题目:PETRv2: AUnified Framework for 3D Perception from Multi-Camera Images
1. motivation
作者觉得利用单帧太局限了,要搞时序;
在自动驾驶领域,如何利用多摄像头图像进行精准的 3D 感知(如目标检测和地图分割)一直是研究热点。现有的方法主要分为两类:
- 基于BEV的方法:通过如LSS等算法将2D图像特征显式转换为鸟瞰图(Bird's Eye View, BEV)表示。
- 基于DETR的方法:将3D目标建模为可学习的"query",利用Transformer架构实现端到端的检测。
PETR(Position Embedding Transformation)作为后者的一种,通过将3D坐标的位置信息编码为图像特征,使目标query能够感知3D位置,从而直接进行检测。然而,仅依赖单帧信息在复杂场景下存在局限。
PETRv2 在此基础上进行了重大升级,旨在构建一个统一的、高效的多任务3D感知框架,不仅提升了检测精度,还扩展支持了高质量的BEV分割任务。
2. methods
框架结构概览
整体架构流程如下:
- 2D Backbone:提取多视角图像特征(如ResNet-50)。
- 坐标处理:生成3D坐标,并通过姿态变换对齐相邻帧的坐标。
- 特征编码:利用特征引导的位置编码器生成Key,2D特征作为Value输入Transformer解码器。
- Query交互:Det Query(检测)和 Seg Query(分割)并行与特征交互。
- 任务头 :分别输出检测框和分割图。
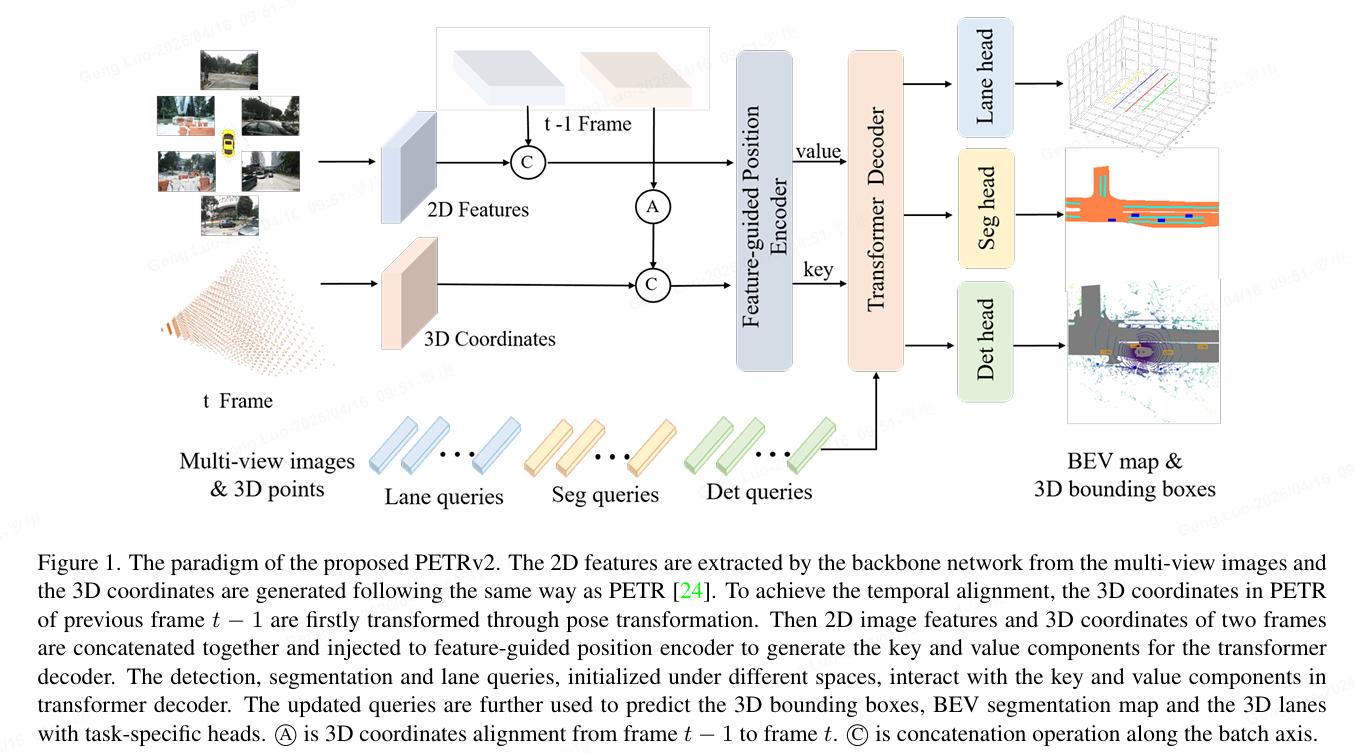
论文主要解决了三个关键问题:
-
如何利用时间信息? (时域建模)
作者是这样做的:
-
如何提升位置编码的准确性?(数据适应性)
-
如何统一处理多种感知任务? (多任务扩展)
好像在代码中没有一起训练;
2.1 时域建模:利用历史帧增强感知
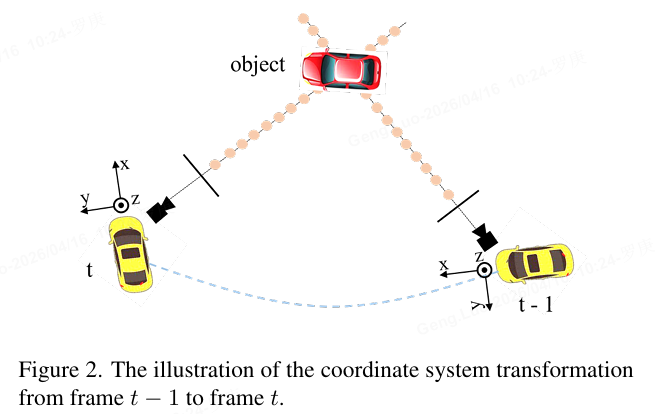
PETRv2的核心创新之一是引入了时间维度 。它利用前一帧(t−1t-1t−1)的时间信息来增强当前帧(ttt)的3D感知能力。
- 3D坐标对齐 :为了实现跨帧的时间对齐,PETRv2利用车辆的自我运动信息,通过姿态变换矩阵 Tt−1tT_{t-1}^{t}Tt−1t,将前一帧的3D坐标转换到当前帧的坐标系中。
P3dt=Tt−1tP3dt−1P_{3d}^{t} = T_{t-1}^{t} P_{3d}^{t-1}P3dt=Tt−1tP3dt−1 - 效果 :这种对齐方式使得模型能够整合连续帧的信息,显著增强了目标定位的准确性和速度估计的稳定性。
2D特征引导的位置编码器
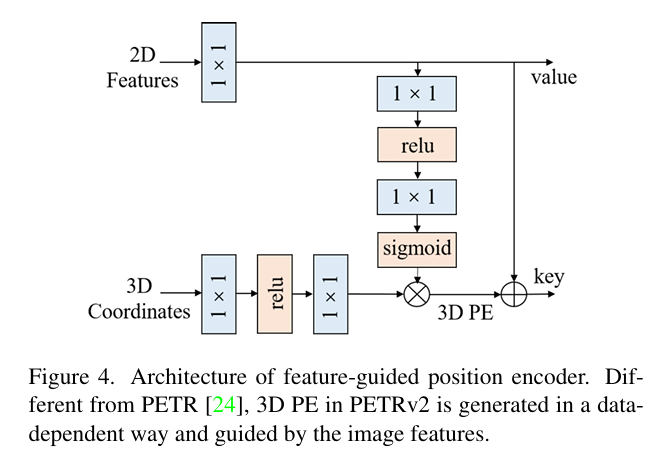

传统的PETR使用固定的3D位置嵌入(3D PE),与输入图像内容无关。PETRv2认为,位置编码应该根据实际的2D图像特征(如深度信息)进行动态调整。
- 机制 :引入了特征引导的位置编码器。该编码器利用2D图像特征作为指导,通过一个小的MLP网络生成注意力权重。
- 过程 :2D特征经过1×1卷积投影后,反馈到MLP和Sigmoid函数中生成权重;同时3D坐标也被转换,两者相乘生成最终的3D PE。这使得位置编码隐含了视觉先验知识(如深度),使模型更具数据适应性。
同时,作者也加了denoise策略来加速收敛。

2.3 多任务统一框架的query:Od Query、Seg Query、Lane Query
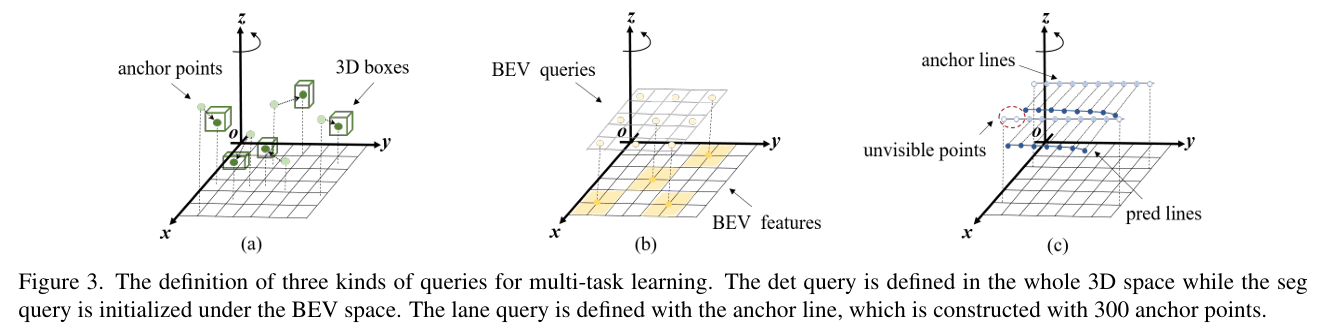
为了让框架支持高质量的BEV分割(如车道线检测),PETRv2在原有的检测Query基础上,增加了专门用于分割和车道线检测的Seg Query、Lane Query
- 设计:高分辨率的BEV地图被划分为若干个Patch(如256×256划分为16个16×16的Patch)。
- 交互:每个Seg Query对应一个特定的Patch区域,初始化后输入到Transformer解码器中,与图像特征进行交互。
- 输出:更新后的Seg Query通过一个简单的分割头(MLP + Sigmoid),预测出对应Patch的分割结果,最终拼接成完整的BEV分割图。
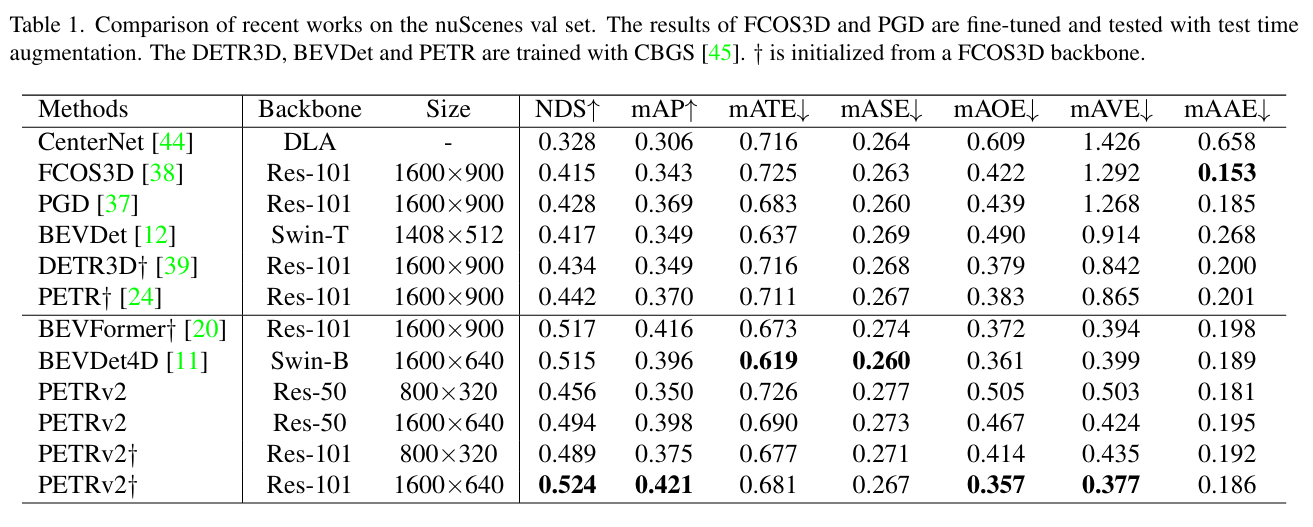
4. 实验与鲁棒性分析
PETRv2在nuScenes等主流数据集上进行了验证,取得了当时最先进的性能。除了精度提升,论文还特别关注了系统的鲁棒性:
- 抗噪能力:在相机外参存在噪声、相机缺失(如部分摄像头故障)或时间延迟等恶劣情况下,PETRv2依然保持了较高的性能稳定性。
- 多任务优势:通过共享特征提取和Transformer解码器,模型在增加分割任务的同时,计算开销增加有限,实现了高效的多任务学习。
【完结】