将机器学习研究转化为工业部署时,四个反复出现的差距始终存在(图1)。
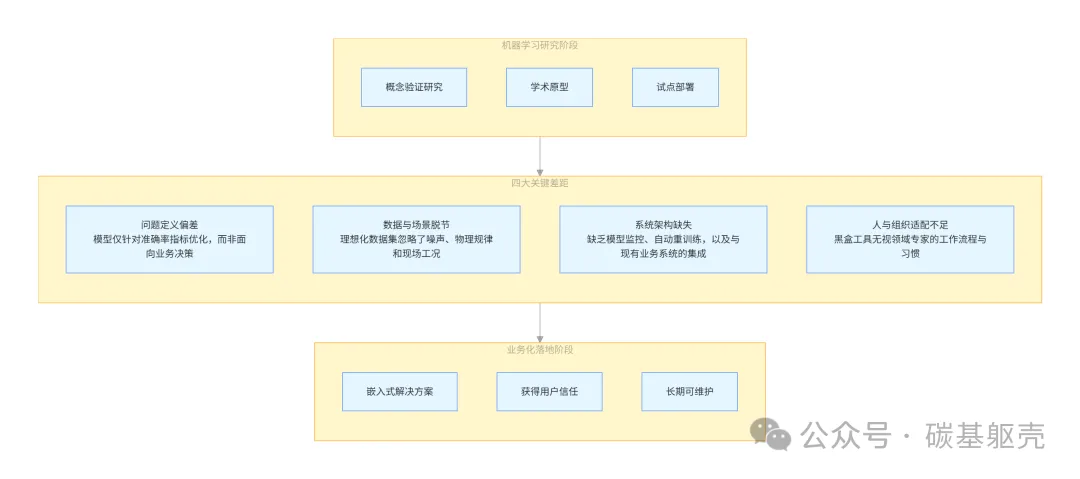
问题表述差距。 许多研究围绕算法上有趣的问题而非决策驱动的问题展开。在历史生产数据上最大化准确性指标可能会产生优雅的结果,但不一定能帮助生产工程师决定如何调整节流阀设置或对加密井候选井进行排序。当研究优化模型而非决策时,它往往只提供洞察而非影响。
数据与情境差距。 学术模型经常依赖理想化的数据集,这些数据集不能反映现场条件。在实践中,油气数据稀疏、有偏差、被计划外/意外的运营事件中断,并受物理规律影响。在稳态假设下训练的模型在面对修井、关井、传感器漂移或不断变化的运营政策时难以应对。如果不嵌入领域情境和物理约束,即使高度准确的模型也可能在生产中灾难性地失败。
架构差距。 一个工作的Python或MATLAB笔记本不是可部署的系统。许多研究工作在模型离线表现良好后就停止了,而没有解决如何监控、重新训练或将其集成到现有平台中。模型漂移、数据质量下降和不断变化的运营制度是现实,即使对于拥有成熟或先进机器学习基础设施的技术公司也是如此。在油气行业,系统更复杂、反馈循环更慢,忽视生命周期考虑几乎注定失败。
人员与组织差距。 也许最关键的是,研究往往忽视最终用户工作流程和可解释性要求。"传统运营与机器学习工具之间的接受差距"并非真正关于变革阻力;它主要是关于工具不符合领域专家------油藏工程师、钻井主管和生产技术人员------实际工作方式。一个没有解释就提供建议的黑箱模型,无论其统计性能如何,都不太可能被使用。成功的解决方案增强领域专业知识,而非试图取代它。
如何在现场使机器学习发挥作用
弥合这些差距需要改变油气领域机器学习研究的框架和执行方式(图2)。
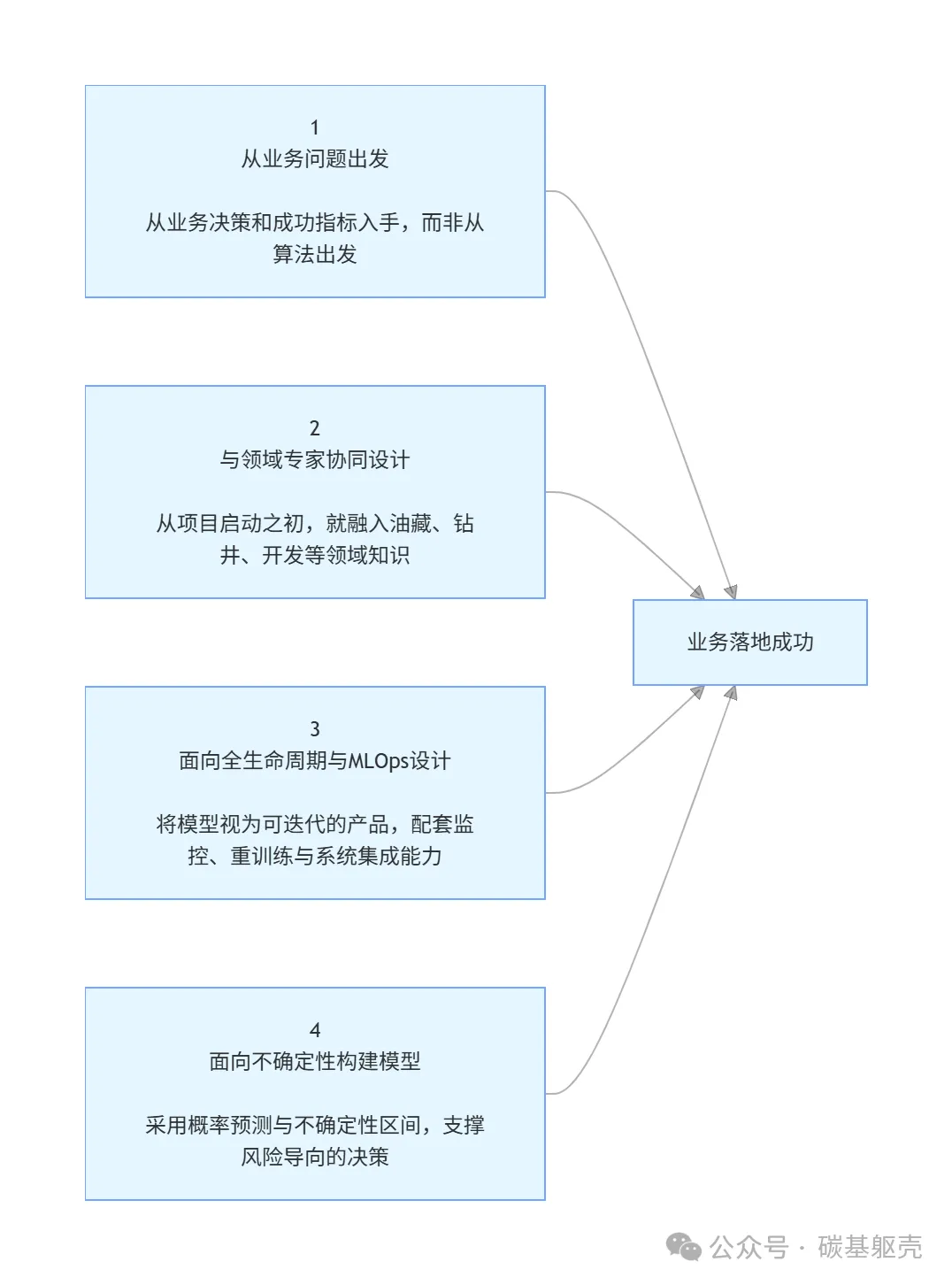
从问题出发。 研究应从明确定义的运营决策和成功指标开始。无论目标是减少非生产时间、提高采收率还是最小化停机时间,模型评估都应反映业务价值而非仅准确性。这要求研究人员在选择算法方法之前投入足够时间了解运营约束,确保问题表述本身反映工业现实。
与领域专家共同设计。 从问题界定到验证全程让油藏、钻井和生产工程师参与。他们对经验法则、运营启发式和物理约束的了解应指导特征工程、模型架构和评估标准。从一开始就纳入领域专业知识的研究产生更符合部署现实的解决方案。研究人员应将领域专家视为共同研究者,而非仅仅是数据提供者或最终用户。这意味着研究人员应记录领域知识如何影响特征选择、数据处理和工作流程集成。透明报告将技术决策与专家协作联系起来。这使嵌入领域专业知识成为公认的研究贡献。
为生命周期和MLOps设计。 模型应被视为不断演进的产品,而非静态工件。明确考虑部署架构、工作流程监控、重新训练触发器和性能下降的研究提供了通往现实世界影响的更清晰路径。正如研究机构Gartner预测的那样,75%的企业在2024年从试点转向运营化机器学习,但运营化需要研究必须预见的基础设施。因此,研究人员必须仔细概述数据管道规范,定义与运营系统的集成程序,并对模型在不同数据分布下的行为进行深入分析。遵守这些实践可实现实际工作流程中的稳健实施和适应性,从而增强有效部署和广泛采用的前景。
为不确定性构建和验证。 地下系统本质上是不确定的,机器学习研究应反映这一点。对于决策者,特别是在高风险运营环境中,概率预测、不确定性边界和基于场景的验证远比单点估计更有价值。概率方法可以比传统方法提供更准确的结果,同时产生支持风险知情决策的置信边界。建议开发团队明确描述模型相对于运营包络和安全边际的行为。他们还应包括验证研究,测试不确定性估计在分布外数据或运营制度变化期间的表现。