HarmonyOS 6实战:从视频编解码到渲染过程,一文了解鸿蒙音视频数据流向
-
- 视频编解码、视频渲染的区别
- [编码器 Surface 模式、Buffer 模式是什么意思?](#编码器 Surface 模式、Buffer 模式是什么意思?)
-
- [Surface 是什么](#Surface 是什么)
- [NativeWindow 是什么](#NativeWindow 是什么)
- [Buffer 又是什么](#Buffer 又是什么)
- [为什么相机、录屏、GPU 渲染特别适合 Surface 模式](#为什么相机、录屏、GPU 渲染特别适合 Surface 模式)
- [Surface 模式 vs Buffer 模式区别](#Surface 模式 vs Buffer 模式区别)
-
- 数据交付方式不同、数据不同
- 生命周期控制不同
- [解码器在 Surface 模式下必须先绑窗口](#解码器在 Surface 模式下必须先绑窗口)
- 解码出来的画面,怎么交给渲染管线?
-
- [XComponent 满足不了需求时,搭建NAPI 层](#XComponent 满足不了需求时,搭建NAPI 层)
- [分叉点:解码器输出的 Surface 绑给谁?](#分叉点:解码器输出的 Surface 绑给谁?)
- 回调队列这块,特别适合理解成"取号叫号系统"
- [渲染过程进阶------OpenGL 纹理化](#渲染过程进阶——OpenGL 纹理化)
- [渲染过程进阶------Vulkan 底层操作GPU 图像渲染](#渲染过程进阶——Vulkan 底层操作GPU 图像渲染)
- 总结
前阵子我们写了两篇视鸿蒙视频加载的博客,大家的评价还不错。反馈最多的就是生动形象,但其实,虽然我有一定音视频开发基础,但是翻越鸿蒙官网文档时,读起来也是比较晦涩的,处于Demo 能跑,代码也能看懂个大概,但很多术语也是"会用,不真懂"。
比如:
Surface到底是什么?NativeWindow和Buffer有什么区别?- 为什么官方文档总在强调
Surface 模式? - 为什么一提相机、录屏、游戏渲染,很多文章都说"优先考虑 Surface"?
后来继续翻官方文档,突然意识到一件事:
Surface 模式真正厉害的地方,不是"接口高级",而是它更贴合真实的视频数据流向。
简单说:
如果你的视频数据不是从文件里一点一点读出来的,而是从"设备"实时产生出来的,那么 Surface 模式就会特别顺手。
比如:
- 相机实时拍摄
- 屏幕录制
- 游戏 / OpenGL / Vulkan 实时渲染
这几个场景有个共同点:
数据本来就在图形系统或设备流水线上流动。
这时候如果你硬要把数据拽回 CPU 内存,再塞给编码器或显示模块,过程就会多很多冤枉路。
所以今天这篇文章,我想借助官网的教学代码,把我对鸿蒙音视频的理解讲透:
-
Surface 模式和Buffer 模式到底区别在哪 -
为什么相机、录屏、GPU 渲染天然适合 Surface
-
XComponent / OpenGL / Vulkan等渲染路径到底有什么区别
视频编解码、视频渲染的区别
很多人会把它们搞混,因为平时聊「看视频」的时候,这两个事儿是串在一起发生的。但底层逻辑上,它们干的是完全不同的活。
我用最直白的方式说清楚:
| 概念 | 干的事 | 输入 | 输出 |
|---|---|---|---|
| 编解码 | 压缩 / 解压缩 | 原始画面(YUV) / H.264文件 | H.264文件 / 原始画面(YUV) |
| 渲染 | 把画面画到屏幕上 | 原始画面(YUV/RGB) | 屏幕上你看到的图像 |
编解码管的是「体积」和「存储/传输」。为什么要编码?因为原始视频太大了,一秒钟几十兆,不压缩根本存不下、传不动。
渲染管的是「显示」。解码出来的画面,你得把它画到屏幕上才能看见。画多大?画在哪个位置?要不要旋转、加滤镜?这些都是渲染的事。
举个例子
场景:你刷抖音
- 服务器把 H.264 视频传给你 → 网络传输
- 解码器 把 H.264 解成 YUV 画面 → 这是解码
- 解码后的 YUV 画面交给 GPU/显示系统,画到屏幕上 → 这是渲染
没有解码,你看不了视频;没有渲染,解码出来你也看不见。
场景:你用手机拍视频
- 摄像头拍到原始画面 → 采集
- 取景框里实时显示这个画面 → 这是渲染
- 点录制,原始画面被编码器 压缩成 H.264 → 这是编码
- 存到手机里
渲染让你看到自己在拍什么,编码让视频能存下来。
看视频时:解码 + 渲染(先解出来,再画上去)
拍视频时:编码 + 渲染(一边存,一边预览)
视频编辑时:解码 → 渲染(预览)→ 编码(导出)
很多场景下它们确实同时出现,但各干各的活,不是一回事。
编解码 = 压缩/解压缩,管体积;渲染 = 画到屏幕,管显示。
编码器 Surface 模式、Buffer 模式是什么意思?
如果你现在只想记住一句话,请记这个:
数据从哪里来,决定你更适合用 Surface 还是 Buffer。
更具体一点:
- 相机 / 屏幕 / GPU 实时产生的数据,更适合
Surface 模式 - 文件里的原始帧、你自己手里已经拿到的 YUV 数据,更适合
Buffer 模式
再接地气一点:
- Surface 模式:更像"把一个画面通道直接接给下游模块"
- Buffer 模式:更像"我自己拿着一块内存,把像素数据拷进去,再交给下游"
Surface 是什么
如果你把它想成"屏幕"也不完全对。
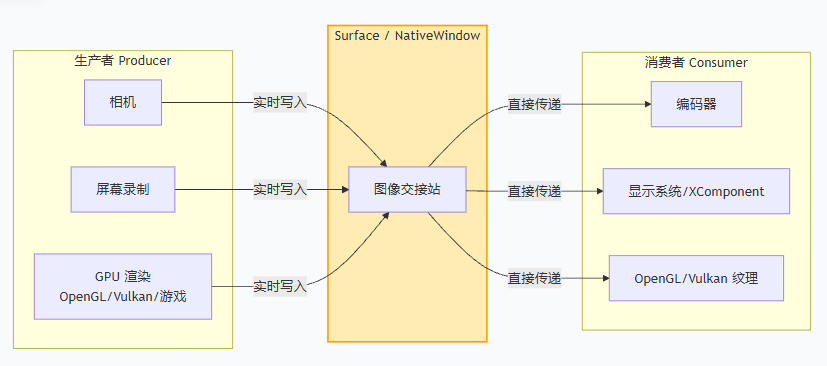
更准确一点,它像是一个"图像生产和消费的接口面板"。
谁往这个面板上写图像,谁就是生产者;谁从这个面板上取图像,谁就是消费者。
在图形/媒体系统里,常见的生产者可能是:
- 相机
- 解码器
- OpenGL
- Vulkan
- 屏幕采集模块
常见的消费者可能是:
- 编码器
- 显示系统
XComponent- OpenGL / Vulkan 的纹理系统
所以 Surface 的本质不是"一个组件",而是一个图像交接站。
NativeWindow 是什么
在 HarmonyOS / OpenHarmony 这套体系里,OHNativeWindow 经常就是应用层拿来和 Surface 打交道的"把手"。
你可以粗暴理解成:
Surface是图像通道NativeWindow是操作这个通道的句柄
官方文档里对视频解码也明确提到了一个核心点:Surface 输出是通过 OHNativeWindow 来传递输出数据的,可以和其他模块对接,比如 XComponent。
这句话特别关键,因为它直接解释了为什么这个项目能把解码后的画面送到 XComponent,或者送进 NativeImage 再让 OpenGL / Vulkan 去接管。
Buffer 又是什么
Buffer 就好理解多了。
它本质上是一块数据内存。
如果你走 Buffer 模式,通常意味着:
- 你能拿到共享内存地址
- 你要自己处理像素内容
- 你需要自己决定什么时候写入、什么时候释放
所以 Buffer 更像"自己扛着一箱像素数据到处跑"。
而 Surface 更像"把货直接从传送带送到下一个工位"。
为什么相机、录屏、GPU 渲染特别适合 Surface 模式
这部分是最容易一下子想明白的。
场景一:相机拍视频
你打开抖音、快手、小红书,点击录制,画面来自哪里?
来自相机。
相机预览帧是实时产生的,不是从文件里读的。
如果走 Surface 模式,思路会很顺:
- 编码器给你一个
Surface - 你把这个
Surface交给相机 - 相机直接往这个
Surface里写图像 - 编码器直接从这个
Surface取数据编码
这套链路的好处是:
- 少一次 CPU 参与
- 少一次内存拷贝
- 少一次额外分配
- 理论上更省电、更低发热
如果不用 Surface,会怎样?
你就得:
- 从相机拿一帧 YUV
- 拷到自己的内存
- 再塞给编码器
这就相当于本来可以走传送带的货,你非要自己搬一趟。
场景二:屏幕录制
录屏的本质是什么?
是把屏幕上正在显示的内容变成视频。
这类数据本来就在图形系统里流动。如果能直接在图形链路里交接给编码器,就很自然。
官方文档在 AVScreenCapture 的介绍里提到,录屏能力会通过图形图像服务捕获屏幕数据,再进行编码封装。
这里我做一个明确标注:
下面这句是基于官方文档和工程经验的推断。
对录屏这类"图形系统实时生成画面"的场景,Surface 思路天然更合理,因为它更符合"画面在图形栈里直接流动"的模型,而不是把每一帧先拖回 CPU 再处理。
场景三:OpenGL / Vulkan / 游戏画面
游戏或者特效视频的画面,很多时候是 GPU 渲染出来的。
这时候你要做录制或编码,最怕什么?
最怕把 GPU 上的结果再拉回 CPU。
为什么?
因为这很贵。
你可以把它想成:
- 本来画面已经在 GPU 工厂生产线上了
- 结果你非要把成品先搬回仓库点一遍数
- 然后再送回另一个 GPU 车间
这当然浪费。
所以对 GPU 实时渲染场景来说,Surface 模式的优势会更明显。
Surface 模式 vs Buffer 模式区别

这里我结合官方文档,把核心差异翻译成更容易理解的版本。
数据交付方式不同、数据不同
Surface 输出:通过OHNativeWindow把图像往下传Buffer 输出:通过共享内存把图像数据给你
这两种模式,不是"一个高级一个低级",而是"交货方式不同"。
在 Buffer 模式下,你通常可以拿到:
- buffer 的地址
- 实际像素数据
- 数据信息
在 Surface 模式下,你更多拿到的是:
- buffer 的描述信息
- 对应的 surface / window 交接能力
但你未必能像 Buffer 模式那样直接拿像素地址去随便改。
生命周期控制不同
官方文档对视频解码给了一个很重要的区别:
- 在
Surface 模式下,可以选择调用OH_VideoDecoder_FreeOutputBuffer()丢弃输出帧,不送显 - 在
Buffer 模式下,应用必须调用OH_VideoDecoder_FreeOutputBuffer()释放数据
为什么会有这个差异?
因为 Surface 模式更像"图像已经交给显示链路了",你可以选择显示,也可以选择丢掉。
而 Buffer 模式更像"这块数据在你手上",你必须自己负责释放。
解码器在 Surface 模式下必须先绑窗口
官方文档还强调了一个关键点:
在视频解码的 Surface 模式 下,解码器就绪前必须先调用 OH_VideoDecoder_SetSurface() 设置 OHNativeWindow。
启动之后,开发者可以:
- 调用
OH_VideoDecoder_RenderOutputBuffer()显示并释放解码帧 - 或调用
OH_VideoDecoder_RenderOutputBufferAtTime()在指定时间点显示并释放
如果你要做音画同步或控制播放节奏,官方建议优先考虑 RenderOutputBufferAtTime。
这一点,和我们当前仓库里的实现是可以直接对上的。
解码出来的画面,怎么交给渲染管线?
上面给的几个场景:
- 相机拍摄
- 屏幕录制
- OpenGL 渲染
它们主要讲的是:编码器输入侧的 Surface 模式。
也就是:
text
相机 / 屏幕 / GPU
-> Surface
-> 编码器而接下来我们讲解渲染过程:解码器输出侧的 Surface 模式。
也就是:
text
视频文件
-> 解复用
-> 解码器
-> Surface / NativeWindow
-> XComponent 或 OpenGL / Vulkan别看一边是"编码输入",一边是"解码输出",它们背后的核心思想其实是一样的:
让图像尽可能在图形系统内部直接流动,减少不必要的 CPU 介入和内存搬运。
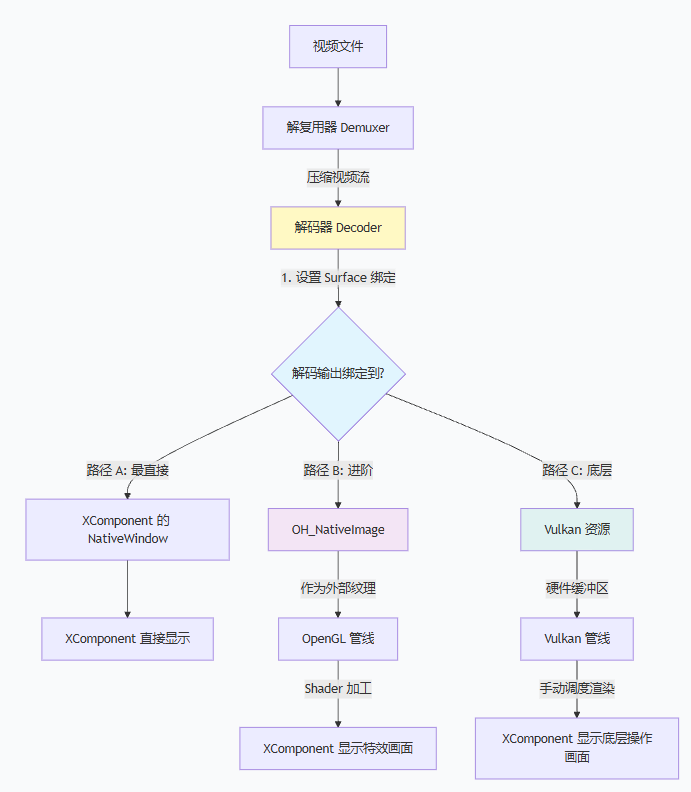
而图像渲染,也就是我们的入门XComponent 路线:最直接,也最适合做第一站理解
这条路径最简单:
text
文件 -> 解复用 -> 解码 -> 直接写到 XComponent 对应的 NativeWindow它几乎不做额外加工,所以特别适合用来建立第一层理解:
- 我的视频从哪里来
- 解码器怎么工作
- 画面为什么能出来
XComponent 满足不了需求时,搭建NAPI 层
我们参考官网的cpp文件实现:
cpp
static napi_value Init(napi_env env, napi_value exports)
{
NativeXComponentSample::PluginManager::GetInstance()->RenderConfig(env, exports);
napi_property_descriptor desc[] = {
{"playNative", nullptr, NativeXComponentSample::PluginRender::StartPlayer, nullptr, nullptr, nullptr, napi_default, nullptr},
{"stopNative", nullptr, NativeXComponentSample::PluginRender::StopPlayer, nullptr, nullptr, nullptr, napi_default, nullptr}
};
napi_define_properties(env, exports, sizeof(desc) / sizeof(desc[0]), desc);
return exports;
}这里暴露了两类能力:
playNative / stopNativeRenderConfig
前者负责播放控制,后者负责拿到 XComponent 对应的 native 能力并注册回调。
这一步可以理解成:
ArkTS 负责"发指令",C++ 负责"接管现场"。
分叉点:解码器输出的 Surface 绑给谁?
下面是一个经典的函数, PluginRender::StartPlayer():
cpp
PluginRender *render = PluginRender::GetInstance(type);
if (render != nullptr) {
if (type == "OpenGL") {
sampleInfo.window = render->openGLRenderThread_->GetNativeImageWindow();
} else if (type == "Vulkan") {
sampleInfo.window = render->vulkanRenderThread_->GetNativeImageWindow();
} else {
sampleInfo.window = render->nativeWindow;
}
}
int32_t ret = Player::GetInstance().Init(sampleInfo);
Player::GetInstance().Start();它决定了三条路径的本质差异:
XComponent:直接把解码结果写到页面窗口OpenGL:把解码结果写到NativeImage的窗口Vulkan:把解码结果写到NativeImage的窗口
所以你会发现:
播放器主流程其实没怎么变,变的是解码结果的交付对象。
cpp
int32_t ret = Configure(sampleInfo);
...
if (sampleInfo.window != nullptr) {
int ret = OH_VideoDecoder_SetSurface(decoder_, sampleInfo.window);
if (ret != AV_ERR_OK) {
OH_LOG_ERROR(LOG_APP, "Set surface failed, ret: %{public}d", ret);
return AVCODEC_SAMPLE_ERR_ERROR;
}
}
...
ret = SetCallback(codecUserData);
...
ret = OH_VideoDecoder_Prepare(decoder_);把这段代码和官方文档放在一起看,就非常通了。
官方文档说:
- Surface 模式下,解码器就绪前要先
SetSurface - 启动后再选择
RenderOutputBuffer或RenderOutputBufferAtTime
项目里就是这么做的:
- 先给解码器绑定
window - 再
Prepare - 再
Start - 最后在输出线程里释放 / 送显
这时候你就会明白,OH_VideoDecoder_SetSurface() 不是一个普通配置项,它其实是在回答一个很核心的问题:
"这帧解码出来的图,到底要交给谁?"
第一次读官网案例,很多人可能有疑问:
"不是都已经有解码器了吗?为什么还要自己开线程?"
答案是:因为解码器本身就是回调驱动的,线程是为了把回调变成稳定的消费流水线。
初始化和启动逻辑:
cpp
videoDecoder_ = std::make_unique<VideoDecoder>();
demuxer_ = std::make_unique<Demuxer>();
int32_t ret = demuxer_->Create(sampleInfo_);
...
ret = CreateVideoDecoder();
...
ret = videoDecoder_->Start();
...
videoDecInputThread_ = std::make_unique<std::thread>(&Player::VideoDecInputThread, this);
videoDecOutputThread_ = std::make_unique<std::thread>(&Player::VideoDecOutputThread, this);你可以把它想成两个工人:
- 输入线程负责喂压缩帧
- 输出线程负责拿解码结果并送显
cpp
CodecBufferInfo bufferInfo = videoDecContext_->inputBufferInfoQueue.front();
videoDecContext_->inputBufferInfoQueue.pop();
...
demuxer_->ReadSample(demuxer_->GetVideoTrackId(), reinterpret_cast<OH_AVBuffer *>(bufferInfo.buffer),
bufferInfo.attr);
int32_t ret = videoDecoder_->PushInputBuffer(bufferInfo);就是标准动作:
- 从 demuxer 读压缩数据
- 塞给 decoder
cpp
CodecBufferInfo bufferInfo = videoDecContext_->outputBufferInfoQueue.front();
videoDecContext_->outputBufferInfoQueue.pop();
...
int32_t ret = videoDecoder_->FreeOutputBuffer(bufferInfo.bufferIndex, true);
...
std::this_thread::sleep_until(lastPushTime + std::chrono::microseconds(sampleInfo_.frameInterval));注意这里的 true。
它表示:
释放输出 buffer 的同时,把这帧真正渲染出去。
这就和官方文档里说的"Surface 模式下可以选择送显或丢帧"完全对上了。
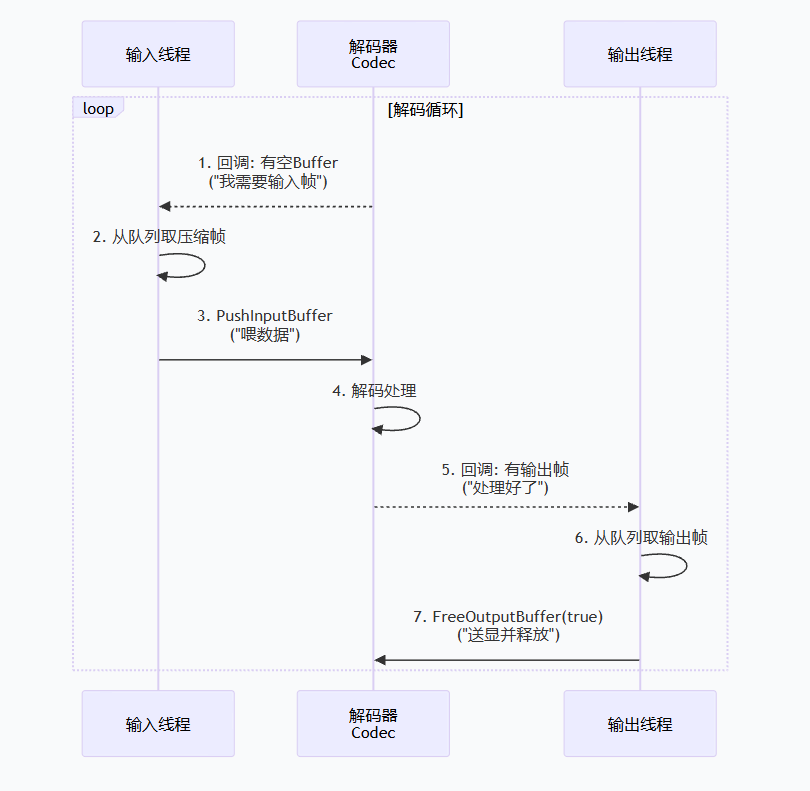
回调队列这块,特别适合理解成"取号叫号系统"
cpp
void SampleCallback::OnNeedInputBuffer(OH_AVCodec *codec, uint32_t index, OH_AVBuffer *buffer, void *userData) {
CodecUserData *codecUserData = static_cast<CodecUserData *>(userData);
std::unique_lock<std::mutex> lock(codecUserData->inputMutex);
codecUserData->inputBufferInfoQueue.emplace(index, buffer);
codecUserData->inputCond.notify_all();
}
void SampleCallback::OnNewOutputBuffer(OH_AVCodec *codec, uint32_t index, OH_AVBuffer *buffer, void *userData) {
CodecUserData *codecUserData = static_cast<CodecUserData *>(userData);
std::unique_lock<std::mutex> lock(codecUserData->outputMutex);
codecUserData->outputBufferInfoQueue.emplace(index, buffer);
codecUserData->outputCond.notify_all();
}如果你觉得"回调 + 队列 + 条件变量"很抽象,那我换个说法:
- 解码器说:"我现在有空 buffer,谁来喂我?"
- 输入线程说:"行,我来"
- 解码器说:"我现在有输出帧了,谁来处理?"
- 输出线程说:"行,我来"
这不就是医院取号叫号系统吗?
这样一想,整个模型就不神秘了。
渲染过程进阶------OpenGL 纹理化

OpenGL Shader编写、纹理化是最常见的一类应用。通过片段着色器(Fragment Shader),可以逐像素地修改画面的颜色、亮度等,实现各种艺术效果。例如基础色彩调整:实时调整视频的亮度、对比度、饱和度、色相等,(视频美颜)。
或者实现风格化滤镜或光效:应用预设的算法,瞬间改变视频的视觉风格,例如灰度、复古、怀旧(Sepia)、冷暖色调等。模拟如发光(Glow/Lighting)、光晕(Bloom)、热浪扭曲(Heat Shimmer)等复杂的光影效果,增强画面的氛围感
OpenGL 这条路的关键思路是:
text
解码器
-> NativeImage
-> 外部纹理
-> Shader
-> XComponent这比直接送 XComponent 多了一层"纹理化"的过程。
OpenGLRenderThread.cpp:
cpp
nativeImage_ = OH_NativeImage_Create(-1, GL_TEXTURE_EXTERNAL_OES);
...
nativeImageWindow_ = OH_NativeImage_AcquireNativeWindow(nativeImage_);
...
nativeImageFrameAvailableListener_.onFrameAvailable = &OpenGLRenderThread::OnNativeImageFrameAvailable;
ret = OH_NativeImage_SetOnFrameAvailableListener(nativeImage_, nativeImageFrameAvailableListener_);这一步的意义是:
- 解码器可以把图像写进
NativeImage - OpenGL 可以把它当成
GL_TEXTURE_EXTERNAL_OES使用
于是图像就从"解码结果"变成了"可被 GPU 采样的纹理"。
再把图像更新成纹理
cpp
OH_NativeImage_AttachContext(nativeImage_, nativeImageTexId_);
int32_t ret = OH_NativeImage_UpdateSurfaceImage(nativeImage_);
...
ret = OH_NativeImage_GetTransformMatrix(nativeImage_, matrix_);
...
DrawVideoImage();这几句连起来看,非常有代表性:
- 把
NativeImage绑到 OpenGL 上下文 - 把最新图像刷到纹理
- 取变换矩阵
- 真正绘制
特效场景喜欢 OpenGL
因为一旦画面成了纹理,你能做的事情就多了。
比如:
- 灰度
- 镜像
- 色调调整
- 模糊
- LUT 滤镜
- 贴纸
- 转场
所以 OpenGL 路线不是"更绕",而是"给你多了一个可编程加工环节"。
渲染过程进阶------Vulkan 底层操作GPU 图像渲染
这部分我其实并不太理解官网的介绍,我以我之前做3D开发的经验做个补充,Vulkan、OpenGL是两种不同的底层驱动,是不同的渲染协议,Vulkan更适合高复杂度精细化场景,它能让你榨干硬件性能,特别适合复杂的3A级游戏(但是用在视频渲染上,我反倒想不起什么好的应用场景)。
追求快速开发、需要兼容大量旧设备,选 OpenGL。它足够简单,且拥有无可比拟的兼容性和海量的学习资料。
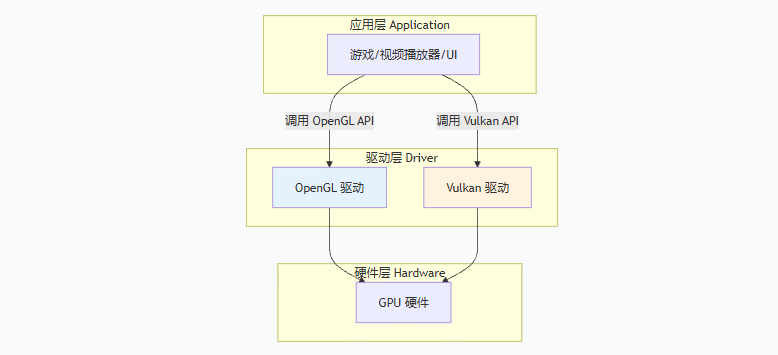
Vulkan 路线比 OpenGL 更像"全手动搭舞台",我对于Vulkan的了解甚少,所以不做展开介绍。
cpp
nativeWindow_ = nativeWindow;
CreateInstance();
vkExample::utils::LoadVulkanFunctions(instance);
CreateSurface();
PickPhysicalDevice();
CreateLogicalDevice();
vkExample::utils::LoadVulkanFunctions(device);
createSwapChain();
createRenderPass();
createFrameBuffersAndImages();
createVertexBuffer();
createUniformBuffer();这段代码特别像在准备演出现场:
- 先搭实例
- 再连窗口 surface
- 再选设备
- 再建交换链
- 再建 render pass
这也是 Vulkan 为什么让人觉得"繁琐"的原因。
它不是故意麻烦你,而是把很多默认行为都显式交给你了。
cpp
ret = OH_NativeImage_AcquireNativeWindowBuffer(nativeImage_, &inBuffer, &fenceFd1);
ret = OH_NativeBuffer_FromNativeWindowBuffer(inBuffer, &nativeBuffer);
...
vulkanRenderContext_->hwBufferToTexture(nativeBuffer, matrix_);
vulkanRenderContext_->render();OpenGL 路线里,图像主要是"更新成纹理后直接采样"。
Vulkan 路线里,图像更像是"把底层原生缓冲区导进 Vulkan 的资源体系里"。
总结
很多人卡在音视频和图形开发,不是因为不会写代码,而是因为术语把人吓住了。
其实你把这些词换成熟悉的画面,就没那么难了:
Surface:图像交接站NativeWindow:交接站的把手Buffer:你自己扛着走的数据箱子OpenGL:可编程渲染流水线Vulkan:更底层、更手动的 GPU 调度系统
在教程的时候,脑子里不要思考"某个 API 怎么调",而是"同一帧视频图像,如何走进不同的渲染世界"。思考数据流向
- 先看谁发起播放
- 再看谁决定走哪条渲染路径
- 再看解码器怎么把图像交出去
- 最后看 OpenGL / Vulkan 怎么接手
如果你以后再看到 Surface 模式 这四个字,别再把它当成冷冰冰的接口术语。
你可以直接把它翻译成:
"让图像在图形系统内部直接流动,少绕 CPU 的弯路。"
当你这么理解之后,当前这个项目、相机录制、录屏、OpenGL 特效、Vulkan 渲染,就会突然连成一张完整的地图。