最近在刷 GitHub 的时候发现了一个叫 Flocks 的项目,自称 "AI-Native SecOps Platform"。坦白说,刚开始看到这个定位我是不以为意的------市面上打着 AI + Security 旗号的项目太多了,大部分不过是拿 GPT 包装一下告警分析。但翻完它的源码之后,我改变了看法。
这个项目的设计思路和我见过的任何 "AI 安全助手" 都不一样。它不是简单地调 API 做对话,而是从底层构建了一套完整的多智能体协作体系,把安全运营中的各种环节------从威胁研判到应急响应------都拆解成可编排的 Agent 工作流。
今天这篇文章,我会从架构设计、核心模块、技术实现三个层面,把 Flocks 拆开来看,聊聊它的设计取舍和技术细节。
先聊聊它到底想解决什么问题
做安全运营(SecOps)的同行应该深有体会,日常工作中有大量重复性的、需要多工具联动的场景:
收到一条告警 → 上威胁情报平台查 IOC → 跳到 EDR 看进程行为 → 去 SIEM 拉关联日志 → 写研判结论 → 开工单处置
这个过程涉及 5-6 个不同系统,每个系统有自己的 API、认证方式、数据格式。就算你写好了自动化脚本,一旦告警类型变了、处置流程调整了,脚本又要改。更别提那些需要"人肉判断"的环节------比如一条告警到底是真威胁还是误报,很多时候得靠经验。
Flocks 的核心思路是:把这些环节都交给 Agent,但不是交给一个万能的 Agent,而是交给一群各司其职的 Agent,通过编排让它们协同工作。
这个想法本身并不新鲜,AutoGen、CrewAI 这些框架也都在做多智能体协作。但 Flocks 的不同之处在于,它是面向安全运营场景深度定制的,不是通用的 Agent 编排框架。这意味着它的工具集、工作流引擎、会话管理都是为 SecOps 场景设计的。
整体架构一览
先把项目结构铺开看。Flocks 的后端是纯 Python 实现,核心包 flocks/ 下面有 27 个子模块:
bash
flocks/
├── agent/ # Agent 核心:基类、工厂、注册表、工具集
├── bus/ # 事件总线:组件间通信
├── channel/ # 渠道网关:企业微信、飞书等 IM 接入
├── cli/ # 命令行工具
├── command/ # 命令解析
├── config/ # 配置管理
├── hooks/ # 钩子系统
├── lsp/ # Language Server Protocol
├── mcp/ # Model Context Protocol
├── memory/ # 记忆系统
├── permission/ # 权限控制
├── plugin/ # 插件系统
├── project/ # 项目管理
├── provider/ # LLM 提供商抽象层
├── pty/ # 伪终端
├── sandbox/ # 沙箱执行
├── security/ # 安全模块
├── server/ # HTTP 服务(FastAPI)
├── session/ # 会话管理
├── skill/ # 技能系统
├── snapshot/ # 快照管理
├── storage/ # 存储层
├── task/ # 任务调度
├── tool/ # 工具系统
├── updater/ # 自动更新
├── utils/ # 工具函数
├── workflow/ # 工作流引擎
└── workspace/ # 工作空间管理前端 webui/ 是一个独立的 React 项目,用 Vite 构建,TypeScript + Tailwind CSS 技术栈。
下面这张架构图把 27 个模块按职责分层,可以直观地看到系统全貌:
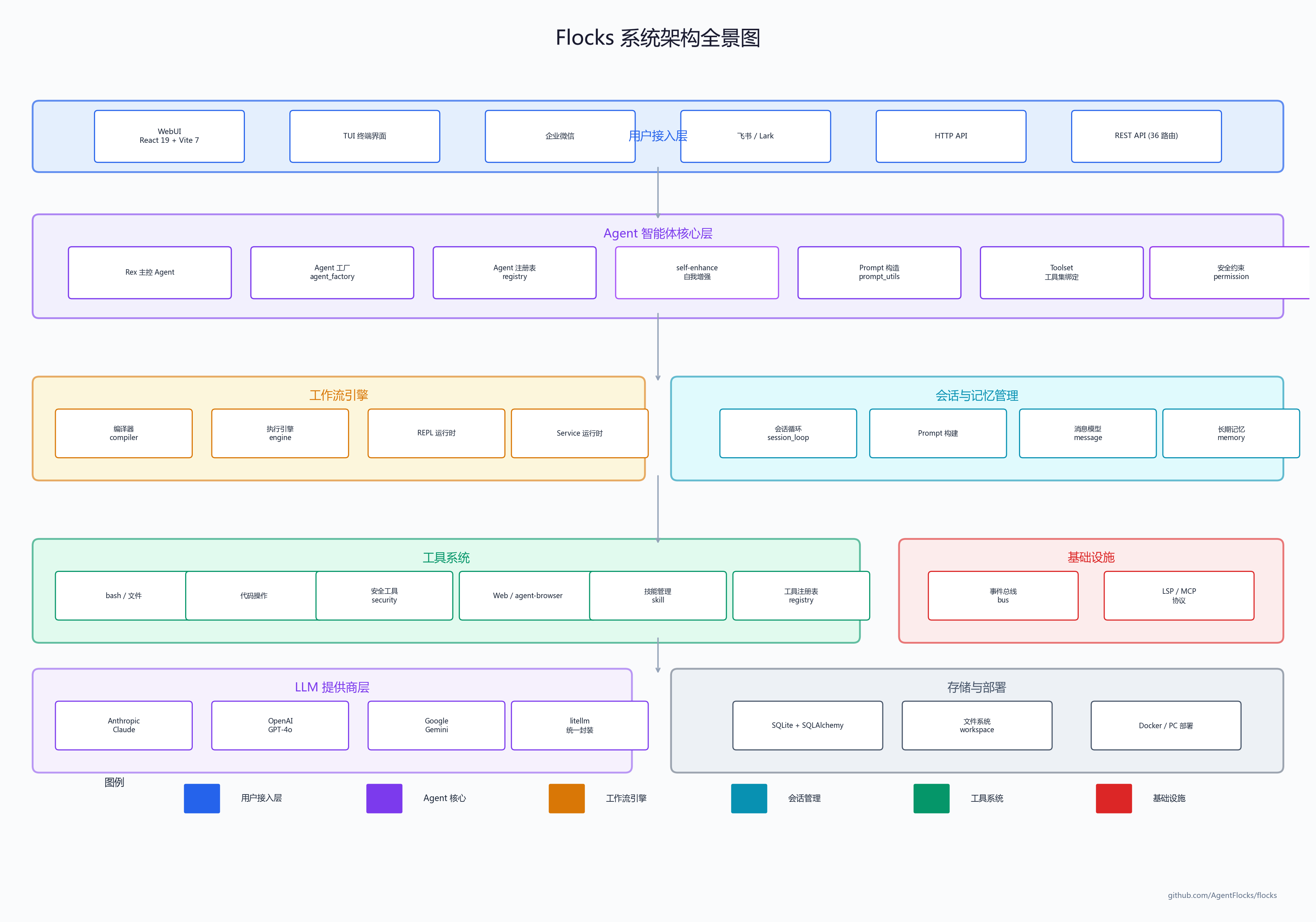
光看这个目录结构就知道,这不是一个 demo 级别的项目。27 个模块涵盖了 Agent 运行时的方方面面。我重点拆几个核心模块。
Agent 系统:不只是调 API
很多 AI 项目的 "Agent" 本质上就是一个 function calling 的循环:LLM 决定调哪个函数 → 执行 → 把结果喂回 LLM → 继续循环。Flocks 的 Agent 系统比这个复杂得多。
先看 agent/ 目录下的结构:
-
agent.py:Agent 基类,定义了 Agent 的生命周期和行为规范 -
agent_factory.py:Agent 工厂,负责创建不同类型的 Agent 实例 -
registry.py:Agent 注册表,维护可用 Agent 的清单 -
toolset.py:工具集绑定,每个 Agent 可以挂载不同的工具组合 -
prompt_utils.py:Prompt 构造工具,处理系统提示词的组装 -
constants.py:Agent 相关常量定义
这里面最有意思的是 Agent 工厂 + 注册表 的设计模式。Flocks 不是硬编码几种 Agent 类型,而是通过注册表机制让 Agent 类型可扩展。你可以注册一个新的 Agent 类型,定义它有哪些工具、什么系统提示词、什么行为约束,然后工作流引擎就能直接调度它。
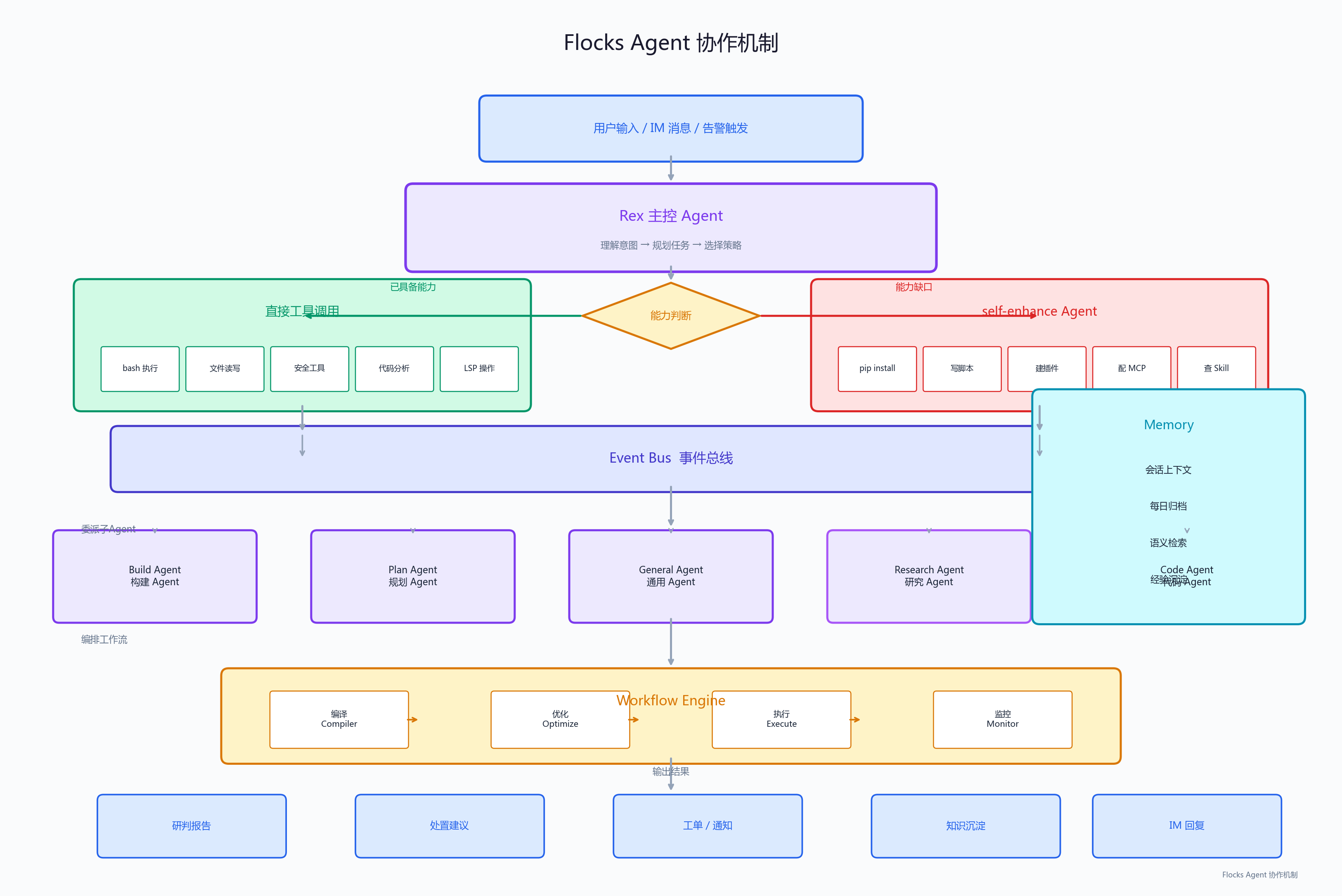
从 AGENTS.md 文档来看,系统内置了一个叫 Rex 的主 Agent(类似一个安全运营总指挥),它可以把任务委派给不同类型的子 Agent,比如 self-enhance(自我增强 Agent,负责在遇到能力缺口时自动安装工具包或创建新插件)。
这里有一个我特别欣赏的设计------Capability Gap Resolution Protocol(能力缺口解决协议)。当 Rex 遇到自己搞不定的任务时,它不会直接告诉用户"我做不了",而是触发一套标准化的流程:
-
先自查------能不能用 bash + Python 标准库搞定?
-
查技能库------有没有现成的 skill 可以安装?
-
委派给
self-enhanceAgent------让它去装包、写脚本、建插件 -
实在不行才告知用户
这个设计非常务实。做安全运营的人都知道,不可能提前预判所有需要的能力。让 Agent 具备"自我进化"的能力,远比穷举工具列表靠谱。
整个 Agent 协作机制可以用下面这张图来概括------从用户输入到最终输出,中间经历了能力判断、工具调用/自我增强、事件总线广播、子 Agent 委派、工作流编排等多个环节:
工具系统:安全工程师的数字工具箱
tool/ 是整个项目里子模块最多的包,足足有 7 个子目录:
bash
tool/
├── agent/ # Agent 相关工具(委派任务等)
├── channel/ # 渠道工具
├── code/ # 代码操作工具
├── file/ # 文件操作工具
├── security/ # 安全专用工具
├── skill/ # 技能管理工具
├── system/ # 系级工具
├── task/ # 任务管理工具
├── web/ # Web 操作工具
└── wecom/ # 企业微信工具注意那个 security/ 目录------这是 Flocks 区别于通用 Agent 框架的关键。通用框架的工具集是面向开发者的(读文件、写代码、跑命令),而 Flocks 专门内置了安全领域的工具。虽然具体的工具实现细节在闭源的 skills 里(项目支持外部 skill 安装),但从 AGENTS.md 可以看到,它对 TDP、OneSec、SkyEye、青藤等国内主流安全产品都做了适配。
另一个值得关注的点是 tool/catalog.py 和 tool/registry.py。Flocks 用了一个工具注册表来管理所有可用工具,每个工具都有明确的 schema 定义(输入参数、输出格式、权限要求)。Agent 在选择工具时,不是从一大堆函数里随机挑,而是通过注册表做结构化查询。
tool/tool_loader.py 负责动态加载工具------这意味着你可以不修改核心代码,通过插件机制添加新工具。结合 self-enhance Agent 的能力,系统甚至可以在运行时自动发现并安装缺失的工具。
工作流引擎:不只是 DAG
workflow/ 目录包含 19 个文件,是除 server/routes 之外最大的模块之一:
bash
workflow/
├── center.py # 工作流中心(调度器)
├── compiler.py # 工作流编译器
├── engine.py # 执行引擎
├── runner.py # 运行器
├── models.py # 数据模型
├── code_gen.py # 代码生成
├── repl_runtime.py # REPL 运行时
├── service_runtime.py # 服务运行时
├── tools.py # 工作流内置工具
├── tools_adapter.py # 工具适配层
├── tools_spec.py # 工具规格定义
├── requirements.py # 依赖检查
├── workflow_lint.py # 工作流静态检查
├── fs_store.py # 文件系统存储
└── errors.py # 错误处理这里有几个有意思的设计:
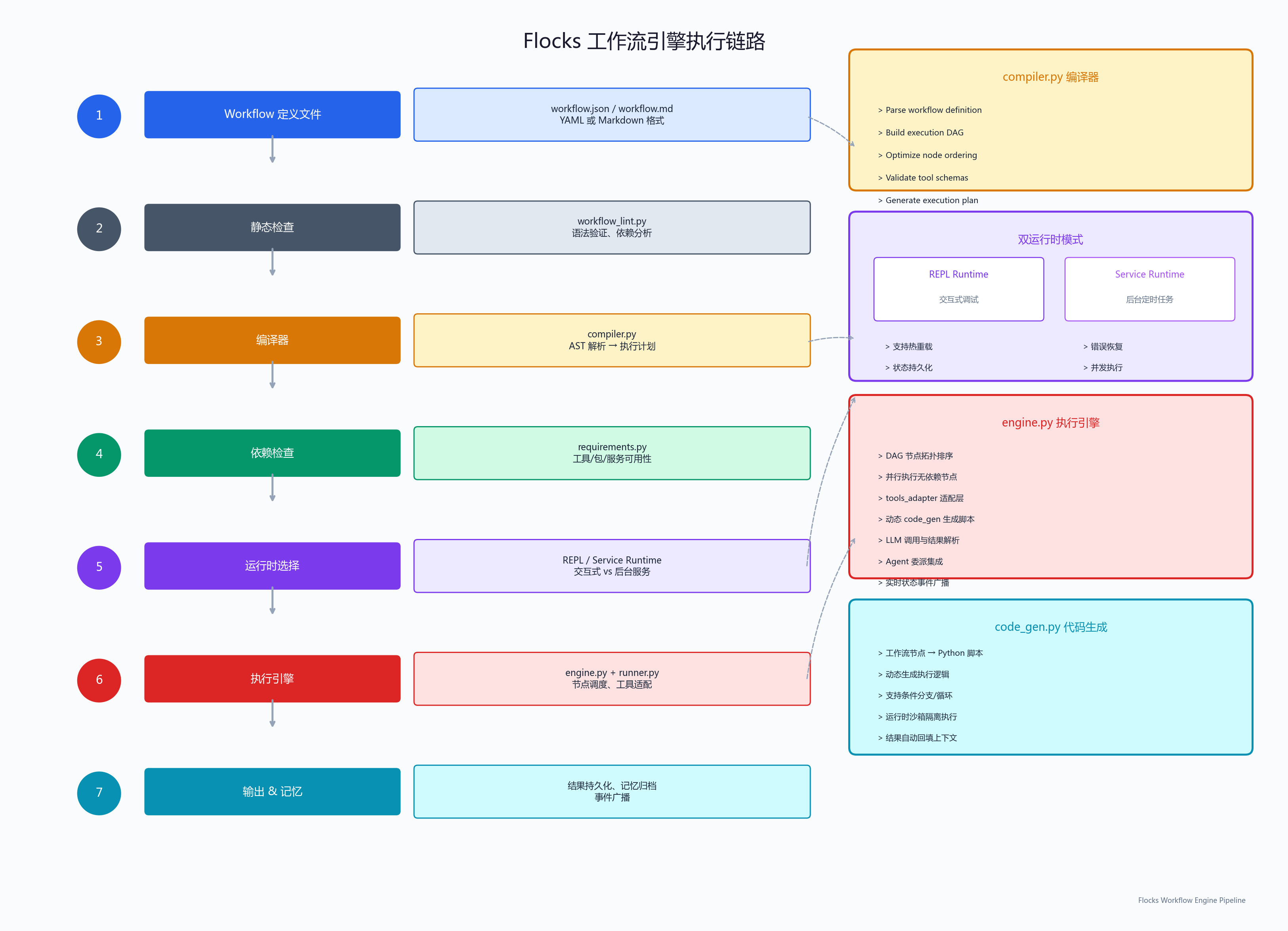
编译器(compiler.py) :Flocks 的工作流不是简单的 JSON DAG,而是经过"编译"的。这意味着你写的 workflow 定义文件会先经过语法检查、依赖分析、优化,然后生成可执行的执行计划。workflow_lint.py 提供静态检查能力,在执行前就能发现潜在问题。
双运行时 :repl_runtime.py 和 service_runtime.py 分别对应交互式执行和后台服务执行两种模式。交互模式适合开发调试,服务模式适合生产部署------比如定时跑安全巡检任务。
代码生成(code_gen.py):工作流引擎还集成了代码生成能力。这意味着某些场景下,工作流可以动态生成 Python 脚本来执行复杂逻辑,而不是仅仅串联预定义的步骤。
整条工作流的执行链路,从定义文件到最终输出,中间经历了 7 个阶段。下面这张图展示了完整的 Pipeline,右侧还标注了编译器、双运行时、执行引擎、代码生成等关键模块的内部细节:
会话管理:Agent 的"工作记忆"
session/ 模块是 Agent 和用户交互的核心:
bash
session/
├── session.py # 会话模型
├── session_loop.py # 主事件循环
├── runner.py # 会话执行器
├── prompt.py # Prompt 构造
├── prompt_strings.py # Prompt 模板
├── message.py # 消息模型
├── recorder.py # 会话记录
├── callable_schema.py # 可调用接口 Schema
└── callable_state.py # 调用状态追踪session_loop.py 是整个系统的心脏------它实现了 Agent 的主循环:接收用户输入 → 构造 Prompt(包含系统提示词、历史消息、工具定义)→ 调用 LLM → 解析响应(可能是文本回复,也可能是工具调用)→ 执行工具 → 把结果追加到上下文 → 继续循环。
这里有一个关键设计:会话和工作流是分离的 。会话负责"对话"层面的状态管理(上下文窗口、历史记录、用户偏好),工作流负责"任务"层面的执行编排。两者通过事件总线(bus/)解耦。这意味着一个长时间运行的工作流可以独立于用户对话存在------你可以发一条消息启动一个安全巡检工作流,然后关掉浏览器,工作流会在后台继续跑。
多模型支持:不绑定单一厂商
provider/ 模块实现了 LLM 提供商的抽象层:
bash
provider/
├── provider.py # 提供商基类
├── model_manager.py # 模型管理器
├── model_catalog.py # 模型目录
├── catalog.json # 模型配置
├── credential.py # 凭证管理
├── cost_calculator.py # 成本计算
├── usage_service.py # 用量追踪
├── options.py # 配置选项
├── types.py # 类型定义
└── sdk/ # 各厂商 SDK 适配从 pyproject.toml 的依赖可以看到,Flocks 同时支持 Anthropic、OpenAI、Google 三家模型,而且通过 litellm 做了统一封装。cost_calculator.py 和 usage_service.py 说明它还内置了 token 用量追踪和成本计算------这对企业用户来说非常实用,毕竟安全运营场景下 Agent 可能需要处理大量日志,token 消耗不可忽视。
catalog.json 维护了一个模型目录,定义了每个模型的能力(是否支持 function calling、上下文窗口大小、最大输出 token 等)。上层代码不需要关心具体用哪个模型,只需要声明"我需要一个支持工具调用的模型",由 model_manager 根据配置和预算自动选择。
事件总线:系统的神经网络
bus/ 目录只有 4 个文件,但它可能是整个架构中最重要的基础设施之一:
bash
bus/
├── bus.py # 事件总线核心
├── bus_event.py # 事件定义
└── events.py # 事件常量所有模块间的异步通信都通过事件总线进行。Agent 执行完了任务,发一个事件;工作流状态变了,发一个事件;新工具安装好了,发一个事件。其他模块订阅自己感兴趣的事件,做相应的处理。
这种设计的好处是模块间完全解耦。你可以替换整个前端实现,只要它订阅同样的事件就行;你可以加一个新的通知渠道(比如钉钉),只需要写一个事件订阅者,不需要改动核心逻辑。
从 server 端的 event_router 可以看到,Flocks 通过 SSE(Server-Sent Events)把事件推送到前端,实现实时状态更新。
记忆系统:让 Agent "记住"之前干过什么
memory/ 模块实现了 Agent 的长期记忆:
bash
memory/
├── manager.py # 记忆管理器
├── bootstrap.py # 记忆初始化
├── config.py # 配置
├── daily.py # 每日记忆归档
├── flush.py # 记忆刷写
├── types.py # 类型定义
├── search/ # 记忆检索
└── sync/ # 记忆同步LLM 的上下文窗口是有限的,不可能把所有历史对话都塞进去。Flocks 的记忆系统解决这个问题的方式是:把重要的信息从对话上下文中提取出来,持久化存储,在需要的时候通过检索召回。
daily.py 实现了按日归档------每天的对话结束后,系统会自动总结当天的关键信息,压缩存储。search/ 提供了语义检索能力,Agent 可以根据当前任务的需求,从历史记忆中找到相关的上下文。
这比简单的"保留最近 N 轮对话"高明得多。想象一下:你上周让 Agent 分析过一批恶意样本,这周又来了类似的样本,Agent 可以直接从记忆中调出上次的分析思路和结论,而不是从头来过。
HTTP 服务:36 个路由模块的 API 体系
server/routes/ 目录有 36 个路由文件,覆盖了系统功能的方方面面。FastAPI 作为后端框架,提供了自动 OpenAPI 文档、请求验证、异步支持等开箱即用的能力。
几个值得关注的路由:
-
/api/session:会话管理,创建、删除、切换会话 -
/api/agent:Agent 管理,查看 Agent 状态、可用工具 -
/api/tools:工具管理,注册、查询、执行工具 -
/api/workflow:工作流 CRUD 和执行 -
/api/mcp:MCP(Model Context Protocol)服务器管理 -
/api/channel:IM 渠道管理 -
/api/event:SSE 事件推送 -
/api/usage:用量和成本查询
服务启动时有一套完整的初始化流程:日志初始化 → 存储初始化 → 配置文件检查 → MCP 服务器连接 → 工作流同步 → 任务调度器启动 → 文件监控启动 → 渠道网关启动。关闭时也有对应的优雅退出流程,包括等待繁忙会话完成、关闭 MCP 连接、释放所有资源。
前端:React 19 + Vite 7 的现代化实现
WebUI 用的技术栈相当新:React 19、TypeScript 5.9、Vite 7、Tailwind CSS 3。
几个关键依赖值得注意:
-
@xyflow/react:这是一个流程图/节点编辑器库。结合工作流引擎来看,前端很可能有可视化的工作流编排界面------拖拽节点、连线、配置参数,所见即所得。 -
zustand:轻量级状态管理。比 Redux 简洁,比 Context 性能好,适合中等复杂度的前端应用。 -
recharts:图表库。用在用量统计、成本分析等数据可视化场景。 -
i18next:国际化支持。从项目同时维护英文和中文 README 来看,国际化是认真做的。 -
react-markdown+rehype-highlight+remark-gfm:Markdown 渲染,支持语法高亮和 GitHub 风格扩展。Agent 的回复通常包含代码块、表格等富文本内容,这套渲染管线是必要的。
MCP 和 LSP:两个关键的协议集成
Flocks 集成了两个重要的协议:
MCP(Model Context Protocol) 是 Anthropic 提出的标准协议,定义了 AI 模型如何与外部工具和数据源交互。Flocks 不仅是 MCP 的客户端(连接外部 MCP 服务器获取工具),还自己充当 MCP 服务器(把 Flocks 的工具暴露给其他 AI 应用)。这个双向设计很有远见。
LSP(Language Server Protocol) 是微软提出的代码智能协议,提供代码补全、跳转定义、查找引用等功能。在 SecOps 场景下,Agent 需要分析和编写脚本(Python、Shell 等),LSP 集成让 Agent 具备了代码级别的理解能力,而不只是把代码当作纯文本处理。
安全设计:SecOps 平台的自我修养
作为一个安全运营平台,Flocks 自身的安全性设计也值得说说:
-
permission/:权限控制模块,定义了 Agent 可以执行哪些操作 -
sandbox/:沙箱执行环境,Agent 执行的代码在隔离环境中运行 -
security/:安全策略模块 -
acp/:Access Control Protocol,访问控制协议
从 AGENTS.md 的安全约束表可以看到一些具体规则:允许在项目虚拟环境中安装 PyPI 包,禁止 sudo 提权;允许写脚本到 /tmp,禁止下载二进制文件;允许创建插件,禁止修改系统 Python。这些约束确保了 Agent 即使被恶意 prompt 注入,也不会造成系统级别的破坏。
渠道网关:企业 IM 深度集成
channel/ 模块和 tool/wecom/ 目录表明 Flocks 对企业即时通讯做了深度集成。从依赖可以看到:
-
wecom-aibot-sdk:企业微信 AI 机器人 SDK(WebSocket 长连接) -
lark-oapi:飞书/Lark SDK(WebSocket 长连接 + Open API)
这意味着你可以直接在企业微信或飞书群里 @Flocks,让它执行安全运营任务------查一个 IP 的情报、拉一份报告、触发一个工作流。不需要切换到单独的 WebUI,在工作群里就能完成大部分操作。
一键部署体验
Flocks 的安装方式做得比较省心:
PC 安装:一条 curl 命令(macOS/Linux)或一条 PowerShell 命令(Windows),自动处理所有依赖。对国内用户还有镜像加速方案。
Docker 安装 :docker pull + docker run 两步搞定,挂载 ~/.flocks 目录做持久化。
CLI 管理 :安装完成后通过 flocks 命令管理整个服务生命周期------start、stop、restart、status、logs。后端 API 默认跑在 127.0.0.1:8000,WebUI 在 127.0.0.1:5173,支持远程访问配置。
几个值得讨论的设计取舍
分析了这么多,聊聊我观察到的一些设计取舍:
Python 3.12 限定:Flocks 要求 Python 3.12,不用 3.13 也不用 3.11。这是一个大胆的选择。好处是可以用最新的语法特性(比如更好的类型提示、性能优化),代价是部署环境要求更高。对于一个 AI 工具来说,我觉得这个选择是合理的------目标用户通常是专业安全团队,环境控制能力较强。
事件总线而非消息队列:Flocks 用的是进程内事件总线,不是 Redis/RabbitMQ 这样的外部消息队列。这意味着它目前是单进程架构。对于安全运营场景来说,单进程通常够用(毕竟 IO 密集型任务通过异步处理了),但如果需要横向扩展,这个设计会成为瓶颈。
前后端分离但单体部署 :FastAPI 后端和 React 前端是分开的代码仓库(在同一个 Git 仓库的不同目录),但部署时通过 flocks start 一键启动。这种"开发时分离、部署时一体"的方式对用户体验很友好,但对开发者来说需要维护两套构建工具链。
闭源 skills + 开源平台:核心平台是 Apache 2.0 开源的,但安全领域的专业 skills(TDP、OneSec、SkyEye、青藤等)可能是闭源的。这是一个务实的商业化策略------平台免费引流,专业能力付费。
适用场景
综合来看,Flocks 适合以下场景:
-
安全运营团队日常提效:把重复性的研判、报告、工单工作交给 Agent
-
安全事件应急响应:通过工作流编排,实现标准化的处置流程
-
安全合规巡检:定时触发巡检任务,自动汇总结果
-
安全知识沉淀:利用记忆系统,把团队的经验积累成可检索的知识库
-
多平台告警聚合分析:通过 MCP 连接多个安全产品,统一分析
写在最后
Flocks 让我看到了 Multi-Agent 在垂直领域落地的可能性。它不是在做一个"万能 AI 助手",而是在认真地解决安全运营中的具体问题。从事件总线到工作流引擎,从记忆系统到自我增强机制,每个设计决策背后都能看到对 SecOps 场景的深入理解。
当然,作为一个还在 Alpha 阶段的项目(从 pyproject.toml 的 classifiers 可以看到),它在文档完善度、测试覆盖率、生产稳定性方面还有提升空间。但架构设计的完整度和工程实现的成熟度,已经远超大部分同类项目了。
如果你在做安全运营自动化,或者对 Multi-Agent 在垂直领域的落地感兴趣,这个项目值得你花时间深入研究。
项目地址 :https://github.com/AgentFlocks/flocks
最后放一张技术栈全景图。左边是 Flocks 与通用 AI 助手的能力对比雷达图,右边是项目工程化数据和技术栈分层概览:
技术栈速览:
| 层面 | 技术选型 |
|---|---|
| 后端 | Python 3.12 + FastAPI + Uvicorn |
| LLM | Anthropic / OpenAI / Google (via litellm) |
| 前端 | React 19 + TypeScript + Vite 7 + Tailwind CSS |
| 状态管理 | Zustand |
| 可视化 | @xyflow/react + Recharts |
| 国际化 | i18next |
| 存储 | SQLite (aiosqlite) + SQLAlchemy |
| 协议 | MCP + LSP + SSE + WebSocket |
| IM 集成 | 企业微信 + 飞书 + 钉钉 |
| 部署 | PC 安装 / Docker |