Hello,由于小V的懒散,各种童鞋在私信问,还在吗?我的内心OS:

我在!踩过的坑、背过的锅、熬的通宵不计其数都融合在这边文章里,各位看官听我细细到来。很多刚入行的 FAE、企业 IT 负责人,找我吐槽最多的就是:
1、网上搜的部署教程全是碎片化的理论,没有完整的全流程 SOP,照着做还是踩坑;
2、调试完了才发现不符合客户业务场景,反复返工,验收拖几个月结不了项;
3、遇到突发异常没有排查思路,客户盯着解决,手忙脚乱背锅。
特别是第三个,客户盯着,自己看着问题,问题看着我,你认识我吗,我不认识你,大型社死现场。我把 AI 服务器部署全流程,拆解成了 6 个环环相扣的阶段,任何一个阶段漏项,都会导致后续返工、项目延期,这也是 90% 的新人最容易忽略的地方。
阶段1
阶段1:部署前预勘测与需求锁定(最核心,决定项目 80% 的成功率)
很多人上来就直接上架调试,90% 的坑都是这里没做好。
1、核心目标:提前锁定所有前置条件,杜绝进场后才发现问题,耽误工期
2、核心动作:机房环境勘测(机柜尺寸、电源功率、网络环境)、客户业务需求确认、验收标准提前锁定、软硬件资源提前备货校验
3、免费避坑提醒:这个阶段必须做书面确认,所有勘测数据、验收标准,必须让客户对接人签字确认,口头承诺 100% 会出问题(例如XXX项目,私下客户说模型跑起来就行,没有验收标准,在部署完之后,客户觉得不满意,一句部署模型不行,返工半天,所以确定标准真的很关键)
阶段 2:上架前硬件与环境校验
服务器上架前的最后一道校验,避免上架后拆下来返工,浪费大量时间。
1、核心目标:确保硬件无故障、环境完全匹配,上架即可调试
2、核心动作:硬件开箱核验、固件版本预校验、机房环境二次确认、上架工具与应急预案准备
3、免费避坑提醒:开箱必须全程录像,硬件外观、序列号逐一核对,避免运输损坏扯皮,这是一线 FAE 的保命符
阶段 3:服务器上架与基础环境部署
1、核心目标:规范上架,完成基础系统、驱动、固件部署,确保硬件正常运行
2、核心动作:服务器规范上架布线、BIOS 配置优化、操作系统安装、驱动与固件适配、基础网络配置
3、免费避坑提醒:布线必须做好标签,一缆一标,不然后续排查故障,你要一根根线找,浪费几倍的时间
阶段 4:AI 算力环境部署与适配
1、核心目标:完成 AI 算力组件部署,确保算力性能达标,匹配客户业务场景
2、核心动作:CUDA / 算力组件部署、容器环境配置、集群网络配置、单机 / 集群算力校验
3、免费避坑提醒:必须严格匹配客户业务场景的版本要求,不要盲目装最新版本,极易出现兼容性问题,导致反复返工
阶段 5:业务场景压力测试与稳定性校验
核心目标:模拟客户真实业务场景,确保服务器满负荷运行无异常,提前规避上线后故障
核心动作:72 小时满负荷压力测试、算力性能达标校验、业务场景适配性测试、异常场景容错测试
免费避坑提醒:不要只跑官方标准测试用例,必须按客户的真实业务场景做测试,不然客户上线出问题,第一个找你背锅

阶段 6:交付验收与文档归档
1、核心目标:顺利完成客户验收,全流程文档留痕,闭环项目
2、核心动作:测试报告输出、客户现场培训、验收签字确认、全流程文档归档、售后交接
3、免费避坑提醒:所有交付文档必须完整留痕,每一个变更、每一次调试都要有记录,这是后续出问题划清责任的唯一依据
以上是 AI 服务器部署的核心框架,能帮你理清全流程逻辑,避开基础坑。有的童鞋再问,小v有没有能落地的核心内容,有的有的,下面听我一一讲解:
示例:
目标:部署DeepSeek-V3-W8A8
机器 :2*G5680 V2 910B
框架:
MindIE
链接:Mindie
驱动固件: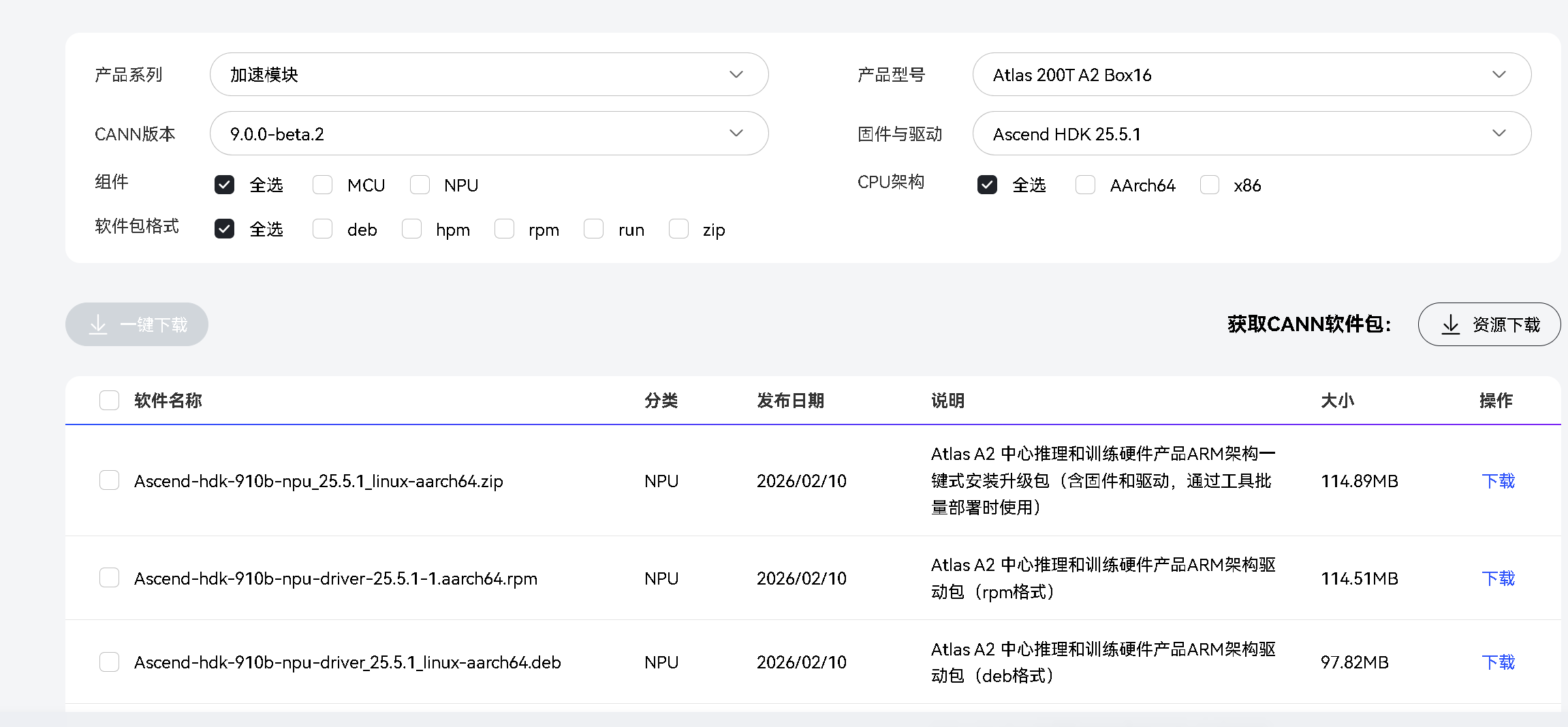
Npu驱动与固件
驱动固件下载
docker
docker
我们的交付大模型跟古代大战是一样的,兵马未动,粮草先行,先把必须的软件下载好,就是成功的一半。接下来就是服务器的核心OS:
OS:Kylin-Server-V10-SP3(内核版本4.19)
OS试用
Bios操作:
BIOS 配置
1、安装操作系统前,需要进入 BIOS 界面,将 "Advanced" 界面中 Support Smmu 和 Support SPCR 参数设为 Disable 状态。
说明
操作步骤
步骤 1 进入 BIOS 界面。
步骤 2 使用方向键切换到 "Advanced" 界面,选择 "MISC Config -> Support Smmu",将参数设置为 Disabled 状态。步骤 3 使用方向键切换到 "Advanced" 界面,选择 "MISC Config -> Support SPCR",将参数设置为 Disabled 状态。步骤 4 设置完成后,按 "F10",保存配置。步骤 5 服务器自动重启并将 BIOS 配置生效。
安装OS
步骤 1 挂载OS镜像。
- 通过虚拟光驱加载系统ISO镜像。在KVM界面中,单击工具栏上的光驱图标 ,选中"Image File"单选按钮,在下拉列表中选择本地PC上对应的系统ISO镜像,单击"Connect"。
根据指导一直点击下一步
2、安装完毕之后,使用ssh工具例如MobaXterm工具连接服务器,以root用户登录。
3、3. 执行命令lsblk查看镜像盘符编号,例如sr0,然后执行命令mount /dev/sr0 /mnt(路径自己定义就好,为接下来的yum源做配置)将OS镜像挂载至/mnt目录。
python
[root@ai01 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 600G 0 disk
├─sda1 8:1 0 600M 0 part /boot/efi
├─sda2 8:2 0 1G 0 part /boot
└─sda3 8:3 0 598.4G 0 part
├─cl-root 253:0 0 50G 0 lvm /
├─cl-swap 253:1 0 15.8G 0 lvm [SWAP]
└─cl-home 253:2 0 532.7G 0 lvm /home
sr0 11:0 1 7.7G 0 rom
[root@ai01 ~]#
[root@ai01 ~]# mount /dev/sr0 /mnt
mount: /mnt: WARNING: device write-protected, mounted read-only.
[root@ai01 ~]#配置yum源
备份yun源
python
[root@ai01 ~]# cd /etc/yum.repos.d/
[root@ai01 yum.repos.d]#
[root@ai01 yum.repos.d]# mkdir bak
[root@ai01 yum.repos.d]# mv *.repo bak/
[root@ai01 yum.repos.d]# ll
total 4
drwxr-xr-x. 2 root root 4096 Dec 5 16:42 bak
[root@ai01 yum.repos.d]#执行vi local.repo命令创建并编辑local.repo文件(豆包自自动生成,示例)
python
[root@ai01 yum.repos.d]# vi local.repo
[Kylin-SP3-Local]
name=Kylin Server V10 SP3
baseurl=file:///mnt
enabled=1
gpgcheck=0
~ [root@ai01 yum.repos.d]#更新yum源
python
[root@ai01 yum.repos.d]# yum clean all
0 files removed
[root@ai01 yum.repos.d]#
[root@ai01 yum.repos.d]# yum makecache
AppStream 138 MB/s | 5.7 MB 00:00
BaseOS 108 MB/s | 2.2 MB 00:00
Metadata cache created.安装NPU卡驱动固件
1、root登录服务器(非root有专门的安装可以参考官网进行安装)
2、创建驱动运行用户HwHiAiUser(运行驱动进程的用户),安装驱动时无需指定运行用户,默认即为HwHiAiUser。
python
。
groupadd HwHiAiUser
useradd -g HwHiAiUser -d /home/HwHiAiUser -m HwHiAiUser -s /bin/bash
3、首次安装驱动-固件,覆盖安装固件-驱动
示例:检查依赖,以麒麟为例
需要安装make、dkms、gcc、kernel-devel软件包。
python
make -v
rpm -qa | grep dkms
rpm -qa | grep gcc
rpm -qa | grep kernel-devel-$(uname -r)4、上传驱动和固件包,下载地址:驱动固件下寨地址
python
chmod +x Ascend-hdk-xxx-npu-driver_xxxx.run
chmod +x Ascend-hdk-xxx-npu-firmware_xxxx.run执行如下命令,校验run安装包的一致性和完整性
python
./Ascend-hdk-xxx-npu-driver_xxxx.run --check
./Ascend-hdk-xxx-npu-firmware_xxxx.run --check5、执行安装
驱动:
python
./Ascend-hdk-xxx-npu-driver_xxxx.run --full --install-for-all固件:
python
./Ascend-hdk-xxx-npu-firmware_xxxx.run --full出现successfully,重启服务器reboot
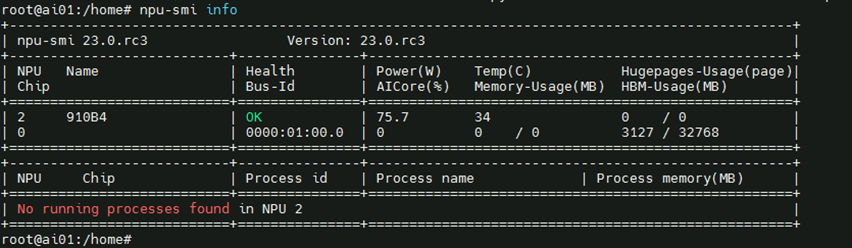
6、执行npu-smi info看下服务器效果
示例:
Docker容器部署场景
以离线部署为例,在线的参考网上其他大佬的
下载安装包:docker
根据服务器类型下对应的安装包
执行如下命令解压docker源码包
python
[root@ai01 home]# tar -zxvf docker-24.0.7.tgz
docker/
docker/docker
docker/docker-init
docker/dockerd
docker/runc
docker/ctr
docker/containerd-shim-runc-v2
docker/containerd
docker/docker-proxy步骤 4 执行如下命令复制解压出来的文件到/usr/bin目录
python
[root@ai01 home]# cp docker/* /usr/bin/
cp: overwrite '/usr/bin/runc'? y //输入y确认覆盖
[root@ai01 home]#步骤 5 执行如下命令创建systemctl管理服务,在文件中添加如下加粗内容
python
[root@ai01 home]# vi /etc/systemd/system/docker.service
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
# the default is not to use systemd for cgroups because the delegate issuesstill
# exists and systemd currently does not support the cgroup feature set required
# for containers run by docker
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
# Having non-zero Limit*s causes performance problems due to accounting overhead
# in the kernel. We recommend using cgroups to do container-local accounting
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
# Uncomment TasksMax if your systemd version supports it.
# Only systemd 226 and above support this version.
#TasksMax=infinity
TimeoutStartSec=0
# set delegate yes so that systemd does not reset the cgroups of docker containers
Delegate=yes
# kill only the docker process, not all processes in the cgroup
KillMode=process
# restart the docker process if it exits prematurely
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
[root@ai01 home]#步骤 6 执行如下命令启动docker并设置开机自启动。
python
[root@ai01 home]# systemctl start docker
[root@ai01 home]# systemctl enable docker
Created symlink /etc/systemd/system/multi-user.target.wants/docker.service → /etc/systemd/system/docker.service.
[root@ai01 home]#步骤 7 执行docker version命令,如回显类似以下信息表示Docker已安装并启动。
python
[root@ai01 home]# docker version
Client:
Version: 24.0.7
API version: 1.43
Go version: go1.20.10
Git commit: afdd53b
Built: Thu Oct 26 09:04:00 2023
OS/Arch: linux/amd64
Context: default
Server: Docker Engine - Community
Engine:
Version: 24.0.7
API version: 1.43 (minimum version 1.12)
Go version: go1.20.10
Git commit: 311b9ff
Built: Thu Oct 26 09:05:28 2023
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: v1.7.6
GitCommit: 091922f03c2762540fd057fba91260237ff86acb
runc:
Version: 1.1.9
GitCommit: v1.1.9-0-gccaecfc
docker-init:
Version: 0.19.0
GitCommit: de40ad0导入Mindie镜像
镜像链接:镜像下载
执行
python
docker load -i xxxxx.tar//根据实际修改配置NPU卡IP
python
# 步骤1:配置每张NPU卡的IP地址
echo "1️⃣ 配置 NPU 卡 IP 地址"
hccn_tool -i 0 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 1 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 2 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 3 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 4 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 5 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 6 -ip -s address 实际IP地址 netmask xxxx
hccn_tool -i 7 -ip -s address 实际IP地址 netmask xxxx
# 步骤2:配置网关(所有NPU卡统一网关)
echo "2️⃣ 配置 NPU 卡网关"
for i in {0..7}; do hccn_tool -i $i -gateway -s gateway xxx网关 ; done
# 步骤3:配置侦测IP(所有NPU卡统一为网关IP)
echo "3️⃣ 配置 NPU 卡侦测IP"
for i in {0..7}; do hccn_tool -i $i -netdetect -s address xxxxx ; done
# 步骤4:关闭 TLS 加密
echo "4️⃣ 关闭 NPU 卡 TLS"
for i in {0..7}; do hccn_tool -i $i -tls -s enable 0; done
# 步骤5:验证配置结果
echo "===== 验证配置结果 ====="
echo "🔍 查看 IP 配置"
for i in {0..7}; do hccn_tool -i ${i} -ip -g ; done
echo "🔍 查看网关配置"
for i in {0..7}; do hccn_tool -i $i -gateway -g ; done
echo "🔍 查看侦测IP配置"
for i in {0..7}; do hccn_tool -i $i -netdetect -g ; done
echo "🔍 查看物理链接状态"
for i in {0..7}; do hccn_tool -i $i -link -g ; done
echo "🔍 查看网络健康状态"
for i in {0..7}; do hccn_tool -i $i -net_health -g ; done看到这里赶紧写的太多,下面模型拉起以及基础调优放在后面一篇,还是那句话,万水千山总是情,点个关注行不行,有任何问题可以留言或私聊哦~
