1 回归概述
1.1 什么是回归
回归是一种监督学习 方法,主要用于预测连续值。
Regression is a supervised learning method mainly for predicting continuous values.
1.2 历史来源
1885 年由 Francis Galton 提出,最初用于研究父母与子女身高的遗传关系。
Proposed by Francis Galton in 1885, originally for studying hereditary stature.
1.3 回归的三种类型
- 简单线性回归(Simple Linear Regression):一个输入,一个输出(one input, one output)
- 多元回归(Multiple Regression):多个输入,一个输出(multiple inputs, one output)
- 多输出回归(Multivariate Regression):多个输入,多个输出(multiple inputs, multiple outputs)
1.4 核心思想
假设输出 y 与输入 x 呈线性关系,学习一组系数,用于预测新样本。
Assume output y has a linear relationship with input x; learn coefficients for prediction.
2 回归的理论定义
2.1 回归问题
独立同分布:样本之间不互相影响,数据来自同一个模型环境规则。
给定独立同分布(i.i.d)的带标签样本,学习一个预测函数 ℎ,使泛化误差最小。
Given i.i.d labeled samples, learn a function ℎ to minimize generalization error.
2.2 泛化误差(Generalization Error)
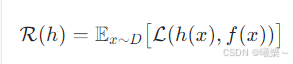
模型在真实数据分布 上的期望误差
Expected error over true data distribution
2.3 经验误差(Empirical Error)
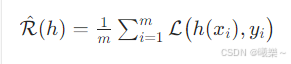
模型在训练集 上的平均误差
Average error on training set
2.4 常用损失:平方误差
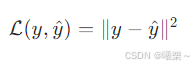
最常用,平滑易优化
Most common, smooth & easy to optimize
3 线性回归(Linear Regression)
线性回归假设预测输出是输入特征的线性组合
3.1 模型公式
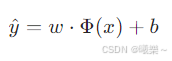
预测值 = 权重・特征 + 偏置
Prediction = weight·feature + bias
3.2 优化目标(MSE)
在假设空间里,找到一组 w,b,使预测值与真实值的均方误差最小
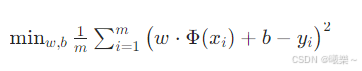
最小化均方误差
Minimize mean squared error
- m:样本数量(number of samples)
- xi:第 i 个输入
- yi:第 i 个真实标签
- Φ(xi):第 i 个样本的特征
3.3 矩阵紧凑形式
在每个Φ(xi)后面+一维1,把所有样本堆叠成矩阵
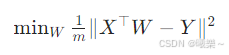
3.4 求最优解:梯度==0
损失函数是凸函数,可导,梯度==0时有最小值
如果 XX⊤ 可逆,直接求逆得到最优 W:
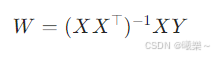
不可逆时用伪逆(pseudo-inverse)。
3.5 线性回归的缺点
- 低偏差、高方差(low bias, high variance)
- 无正则化,容易过拟合
- 无法自动做特征选择
- 无法处理强非线性
4 核岭回归(Kernel Ridge Regression)
4.1 是什么
线性回归 + L2 正则化 + 核技巧,可以拟合非线性。
Linear regression + L2 regularization + kernel trick, can fit nonlinearity.
4.2 目标函数
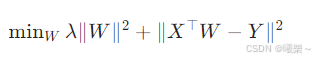
- λ:正则强度(regularization strength)
- L2 正则:让权重变小,防止过拟合
4.3 闭式解
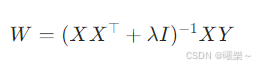
一定可逆,稳定安全
Always invertible, stable & safe
4.4 特点
- 平衡偏差 - 方差(bias-variance trade-off)
- 权重收缩(shrinkage)趋近于 0
- 可用于非线性回归
5 Lasso 回归(Lasso Regression)
5.1 全称
Least Absolute Shrinkage and Selection Operator
最小绝对值收缩与选择算子
5.2 核心
使用 L1 正则 ,可以把不重要特征的权重直接压到 0 ,实现自动特征选择。
Uses L1 regularization to push irrelevant weights to 0 , doing automatic feature selection.
5.3 目标函数
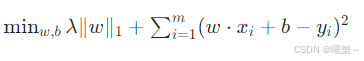
5.4 关键特性
- 稀疏解(sparse solution)
- 输出少量非零权重
- 自动筛选重要特征
- 无法直接使用核技巧
6 弹性网回归(Elastic Net Regression)
6.1 是什么
结合 L1 + L2 正则,融合 Lasso 与 Ridge 的优点。
Combines L1 + L2 regularization, merges advantages of Lasso & Ridge.
6.2 目标函数
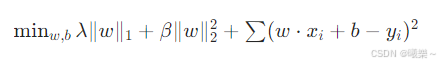
6.3 优点
- 处理特征相关的数据效果更好
- 稳定、比 Lasso 更鲁棒
- 既能稀疏,又能收缩权重
7 数据处理(Dealing with Data)
7.1 非代表性数据
训练数据分布必须与真实场景一致,否则无法泛化。
Train distribution must match real-world distribution.
7.2 低质量数据
- 异常值(outliers):删除或修正
- 噪声(noise):去噪、平滑
- 缺失值(missing values):填充均值 / 中位数,或丢弃特征
7.3 无关特征
用特征选择 或特征提取处理,正则化(Lasso/ElasticNet)可自动筛选。
Use feature selection/extraction, regularization helps automatically.
8 偏差 - 方差权衡(Bias-Variance Trade-off)
8.1 模型误差三部分
- 不可约误差(irreducible error)
- 偏差(Bias) :模型拟合能力不足 → 欠拟合
- 方差(Variance) :模型太敏感 → 过拟合
8.2 规律
- 模型越简单 → 高偏差、低方差
- 模型越复杂 → 低偏差、高方差
- 最优在中间平衡点
8.3 直观理解
- 欠拟合(高偏差):模型太笨,学不会
- 过拟合(高方差):模型太聪明,死记硬背
9 四大回归模型对比
| 模型 | 正则 | 特点 | 适用场景 |
|---|---|---|---|
| 线性回归 | 无 | 简单、易过拟合 | 基础线性问题 |
| 岭回归 Ridge | L2 | 权重收缩、稳定 | 特征多、共线 |
| Lasso | L1 | 稀疏、特征选择 | 高维、筛选特征 |
| 弹性网 ElasticNet | L1+L2 | 稳定 + 稀疏 | 特征相关、高维 |