一、引言:AI 从"问答机"到"自主代理"的跃变
早期的大语言模型(LLM)就像一个超级问答机------你问,它答,交互止步于此。然而 2022 年之后,一类新的 AI 使用范式开始兴起:让 LLM 不仅能"想",还能"做"。
这一范式被称为 Agentic LLM(智能体化大语言模型),其核心思想是:给模型配备工具、赋予它执行计划的能力,让它自主地完成多步骤任务------就像一个真正的"助理",而不是被动的"搜索引擎"。
在这一演进中,ReAct 是最具代表性、影响力最大的技术框架之一。本文将从 ReAct 出发,系统讲解 LLM Agent 体系的核心概念,包括:
● ReAct:推理与行动的交织
● Tool Use(工具调用):Agent 的"手"
● Harness(测试框架):确保 Agent 按规则行动
● Spec-Driven(规范驱动):用规范约束 Agent 行为
● 以及其他相关概念
二、ReAct:思考与行动的统一范式
2.1 背景:两条独立的路
在 ReAct 出现之前,研究者们主要沿着两条路发展 LLM 能力:
路线一:Chain-of-Thought(CoT,思维链)
让模型在回答前先写出推理步骤,就像做数学题时先列过程再给答案。这显著提升了模型的逻辑推理能力,但它是纯粹"在脑子里想",没有与外部世界交互。
路线二:Action Generation(行动生成)
让模型直接生成行动序列(如搜索关键词、点击按钮),直接"做事"。但这种方式缺乏显式推理,模型容易"行动过头"------不知道为什么做,只是机械执行。
2.2 ReAct 的核心思想:交织推理与行动
2022 年,Yao 等人在论文《ReAct: Synergizing Reasoning and Acting in Language Models》(arXiv:2210.03629)中提出了 ReAct 框架。
ReAct = Reasoning(推理)+ Acting(行动),两者交替进行、相互增强。
其运行方式如下(以一个回答问题的 Agent 为例):
Thought: 我需要查一下这个人的出生年份
Action: Search"某某人物"
Observation: 某某生于1985年,是...
Thought: 好,现在我知道出生年份了,还需要计算年龄
Action: Calculator"2026 - 1985"
Observation: 41
Thought: 已经有足够信息了
Action: Finish"该人物今年41岁"
这里有三个关键元素:
● Thought(思考):模型的内心独白,分析当前情况,规划下一步
● Action(行动):调用外部工具,如搜索引擎、计算器、API
● Observation(观察):工具返回的结果,作为下一轮思考的输入
这个循环不断迭代,直到任务完成。
2.3 为什么 ReAct 有效?
ReAct 的强大之处在于:
- 思考为行动导航:Thought 步骤让模型在行动前先理清思路,避免盲目操作
- 行动更新知识:每次 Observation 为模型提供新信息,更新其对世界的认知
- 错误可以被发现和纠正:如果某个行动结果出乎意料,模型可以在 Thought 中调整策略
- 可解释性强:整个推理-行动过程是透明的,人类可以审查
实验证明,在知识密集型任务(如 HotpotQA 多跳问答)和决策型任务(如 ALFWorld 家庭环境操作)中,ReAct 都显著优于纯 CoT 或纯行动方法。
三、Tool Use(工具调用):给 LLM 装上"手"
3.1 什么是 Tool Use?
ReAct 框架里的 Action 步骤,本质上就是调用工具。Tool Use(工具调用)是 LLM Agentic 范式的核心能力之一。
工具可以是任何外部能力:
● 搜索引擎:Google、Bing,让模型能获取最新信息
● 计算器:精确处理数学运算(LLM 本身做数学经常出错)
● 代码执行器:运行 Python/JS 代码,处理数据、操作文件
● API 接口:天气、股票、地图、日历、邮件...几乎任何服务
● 数据库查询:SQL 查询、向量搜索
● 浏览器控制:截图、点击、填表单
3.2 Function Calling:工具调用的标准化
工具调用的标准化形式是 Function Calling(函数调用),由 OpenAI 于 2023 年引入并广泛采用。
其工作原理如下:
- 定义工具:用结构化格式(JSON Schema)描述工具的名称、功能和参数
csharp
{
"name": "get_weather",
"description": "获取指定城市的当前天气",
"parameters": {
"city": {"type": "string", "description": "城市名称"}
}
}- 模型决策:LLM 看到工具定义和用户请求,决定是否调用工具以及传入什么参数
csharp
{"tool": "get_weather", "arguments": {"city": "深圳"}}- 执行并返回结果:程序执行工具,将结果返回给 LLM 继续处理
这个流程将 LLM 的"语言理解和决策能力"与"外部系统的执行能力"优雅地结合在一起。
3.3 工具调用的挑战
工具调用看似简单,实际上有很多难点:
● 工具选择:当有几十个工具时,模型如何选对工具?
● 参数填写:模型可能填错参数类型或遗漏必要字段
● 错误处理:工具调用失败时,模型能否理解错误信息并重试?
● 多工具协同:复杂任务需要按正确顺序调用多个工具
研究表明(arXiv:2401.07324),小参数量的 LLM 在工具调用方面相比大模型明显弱,这促使了多模型协同(Multi-LLM)架构的出现------用专门的小模型负责工具调用,大模型负责整体推理。
四、Harness(测试框架):让 Agent 行为可约束、可测量
4.1 什么是 Harness?
"Harness"字面意思是"驾具"(套在马身上控制方向的装置)。在 LLM Agent 领域,Harness 是一套围绕 Agent 构建的约束、测试和评估框架。
当 LLM 作为 Agent 运行时,它可能做出"违规"操作------比如在国际象棋比赛中走出非法棋步(arXiv:2603.03329 指出,Gemini-2.5-Flash 78% 的失败都是因为非法棋步),或在生产环境中误删数据。Harness 就是为了解决这类问题而设计的。
4.2 Harness 的核心组成
一个完整的 Agent Harness 通常包含:
(1)环境模拟层(Environment Simulator)
● 模拟 Agent 要操作的真实环境(网页、文件系统、API 等)
● 提供沙箱隔离,让 Agent 的危险操作不影响真实系统
● 记录 Agent 的所有操作日志
(2)动作约束层(Action Constraints)
● 定义哪些操作是合法的(Action Space)
● 在 Agent 尝试非法操作时立即拦截并返回错误
● 例如:棋类游戏 Harness 会检验棋步是否合规
(3)评估指标层(Evaluation Metrics)
● 任务完成率
● 操作效率(步骤数)
● 安全性(有无危险操作)
● 可信度(行动是否符合预期逻辑)
(4)基准测试(Benchmarks)
● 标准化的任务集,用于横向比较不同 Agent 的性能
● 常见基准:ALFWorld、WebArena、AgentBench、SWE-Bench 等
4.3 AutoHarness:自动生成约束
最新研究(arXiv:2603.03329)提出了 AutoHarness 的概念------用 LLM 自动为 Agent 生成代码约束(harness),替代手工编写规则。
其思路是:
- 观察 Agent 在某任务上的常见错误
- 用另一个 LLM 自动生成检查代码
- 将检查代码嵌入执行环境,实时验证 Agent 的行动合法性
这大幅降低了为新任务编写 Harness 的人工成本。
五、Spec-Driven(规范驱动):用规范定义 Agent 的边界
5.1 什么是 Spec-Driven?
Spec-Driven(规范驱动) 是一种 Agent 开发方法论,强调在构建 Agent 之前,先用形式化或半形式化的方式定义:
● Agent 能做什么(能力边界)
● Agent 应该怎么做(行为规范)
● Agent 不能做什么(禁止行为)
● Agent 完成任务的判定标准(成功条件)
这些规范构成了 Agent 行为的"宪法"。
5.2 规范驱动的具体形式
(1)工具规范(Tool Specification)
用 OpenAPI / JSON Schema 等标准格式精确定义每个工具的接口:
● 输入参数类型和约束
● 输出格式
● 错误代码含义
● 副作用说明(如"此操作不可撤销")
(2)行为规范(Behavioral Spec)
用自然语言或伪代码描述 Agent 在各种情况下的预期行为:
规则1: 当用户请求删除文件时,必须先确认文件名和路径
规则2: 任何涉及外部付款的操作,必须获得用户二次确认
规则3: 不得访问用户未明确授权的文件目录
(3)任务规范(Task Spec)
定义任务的起始状态、目标状态和约束条件,让 Agent 知道"完成"意味着什么。
(4)安全规范(Safety Spec)
专门针对安全性的规范,防止 Agent 被恶意输入(Prompt Injection)劫持或执行有害操作。
5.3 为什么 Spec-Driven 很重要?
没有规范的 Agent 就像没有说明书的机器------也许能跑,但你不知道它什么时候会出问题。
规范驱动的好处:
● 可预测性:Agent 的行为在规范范围内是可预测的
● 可审计性:出了问题,可以检查 Agent 是否违反了哪条规范
● 可迭代:规范可以随产品演进而更新,不用重新训练模型
● 合规性:在金融、医疗等监管严格的领域,规范是合规的基础
六、Agentic 范式全景:更多核心概念
6.1 Plan-and-Execute(规划-执行架构)
ReAct 是一种"边想边做"的方式,而 Plan-and-Execute 则是先制定完整计划,再逐步执行:
csharp
[Planner LLM] 接到任务 → 生成完整执行计划
[Executor LLM] 按计划逐步调用工具执行
[Verifier] 检查每步结果是否符合预期这种架构适合需要长程规划的任务(如"帮我组织一场会议,包括找时间、发邀请、准备材料"),ReAct 则更适合需要随机应变的任务。
6.2 Multi-Agent(多智能体架构)
单个 Agent 受制于上下文长度和能力范围。Multi-Agent 架构将复杂任务拆分给多个专门的 Agent 协作完成:
csharp
[Orchestrator Agent] 任务分发与协调
├── [Research Agent] 负责信息收集
├── [Code Agent] 负责代码编写
├── [QA Agent] 负责测试验证
└── [Writer Agent] 负责报告撰写代表框架:AutoGen、CrewAI、LangGraph。
6.3 Memory(记忆系统)
Agent 在执行过程中需要记住之前的信息,记忆系统分为四层:
csharp
记忆类型 类比 实现方式
Sensory Memory 感官刺激 当前上下文窗口
Working Memory 工作记忆 中间变量、临时存储
Episodic Memory 情景记忆 向量数据库(记录历史对话/操作)
Semantic Memory 语义记忆 知识图谱、长期知识库6.4 RAG(检索增强生成)
Retrieval-Augmented Generation 是一种将"检索"作为工具的特殊形式。Agent 在回答前,先从知识库中检索相关文档,再结合这些文档生成答案。
RAG 解决了 LLM 知识截止日期的问题,是企业 AI 应用中最常见的架构之一。
6.5 Reflection(自我反思)
受人类"元认知"启发,Reflection 机制让 Agent 周期性地审视自己之前的行动:
csharp
[Agent 行动] → [结果不符合预期] → [Reflection: 分析哪里出了问题] → [修正策略,重试]代表性工作:Reflexion(arXiv:2303.11366),让 Agent 将失败经验写入"记忆",在后续尝试中避免同样的错误。
七、ReAct 的局限与批评
公正地说,ReAct 并非完美。研究者也指出了它的一些问题:
(1)脆弱性(Brittleness)
Verma 等人(arXiv:2405.13966)发现,ReAct 的性能提升可能来自提示词中的表面特征,而非真正的推理能力提升。在分布外(Out-of-Distribution)的任务上,ReAct Agent 表现下降明显。
(2)幻觉传递
如果 Thought 步骤产生错误推理,后续的 Action 和 Observation 都会在错误基础上叠加,可能导致"越错越深"的情况。
(3)评估困难
Lee 等人(arXiv:2601.11903)指出,现有评估框架很难可靠地衡量 Agentic LLM 的可信度和协调性,特别是在多智能体场景下。
(4)Token 消耗大
Thought-Action-Observation 的交替循环会产生大量 token,成本较高,速度较慢。
八、实践:如何构建一个 ReAct Agent?
以一个简单的 Python 示例(使用 LangChain 框架)展示 ReAct 的实现:
from langchain.agents import create_react_agent
from langchain.tools import DuckDuckGoSearchTool, PythonREPLTool
from langchain_openai import ChatOpenAI
1. 定义工具
csharp
tools = [
DuckDuckGoSearchTool(), # 搜索工具
PythonREPLTool(), # 代码执行工具
]2. 初始化 LLM
csharp
llm = ChatOpenAI(model="gpt-4", temperature=0)3. 创建 ReAct Agent
agent = create_react_agent(llm=llm, tools=tools)
4. 运行
csharp
result = agent.invoke({
"input": "帮我查一下今年奥斯卡最佳影片,然后用 Python 统计片名的字符数"
})
print(result)
Agent 会自动执行:
Thought: 我需要先搜索今年奥斯卡获奖信息
Action: DuckDuckGoSearch("2026 Oscar Best Picture winner")
Observation: [搜索结果...]
Thought: 找到了,片名是 xxx,现在计算字符数
Action: PythonREPL("print(len('xxx'))")
Observation: 42
Thought: 任务完成
Final Answer: 今年奥斯卡最佳影片是 xxx,片名有 42 个字符九、总结:Agentic AI 的大图景
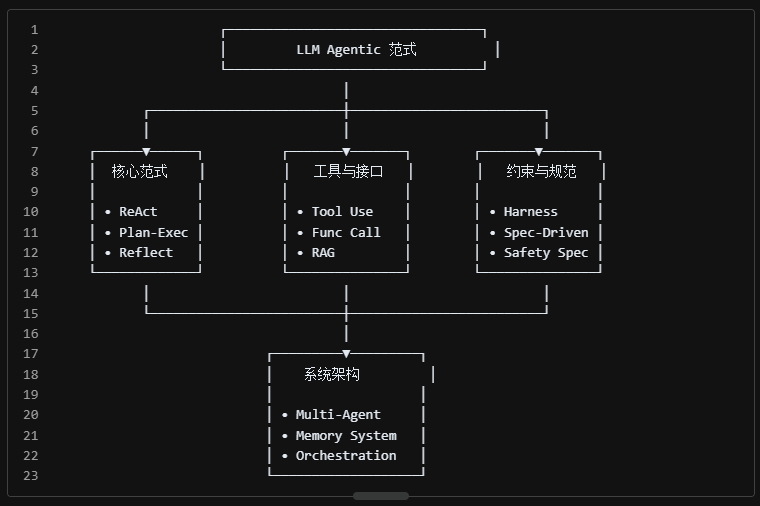
核心洞察:
- ReAct 是基础:推理与行动的交织是 Agentic AI 的基本范式
- 工具是能力的延伸:LLM 本身有局限,工具调用让它无所不能
- 规范是安全的保障:没有约束的 Agent 是危险的,Harness 和 Spec 是工程化落地的必要条件
- 组合是未来方向:Multi-Agent + Memory + Reflection 的组合,正在让 AI 具备真正意义上的"自主完成复杂任务"的能力
参考文献
- Yao, S. et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629
- Plaat, A. et al. (2025). Agentic Large Language Models, a survey. arXiv:2503.23037
- Verma, M. et al. (2024). On the Brittle Foundations of ReAct Prompting for Agentic LLMs. arXiv:2405.13966
- Jiang, J. et al. (2024). KG-Agent: Autonomous Agent Framework for Complex Reasoning over KG. arXiv:2402.11163
- Lou, X. et al. (2026). AutoHarness: Improving LLM Agents by Automatically Synthesizing a Code Harness. arXiv:2603.03329
- Shinn, N. et al. (2023). Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366
- Lee, Y. et al. (2026). AEMA: Verifiable Evaluation Framework for Trustworthy and Controlled Agentic LLM Systems. arXiv:2601.11903