在 AI 基础设施的运维与优化中,我们常常面临一个核心挑战:如何让昂贵的 GPU 算力得到充分利用?很多时候,性能的瓶颈并不在 GPU 本身,而是隐藏在 CPU 与 GPU 的协同链路中。
本文将通过一个真实的迁移案例,带您了解 Btune 2.0 是如何通过全新的「耗时分析」能力,实现对复杂性能问题的自动化根因定位。
1. 隐性的瓶颈:当 CPU 锁住 XPU 的脚步
故事的起点源于一次真实的业务挑战。一年前,我们将某核心推理服务从 GPU 集群迁移至全国产化 AI 算力 XPU 集群,在前端请求打满的高负载场景下,系统有效 QPS 却显著低于理论值,且 CPU 与 XPU 集群的利用率出现大幅波动且整体偏低。
这一异常引发了跨团队的漫长排查。
业务团队通过监控发现资源利用率异常,但无法解释成因;PaaS 团队通过对比测试发现,直接使用 Docker 部署时性能正常,而通过公司容器平台以 K8s Pod 方式部署时性能劣化,这暗示问题可能出在基础组件层面。经过基础组件团队逐个停用 Agent 的排查,最终锁定了一个名为 halolet 的基础组件。与此同时,硬件团队利用 Btune 1.0 进行热点分析,发现程序瓶颈集中在 xxx_unlocked_loctl 锁上。
多方线索汇聚后,根因浮出水面:halolet 组件频繁调用驱动接口,导致其长期持有内核锁 xxx_unlocked_loctl。这一行为阻塞了 CPU 对加速卡的正常任务编排,使得 CPU 与 XPU 陷入相互等待的状态。最终,通过优化 halolet 的接口调用逻辑,规避了对内核锁的频繁占用,推理服务性能得以恢复。
这个案例揭示了一个常被忽视的技术事实:在异构计算场景中,GPU/XPU 的理论性能高度依赖 CPU 的任务编排效率。一旦 CPU 侧因锁竞争、调度延迟等软件问题陷入停滞,GPU/XPU 便会因「饥饿」而无法发挥算力。传统的资源监控往往只能看到「利用率低」的结果,却难以看清「为何低」的过程。这正是 Btune 2.0 致力于解决的核心痛点。
2. Btune 2.0:从资源视角到耗时视角的全面升级
Btune 1.0 基于 USE(利用率、饱和度、错误)方法和 TSA(线程状态分析)方法,构建了五大瓶颈分析树,有效解决了大部分 CPU 资源瓶颈的诊断问题。然而,面对 AI 场景中复杂的 CPU+GPU 协同计算以及多进程关联干扰,仅靠资源视角已显不足。
Btune 2.0 在此基础上进行了架构级升级,形成了「负载画像 + 性能诊断树 + AI 智能体」的三层架构体系。
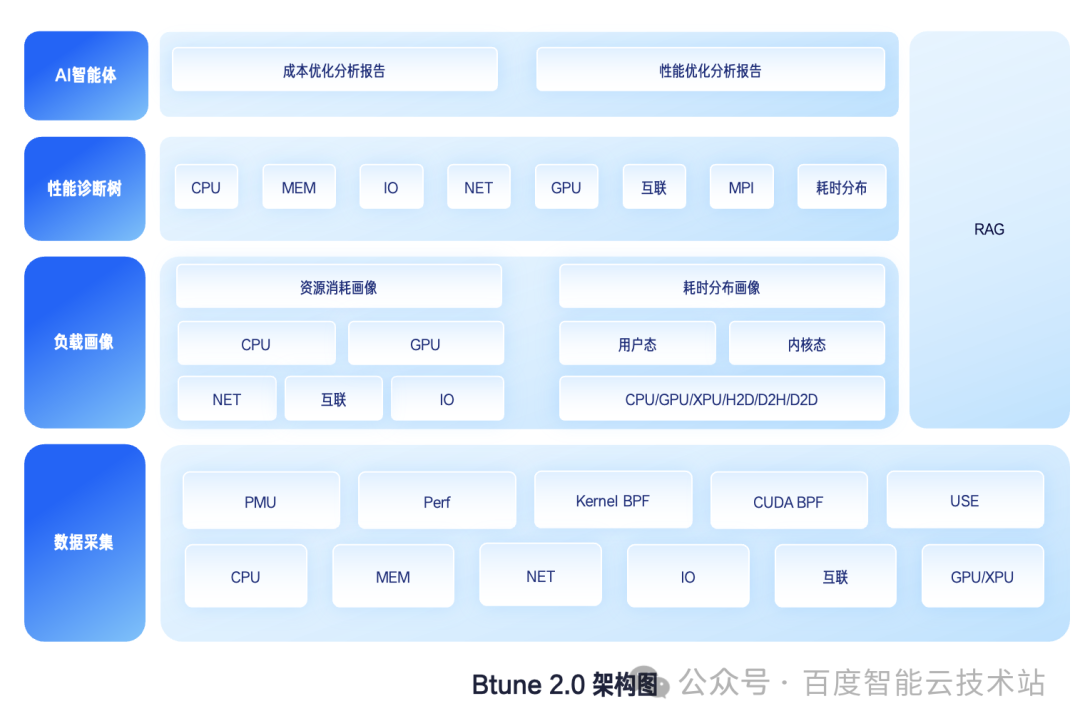
全维度的负载画像与诊断树
Btune 2.0 将诊断维度扩展为 CPU、内存、磁盘、网络、GPU/XPU 、互联、并行度、耗时八大领域。它不仅关注资源是否被占用,更关注时间花在哪里。通过构建精准的负载性能模型,Btune 2.0 能够从资源消耗与耗时分布两个维度,还原系统的真实运行状态。
深层耗时分析:透视内核执行路径
针对上述锁瓶颈案例中暴露出的问题,Btune 2.0 新增了内核耗时分析模块。该模块不再局限于应用层的函数调用栈,而是深入操作系统内核,对以下关键耗时进行系统化拆解:
-
调度耗时(Scheduler Latency):分析线程在就绪队列中的等待时间。
-
中断/软中断抢占耗时:评估硬件中断对正常任务执行的干扰。
-
系统调用耗时:追踪用户态与内核态切换的成本。
-
任务抢占耗时:识别高优先级任务对当前任务的剥夺情况。
-
不可中断等待耗时(D 状态):精准定位因 I/O 或锁等待导致的进程阻塞。
这种接近专家视角的细分分析,使得开发人员能够快速理解性能问题的本质,区分是计算密集、I/O 阻塞还是同步原语竞争导致的问题。
AI 智能体:让决策清晰可执行
Btune 2.0 接入了 AI 智能体(Agent),融合硬件数据、知识库与实时画像。Agent 能够自动执行多维建模,依据内置的性能诊断树进行推理决策,并调用相应的工具链(如锁分析、调用栈采集)。最终,它生成两份报告:成本分析报告指出资源浪费点,性能分析报告给出瓶颈根因与优化建议。
这使得 Btune 2.0 如同团队中一位不知疲倦的「首席性能架构师」,让调优决策变得清晰且可执行。
3. 自动化实战:数字人训练场景下的智能诊断
为了验证 Btune 2.0 在复杂场景下的自动化能力,我们将其应用于某数字人模型训练场景。在该场景中,研发人员面临训练吞吐忽高忽低、平均性能下降的难题,传统手工排查未能找到明确方向。
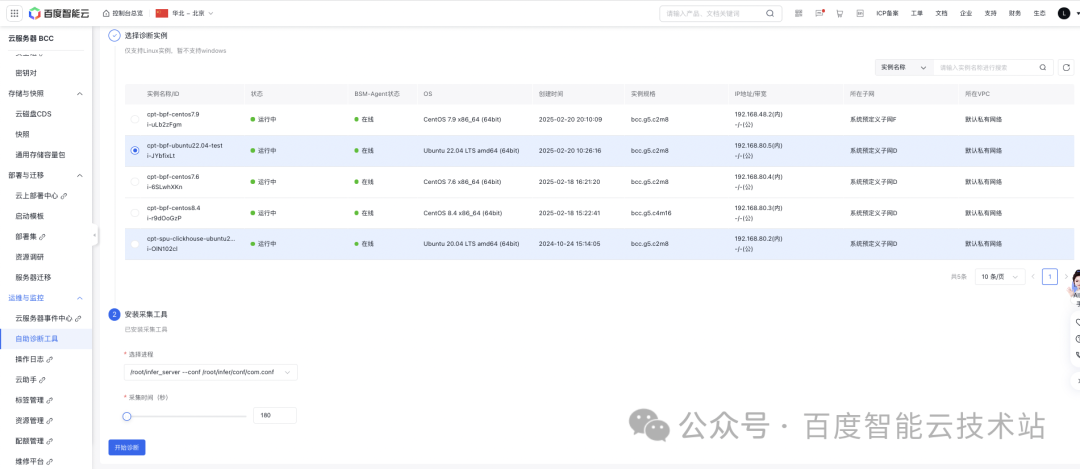
Btune 2.0 的 AI Agent 接管了诊断过程,展示了其自动化闭环分析的能力:
首先,Agent 执行全方位的性能采样,覆盖 CPU、GPU/XPU、硬件互联、网络、磁盘 IO 及各类耗时数据。通过初步的瓶颈分析树排查,Agent 迅速排除了 XPU 计算本身及互联 IO 的资源瓶颈,将焦点锁定在异常的「内核耗时」数据上。
随后,Agent 自动调用内核耗时分析模块,对调度耗时、中断抢占、系统调用、任务抢占及不可中断等待耗时进行深入拆解。分析结果显示,「不可中断等待耗时(D 状态)」存在显著异常。
针对这一异常,Agent 启动了深度追踪机制:
-
数据收集:在特定时间窗口内持续扫描目标进程,记录处于 D 状态的时间分布、对应的内核调用栈及各路径耗时统计。
-
锁对象定位:系统自动标记超过阈值的阻塞点,精确获取锁对象的名称及内核地址。在本案例中,确认为锁等待异常。
-
元凶进程关联:这是传统工具难以企及的能力。Btune Agent 通过锁对象的内核地址,自动关联所有参与该锁竞争的进程,判断是否存在其他进程长时间占用锁资源。最终,Agent 精确定位了导致当前训练进程阻塞的「元凶进程」。
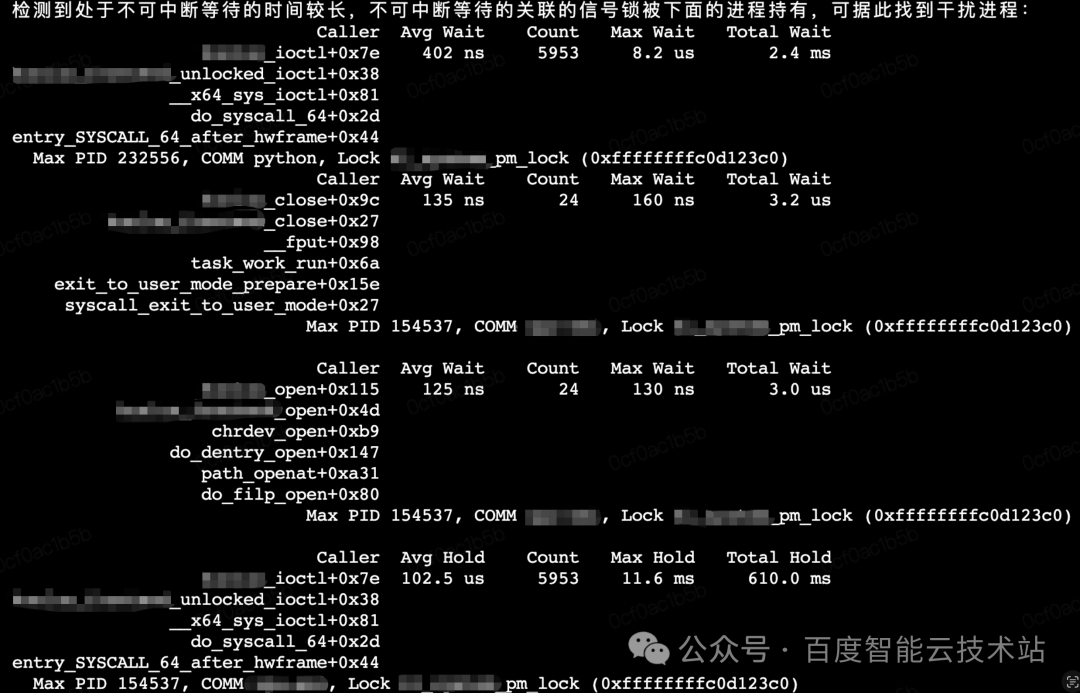
相比传统方法局限于单进程的资源视角,Btune 2.0 展现了强大的跨进程关联分析能力。它无需人工逐层排查调用链,而是结合系统状态、调度行为和资源竞争进行综合判断,自动输出具备可解释性的性能分析报告。

研发人员根据报告建议,对元凶进程进行优化处理后,训练吞吐稳定性显著提升。
4. 结语
从手动排查到自动化诊断,从资源监控到耗时透视,Btune 2.0 的演进反映了我们对 AI 基础设施性能调优理解的深化。在算力成本高企、模型规模激增的背景下,每一毫秒的耗时优化都意味着巨大的成本节约与效率提升。
Btune 2.0 不仅是一个工具,更是一套标准化的性能治理方案。我们通过开源百度在生产级别验证过的代码与技术理念,希望帮助更多开发者跨越异构计算的复杂性陷阱,让算力释放更加高效、透明。