
在双碳战略进入深水区的2026年,园区级能源管理正面临一场从"设备联网"到"数据驱动决策"的质变。过去那种靠单体式系统堆功能、靠关系型数据库硬扛时序数据的玩法,已经撑不住百万级测点、秒级采样的真实生产场景。今天,我想和大家聊聊 MyEMS 开源能源管理系统在园区数字化项目中的真实落地经验------特别是微服务如何拆分、时序数据库如何选型,以及这些技术决策背后的工程权衡。
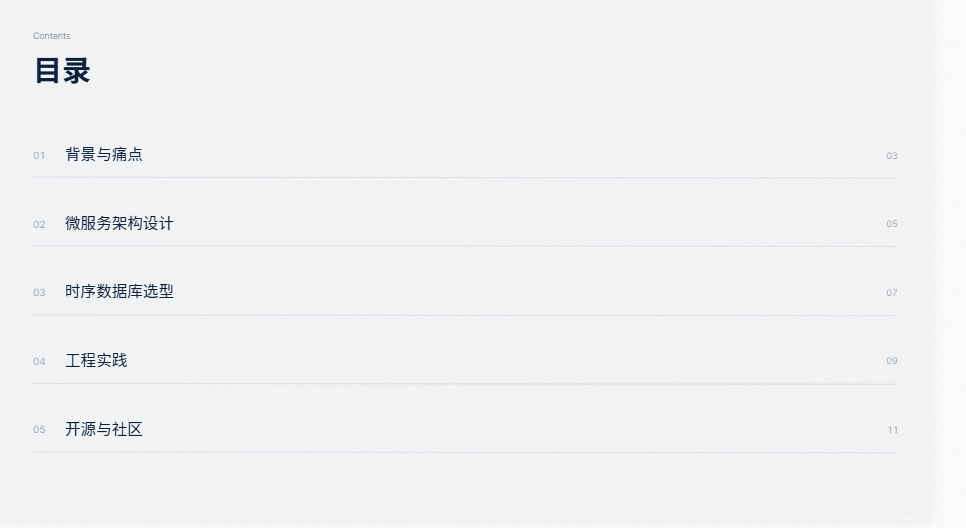
园区能源数字化的核心矛盾,从来不是"缺数据",而是"数据来了怎么处理"。一个中型工业园区,水电气热冷五表合一,加上光伏、储能、充电桩和产线设备,轻松就能涌出几十万甚至上百万个测点。传统单体架构下,采集、计算、存储、展示全挤在一个进程里,一旦某个模块阻塞,整个系统跟着卡顿甚至崩溃。MyEMS 团队早在项目初期就意识到:如果不从架构层面解耦,开源项目迟早会撞上单体应用的天花板。

微服务拆分的第一原则,不是"拆得越细越好",而是"按业务域边界对齐"。MyEMS 参考了能源管理的天然业务闭环,将系统拆分为数据采集服务、实时计算服务、时序存储服务、告警引擎、报表服务、Web 前端和运维后台七大核心域。每个域独立部署、独立扩缩容,一个园区的光伏功率预测模型升级,绝不会拖累另一个园区的空调能效分析模块。
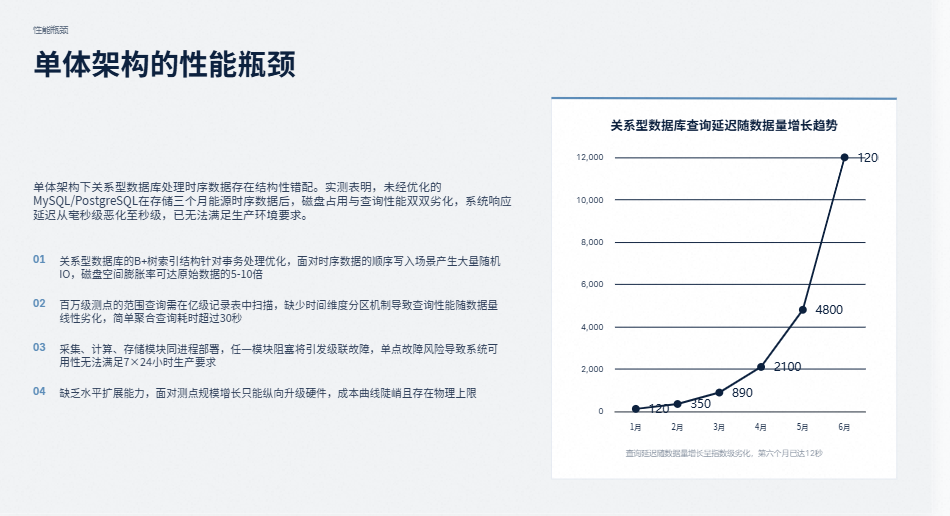
采集服务是离设备最近的触角,也是并发压力最大的入口。MyEMS 的采集层采用插件化设计,支持 Modbus、BACnet、MQTT、OPC UA 等多种协议接入。每个采集节点以独立容器运行,通过消息队列与下游解耦。这意味着即使某个老旧设备频繁掉线、重连风暴,也只会影响本地采集实例,不会把抖动传导给整个平台。

实时计算服务承担了能源流向的实时分析任务。园区里的峰谷平电价切换、需量预警、碳排放因子实时折算,都要求计算层具备低延迟响应能力。MyEMS 将计算逻辑拆分为有状态流处理和无状态规则引擎两条支线:流处理负责滑动窗口聚合,规则引擎负责阈值判断与联动控制。两者通过 gRPC 通信,既保证了吞吐量,又避免了状态耦合。

时序数据存储是整个架构的底座,也是最容易踩坑的地方。我们在早期调研中发现,很多团队直接把能源时序数据塞进 MySQL 或 PostgreSQL 的普通表,结果三个月数据量就把磁盘和查询性能双双拖垮。MyEMS 最终选择了 InfluxDB 作为主时序存储,PostgreSQL 作为关系型元数据存储的混合架构。这个决策不是拍脑袋,而是基于写入吞吐、压缩率、查询模式和运维成本四维评估后的结果。

InfluxDB 在 MyEMS 中的角色非常清晰:只存"时间-标签-数值"三要素,不做复杂关联。每个测点的设备编码、车间位置、能源类型等维度信息,全部放在 PostgreSQL 里通过外键关联。查询时先走关系库定位设备范围,再下推时间区间到 InfluxDB 做聚合。这种"元数据归关系库、量测数据归时序库"的分层策略,让两类数据库都做自己最擅长的事。

选型过程中,我们也深度评估过 TimescaleDB。作为 PostgreSQL 的扩展,TimescaleDB 在 SQL 兼容性和生态成熟度上确实有优势,对于已经深度投入 PG 技术栈的团队来说,迁移成本更低。MyEMS 在部分轻量级部署场景中保留了 TimescaleDB 的适配分支,让用户可以根据自身运维能力二选一。这种"主推荐 + 备选"的开放策略,正是开源项目应有的包容姿态。
微服务架构带来的另一个好处,是技术栈可以按场景择优。MyEMS 的告警引擎对延迟极其敏感,我们选用了 Redis 做滑动窗口计数,配合 Lua 脚本实现毫秒级触发;报表服务则偏向批量离线处理,直接用 Python 生态的 Pandas + ClickHouse 做宽表聚合。不同服务各取所需,再也不用被单体框架的技术选型绑架。

容器化部署是微服务落地的最后一公里。MyEMS 提供完整的 Docker Compose 编排模板和 Kubernetes Helm Chart,园区运维团队可以在半小时内完成从代码到环境的完整搭建。每个服务的镜像都遵循多阶段构建,Alpine 基础镜像把体积控制在百兆以内,边缘网关的弱网环境下也能快速拉取和更新。

服务网格不是必选项,但可观测性一定是。MyEMS 在微服务间引入了分布式链路追踪,采集、计算、存储的调用链全程可视化。当某个园区的能耗数据出现延迟,运维人员可以秒级定位是采集端网络抖动,还是计算队列堆积,抑或是时序库写入瓶颈。这种"全链路可观测"的能力,在传统单体系统里几乎不可能实现。

时序数据的压缩与降采样,是长期运行后的必答题。MyEMS 内置了自动降采样策略:原始秒级数据保留七天,分钟级聚合保留三个月,小时级聚合长期归档。InfluxDB 的连续查询配合 Retention Policy,让存储成本随时间线性增长而非指数爆炸。一个运行两年的园区项目,历史数据量可以控制在数百 GB 级别,普通 SSD 即可承载。

微服务拆分也带来了分布式事务的挑战。能源结算场景下,一次峰谷电费计算可能同时涉及计量数据校验、费率规则匹配、账单生成三个服务。MyEMS 采用 Saga 模式处理长事务,通过事件总线实现最终一致性。虽然牺牲了强事务的即时保证,但换来了系统整体的可用性和分区容错,这对 7×24 小时运行的园区能源系统来说更为关键。

API 网关是微服务对外的统一门面。MyEMS 的网关层不仅承担路由和负载均衡,还集成了园区多租户的权限隔离。每个入驻园区的企业租户,只能访问自己授权范围内的能耗数据。网关通过 JWT Token 解析租户标识,再下推到各服务的行级权限过滤,实现真正的数据安全边界。

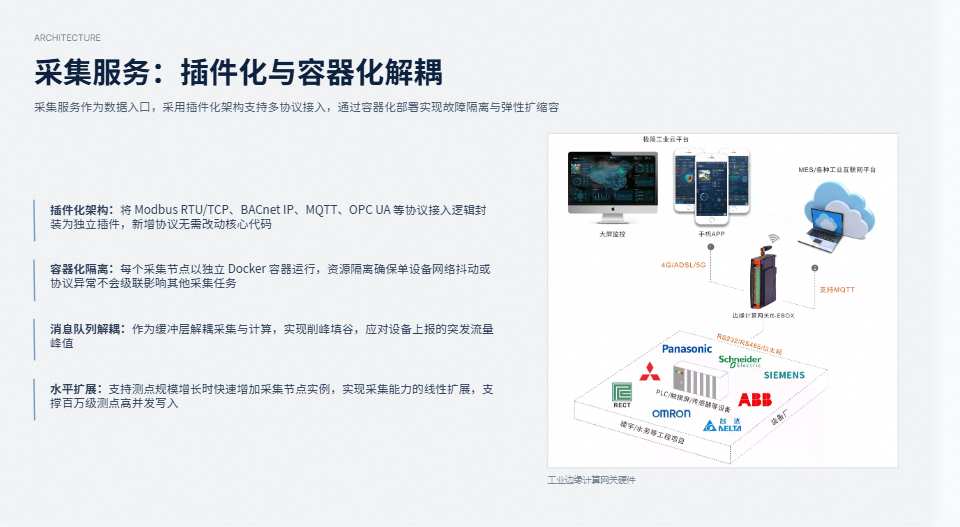
边缘计算是园区场景绕不开的刚需。很多工厂对数据上云有顾虑,或者网络条件根本不允许全量上云。MyEMS 支持云边端三层架构:边缘节点部署轻量级采集与预处理服务,只向云端同步聚合后的指标;云端保留全量元数据和全局分析能力。边缘到云端的通信采用 MQTT over TLS,断网时本地缓存、恢复后自动补传,确保业务连续性。
时序数据库的查询优化,往往比写入更考验设计功力。MyEMS 的前端仪表盘常用"最近一小时趋势"和"同比环比"两类查询,InfluxDB 的 Tag 索引策略天然适合前者,而后者需要预计算中间表。我们在计算服务里引入了物化视图机制,每天凌晨对高频查询模式做预聚合,把前端加载时间从秒级压到百毫秒级。

开源项目的生命力在于社区反馈驱动迭代。MyEMS 在 GitHub 上维护了详细的架构决策记录(ADR),每一次微服务边界调整、每一次存储引擎升级,都有完整的背景说明和回滚方案。园区开发者如果在二次开发中遇到拆分粒度或选型困惑,可以直接查阅 ADR,理解设计背后的 trade-off,而不是盲目照搬。

双碳目标下的碳排放核算,对数据精度提出了更高要求。园区不仅要算"用了多少电",还要算"这些电在特定时间、特定区域的碳排放因子是多少"。MyEMS 将碳因子库独立为微服务,支持按电网调度区、按小时粒度动态更新因子值。时序库里的每一度电,都能精确映射到对应的碳排放当量,满足企业级碳盘查的审计要求。

微服务架构让 A/B 测试和灰度发布成为可能。MyEMS 的新版预测算法可以先在 5% 的园区节点上试运行,对比旧版准确率后再全量推广。这种渐进式演进的能力,对于需要持续优化能效的园区运营方来说,意味着更低的试错成本和更稳的业务节奏。

时序数据的冷热分层,是成本优化的利器。MyEMS 支持将三个月前的历史数据自动迁移到对象存储(如 MinIO 或 S3),查询时通过透明代理层自动路由。热数据走本地 SSD 保证实时性,冷数据走对象存储降低成本,中间温数据用网络存储过渡。园区可以根据预算和查询模式灵活配置分层策略。

微服务的健康治理离不开自动化测试。MyEMS 为每个服务维护了独立的单元测试和契约测试套件,采集服务的 Modbus 模拟器、计算服务的流数据生成器、存储服务的容器化数据库实例,全部集成在 CI 流水线中。每次代码提交都会触发全量契约验证,确保服务间接口的向后兼容。
园区能源数字化不是一锤子买卖,而是持续运营的过程。MyEMS 的微服务架构允许客户按需订阅功能:今天只上能耗监测,明天叠加碳排放管理,后天接入需求响应。每个新功能以独立服务形态插入,不影响既有业务。这种"渐进式数字化"路径,极大降低了园区管理者的决策门槛。

最后想说的是,技术选型没有银弹,架构演进也没有终点。MyEMS 从一体化走到微服务,从关系库走到时序库,每一步都是真实项目里踩过坑、流过汗之后的反思。我们把这些经验开源出来,不是为了标榜某种技术栈的优越,而是希望给正在园区数字化路上摸索的开发者朋友们,提供一份经过验证的参考蓝图。