"current_step": "compare",
"completed_steps": state["completed_steps"] + ["compare"]
}
def recommend(state: ShoppingAgentState) -> ShoppingAgentState:
"""推荐商品"""
if "recommend" in state["completed_steps"]:
print(" [recommend] 已完成,跳过")
return state
best = state["products"][0] if state["products"] else "无"
print(f" [recommend] 推荐: {best}")
return {
"recommendation": f"强烈推荐 {best}!",
"current_step": "recommend",
"completed_steps": state["completed_steps"] + ["recommend"]
}
# 构建图
graph = StateGraph(ShoppingAgentState)
graph.add_node("understand", understand)
graph.add_node("search", search)
graph.add_node("compare", compare)
graph.add node("recommend", recommend) # 注意:不是 recommend()
graph.set_entry_point("understand")
graph.add_edge("understand", "search")
graph.add_edge("search", "compare")
graph.add_edge("compare", "recommend")
graph.set_finish_point("recommend")
# 模拟中断:在 compare 步骤手动抛出异常
class InterruptException(Exception):
pass
def compare_with_interrupt(state: ShoppingAgentState) -> ShoppingAgentState:
if "compare" in state["completed_steps"]:
print(" [compare] 已完成,跳过")
return state
print(" [compare] 对比商品... (模拟中断点)")
# 模拟执行到一半崩了
if len(state["completed_steps"]) < 3: # 只有前3步完成时抛出
raise InterruptException("模拟中断:服务器崩了")
return {
"current_step": "compare",
"completed_steps": state["completed_steps"] + ["compare"]
}
# 用带中断的版本替换
graph.add_node("compare", compare_with_interrupt)
# 编译(启用 Checkpoint)
checkpointer = MemorySaver()
app = graph.compile(checkpointer=checkpointer)
# ========== 第一次执行:跑到 compare 时中断 ==========
print("=" * 50)
print("第一次执行:模拟中断")
print("=" * 50)
config = {"configurable": {"thread_id": "user-456"}}
initial_state: ShoppingAgentState = {
"user_request": "想买一个打游戏快的笔记本电脑",
"current_step": "",
"completed_steps": [],
"products": [],
"recommendation": ""
}
try:
result = app.invoke(initial_state, config)
print(f"最终结果: {result['recommendation']}")
except InterruptException as e:
print(f"中断了: {e}")
print(f"当前完成步骤: {result.get('completed_steps', []) if 'result' in dir() else []}")
print()
# ========== 第二次执行:从 Checkpoint 恢复 ==========
print("=" * 50)
print("第二次执行:从 Checkpoint 恢复")
print("=" * 50)
# 同一个 thread_id,自动从最近的 Checkpoint 恢复
result = app.invoke(None, config) # 传入 None,表示从存档点继续
print(f"最终结果: {result['recommendation']}")六、运行结果 / 流程图
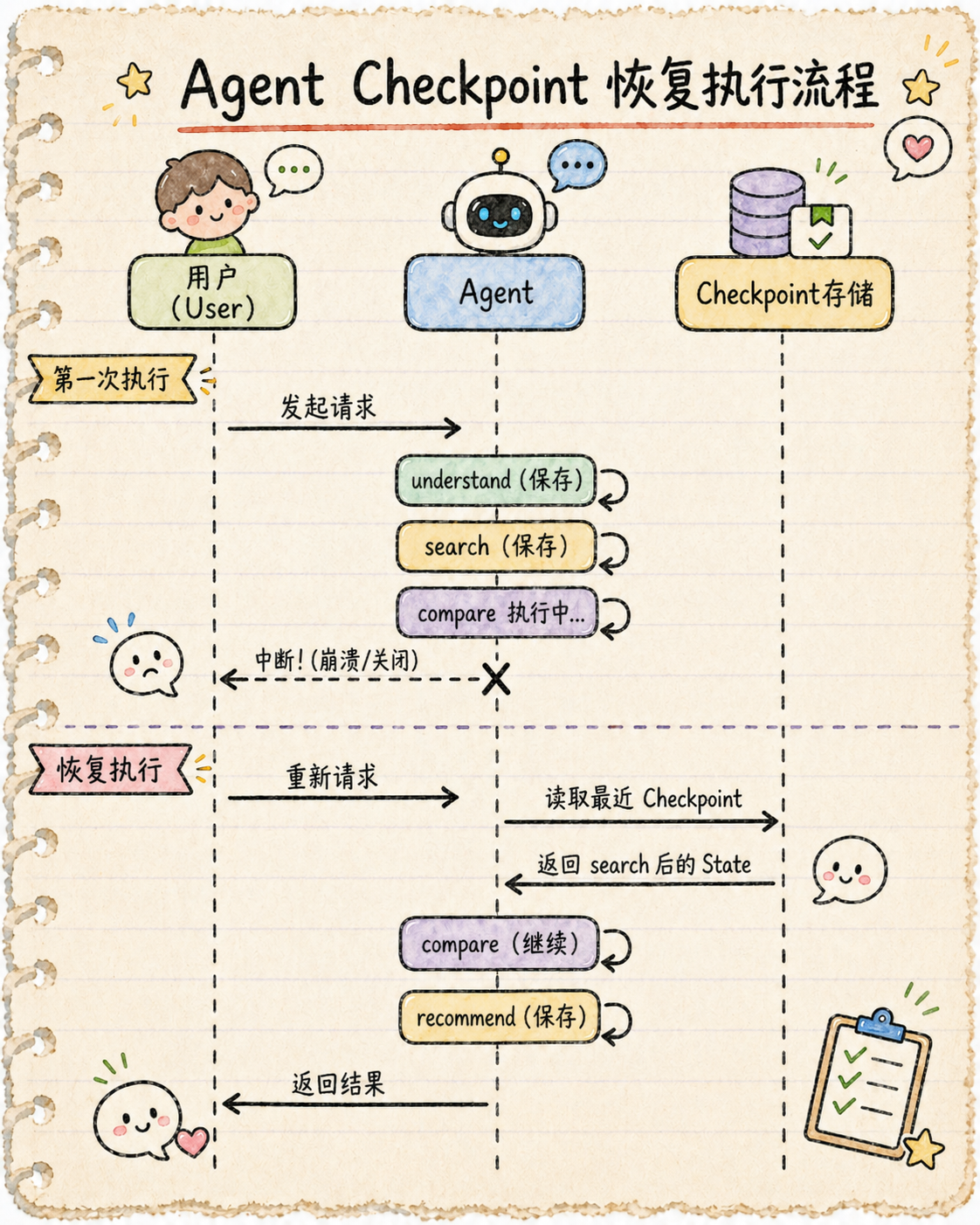
运行输出:
==================================================
第一次执行:模拟中断
==================================================
[understand] 理解需求: 想买一个打游戏快的笔记本电脑
[search] 搜索商品中...
[compare] 对比商品... (模拟中断点)
中断了: 模拟中断:服务器崩了
==================================================
第二次执行:从 Checkpoint 恢复
==================================================
[compare] 已完成,跳过
[recommend] 推荐: 商品A
最终结果: 强烈推荐 商品A!可以看到恢复时,compare 检测到已完成就直接跳过了,recommend 从之前保存的 products 继续执行。
七、项目中怎么用
实际场景:
-
长任务恢复:用户提交一个复杂的数据分析任务,跑了 2 小时后服务器重启。从 Checkpoint 恢复,不用重新跑。
-
页面刷新保留状态:用户在 AI 助手页面填写了一个长表单,刷新后继续填,不用重新填。
-
多轮对话恢复:用户和 Agent 对话了 10 轮,中断了。重新打开时从第 10 轮的 Checkpoint 继续。
注意点:
-
设计幂等的 Node:每个 Node 要么完全成功,要么完全失败,避免中间状态丢失。
-
分离关键数据和临时数据:Checkpoint 只保存关键数据,减少存储开销。
-
设置合理的 Checkpoint 过期时间:避免存储无限增长。
八、总结 + 下篇预告
核心要点:
- Checkpoint = State 快照,在 Node 执行完成后保存
- 恢复时传入同一个 thread_id,Agent 自动找到最近的 Checkpoint 继续执行
- Checkpoint 让 Agent 不怕中断,用户不用重新等待
- 存储方式:开发用 MemorySaver,生产用 PostgresSaver
下篇预告:下一篇我们将探讨《Agent 的 Time Travel 是什么?》,理解如何利用 Checkpoint 实现"回到过去"------不是简单恢复,而是像时间旅行一样回到任意之前的状态。
延伸阅读: