在开发过程中,我们经常需要执行周期性的后台任务,比如每天发送报表、定时清理缓存、轮询第三方接口等。为了实现任务的精细化控制和跨平台运行,一个强大且易用的定时任务框架就显得尤为重要。Python 的 APScheduler 正是这样一个优秀的库,它提供了丰富的接口和灵活的配置,能够满足从简单到复杂的各种定时任务需求。本文将详细介绍 APScheduler 的核心概念、组件以及具体使用方法,帮助你快速上手并应用到实际项目中。
一、APScheduler 简介
APScheduler(Advanced Python Scheduler)是一个轻量级但功能强大的 Python 定时任务库。它支持基于日期、固定时间间隔以及类似 Linux crontab 的 cron 表达式来触发任务,并且可以将任务持久化到数据库中,避免因程序重启而导致任务丢失。此外,APScheduler 还提供了多种调度器、执行器和任务存储器,方便与不同的应用框架(如 Django、Flask、Tornado、asyncio 等)集成。
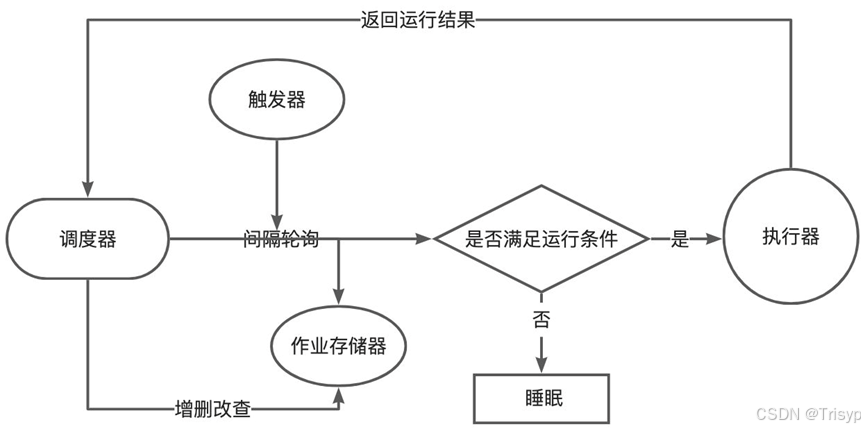
二、核心组件
APScheduler 由四个主要组件构成,理解它们之间的关系是熟练使用该库的基础。
1. 触发器(Trigger)
触发器定义了任务在何时被触发。每个作业都有自己的触发器,触发器完全无状态,只包含调度逻辑。APScheduler 内置了三种触发器:
-
DateTrigger:在指定的日期时间点触发一次(一次性任务)。
-
IntervalTrigger:以固定的时间间隔触发,支持周、天、时、分、秒等。
-
CronTrigger:使用 cron 表达式进行灵活配置,适用于复杂的时间规则。
2. 任务存储器(Job Store)
任务存储器用于存放作业及其相关数据。默认情况下,作业保存在内存中,但也可以持久化到各种数据库中(如 SQLite、MySQL、PostgreSQL、Redis、MongoDB 等)。当作业被存入数据库时,会被序列化;重新加载时再反序列化。需要注意的是,不同的调度器之间不能共享同一个任务存储器。
3. 执行器(Executor)
执行器负责将作业(即要执行的函数)提交到线程池或进程池中运行。任务执行完成后,执行器会通知调度器触发相应的事件。根据任务类型(I/O 密集型或 CPU 密集型),我们可以选择合适的执行器。
4. 调度器(Scheduler)
调度器是整个框架的控制中心。它协调触发器、任务存储器和执行器,负责添加、修改和删除作业。开发人员通常只需要与调度器交互,而不需要直接操作触发器或执行器(除非需要自定义配置)。一个应用程序中一般只有一个调度器在运行。
三、触发器详细配置
1. DateTrigger(日期触发器)
最简单的触发器,仅在指定时间点执行一次任务。
python
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
def my_job():
print("任务执行了!", datetime.now())
scheduler = BlockingScheduler()
# 在 2025-12-31 23:59:59 执行一次
scheduler.add_job(my_job, 'date', run_date=datetime(2025, 12, 31, 23, 59, 59))
scheduler.start()2. IntervalTrigger(间隔触发器)
以固定的时间间隔重复执行,支持 weeks、days、hours、minutes、seconds,还可以设置起始时间 (start_date) 和结束时间 (end_date),以及 jitter 参数随机抖动触发时间,避免集中请求。
| 参数 | 含义 | 类型 |
|---|---|---|
| weeks | 周 | int |
| days | 天 | int |
| hours | 小时 | int |
| minutes | 分钟 | int |
| seconds | 秒 | int |
| start_date | 开始触发的起始时间 | datetime/str |
| end_date | 结束触发的结束时间 | datetime/str |
| jitter | 触发时间随机偏移秒数 | int |
示例:每隔 2 小时执行一次,从 2025-01-01 00:00:00 开始,到 2025-12-31 23:59:59 结束。
python
scheduler.add_job(my_job, 'interval', hours=2,
start_date='2025-01-01 00:00:00',
end_date='2025-12-31 23:59:59')3. CronTrigger(cron 表达式触发器)
功能最强大的触发器,语法与 Linux crontab 类似,可以精确到秒、分、时、日、月、星期等。
python
# 每天 10:30 执行
scheduler.add_job(my_job, 'cron', hour=10, minute=30)
# 每周一到周五的 9:00 执行
scheduler.add_job(my_job, 'cron', day_of_week='mon-fri', hour=9, minute=0)
# 每月 1 号凌晨 0:0 执行
scheduler.add_job(my_job, 'cron', day=1, hour=0, minute=0)CronTrigger 支持以下参数(均为可选):
| 字段 | 说明 | 取值范围 |
|---|---|---|
| year | 年 | 四位数 |
| month | 月 | 1-12 |
| day | 日 | 1-31 |
| week | 周 | 1-53 |
| day_of_week | 星期几 | 0-6 或 mon,tue,wed... |
| hour | 时 | 0-23 |
| minute | 分 | 0-59 |
| second | 秒 | 0-59 |
| start_date | 最早触发时间 | datetime/str |
| end_date | 最晚触发时间 | datetime/str |
| timezone | 时区 | tzinfo |
四、调度器(Scheduler)类型及选择
APScheduler 提供了多种调度器,以适应不同的应用场景:
| 调度器 | 适用场景 |
|---|---|
BlockingScheduler |
阻塞当前进程,适用于独立运行的脚本(没有其他非守护线程)。 |
BackgroundScheduler |
在后台线程中运行,不阻塞主线程。适用于 Django、Flask 等已有主循环的应用。 |
AsyncIOScheduler |
与 asyncio 框架集成,适用于异步代码。 |
GeventScheduler |
与 gevent 协程框架集成。 |
TornadoScheduler |
与 Tornado Web 框架集成。 |
TwistedScheduler |
与 Twisted 框架集成。 |
QtScheduler |
与 PyQt / PySide 应用集成。 |
对于大多数简单脚本,BlockingScheduler 足矣;如果需要在 Web 应用后台运行定时任务,则使用 BackgroundScheduler。
五、执行器(Executor)类型及选择
执行器决定了任务以何种方式运行(线程或进程)。选择合适的执行器可以显著提升性能。
| 执行器 | 说明 |
|---|---|
ThreadPoolExecutor |
默认线程池执行器,适合 I/O 密集型任务。 |
ProcessPoolExecutor |
进程池执行器,适合 CPU 密集型计算(注意跨平台序列化问题)。 |
AsyncIOExecutor |
用于 asyncio 环境,需配合 AsyncIOScheduler 使用。 |
TornadoExecutor |
配合 TornadoScheduler 使用。 |
TwistedExecutor |
配合 TwistedScheduler 使用。 |
GeventExecutor |
配合 GeventScheduler 使用。 |
六、任务存储器(Job Store)类型
默认存储器是 MemoryJobStore,作业只存在于内存中,程序重启后丢失。若需要持久化,可以使用以下数据库后端:
-
SQLAlchemyJobStore:支持 MySQL、PostgreSQL、SQLite 等关系型数据库。
-
MongoDBJobStore:用于 MongoDB。
-
RedisJobStore :用于 Redis(需安装
redis-py)。
使用 SQLite 作为持久化存储的示例:
python
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
scheduler = BackgroundScheduler(jobstores=jobstores)七、安装与基本使用
1. 安装 APScheduler
bash
pip install apscheduler2. 一个完整的示例
下面我们使用 BlockingScheduler 创建一个每隔 5 秒打印当前时间的任务,同时添加一个一次性任务。
python
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
import time
def job_func():
print(f"[{datetime.now()}] 任务执行中...")
scheduler = BlockingScheduler()
# 每隔5秒执行一次
scheduler.add_job(job_func, 'interval', seconds=5, id='my_interval_job')
# 在10秒后执行一次(一次性)
scheduler.add_job(job_func, 'date', run_date=datetime.now().replace(second=datetime.now().second + 10))
print("调度器已启动,按 Ctrl+C 退出")
try:
scheduler.start()
except KeyboardInterrupt:
print("调度器已停止")3. 配置多个执行器与任务存储器
更复杂的场景可以同时配置多个任务存储器和执行器:
python
from apscheduler.schedulers.background import BackgroundScheduler
from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20),
'processpool': ProcessPoolExecutor(5)
}
scheduler = BackgroundScheduler(jobstores=jobstores, executors=executors)
# 添加作业时可以指定执行器
def io_task():
# 网络请求等
pass
def cpu_task():
# 计算密集型
pass
scheduler.add_job(io_task, 'interval', minutes=1, executor='default')
scheduler.add_job(cpu_task, 'interval', minutes=5, executor='processpool')八、常见问题与注意事项
-
作业持久化时的序列化问题
如果使用数据库存储作业,作业函数必须是全局可导入的(不能是 lambda 或内部函数),否则反序列化时会失败。
-
时区处理
APScheduler 默认使用系统时区,建议显式设置时区避免混淆,尤其是在使用 cron 表达式时。
python
from pytz import timezone scheduler = BlockingScheduler(timezone=timezone('Asia/Shanghai')) -
作业冲突与重叠
默认情况下,如果某个作业执行时间超过了其触发间隔,下一个实例不会同时运行(等待当前执行完成)。可以通过
max_instances参数限制同时运行的实例数量。python
scheduler.add_job(my_job, 'interval', seconds=2, max_instances=3) -
捕获异常
作业函数中的异常会被 APScheduler 捕获并记录日志,不会导致调度器停止。你可以添加错误监听器来自定义处理。
python
def my_listener(event): if event.exception: print(f"作业出错: {event.exception}") scheduler.add_listener(my_listener, EVENT_JOB_ERROR)
九、总结
APScheduler 是一个非常成熟且活跃的 Python 定时任务库,它通过清晰的组件设计(触发器、任务存储器、执行器、调度器)提供了极大的灵活性。无论你是需要运行简单的周期性脚本,还是要在复杂的 Web 应用中管理大量持久化任务,APScheduler 都能很好地满足需求。
通过本文的介绍,你应该已经掌握了 APScheduler 的核心概念和基本使用方法。赶快在你的下一个项目中尝试一下吧!
参考链接