【Spring AI 实战】六、文档 ETL 实战:PDF/Word/Markdown 解析与文本分割
大家好,我是冰点,今天我们继续聊SpringAI的基本用法和特性
建议先阅读第五篇《RAG 核心原理》,了解文档 ETL 在 RAG 流程中的定位。
第二阶段·RAG 检索增强
文章目录
- [【Spring AI 实战】六、文档 ETL 实战:PDF/Word/Markdown 解析与文本分割](#【Spring AI 实战】六、文档 ETL 实战:PDF/Word/Markdown 解析与文本分割)
-
- [一、文档 ETL 在 RAG 中的角色](#一、文档 ETL 在 RAG 中的角色)
- [二、Spring AI 文档读取体系](#二、Spring AI 文档读取体系)
- [三、PDF 解析:PdfReader 详解](#三、PDF 解析:PdfReader 详解)
-
- [3.1 依赖](#3.1 依赖)
- [3.2 基本用法](#3.2 基本用法)
- [3.3 带分页和元数据的读取](#3.3 带分页和元数据的读取)
- [3.4 提取元数据](#3.4 提取元数据)
- [四、Word 文档解析:WordDocumentReader](#四、Word 文档解析:WordDocumentReader)
-
- [4.1 依赖](#4.1 依赖)
- [4.2 基本用法](#4.2 基本用法)
- [4.3 读取表格内容](#4.3 读取表格内容)
- [五、Markdown 解析:MarkdownReader](#五、Markdown 解析:MarkdownReader)
- [六、HTML 网页解析](#六、HTML 网页解析)
- [七、JSON 文档解析](#七、JSON 文档解析)
- 八、批量文档读取工厂
- [九、文本分割:TextSplitter 核心原理](#九、文本分割:TextSplitter 核心原理)
-
- [9.1 为什么不能直接喂整篇文档?](#9.1 为什么不能直接喂整篇文档?)
- [9.2 Spring AI 内置分割器](#9.2 Spring AI 内置分割器)
- [9.3 语义感知分割:RecursiveCharacterTextSplitter](#9.3 语义感知分割:RecursiveCharacterTextSplitter)
- [9.4 Markdown 语义分割:保留标题层级](#9.4 Markdown 语义分割:保留标题层级)
- [十、自定义分割器:SentenceTransformers 语义分割](#十、自定义分割器:SentenceTransformers 语义分割)
- 十一、分割策略实战参数建议
- [十二、完整 ETL 流程示例](#十二、完整 ETL 流程示例)
- 十三、本章小结
一、文档 ETL 在 RAG 中的角色
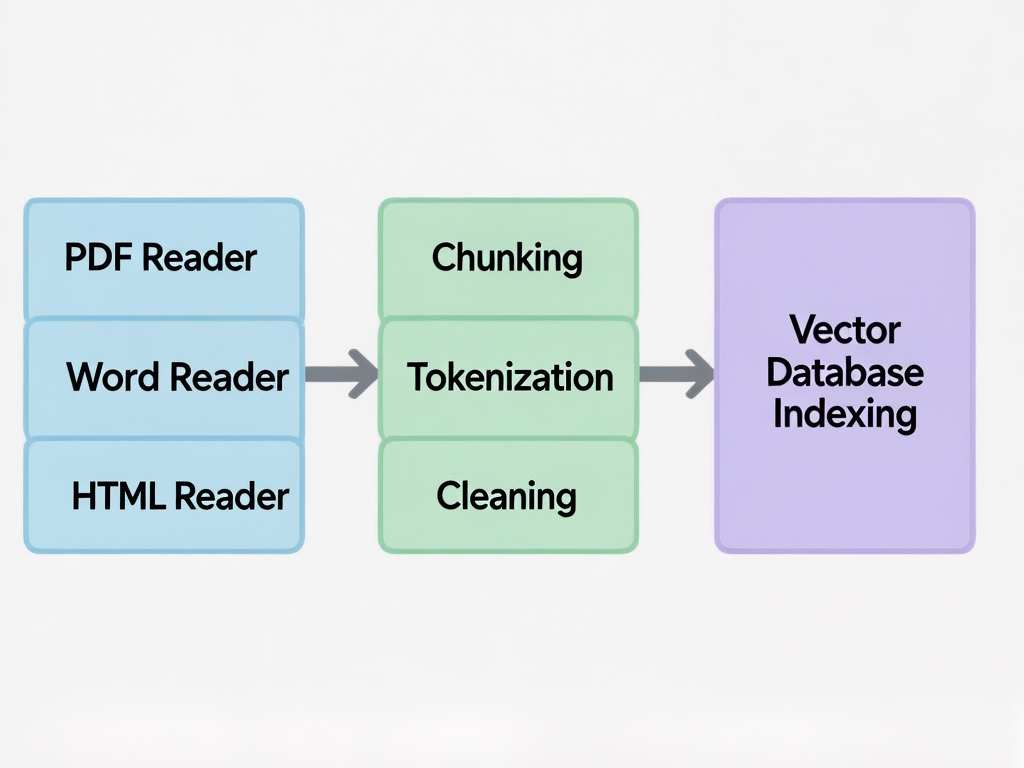
一个完整的 RAG 问答系统,数据处理流程如下:
原始文档(PDF/Word/HTML/TXT)
↓
读取(Read) ← ETL 的 E(Extract)
↓
解析(Parse) ← ETL 的 T(Transform)
↓
分割(Split) ← ETL 的 L(Load 前置步骤)
↓
向量化(Embed) → 存入 VectorStoreETL = Extract(抽取) + Transform(转换) + Load(加载),其中"Load"在 RAG 语境下就是向量化存储。本篇文章重点覆盖前三步。
二、Spring AI 文档读取体系
Spring AI 提供了一套统一的 DocumentReader 接口,所有文档源都实现这个接口:
java
// 核心接口
public interface DocumentReader {
List<Document> read();
}
// 常用实现
// - PdfReader PDF 文件
// - WordDocumentReader Word/ DOCX 文件
// - MarkdownReader Markdown 文件
// - TxtReader 纯文本文件
// - HtmlDocumentReader HTML 网页
// - JsonReader JSON 文件
// - ApachePoiDocumentReader Apache POI 读取 Word/Excel三、PDF 解析:PdfReader 详解
3.1 依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-readers-spring-boot-starter</artifactId>
</dependency>
<!-- PDF 解析底层依赖二选一 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.1</version>
</dependency>3.2 基本用法
java
@Bean
public DocumentReader pdfReader() {
return new org.springframework.ai.reader.pdf.PdfReader(
"classpath:/docs/product-manual.pdf"
);
}
// 读取并打印
List<Document> docs = pdfReader().read();
docs.forEach(doc -> System.out.println(doc.getContent()));3.3 带分页和元数据的读取
java
@Bean
public DocumentReader pdfReaderWithMetadata() {
PdfReader pdfReader = new PdfReader(
PathUtils.getResourceURL("classpath:/docs/product-manual.pdf")
);
// PdfReader 支持自定义 PageExtractionStrategy
PdfReaderConfig config = PdfReaderConfig.builder()
.pageExtractionStrategy(
// ALL_PAGES:所有页; ODD_PAGES:奇数页; EVEN_PAGES:偶数页
PageExtractionStrategy.ODD_PAGES
)
// 每页自定义过滤(去掉页眉页脚)
.filterPhraseMapper(phrase ->
phrase.replace("CONFIDENTIAL", "")
.replace("Page {n} of {total}", "")
)
.build();
return new org.springframework.ai.reader.pdf.PdfReader(
PathUtils.getResourceURL("classpath:/docs/product-manual.pdf"),
config
);
}3.4 提取元数据
PDF 的元数据(页码、章节标题、文件路径)会自动注入到 Document 的 metadata 中:
java
List<Document> docs = pdfReader().read();
Document firstPage = docs.get(0);
// Spring AI 会自动填充以下元数据
firstPage.getMetadata().forEach((k, v) -> System.out.println(k + ": " + v));
// 输出示例:
// source: classpath:/docs/product-manual.pdf
// page-number: 1
// total-pages: 42四、Word 文档解析:WordDocumentReader
4.1 依赖
xml
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>5.2.5</version>
</dependency>4.2 基本用法
java
@Bean
public DocumentReader wordReader() {
return new WordDocumentReader(
PathUtils.getResourceFile("classpath:/docs/company-policy.docx"),
WordDocumentReaderConfig.builder()
.perPageConverter(false) // false: 整篇文档为一个 Document;true: 每页一个
.build()
);
}4.3 读取表格内容
Word 中的表格默认不自动提取,需要配合自定义处理器:
java
public class TableAwareWordReader extends WordDocumentReader {
public TableAwareWordReader(Resource resource) {
super(resource, WordDocumentReaderConfig.builder().build());
}
@Override
public List<Document> read() {
List<Document> docs = super.read();
// 手动解析 Word 中的表格并追加到文本
// Apache POI 解析 XWPFTable 逻辑...
return docs;
}
}五、Markdown 解析:MarkdownReader
Markdown 是最干净的格式,解析时能保留结构化语义。
java
@Bean
public DocumentReader markdownReader() {
return new MarkdownReader(
PathUtils.getResourceFile("classpath:/docs/api-guide.md"),
// 自定义元数据提取器:从 YAML Front Matter 读取
new DefaultContentAggregator(
MetadataMode.ALL,
null // frontMatterExtractor
)
);
}Markdown 解析的额外优势:
- 标题层级自动映射到 Document metadata 的
headings字段 - 代码块自动识别并标记语言类型
- 支持 YAML Front Matter 元数据提取
六、HTML 网页解析
java
@Bean
public DocumentReader webPageReader() {
return new HtmlDocumentReader(
"https://docs.company.com/api-reference/auth",
HtmlDocumentReaderConfig.builder()
.charset(StandardCharsets.UTF_8)
.xpathSelector("//div[@class='article-content']") // 只提取正文区域
.build()
);
}七、JSON 文档解析
适合处理结构化数据源,如日志、产品目录:
java
@Bean
public DocumentReader jsonReader() {
return new JsonReader(
PathUtils.getResourceFile("classpath:/docs/products.json"),
// 每条记录中的文本字段
List.of("name", "description", "specs"),
// 元数据字段(不参与 Embedding,但会附加到 Document)
List.of("category", "price", "sku"),
"product_id" // 唯一 ID 字段
);
}八、批量文档读取工厂
生产环境中通常需要一次性读取整个目录的文档:
java
@Component
public class DocumentLoaderFactory {
@Value("${spring.ai.rag.document.path}")
private String documentPath;
public List<Document> loadAllDocuments() {
List<Document> allDocs = new ArrayList<>();
// 读取 PDF
loadDirectory(documentPath + "/pdf", "*.pdf",
() -> new PdfReader(PathUtils.getResourceFile("classpath:")));
// 读取 Word
loadDirectory(documentPath + "/word", "*.docx",
() -> new WordDocumentReader(PathUtils.getResourceFile("classpath:")));
// 读取 Markdown
loadDirectory(documentPath + "/markdown", "*.md",
() -> new MarkdownReader(PathUtils.getResourceFile("classpath:")));
return allDocs;
}
private void loadDirectory(String path, String glob, Supplier<DocumentReader> readerFactory) {
File dir = new File(path);
if (!dir.exists()) return;
File[] files = dir.listFiles((d, name) -> name.matches(glob.replace("*", ".*")));
if (files == null) return;
for (File file : files) {
// 根据具体文件路径创建 Reader...
DocumentReader reader = readerFactory.get();
allDocs.addAll(reader.read());
}
}
}九、文本分割:TextSplitter 核心原理
文档解析完成后,需要将长文本切分为适合检索的"块(Chunk)"。这是整个 ETL 流程中最关键的一步,切分策略直接影响检索质量。
9.1 为什么不能直接喂整篇文档?
| 问题 | 原因 |
|---|---|
| 上下文超限 | LLM 有 Token 限制(如 GPT-3.5 的 16K),超长文档塞不进去 |
| 检索精度下降 | 整篇文档主题杂糅,相关性打分不准确 |
| 成本增加 | 每次检索都带入大量无关上下文,Token 费用翻倍 |
| embedding 效果差 | 长文本 embedding 会被"平均化",失去局部焦点 |
9.2 Spring AI 内置分割器
java
// 按字符数分割(最简单)
TextSplitter characterSplitter = new CharacterTextSplitter(
500, // 每块目标字符数
50, // 块间重叠字符数(避免割裂语义)
true, // 是否保留分隔符
" " // 分隔符
);
// 按 Token 数分割(更精确,基于 LLM tokenizer)
TextSplitter tokenSplitter = new TokenTextSplitter(
300, // 每块目标 Token 数
50, // 重叠 Token 数
true, // 是否保留分隔符
true // 是否追加块序号
);9.3 语义感知分割:RecursiveCharacterTextSplitter
这是最推荐的生产级分割器,它按优先级尝试多种分隔符,逐层拆分:
尝试按 "\n\n\n" (三级标题)分割
↓ 如果块太大
尝试按 "\n\n" (段落)分割
↓ 如果块太大
尝试按 "\n" (换行)分割
↓ 如果块太大
尝试按 " " (句子)分割
↓ 如果块太大
按字符数硬截断(最后手段)
java
@Bean
public DocumentReader semanticSplitterReader() {
// 推荐配置:重叠 20%,保留段落边界
return new RecursiveCharacterTextSplitterReader(
pdfReader(),
RecursiveCharacterTextSplitterReaderConfig.builder()
.chunkSize(500) // 每块目标字符数
.chunkOverlap(100) // 重叠 20%
.separators(List.of("\n\n", "\n", "。", "!", "?", " "))
.keepSeparator(true)
.build()
);
}9.4 Markdown 语义分割:保留标题层级
对于 Markdown 文档,用 MarkdownHeaderTextSplitter 可以在标题处自然断点:
java
List<Document> docs = markdownReader().read();
MarkdownHeaderTextSplitter splitter = new MarkdownHeaderTextSplitter(
List.of(
// 按 ## 二级标题分割
new HeaderMetadata("#", 1),
new HeaderMetadata("##", 2),
new HeaderMetadata("###", 3)
),
300, // fallback chunk size
50 // overlap
);
List<Document> chunks = splitter.split(docs);
// 每个 chunk 自动带上 headings metadata: ["Spring AI", "安装配置"]十、自定义分割器:SentenceTransformers 语义分割
当对语义完整性要求极高时,可以用 Embedding 模型做语义感知分割------只在新主题出现时才断点:
java
@Component
public class SemanticChunker {
private final EmbeddingModel embeddingModel;
private final double similarityThreshold = 0.7;
public List<Document> semanticChunk(String text, List<String> sentences) {
List<List<String>> chunks = new ArrayList<>();
List<String> currentChunk = new ArrayList<>();
for (String sentence : sentences) {
if (currentChunk.isEmpty()) {
currentChunk.add(sentence);
continue;
}
// 计算当前句子与 Chunk 最后一句的语义相似度
double similarity = computeSimilarity(
currentChunk.get(currentChunk.size() - 1),
sentence
);
if (similarity < similarityThreshold) {
// 低于阈值,创建新 Chunk
chunks.add(new ArrayList<>(currentChunk));
currentChunk.clear();
}
currentChunk.add(sentence);
}
if (!currentChunk.isEmpty()) {
chunks.add(currentChunk);
}
return chunks.stream()
.map(c -> new Document(String.join("", c)))
.collect(Collectors.toList());
}
private double computeSimilarity(String s1, String s2) {
Embedding e1 = embeddingModel.embed(s1);
Embedding e2 = embeddingModel.embed(s2);
return cosineSimilarity(e1, e2);
}
private double cosineSimilarity(Embedding a, Embedding b) {
double dot = 0, normA = 0, normB = 0;
for (int i = 0; i < a.getValues().length; i++) {
dot += a.getValues()[i] * b.getValues()[i];
normA += a.getValues()[i] * a.getValues()[i];
normB += b.getValues()[i] * b.getValues()[i];
}
return dot / (Math.sqrt(normA) * Math.sqrt(normB));
}
}十一、分割策略实战参数建议
| 文档类型 | chunk_size | chunk_overlap | 推荐分割器 |
|---|---|---|---|
| 短文档(FAQ、条款) | 300~500 | 50~100 | CharacterTextSplitter |
| 长文本文档(手册、论文) | 500~800 | 100~200 | RecursiveCharacterTextSplitter |
| 结构化文档(Markdown) | 400~600 | 80~120 | MarkdownHeaderTextSplitter |
| 代码库 | 200~400 | 50~100 | CodeTextSplitter |
| 对话记录 | 800~1500 | 200~300 | TokenTextSplitter |
十二、完整 ETL 流程示例
java
@Service
public class DocumentETLService {
private final VectorStore vectorStore;
private final DocumentReader pdfReader;
private final DocumentReader markdownReader;
@PostConstruct
public void etlAndIndex() {
List<Document> allDocs = new ArrayList<>();
// Step 1: Extract - 读取多源文档
allDocs.addAll(pdfReader.read());
allDocs.addAll(markdownReader.read());
// Step 2: Transform - 语义分割
RecursiveCharacterTextSplitter splitter =
new RecursiveCharacterTextSplitter(600, 120);
List<Document> chunks = splitter.split(allDocs);
// 为每个 Chunk 添加来源元数据
for (Document chunk : chunks) {
chunk.getMetadata().put("indexed_at", LocalDateTime.now().toString());
}
// Step 3: Load - 存入向量数据库
vectorStore.add(chunks);
System.out.println("ETL 完成:处理文档 " + allDocs.size() + " 篇,生成 Chunk " + chunks.size() + " 个");
}
}十三、本章小结
| 知识点 | 核心要点 |
|---|---|
| DocumentReader 体系 | 统一接口,Pdf/Word/Markdown/HTML/JSON 各有实现 |
| 元数据保留 | 页码、章节、来源路径等元数据对可溯源性至关重要 |
| chunk_size 选择 | 500~800 是生产环境最常见的区间 |
| chunk_overlap | 重叠 15~25% 避免语义割裂 |
| 分割策略优先级 | RecursiveCharacterTextSplitter > MarkdownHeaderTextSplitter > Character |
| 语义分割 | SentenceTransformers 方案适合高精度场景 |
下一篇预告:《七、Embedding 向量化与向量数据库选型对比》------ 深度对比 Milvus、Pinecone、Redis、Chroma、Elasticsearch 的适用场景与 Spring AI 集成方式。
📌 系列导航
📎 示例说明:本文侧重 ETL 管道与分割策略,若你准备做完整知识库系统,建议继续阅读第七、八篇。