时序链路预测:预测未来会不会出现某个事件关系。
事件演化预测:预测某个话题会不会扩散到某个实体、群体或平台。
一、TGB 2.0: A Benchmark for Learning on Temporal Knowledge Graphs and Heterogeneous Graphs
一个新的benchmark(基准测试平台),一个新的基准测试框架,专门针对时态知识图和时态异构图上的未来链接预测方法(future link prediction)进行评估。
这篇论文的背景不是普通图,而是动态,多关系图。
TGB2.0的中心任务:多关系(人和人之间可以是"合作""敌对""发帖回复")时序图(关系还会随着时间变化)上的未来连接预测。
TGB 2.0 的价值 = 数据 + 评测协议 + 自动化工具链。
①:数据 TGB 2.0 的数据集在节点数、边数、时间戳数上都明显大于现有数据集。8 个新数据集,来自 5 个领域,最大有 5300 多万条边。
②:提供了评测协议:怎么划分训练/验证/测试,怎么做负采样,用什么指标,怎么过滤时间冲突,怎么保证别人复现出来一样的结果。
1、预备知识
①:Temporal Knowledge Graph(TKG)
TKG 是一组四元组 (s, r, o, t)。
s = subject,头实体
r = relation,关系类型
o = object,尾实体
t = 时间戳
例:(China, visits, France, 2024-01-10)
TKG 的重点是:边有类型,而且有时间
②:Temporal Heterogeneous Graph(THG)
THG 也是四元组集合,但额外有一个**节点类型函数,**给每个节点分配固定类型。
THG=TKG+节点类型
③:Temporal Graph Forecasting / Extrapolation
给定过去的时序多关系图,目标是预测未来时间的边,这个任务被表述成排序问题。 论文不是做简单 yes/no 预测,而是做candidate ranking。
④:Time Representations
事件表示有两种
(1) 离散时间:按时间切成快照
TKG用的是离散时间,因为很多知识图谱事实天然按天、年、时期记录,适合做 snapshot。而且很多 TKG 方法本来就是为离散时间设计的。
(2) 连续时间:把图看成按连续时间到来的事件流
THG用的是连续的时间,因为很多异质交互数据本来就是秒级事件流,比如:用户几点几分安装了 app,用户几点几分回复了帖子,谁在哪一秒打开/关闭了 PR。作者认为连续表示保留信息更多,因为连续可以再离散化,但离散后丢失的信息很难恢复。
二、TGB-Seq Benchmark: Challenging Temporal GNNs with Complex Sequential Dynamics
三、Improving Temporal Link Prediction via Temporal Walk Matrix Projection
现实中的很多动态系统都可以建模成时间图,节点是实体,带时间戳的边是交互;时间链路预测就是利用历史交互预测未来交互。
注:传统的图神经网络学习每个节点节点自己的表示,然后再把两个表示拿去做匹配,这样经常抓不住 pairwise information(节点对特有的信息)普通 GNN 更擅长表示"这个节点周围长什么样",但链路预测需要的是"这两个节点之间有什么特殊关系"。
根据上面问题引出相对编码
相对编码(relative encoding) 即为图中每个相关节点加上一个针对当前待预测边的附加特征
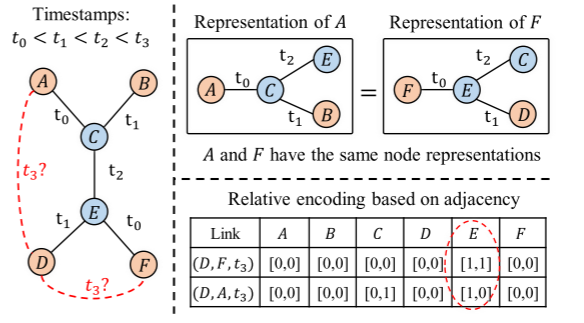
例:假设现在要预测 (D, F, t3) 和 (D, A, t3) 哪个更可能。
如果某个中间节点 E 同时和 D、F 都有关系,那么对预测 D-F 来说,E 的"重要性"就更高。
这种"对当前目标边来说,哪个节点更关键"的信息,就能通过相对编码表达出来。
即相对编码在对图中的每个节点贴一个标签:对当前这条候选边来说,我离左端点多近?我离右端点多近?我是不是它们的共同邻居?我跟它们之间有多少时间路径?
问:这个相对编码和注意力GAT有啥区别呢
GAT 的注意力是在做"聚合邻居时,给哪个邻居更大权重"。
相对编码(relative encoding)是在做"对当前要预测的这条边 (u,v),图里每个节点 w 跟 u/v的关系是什么"。
论文中提到:如上图所示A 和 F 局部结构很像,如果只靠普通邻居聚合,它们可能学出几乎一样的表示;但对候选边 (D,F) 和 (D,A)来说,中间节点 E 的相对编码不同,因此模型就能分清 D 更可能连谁
GAT 更像是消息传递的加权规则,相对编码更像是给节点补充一个'和当前目标边有关'的额外特征。论文里明确说了:如果只是独立地做邻居聚合,学出来的节点表示可能抓不住这对节点之间特有的 pairwise information;相对编码就是为了解这个问题,被作为额外节点特征注入进去的。
1、相对编码的三个缺陷
①:概念上不统一。过去的方法来自不同 heuristic(经验启发),彼此之间缺乏统一理解。
这导致我们虽然知道它们都有效,但不知道它们究竟在同一个更高层概念里是什么关系。
即不同的作者凭经验觉得某种关系可能有用,于是就那样设计了编码。
- "共同邻居可能重要" → 那就编码邻接关系
- "多步 walk 可能重要" → 那就数 temporal walk 条数
- "最短时序路径可能重要" → 那就做 reachability / shortest-walk 风格编码
- "被采样 walk 访问的概率可能重要" → 那就做 visit probability
②:设计上忽略时间。很多方法只基于结构连接关系构造相对编码,比如邻居、最短路径、walk 数量。但时间图里"最近发生"常常比"很久以前发生"更重要。
③:计算上低效 很多方法需要频繁图查询,甚至每个目标边都重新构造一遍编码。这会让相对编码本身成为推理瓶颈。
2、三大贡献
①:统一视角。把不同相对编码统一写成 时间随机游走矩阵的函数。这相当于给这个研究方向建立了一个"公共语言"。
②:新方法 TPNet。提出考虑时间衰减的新 temporal walk matrix,并用随机特征传播高效维护。
③:理论与实验分析。证明维护出来的节点表示,本质上是时间游走矩阵的随机投影,而且还能较好保留矩阵行之间的内积。实验则证明了精度和速度都好。
3、相对编码统一框架
传统方法:node-wise 相对编码:link-wise
①:node-wise

②:link-wise
link-wise 方法会为每个相关节点 w 构造一个相对编码 把它拼接到节点特征里,再去编码。不是直接说E这个节点是什么,而是说E对当前预测的边(u,v)有多重要,模型终于知道"当前在预测哪一对点",而不是盲目学习一个通用节点表示 所以会更强。

相对编码=从目标节点触发,到某节点w的多阶时间游走统计的某种函数
4、核心方法
TPNet(时间游走矩阵):在当前时刻 t,节点 u 和节点 v 之间,通过"符合时间顺序的路径"连接得有多强。
这里的"连接强"不是只看有没有路,还要看:
- 路有多少条
- 路有多长
- 路上的边是不是比较新。
所以它不是普通邻接矩阵,而是一个时间游走矩阵。
(1)最外层公式
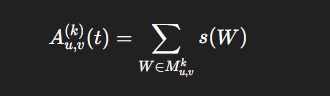
①:A表示时间游走矩阵,行是起点节点,列是终点节点,表里的每个数字,表示"从这个起点到这个终点的某种时序连接强度"。
②:k表示只看 k-step temporal walk。
"k-step" 就是"走 k 步"。
例如:
- A(1):只看 1 步的 temporal walk
- A(2):只看 2 步的 temporal walk
- A(3):只看 3 步的 temporal walk
所以不同的 ,对应不同"长度"的时序路径统计。
③:
从节点 u 到节点 v,在当前时刻 t 看过去,有多少"有价值的" k 步 temporal walk。
④:括号里的 t
这里的 t 表示当前时刻。这个很重要,因为 TPNet 是时间图模型。同样一条历史路径,在不同当前时刻去看,它的重要性会变。
比如:
- 在今天看,一条昨天的边很新
- 在一个月后看,同一条边就没那么新了
所以矩阵值依赖当前时刻 t。
⑤: 不是一条路径 而是一堆路径
所有从 u 到 v 的 k-step temporal walk 的集合。
⑥:W表示这堆 temporal walk 里面的某一条具体 walk
这里的w是一个序列 里面每一项都是 "节点"+"时间"。
⑦:s(W) 表示
这条 temporal walk W的分数。
也就是说,TPNet 不会把每条 walk 都当成一样重要。它会先给每条 walk 打分,再把所有 walk 的分数加起来。
整个意思:从 u 到 v 的所有 k 步 temporal walk,每条 walk 算一个分,把这些分全部相加。
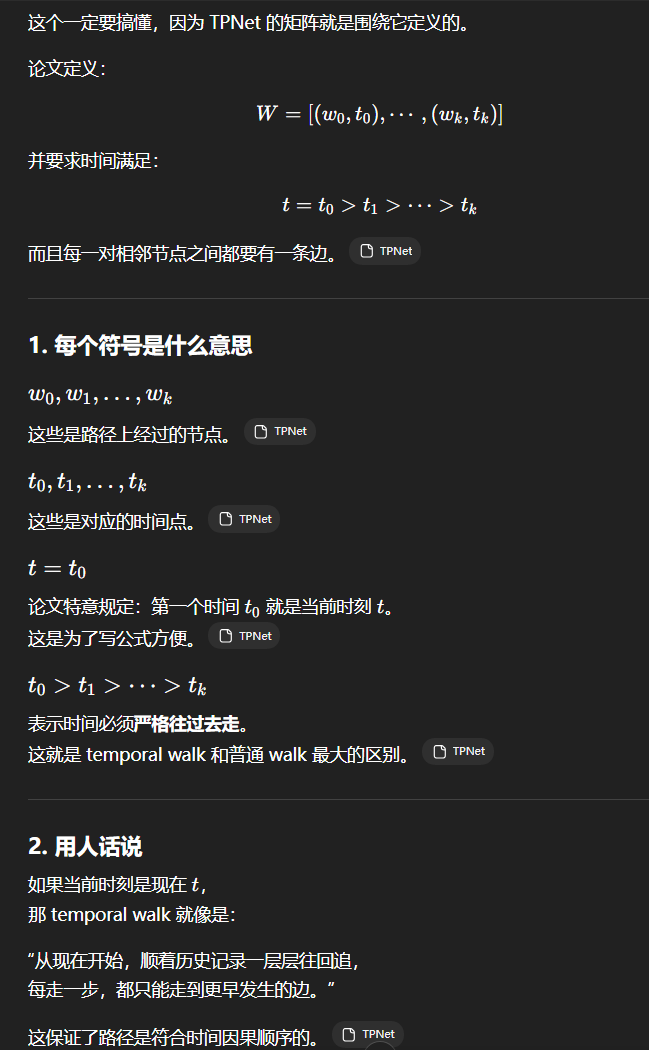
(2)什么叫做 temporal walk
(3) TPNet给一条walk怎么打分
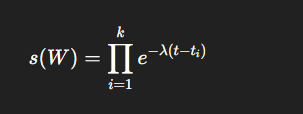
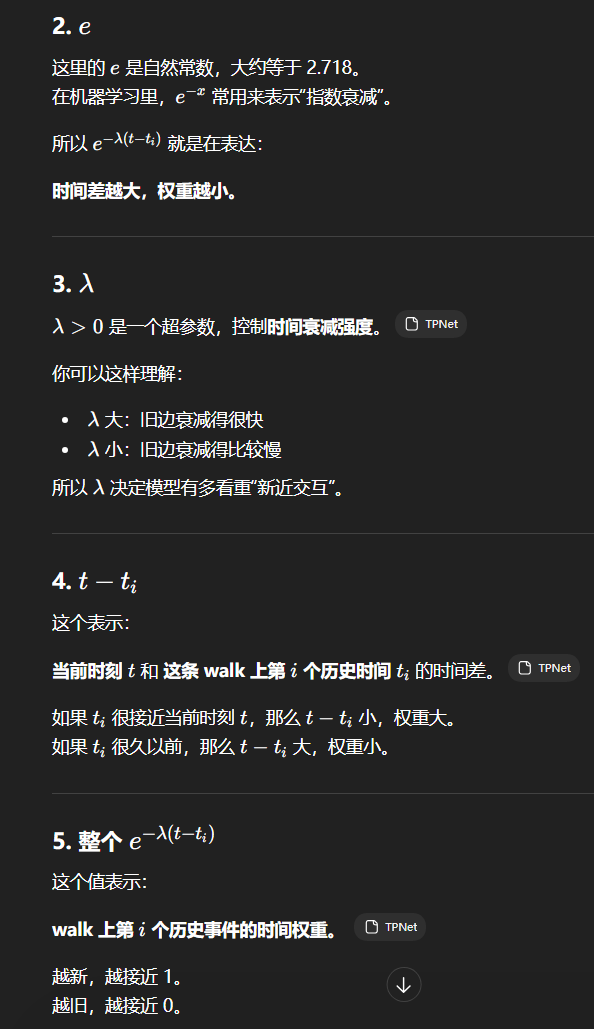
注:为什么要把这些权重乘起来
因为一条 walk 由很多步组成。TPNet 认为一条路径是否重要,不只看其中一步,而要看整条路径上的每一步是不是都足够新。如果一条 walk 里有好几步都非常久远,那这些衰减因子一乘,整条 walk 的分数就会很小。
所以:一条 walk 想得高分,最好整条路径都比较"新"。
公式的整个意思:

记住:

5、举个完整的例子:

6、如何保存信息
为什么不直接存整个游走矩阵
因为这个矩阵太大,而且太难算,它不是一个数,而是一整张表


虽然没有把大矩阵完整存下来,但很多重要的"相似度信息"还在。
这就让后面"从矩阵里读出相对编码"成为可能。
7、相对编码
