目录
[1.1 概论](#1.1 概论)
[1.2 基本理论与概念](#1.2 基本理论与概念)
[① 聚类](#① 聚类)
[② 距离度量](#② 距离度量)
[③ 算法评价指标](#③ 算法评价指标)
[2.1 定义](#2.1 定义)
[2.2 数学公式](#2.2 数学公式)
[2.3 算法流程](#2.3 算法流程)
[2.4 优势与缺点](#2.4 优势与缺点)
[3.1 基本思路](#3.1 基本思路)
[3.2 优势与缺点](#3.2 优势与缺点)
[4.1 基本思路](#4.1 基本思路)
[4.2 优势与缺点](#4.2 优势与缺点)
[5.1 K值选择](#5.1 K值选择)
[5.2 代码案例](#5.2 代码案例)
一、前言
1.1 概论
在现实世界中,我们获取的大量数据往往是没有人工标注标签的。聚类算法的核心优势正是在于:它能够在没有先验知识的情况下,自动发现数据内部的隐含结构和模式,将相似的样本归为一类。
聚类分析被广泛应用于各个领域:从电商平台的用户画像分群、到生物信息学中的基因序列分析又或是智能制造加工等各个方面,都能看到聚类算法的存在。本文主要记录了自己对三种聚类算法K-means、K-means++与K-Medoids的学习笔记,从算法介绍、算法流程再到实际应用,希望能帮助自己复盘和更多人学习~
 聚类
聚类
1.2 基本理论与概念
① 聚类
聚类的核心目标是:将物理或抽象对象的集合,划分为多个由相似对象组成的类(也就是簇,Cluster)。 一个好的聚类结果必须满足几个标准:
-
簇内相似度高: 同一个簇内的数据点应该尽可能紧密地挨在一起;
-
簇间相似度低: 不同簇之间应该尽可能地划清界限,离得越远越好。
② 距离度量
而在聚类算法中,相似度一般由距离函数来定义,常用的距离度量包括以下几个:
- a 欧氏距离 :欧氏距离是我们日常生活中最熟悉的距离,即空间中两点之间的直线距离。 对于
维空间中的两个点
**特点:**计算简单,但是由于平方操作,它对离群点非常敏感,误差会被放大。
- b 曼哈顿距离 :亦称为街区距离,它是在多维空间内从一个对象到另一个对象的折线距离。简单可以理解为在街区穿梭,我们无法穿透建筑走直线,只能沿着街道横向和纵向走。其公式为各坐标维度差的绝对值之和:
特点: 使用绝对值代替了平方,因此它不会过度放大异常值的影响,鲁棒性(抗干扰能力)更强。
- c 切比雪夫距离:类似于从国际象棋的棋盘中的一点走到另一点的最少步数。
③ 算法评价指标
聚类是无监督学习,既然没有标准答案,我们又该如何去判断聚类结果好不好呢?通常有内部评价指标 (不知道真实标签)和外部评价指标(知道真实标签,常用于算法性能基准测试),以下列举几种指标:
内部评价指标
- 误差平方和(SSE):衡量的是簇内各个样本点到其所属簇中心的距离平方和。
也就是SSE 越小,说明各个簇内部的数据越紧凑。它常被用于著名的"肘部法则"中,帮助我们寻找最合适的值。
- 轮廓系数(Silhouette Coefficient) :轮廓系数是所有样本轮廓系数的平均值 。轮廓系数的范围为-1,1,同类别样本距离越近且不同类别样本距离越远,分数越高。对于任意一个样本点
其中,:样本
到同簇 其他样本的平均距离(体现紧凑度,越小越好);
:样本
到最近的其他簇的所有样本的平均距离(体现分离度,越大越好)。
- S_Dbw(Scatter and Density between clusters) :也是用来评估聚类内部质量的,但它的考察维度更加细腻,它主要考察两个方面:簇的散布度 (Scatter) 和 簇间密度 (Density)。该指标的公式如下:
其中,代表簇内散布度 :计算所有簇的平均方差与整体数据方差的比值。值越小,说明簇内越紧凑。
代表簇间密度 :计算不同簇中心点连线的中点(也就是两个簇的交界处)周围的数据点密度。交界处的点越少,说明簇与簇之间分得越开,该值越小。S_Dbw 的值越小,代表聚类效果越好。
外部评价指标
- Jaccard 系数(Jaccard Coefficient):评价聚类结果相较于预设参考模型的符合度,来衡量算法的准确度。我们定义任意两个样本点组成一对。对于所有的样本对,会有以下几种情况:
i TP (True Positive,真正例):真实情况里它俩是同类,聚类结果里它俩也是同类。(准确)
ii FP (False Positive,假正例): 真实情况里它俩不是同类,但聚类结果把它俩分到了同类。(聚类出错)
iii FN (False Negative,假反例): 真实情况里它俩是同类,但聚类结果把它俩分到了不同类。(聚类出错)
那么Jaccard 系数计算为:
评判方法就是:Jaccard 系数的取值范围是 0, 1。值越接近 1,说明聚类结果与真实情况越吻合,效果越好。 如果为 1,说明聚类结果和真实标签完全一模一样。
- 调整的兰德系数(ARI):取值范围在-1,1,值越大意味着聚类结果与真实情况相吻合。
- 互信息评分(MI):可以利用互信息衡量实际类别与预测类别的吻合程度。
二、K-means算法
K-means 算法也被称为K-平均或K-均值算法,它的核心思想是通过迭代优化,将数据集划分成K个簇,使得簇内样本的相似度尽可能高。
2.1 定义
- 簇(Cluster) :K-means 通过最小化簇内距离的平方和,使得数据点在簇内聚集。一个簇是数据点的集合,这些点在某种意义上"彼此相似"。
- 簇中心(Centroid):簇中心是簇中所有点的平均值,表示簇的中心位置。
- 簇分配和更新:K-means 通过反复迭代,调整簇的分配,使得簇内数据点与质心的距离尽可能小,逐步收敛。

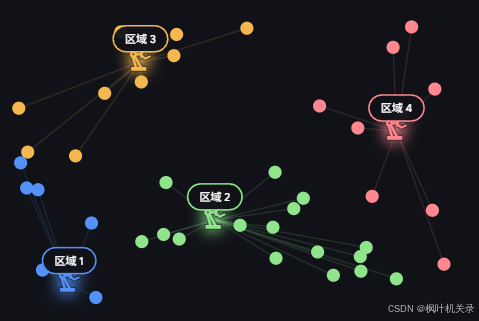
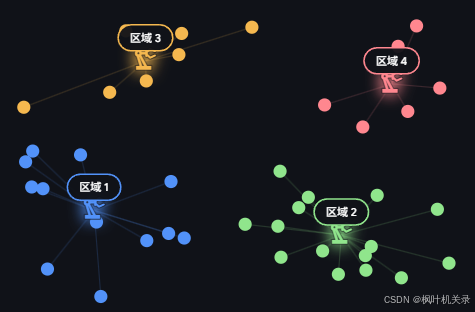
迭代过程
2.2 数学公式
K-means 通常采用欧氏距离(Euclidean Distance)作为相似度度量。空间中两点x和y的距离为:
算法优化的目标函数是最小化簇内误差平方和:
以上,为簇的数量,
是第
个簇的算术均值中心,
是属于该簇的第
个样本。
2.3 算法流程
- **初始化:**在数据空间中随机选择K个点作为初始的"簇中心"(Centroids)。
- **分配节点:**计算所有样本点到这K个中心的距离,将每个样本分配给距离它最近的那个中心,形成K个簇。
- 更新中心: 重新计算每个簇内所有样本点的几何平均值(坐标的算术平均数),将其作为该簇新的中心点。之所以被称为K-Means是因为它可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值计算而成。
- 迭代: 重复步骤 2 和步骤 3,直到中心点的位置不再发生明显变化(或达到迭代设定步数)。
注意:算法中使用到距离可以是任何的距离计算公式,最常用的是欧氏距离,应用时具体应该选择哪种距离计算方式,需要根据具体场景确定。
2.4 优势与缺点
优势:
-
优势1: 原理简单,计算复杂度低(时间复杂度为
-
**优势2:**在适合的初始中心选择下,K-means 通常可以较快收敛。
缺点:
-
对初始点敏感: 完全随机的初始化可能导致初始中心点过于密集,从而使算法陷入局部最优解,导致聚类失败。
-
异常值敏感: 由于在更新步骤中采用了"算术平均值",一旦簇内存在极端的异常值,中心点会被严重拉偏。
-
**局部最优:**K-means不能保证全局最优,只能达到局部最优。
三、K-means++算法
为了解决 K-means 的痛点:陷入局部最优 ,K-means++ 算法应运而生,它可以帮助选择更合理的初始中心,优先选择"距离最远"的点作为初始质心,减少陷入局部最优的风险。它保留了 K-means 所有的迭代更新逻辑,仅仅是对 初始点的选择机制进行了数学上的优化。
3.1 基本思路
- 从数据集
- 计算数据集
- 采用"轮盘法"的方法选择下一个中心点:样本点距离现有中心越远,其被选为下一个中心的概率
- 重复步骤2、3,直到选出
- 之后运行K-means的聚类算法:计算每个数据点到 k 个簇中心的距离,将数据点分配到距离最近的簇中心所在的簇,然后重新计算每个簇的中心,不断迭代这个过程,直到簇中心的变化小于某个阈值或者达到预设的迭代次数。
其中,点被选择为下一个中心点的概率
为:
注:使用距离的平方是为了进一步放大偏远点被选中的概率,确保中心点足够分散。
3.2 优势与缺点
优点:
- **减小陷入局部最优风险:**传统的 K-means 算法是随机选择聚类中心,可能导致聚类中心选择得非常接近,使得算法可能陷入局部最优。而K-means++确保了初始聚类中心的分布更加均匀,从而减少了这种风险。
- 提高收敛速度:虽然初始化阶段增加了计算开销,但通常能大幅减少后续的迭代次数,整体效率更优。
- **结果稳定:**由于增加了中心选择的方法,使得最终聚类结果更加稳定(尤其在处理具有复杂结构或分布的数据时)。
缺点:
- **算法复杂度高:**相比于传统 K-means 算法,K-means++ 算法在初始化簇中心时需要计算每个点到已选簇中心的距离,并根据距离计算概率来选择新的簇中心,这增加了额外的计算量。
- **处理高维数据不佳:**随着数据维度的增加,会出现 "维度灾难" 问题,数据点之间的距离度量变得更加复杂和不准确,这也使得K-means++可能会出现聚类效果不佳的情况。
四、K-Medoids算法
为解决Kmeans采用算数平均导致的异常值敏感问题,K-Mediods算法出现。它们两者间核心思想大同小异,但是最大的不同是在中心点的修正。K-means中选取的中心点为当前类中所有点的重心,而K-medoids法选取的中心点为当前簇中真实存在的一点。这样由于中心点受真实数据的强约束,极端的异常样本无法轻易改变中心点的位置。
4.1 基本思路
- 初始化: 随机从数据集中选取
- 聚类分区: 将其余所有样本点分配给距离其最近的中心点;
- 计算代价: 计算当前所有样本点到其对应中心点的距离之和;
- 替换与迭代: 尝试用簇内的一个非中心点
- 收敛: 重复遍历,直到没有任何替换能够使总距离下降为止。
为了进一步削弱异常值的影响,K-Medoids 放弃平方距离,改用曼哈顿距离(Manhattan Distance)或其他基于绝对值的距离度量:
算法目标函数是最小化绝对误差和:
以上,为集合
的样本点,
必须满足
(即属于原始数据集)
4.2 优势与缺点
优势
- **鲁棒性好:**当存在噪声和离群点时,k-medoids方法比k-means方法鲁棒性更好。此外,聚类结果具有更强的可解释性(中心点是真实的典型案例)。
缺点
- 计算复杂度高: 每次尝试替换中心点时,都需要重新计算大量点与点之间的距离,其单次迭代的时间复杂度高达
五、K值的选择及案例分析
5.1 K值选择
确定最佳的簇数常用的方法有:
- 肘部法(Elbow Method)
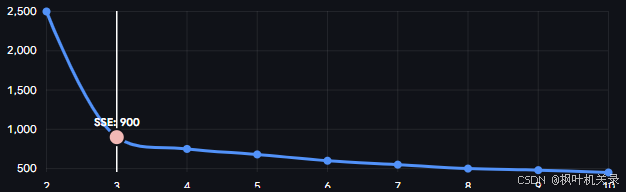
我们在第一章讲了评价指标误差平方和(SSE),肘部法则就是利用 SSE 来找 K 值的。具体流程就是:
首先我们给定一些K值,每次运行完,我们计算出当前的整体 SSE 值并记录下来。可以预见的是,随着越来越大,类别被切分得越来越细,簇内的数据点肯定离中心点越来越近,所以 SSE 的总趋势一定是不断下降的 。(极端情况下,如果
等于样本总数,每个样本自己就是一个簇,SSE 就变成了 0)。
那么如何确定K值呢?我们把值作为横坐标,SSE 作为纵坐标,画一条折线图,在急速下降转为平稳时的拐点(像人的手肘),就是推荐的K值了。
- 轮廓系数法 (Silhouette Coefficient)
衡量聚类结果的紧密度和分离度。通常轮廓系数越高,聚类效果越好。和上面类似,求出K值对应下的所有样本轮廓系数平均值,然后绘制折线图,找到图中最高点,就是推荐的K值了。
5.2 代码案例
结合以上所学做出了这样的一个算法可视化过程,代码及结果如下:
Matlab
function clustering_visual_demo_fixed
clc; clear; close all;
%% =========================
% 1. 构造示例数据
% ==========================
rng(2);
n1 = 70; n2 = 70; n3 = 70;
X1 = randn(n1,2)*0.55 + [2,2];
X2 = randn(n2,2)*0.65 + [7,3];
X3 = randn(n3,2)*0.50 + [4,7];
% 少量离群点:方便体现 K-medoids 稳健性,也会影响 K-means++ 选点概率
outliers = [9 8; 0.5 7.5; 8.5 0.8; 10 4];
X = [X1; X2; X3; outliers];
%% =========================
% 2. K值选择图
% ==========================
kRange = 2:6;
[sse_vals, sil_vals, bestK] = evaluate_k_values(X, kRange);
plot_k_selection_like_example(kRange, sse_vals, sil_vals, bestK);
fprintf('根据轮廓系数法,推荐最佳 K = %d\n', bestK);
% 为了演示清楚,也可以手动固定
K = bestK;
% K = 3;
%% =========================
% 3. 构造三种算法的完整历史
% ==========================
maxIter = 15;
rng(8);
kmeansResult = build_kmeans_full_demo(X, K, maxIter, 'K-means(随机空间初始化)');
rng(8);
kmeansppResult = build_kmeanspp_full_demo(X, K, maxIter, 'K-means++');
rng(8);
kmedoidsResult = build_kmedoids_full_demo(X, K, maxIter, 'K-medoids');
%% =========================
% 4. 打开三个交互窗口
% ==========================
launch_interactive_viewer(kmeansResult);
launch_interactive_viewer(kmeansppResult);
launch_interactive_viewer(kmedoidsResult);
%% =========================
% 5. 初始中心对比图
% ==========================
figure('Name','三种算法初始中心对比','Color','w','Position',[100 100 1380 430]);
subplot(1,3,1);
scatter(X(:,1), X(:,2), 24, [0.75 0.75 0.75], 'filled'); hold on;
scatter(kmeansResult.initCenters(:,1), kmeansResult.initCenters(:,2), 180, ...
[0.85 0.33 0.10], 'p', 'filled');
title('K-means:在空间随机生成 K 个初始点');
xlabel('x_1'); ylabel('x_2'); axis equal; grid on;
legend('数据点','初始中心','Location','best');
subplot(1,3,2);
scatter(X(:,1), X(:,2), 24, [0.75 0.75 0.75], 'filled'); hold on;
scatter(kmeansppResult.initCenters(:,1), kmeansppResult.initCenters(:,2), 180, ...
[0.85 0.33 0.10], 'p', 'filled');
title('K-means++:逐步选出的初始真实样本点');
xlabel('x_1'); ylabel('x_2'); axis equal; grid on;
legend('数据点','初始中心','Location','best');
subplot(1,3,3);
scatter(X(:,1), X(:,2), 24, [0.75 0.75 0.75], 'filled'); hold on;
scatter(kmedoidsResult.initCenters(:,1), kmedoidsResult.initCenters(:,2), 180, ...
[0.85 0.33 0.10], 'p', 'filled');
title('K-medoids:随机选 K 个真实样本点');
xlabel('x_1'); ylabel('x_2'); axis equal; grid on;
legend('数据点','初始中心','Location','best');
end
%% =========================================================
% K值评估
%% =========================================================
function [sse_vals, sil_vals, bestK] = evaluate_k_values(X, kRange)
sse_vals = zeros(size(kRange));
sil_vals = zeros(size(kRange));
oldVisible = get(groot, 'defaultFigureVisible');
set(groot, 'defaultFigureVisible', 'off');
for i = 1:length(kRange)
k = kRange(i);
[idx, ~, sumd] = kmeans(X, k, ...
'Start', 'plus', ...
'Replicates', 10, ...
'MaxIter', 100);
sse_vals(i) = sum(sumd);
f = figure('Visible','off');
s = silhouette(X, idx);
sil_vals(i) = mean(s);
close(f);
end
set(groot, 'defaultFigureVisible', oldVisible);
[~, loc] = max(sil_vals);
bestK = kRange(loc);
end
%% =========================================================
% K值选择图
%% =========================================================
function plot_k_selection_like_example(kRange, sse_vals, sil_vals, bestK)
figure('Name','K值选择','Color',[0.94 0.94 0.94], 'Position',[100 100 980 430]);
subplot(1,2,1);
plot(kRange, sse_vals, '-o', ...
'LineWidth', 2.0, ...
'MarkerSize', 8, ...
'MarkerFaceColor', 'b', ...
'Color', 'b');
hold on;
xline(bestK, '--r', 'LineWidth', 1.5);
yl = ylim;
text(bestK + 0.05, yl(1) + 0.05*(yl(2)-yl(1)), ...
sprintf('最佳 K = %d', bestK), ...
'Color', 'r', 'Rotation', 90, 'FontSize', 11);
title('肘部法则 (SSE)', 'FontWeight', 'bold');
xlabel('K 值');
ylabel('误差平方和');
grid on;
box on;
subplot(1,2,2);
plot(kRange, sil_vals, '-s', ...
'LineWidth', 2.0, ...
'MarkerSize', 8, ...
'MarkerFaceColor', [0 1 0], ...
'Color', [0 0.85 0]);
hold on;
xline(bestK, '--r', 'LineWidth', 1.5);
yl = ylim;
text(bestK + 0.05, yl(1) + 0.05*(yl(2)-yl(1)), ...
sprintf('最优聚类数 = %d', bestK), ...
'Color', 'r', 'Rotation', 90, 'FontSize', 11);
title('轮廓系数法', 'FontWeight', 'bold');
xlabel('K 值');
ylabel('平均轮廓系数');
grid on;
box on;
end
%% =========================================================
% K-means:随机空间初始化
% 初始中心不要求是真实样本点
%% =========================================================
function result = build_kmeans_full_demo(X, K, maxIter, algoName)
d = size(X,2);
% 在数据空间范围内随机生成 K 个初始点
init_centers = random_points_in_space(X, K);
states = {};
state.phase = '初始化';
state.iter = 0;
state.centers = init_centers;
state.idx = [];
state.centerType = '初始中心是空间中的随机点';
state.note = sprintf('K-means 初始化:在数据空间范围内随机生成 %d 个初始中心,不要求是真实样本点', K);
state.showInitOnly = true;
states{end+1} = state;
centers = init_centers;
for iter = 1:maxIter
idx = assign_points(X, centers);
new_centers = centers;
for k = 1:K
pts = X(idx == k, :);
if ~isempty(pts)
new_centers(k,:) = mean(pts, 1);
end
end
state.phase = '聚类迭代';
state.iter = iter;
state.centers = new_centers;
state.idx = assign_points(X, new_centers);
state.centerType = '当前中心是均值点,不一定是真实样本点';
state.note = 'K-means 迭代:将每个簇的中心更新为簇内样本均值';
state.showInitOnly = false;
states{end+1} = state;
if norm(new_centers - centers) < 1e-8
break;
end
centers = new_centers;
end
result.X = X;
result.K = K;
result.d = d;
result.name = algoName;
result.states = states;
result.initCenters = init_centers;
result.centerIsRealAlways = false;
result.initTypeText = '初始中心:随机空间点(不要求是真实样本点)';
result.currentTypeText = '当前中心:均值点';
result.currentMarker = 'x';
end
%% =========================================================
% K-means++:逐步选真实样本点作为初始中心
%% =========================================================
function result = build_kmeanspp_full_demo(X, K, maxIter, algoName)
n = size(X,1);
d = size(X,2);
states = {};
centers = zeros(K, d);
selectedMask = false(n,1);
% 第一个中心:随机选真实样本点
idx1 = randi(n);
centers(1,:) = X(idx1,:);
selectedMask(idx1) = true;
state.phase = '初始化';
state.iter = 1;
state.centers = centers(1,:);
state.idx = [];
state.centerType = '当前已选中心是真实样本点';
state.note = 'K-means++ 初始化:先随机选 1 个真实样本点作为第一个中心';
state.showInitOnly = true;
state.prob = [];
state.D2 = [];
states{end+1} = state;
% 后续中心:按 D(x)^2 概率选
for k = 2:K
D2 = zeros(n,1);
for i = 1:n
dtemp = sum((centers(1:k-1,:) - X(i,:)).^2, 2);
D2(i) = min(dtemp);
end
% 已选点不再参与
D2(selectedMask) = 0;
s = sum(D2);
if s <= eps
% 兜底:如果概率退化,则从未选点里随机选
candidates = find(~selectedMask);
idx = candidates(randi(length(candidates)));
prob = zeros(n,1);
else
prob = D2 / s;
cumprob = cumsum(prob);
r = rand;
idx = find(cumprob >= r, 1, 'first');
end
centers(k,:) = X(idx,:);
selectedMask(idx) = true;
state.phase = '初始化';
state.iter = k;
state.centers = centers(1:k,:);
state.idx = [];
state.centerType = '当前已选中心是真实样本点';
state.note = sprintf('K-means++ 初始化:第 %d 个中心按 D(x)^2 概率选取', k);
state.showInitOnly = true;
state.prob = prob;
state.D2 = D2;
states{end+1} = state;
end
init_centers = centers;
% 初始化完成后,进入普通 K-means 迭代
for iter = 1:maxIter
idx = assign_points(X, centers);
new_centers = centers;
for k = 1:K
pts = X(idx == k, :);
if ~isempty(pts)
new_centers(k,:) = mean(pts,1);
end
end
state.phase = '聚类迭代';
state.iter = iter;
state.centers = new_centers;
state.idx = assign_points(X, new_centers);
state.centerType = '当前中心是均值点,不一定是真实样本点';
state.note = 'K-means++ 完成初始化后,后续迭代与普通 K-means 相同';
state.showInitOnly = false;
state.prob = [];
state.D2 = [];
states{end+1} = state;
if norm(new_centers - centers) < 1e-8
break;
end
centers = new_centers;
end
result.X = X;
result.K = K;
result.d = d;
result.name = algoName;
result.states = states;
result.initCenters = init_centers;
result.centerIsRealAlways = false;
result.initTypeText = '初始中心:按概率逐步选出的真实样本点';
result.currentTypeText = '当前中心:均值点';
result.currentMarker = 'x';
end
%% =========================================================
% K-medoids:初始中心和迭代中心都是真实样本点
%% =========================================================
function result = build_kmedoids_full_demo(X, K, maxIter, algoName)
n = size(X,1);
d = size(X,2);
init_idx = randperm(n, K);
medoid_idx = init_idx(:);
medoids = X(medoid_idx,:);
states = {};
state.phase = '初始化';
state.iter = 0;
state.centers = medoids;
state.idx = [];
state.centerType = '初始中心是真实样本点(medoid)';
state.note = sprintf('K-medoids 初始化:随机选取 %d 个真实样本点作为初始 medoids', K);
state.showInitOnly = true;
states{end+1} = state;
for iter = 1:maxIter
idx = assign_points(X, medoids);
old_medoid_idx = medoid_idx;
for k = 1:K
cluster_points = find(idx == k);
if isempty(cluster_points)
continue;
end
best_cost = inf;
best_idx = medoid_idx(k);
for ii = 1:length(cluster_points)
candidate = cluster_points(ii);
cost = 0;
for jj = 1:length(cluster_points)
p = cluster_points(jj);
cost = cost + norm(X(candidate,:) - X(p,:));
end
if cost < best_cost
best_cost = cost;
best_idx = candidate;
end
end
medoid_idx(k) = best_idx;
end
medoids = X(medoid_idx,:);
state.phase = '聚类迭代';
state.iter = iter;
state.centers = medoids;
state.idx = assign_points(X, medoids);
state.centerType = '当前中心始终是真实样本点(medoid)';
state.note = 'K-medoids 迭代:在每个簇中选择总代价最小的真实样本点作为新中心';
state.showInitOnly = false;
states{end+1} = state;
if isequal(old_medoid_idx, medoid_idx)
break;
end
end
result.X = X;
result.K = K;
result.d = d;
result.name = algoName;
result.states = states;
result.initCenters = X(init_idx,:);
result.centerIsRealAlways = true;
result.initTypeText = '初始中心:随机选取的真实样本点';
result.currentTypeText = '当前中心:真实样本点';
result.currentMarker = 's';
end
%% =========================================================
% 在空间中随机生成 K 个点
%% =========================================================
function centers = random_points_in_space(X, K)
mins = min(X, [], 1);
maxs = max(X, [], 1);
rangeVals = maxs - mins;
centers = mins + rand(K, size(X,2)) .* rangeVals;
end
%% =========================================================
% 按最近中心分配样本
%% =========================================================
function idx = assign_points(X, centers)
n = size(X,1);
idx = zeros(n,1);
for i = 1:n
dist = sum((centers - X(i,:)).^2, 2);
[~, idx(i)] = min(dist);
end
end
%% =========================================================
% 打开交互窗口
%% =========================================================
function launch_interactive_viewer(result)
fig = figure('Name', result.name, ...
'Color', 'w', ...
'Position', [120 120 930 680]);
ax = axes('Parent', fig, 'Position', [0.08 0.24 0.82 0.68]);
data.currentStep = 1;
data.states = result.states;
data.X = result.X;
data.ax = ax;
data.result = result;
guidata(fig, data);
uicontrol(fig, 'Style', 'pushbutton', ...
'String', '下一步', ...
'FontSize', 11, ...
'Position', [120 80 100 42], ...
'Callback', @(src,evt)next_step(fig));
uicontrol(fig, 'Style', 'pushbutton', ...
'String', '上一步', ...
'FontSize', 11, ...
'Position', [240 80 100 42], ...
'Callback', @(src,evt)prev_step(fig));
uicontrol(fig, 'Style', 'pushbutton', ...
'String', '播放全部', ...
'FontSize', 11, ...
'Position', [360 80 100 42], ...
'Callback', @(src,evt)play_all(fig));
uicontrol(fig, 'Style', 'pushbutton', ...
'String', '重置', ...
'FontSize', 11, ...
'Position', [480 80 100 42], ...
'Callback', @(src,evt)reset_view(fig));
uicontrol(fig, 'Style', 'text', ...
'String', result.name, ...
'FontSize', 13, ...
'FontWeight', 'bold', ...
'BackgroundColor', 'w', ...
'Position', [620 82 240 32]);
draw_current_state(fig, 1);
end
%% =========================================================
% 下一步
%% =========================================================
function next_step(fig)
data = guidata(fig);
if data.currentStep < length(data.states)
data.currentStep = data.currentStep + 1;
guidata(fig, data);
draw_current_state(fig, data.currentStep);
end
end
%% =========================================================
% 上一步
%% =========================================================
function prev_step(fig)
data = guidata(fig);
if data.currentStep > 1
data.currentStep = data.currentStep - 1;
guidata(fig, data);
draw_current_state(fig, data.currentStep);
end
end
%% =========================================================
% 播放全部
%% =========================================================
function play_all(fig)
data = guidata(fig);
for s = data.currentStep:length(data.states)
data.currentStep = s;
guidata(fig, data);
draw_current_state(fig, s);
pause(0.9);
end
end
%% =========================================================
% 重置
%% =========================================================
function reset_view(fig)
data = guidata(fig);
data.currentStep = 1;
guidata(fig, data);
draw_current_state(fig, 1);
end
%% =========================================================
% 绘制当前状态
%% =========================================================
function draw_current_state(fig, stepIdx)
data = guidata(fig);
ax = data.ax;
X = data.X;
states = data.states;
state = states{stepIdx};
result = data.result;
cla(ax);
axes(ax);
if state.showInitOnly
scatter(X(:,1), X(:,2), 24, [0.78 0.78 0.78], 'filled'); hold on;
scatter(state.centers(:,1), state.centers(:,2), 220, ...
[0.85 0.33 0.10], 'p', 'filled', ...
'DisplayName', '当前已选初始中心');
title(sprintf('%s - %s 第 %d 步', result.name, state.phase, state.iter), ...
'FontWeight', 'bold', 'FontSize', 14);
xlabel('x_1'); ylabel('x_2');
axis equal; grid on; box on;
xl = xlim; yl = ylim;
if strcmp(result.name, 'K-means++') && ~isempty(state.D2)
infoText = ['说明:当前是 K-means++ 初始化阶段' newline ...
'新中心按 D(x)^2 概率选取,离现有中心越远,被选中的概率越大' newline ...
'注:如果离群点很远,它被选中是可能且合理的'];
else
infoText = [state.centerType newline state.note];
end
text(xl(1) + 0.02*range(xl), yl(2) - 0.02*range(yl), infoText, ...
'FontSize', 10.5, ...
'BackgroundColor', [1 1 1 0.92], ...
'EdgeColor', [0.6 0.6 0.6], ...
'VerticalAlignment', 'top');
legend('Location', 'eastoutside');
hold off;
else
cmap = lines(max(result.K, 3));
gscatter(X(:,1), X(:,2), state.idx, cmap, 'o', 6, 'off');
hold on;
% 初始中心
scatter(result.initCenters(:,1), result.initCenters(:,2), 180, ...
[0.85 0.33 0.10], 'p', 'filled', ...
'DisplayName', '初始中心');
% 当前中心
if result.centerIsRealAlways
scatter(state.centers(:,1), state.centers(:,2), 220, ...
'k', 's', 'LineWidth', 2.2, ...
'DisplayName', '当前中心');
else
scatter(state.centers(:,1), state.centers(:,2), 220, ...
'k', 'x', 'LineWidth', 2.5, ...
'DisplayName', '当前中心');
end
% 画轨迹:这次修复"初始化 -> 第1次迭代"也要画
draw_center_trajectories(states, stepIdx);
title(sprintf('%s - %s 第 %d 次', result.name, state.phase, state.iter), ...
'FontWeight', 'bold', 'FontSize', 14);
xlabel('x_1'); ylabel('x_2');
axis equal; grid on; box on;
xl = xlim; yl = ylim;
if result.centerIsRealAlways
infoText = [result.initTypeText newline ...
result.currentTypeText newline ...
'初始中心:橙色五角星' newline ...
'当前中心:黑色方块' newline ...
'特点:中心始终来自数据集中的真实样本点'];
else
infoText = [result.initTypeText newline ...
result.currentTypeText newline ...
'初始中心:橙色五角星' newline ...
'当前中心:黑色叉号' newline ...
'特点:当前中心可能位于样本之间,不一定是真实样本点'];
end
text(xl(1) + 0.02*range(xl), yl(2) - 0.02*range(yl), infoText, ...
'FontSize', 10.5, ...
'BackgroundColor', [1 1 1 0.92], ...
'EdgeColor', [0.6 0.6 0.6], ...
'VerticalAlignment', 'top');
legend('Location', 'eastoutside');
hold off;
end
end
%% =========================================================
% 画中心轨迹
% 修复点:
% 1) 初始化 -> 第1次迭代 也画虚线
% 2) 后续迭代之间继续画虚线
%% =========================================================
function draw_center_trajectories(states, stepIdx)
clusterStateIdx = [];
for i = 1:stepIdx
if strcmp(states{i}.phase, '聚类迭代')
clusterStateIdx(end+1) = i; %#ok<AGROW>
end
end
if isempty(clusterStateIdx)
return;
end
% 先画:最后一个初始化状态 -> 第一个聚类迭代状态
firstClusterIdx = clusterStateIdx(1);
if firstClusterIdx > 1
prevCenters = states{firstClusterIdx - 1}.centers;
currCenters = states{firstClusterIdx}.centers;
draw_one_segment(prevCenters, currCenters);
end
% 再画:聚类迭代 -> 聚类迭代
for t = 2:length(clusterStateIdx)
prevCenters = states{clusterStateIdx(t-1)}.centers;
currCenters = states{clusterStateIdx(t)}.centers;
draw_one_segment(prevCenters, currCenters);
end
end
%% =========================================================
% 画一段中心连线
%% =========================================================
function draw_one_segment(prevCenters, currCenters)
m = min(size(prevCenters,1), size(currCenters,1));
for k = 1:m
plot([prevCenters(k,1), currCenters(k,1)], ...
[prevCenters(k,2), currCenters(k,2)], ...
'k--', 'LineWidth', 1.2);
end
end运行后结果如下:
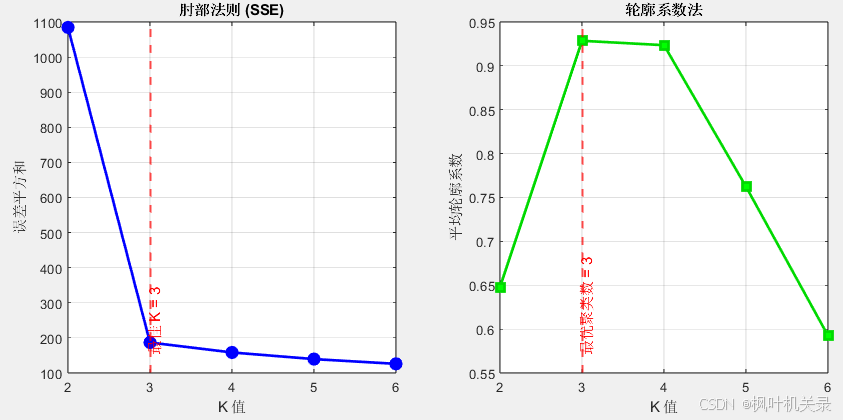
首先是"% K值选择图"这一块,运行完成后可以根据肘部法则(SSE)和轮廓系数法确定数据点的K个簇中心值。(案例输出K=3)
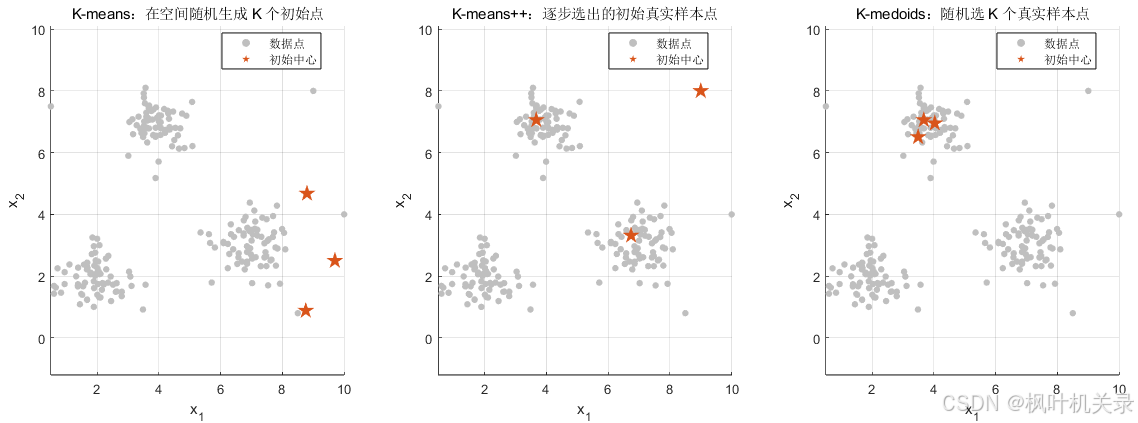
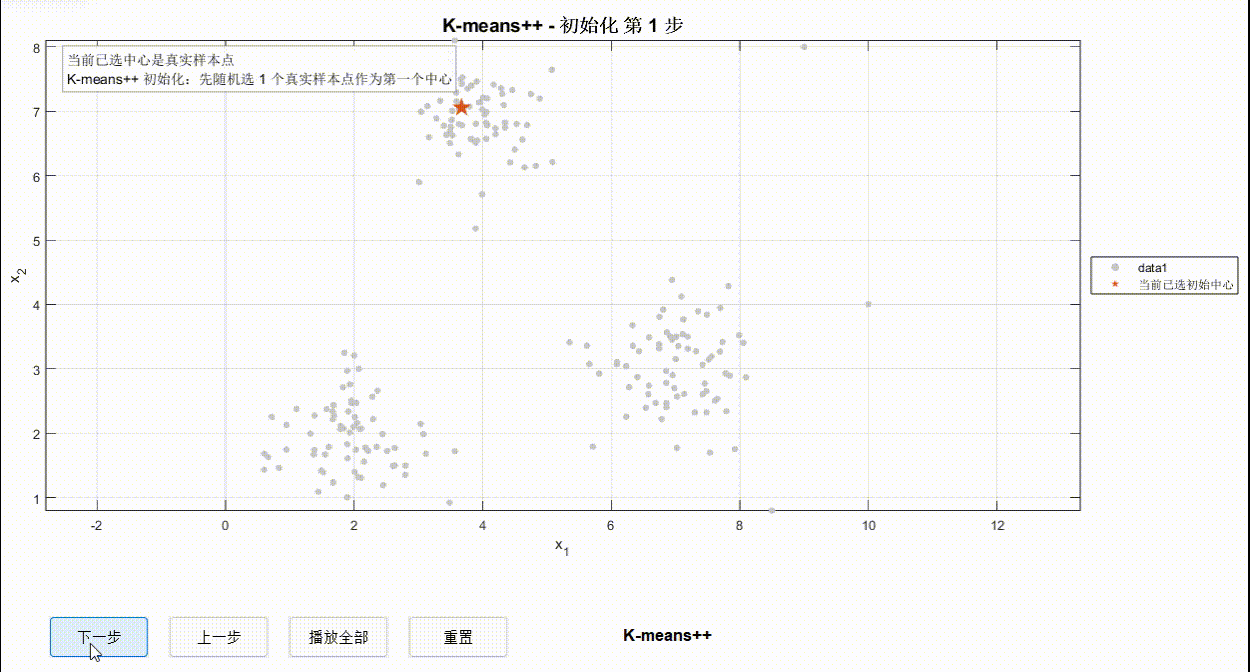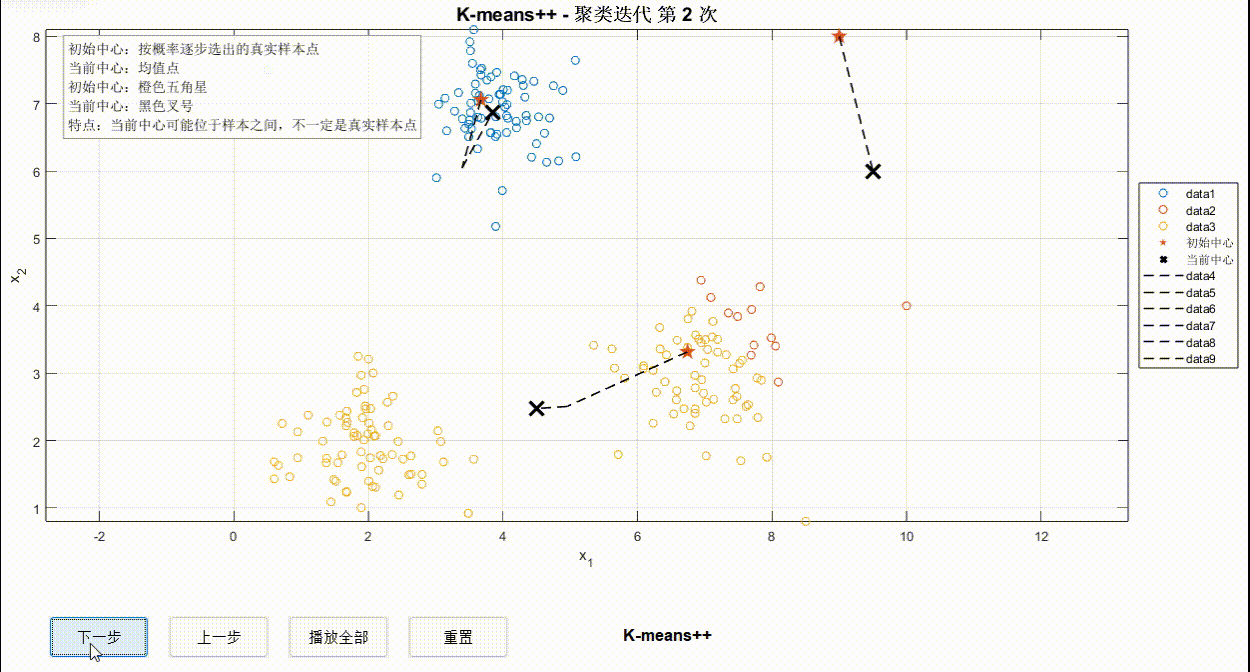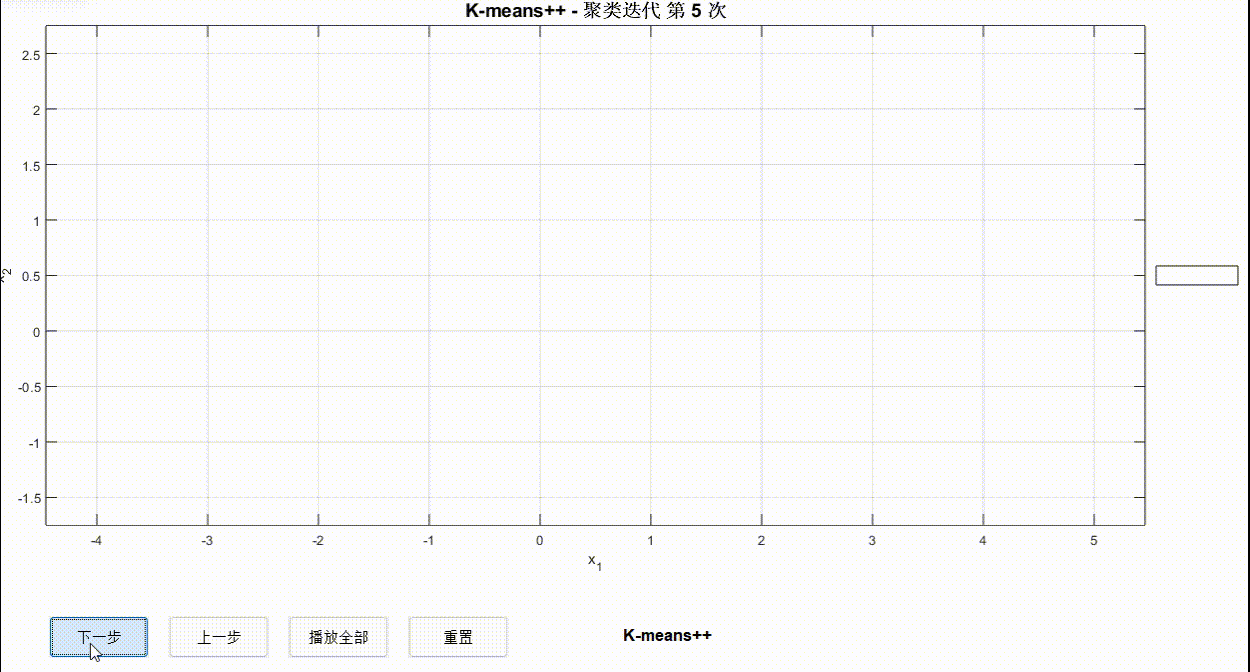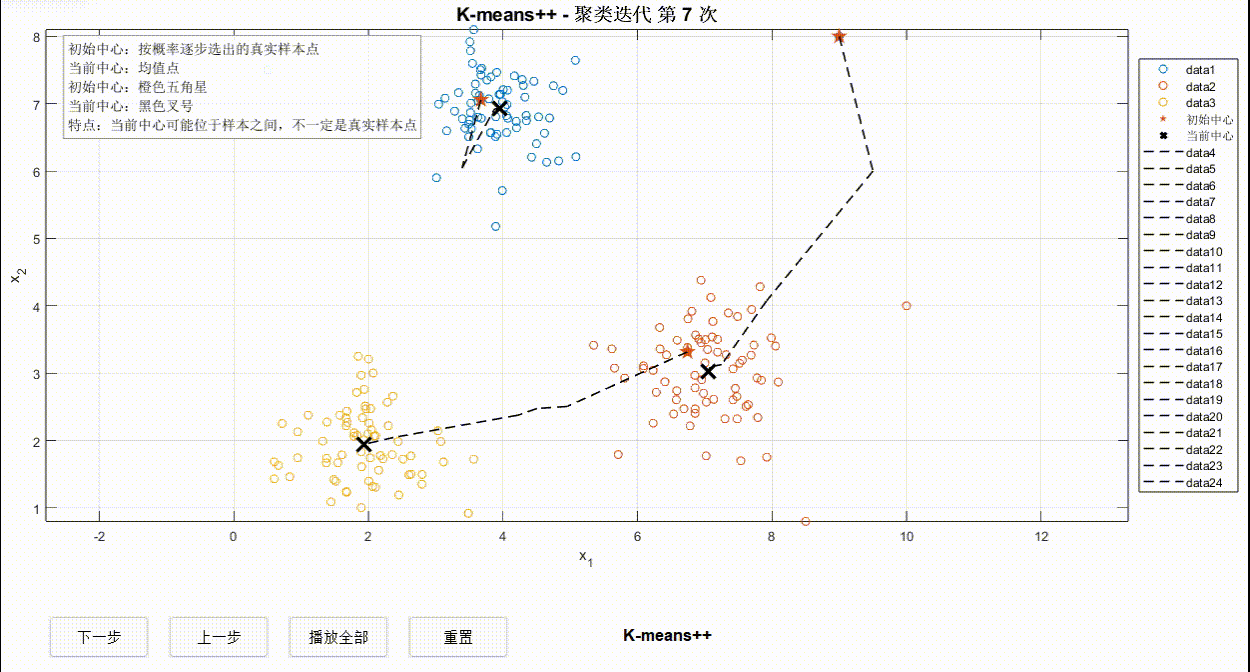
有了K值后对于三种算法流程下一步应该做的就是确定K个初始点,但三种算法的初始点确定有所区别:K-Means在空间中随机选择三个点(不一定是真实样本点)、K-Means++先选择一个样本点然后用轮盘法用概率去逐步选出其他点、K-Medoids则随机选择K个真实的样本点。初始中心如下图所示:
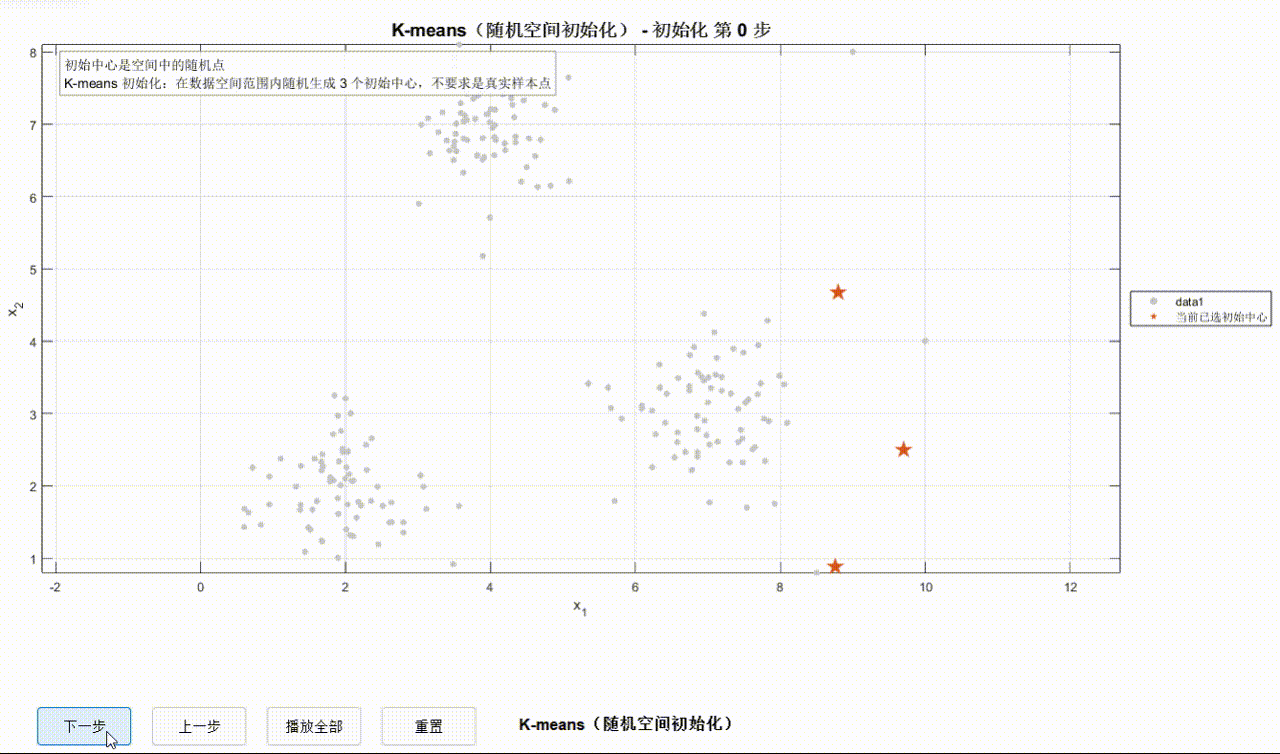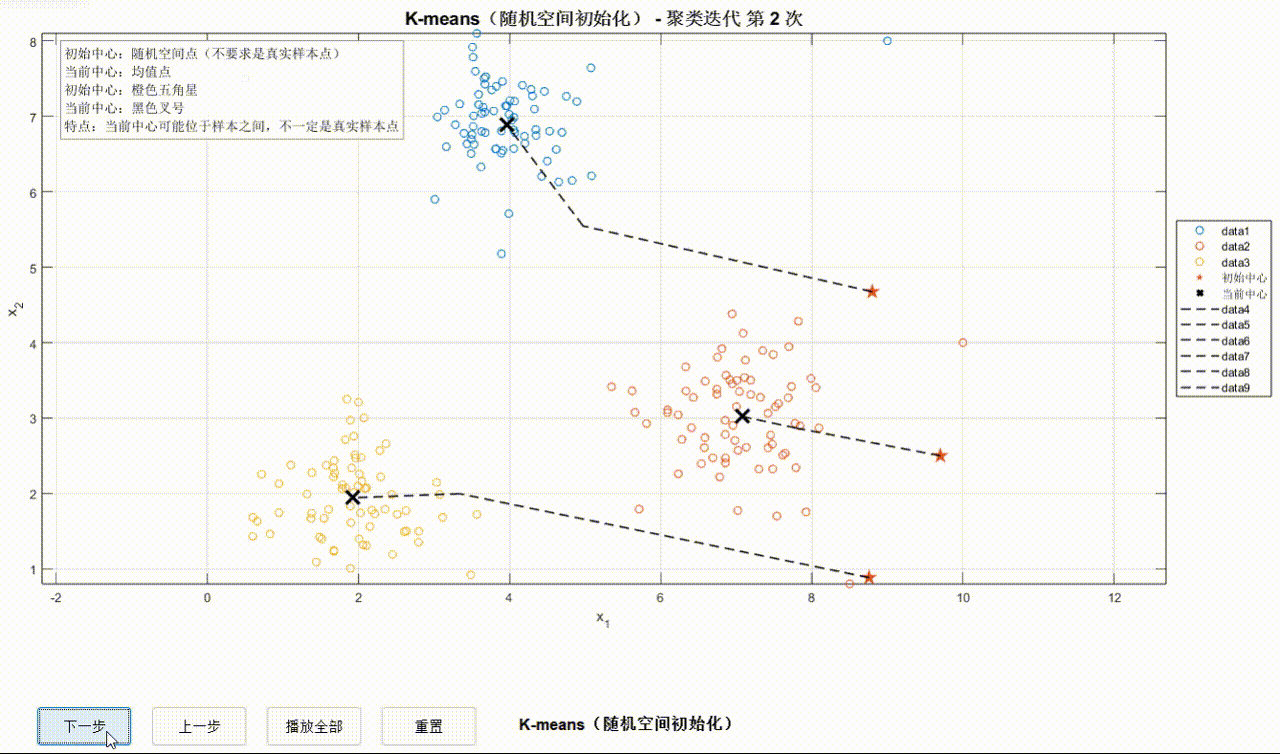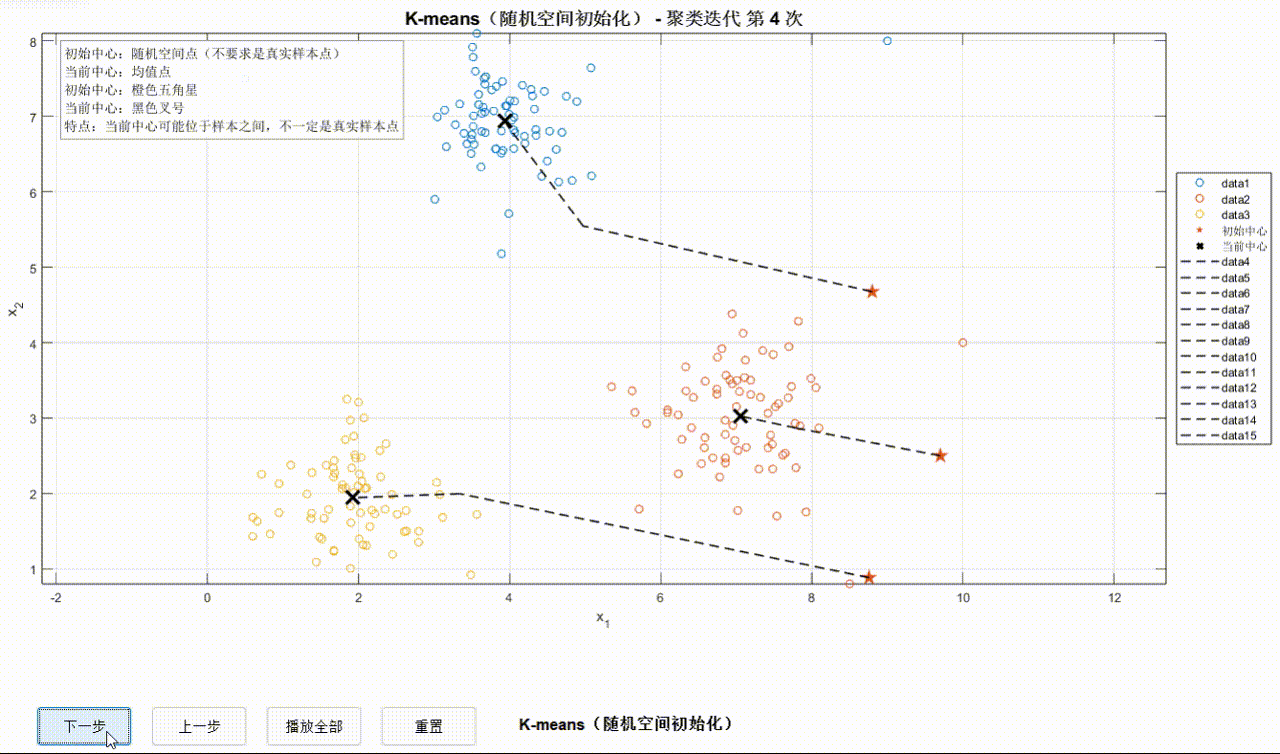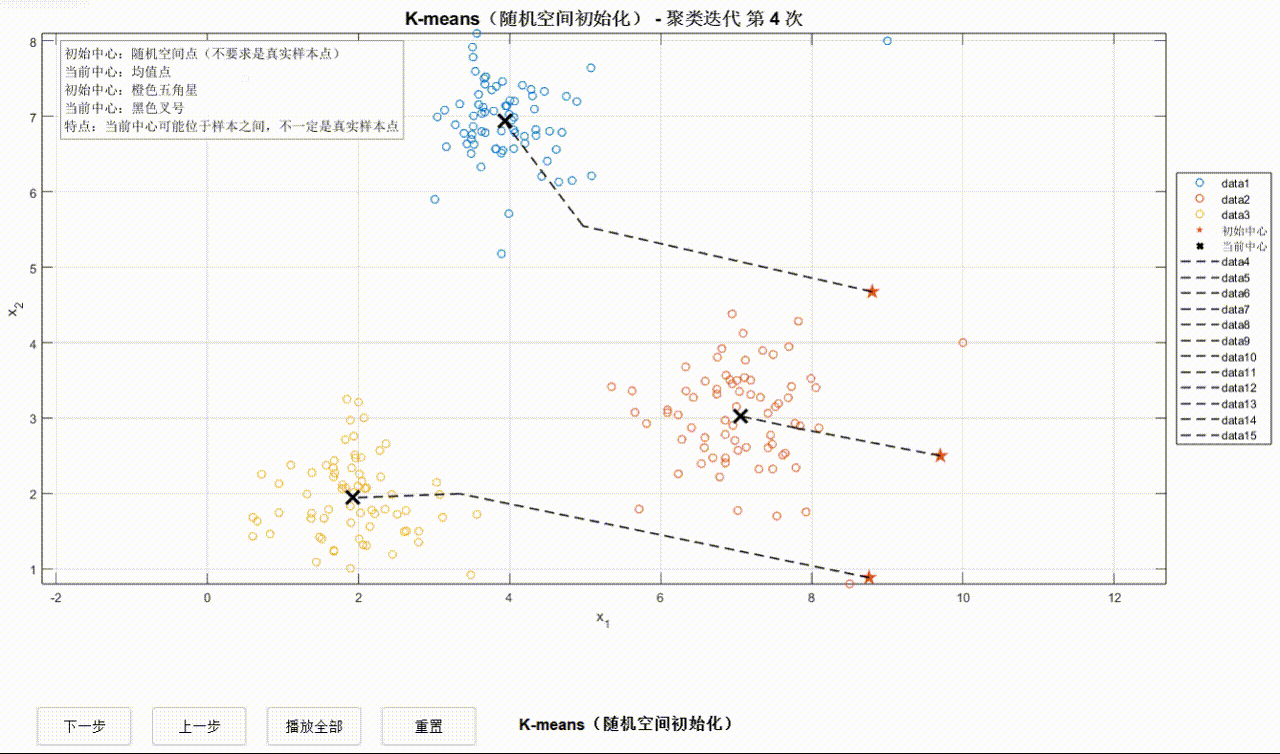
为了方便观察迭代过程,可以在可视化界面手动/自动观察迭代步,迭代过程轨迹用黑色虚线表示。首先初始化初始中心点,之后开始迭代。迭代开始时,数据点变为空心圆并赋予不同颜色用来区分不同簇。
①K-Means迭代过程:
②K-means++迭代过程
③K-Medoids迭代过程
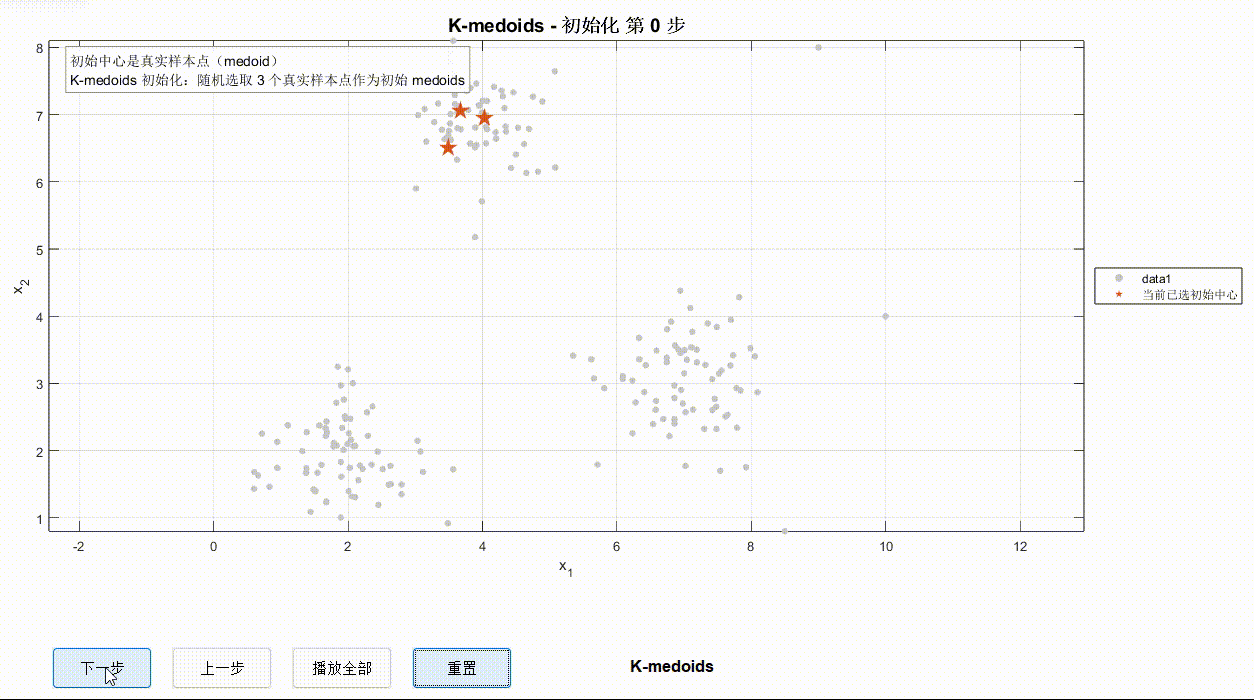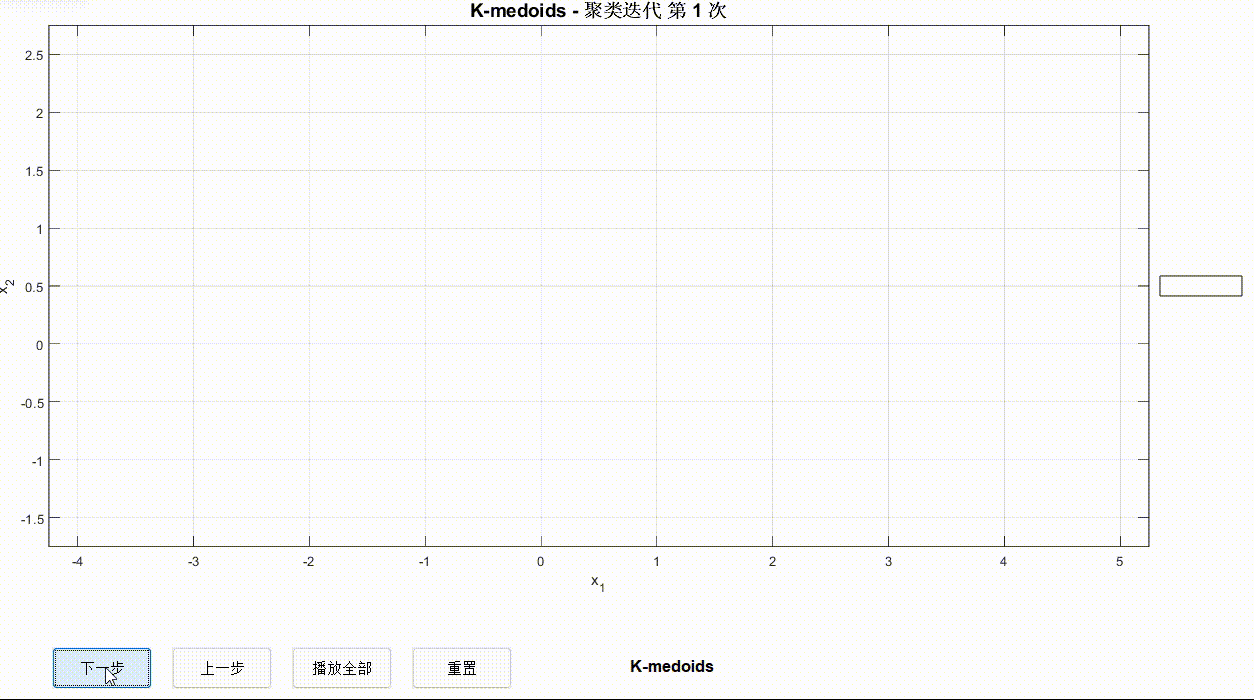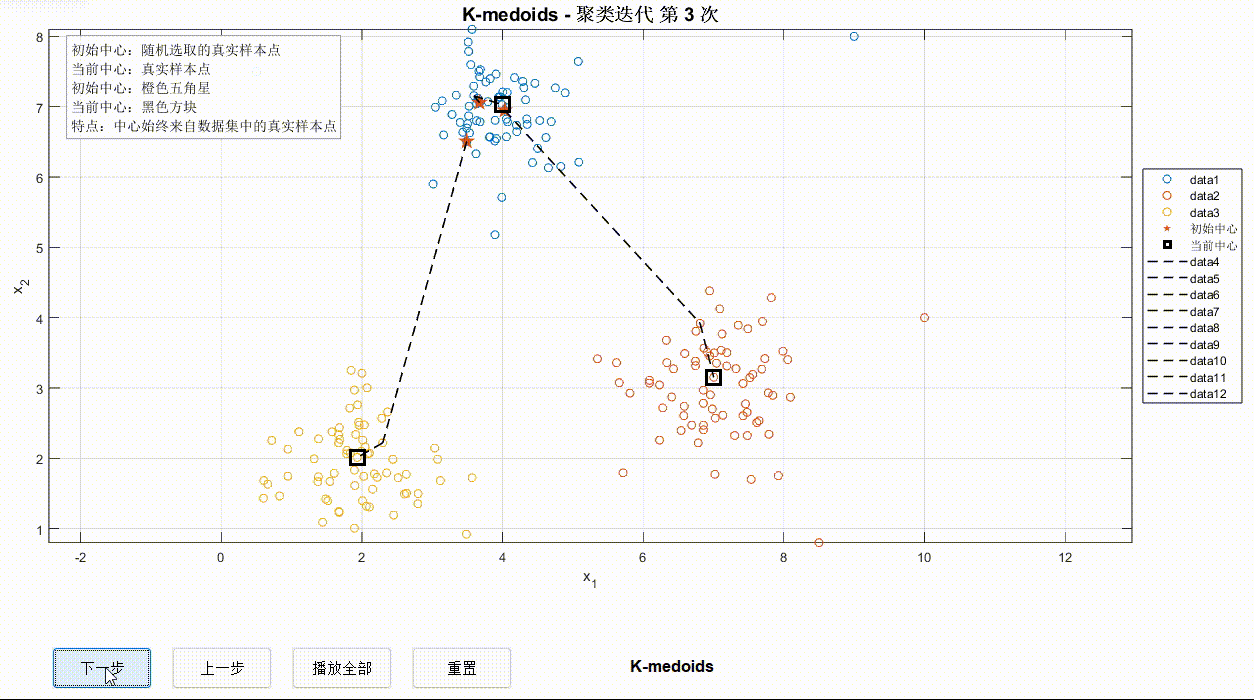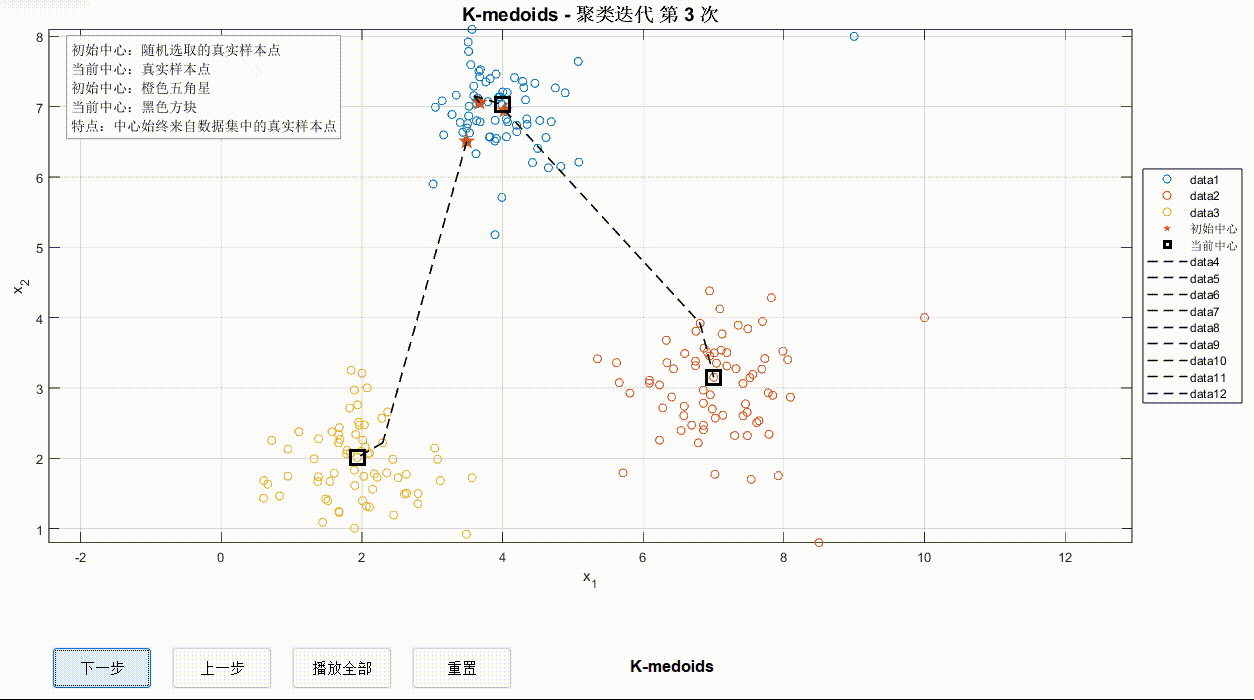
对比以上三种算法可以看出,同样的数据点迭代情况可能有所不同,但使用哪一种并不绝对,还要考虑算力、数据点情况等。希望这一案例对于深入学习算法有所启发~
六、总结
以上总结了聚类算法基本原理、概念及K-Means、K-Means++与K-Medoids三种聚类算法的基本思路与优势缺点等,结合代码原理展示了K值的选择、算法的迭代过程等。总结来看,K-Means++ 算法作为 K-Means 算法的重要改进版本,通过优化初始簇中心的选择策略,有效提升了聚类的稳定性和准确性。而当数据存在离群点时,使用K-Medoids可能鲁棒性更好。在工程实践中我们应基于数据规模、数据质量等灵活选用聚类算法。
本文参考来源:机器学习 K-Means(++)算法、聚类分析算法------K-means聚类 详解、【聚类算法】K-means++算法、数据挖掘------PAM(K-Medoids)聚类算法学习、K-Means及K-Means++算法Python源码实现
注:本文以学习交流为目的,如有侵权请联系~