这一篇要解决一个非常关键的问题:
图像为什么能送进神经网络?
你平时看到的是"人、车、猫、路灯、天空"。
但神经网络并不直接看到这些语义,它先看到的是:
按规则排好的数字。
所以这一篇的核心,不是教你写代码,而是把下面几件事讲清楚:
-
图像为什么本质上是数字
-
宽、高、分辨率在说什么
-
什么是通道
-
为什么彩色图像常写成
[3, H, W] -
tensor 和图像到底是什么关系
-
batch 是什么
-
resize、crop、标注框为什么和图像表示有关
如果这一篇弄明白了,后面你再看 YOLOv8 的输入、输出、训练数据、特征图,就会顺很多。
一、为什么要先学"图像怎么表示"
很多初学者一开始学 YOLOv8,会先碰到这些词:图像尺寸、通道、shape、tensor、batch、
resize、坐标、标注框。
如果这些词只是"眼熟",后面很容易变成这样:
-
会跑模型
-
会看结果图
-
但不知道模型到底吃进去的是什么
-
也不知道为什么图像一会儿变成
[3, 640, 640],一会儿又变成[16, 3, 640, 640]
所以这一步其实是在补"视觉任务的底层输入逻辑"。
先把下面几件事真正弄明白:
**•**一张图为什么可以用数字表示
**•**什么是宽、高、通道
**•**为什么彩色图像经常写成 3, H, W
**•**tensor 和图像之间到底是什么关系
**•**batch 又是什么,为什么训练时经常一次送多张图
**•**resize、crop、标注框这些操作为什么和图像表示密切相关
可以先记一句总纲:
在深度学习里,图像不是按"照片"处理的,而是按"多维数字数据"处理的。
二、图像为什么本质上是数字
你看到一张图,会觉得它是连续的、自然的、完整的。但在计算机里,它其实是由很多很多小格子组成的。
这些小格子,就叫像素(pixel)。
你可以先把像素想成:
图像里最小的一个小点。
整张图就是很多像素排成的一个网格。
1. 灰度图最容易理解
如果是一张灰度图,那么每个像素只需要一个数,就能表示它有多亮。这个数越小,越偏黑;这个数越大,越偏白。最常见的 8 位图像里,像素值通常落在 0 到 255 之间。
比如:
-
0:很黑
-
255:很白
-
中间值:不同程度的灰
所以一张大小为 H×W 的灰度图,本质上就可以写成一个二维表:H 行,W 列。

图 1 灰度图像可以看成一个二维数字表,每个数字对应一个像素强度
2. 这一步很重要
这一步一定要真正理解:
图像之所以能进入神经网络,不是因为神经网络会直接看"风景"或"人脸",而是因为图像可以先表示成数字。
也就是说:
-
图像 → 像素
-
像素 → 数值
-
数值 → tensor
-
tensor → 输入网络
这才是它进入深度学习的路径。
三、宽、高、分辨率,到底在说什么
这一组词特别常见,而且后面你看数据集、看训练参数、看模型输入尺寸时都会碰到。
1. 宽和高
如果一张图写成 640 × 480,通常表示:
-
宽
W = 640 -
高
H = 480
也就是:
-
横向有 640 个像素位置
-
纵向有 480 个像素位置
整张图一共有:
个像素位置。
2. 分辨率是什么
分辨率本质上就是在描述图像有多少像素。
你可以简单理解成:
-
像素多,图像更细
-
像素少,图像更粗
3. 为什么这件事对深度学习重要
因为图像尺寸会直接影响很多事:
-
输入张量有多大
-
一次训练占多少显存
-
训练速度快不快
-
小目标能不能保留足够细节
-
resize 后目标会不会变形太明显
所以 H 和 W 不只是"图像尺寸信息",它们是后面整个视觉模型处理流程的基础。
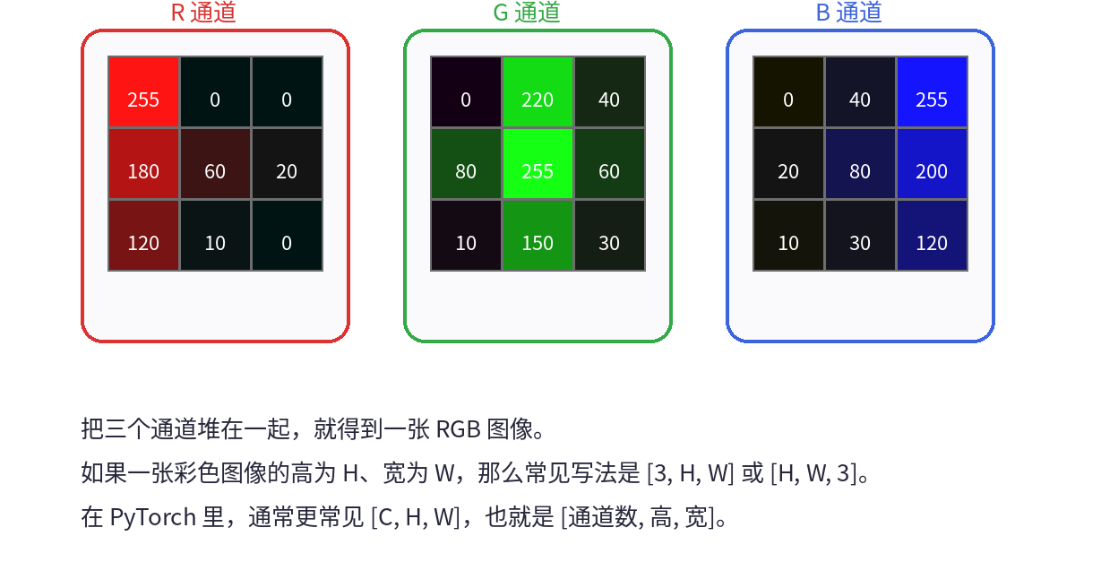
四、通道是什么,为什么彩色图像不是一个二维表
前面说灰度图时,每个像素只需要一个数。但彩色图不是这样。因为彩色图里的每个像素通常至少
要回答三个问题:红色有多强、绿色有多强、蓝色有多强。
-
R:红色强度
-
G:绿色强度
-
B:蓝色强度
1. 一个像素为什么要三个数
比如某个像素点:
-
R = 255
-
G = 0
-
B = 0
那这个点就偏红。
如果:
-
R = 0
-
G = 255
-
B = 0
那这个点就偏绿。
所以一张彩色图里,每个像素其实对应三个数字,而不是一个数字。
2. 什么叫通道
你可以把 RGB 通道理解成:
同一张图,被拆成了三层数字表。
-
一层只管红色有多强
-
一层只管绿色有多强
-
一层只管蓝色有多强
所以彩色图不再只是二维,而是三维数据。
3. 彩色图为什么常写成 [3, H, W]
因为:
-
3:通道数 -
H:高 -
W:宽
比如一张 224 × 224 的 RGB 图像,常写成:
[3, 224, 224]这表示:
-
有 3 个通道
-
高是 224
-
宽是 224
4. 为什么有时又看到 [H, W, 3]
因为不同库的数据排列习惯不一样。现阶段先记住最常见、最重要的一种:
在 PyTorch 里,更常见的是 [C, H, W]。
所以后面看到:
[3, 640, 640]就可以直接翻译成:
一张 RGB 彩色图,高 640,宽 640。
五、tensor 到底和图像是什么关系
1. tensor 就是张量
是的,tensor 就是张量。
在深度学习里,tensor 是统一的数据表示形式。图像、标签、模型参数、中间特征图、loss,最后
都可以表示成 tensor。
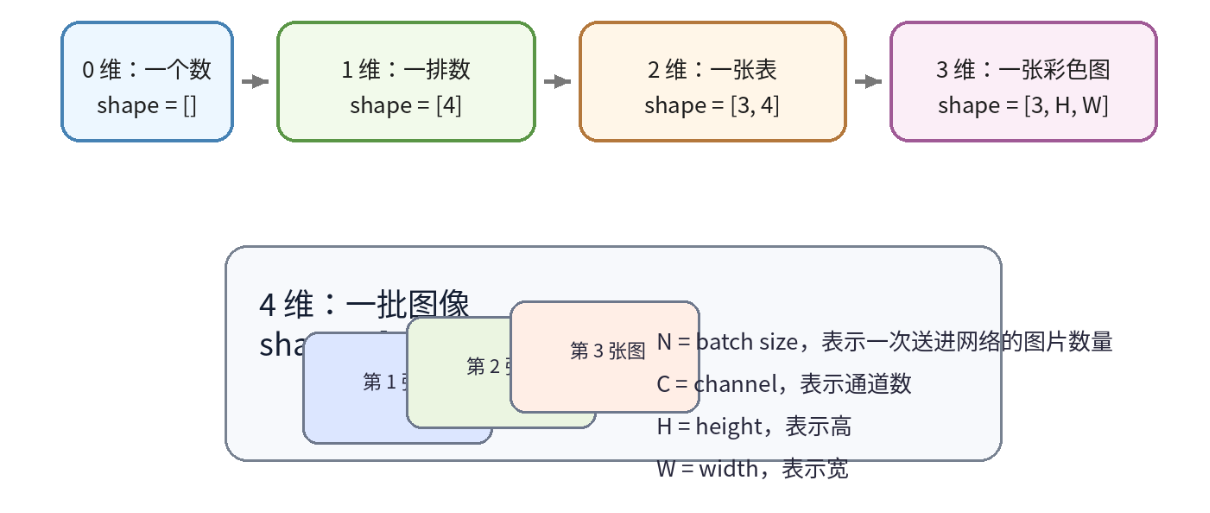
图 3 可以把 tensor 看成"不同维度的数字块";图像只是其中一种常见形式。
2. 图像为什么适合用 tensor 表示
因为图像本来就是数字块。
比如:
-
灰度图:二维数字表
-
彩色图:三维数字块
-
一批彩色图:四维数字块
这些都非常适合用 tensor 表示。
3. tensor 不只是装图像
这一点很关键,不要理解窄了。
在深度学习里,tensor 不只可以装图像,还可以装:
-
标签
-
模型参数
-
中间特征图
-
loss 的数值
-
梯度
所以更准确地说:
图像是 tensor 的一种典型应用,但 tensor 不等于"图像容器"这么简单。
4. 从维度角度怎么理解 tensor
可以这样记:
-
0 维:一个数
-
1 维:一排数
-
2 维:一张表
-
3 维:一张彩色图
-
4 维:一批图像
所以如果你看到:
[16, 3, 640, 640]这就不是"一张奇怪的图",而是:
-
16 张图
-
每张图 3 个通道
-
每张图高 640,宽 640
六、batch 是什么,为什么训练时经常不是一张图一张图地送
batch 是后面训练 YOLOv8 时一定会碰到的概念。
1. 什么是 batch
batch 可以理解成:
一次送进模型的样本数量
比如:
-
batch size = 1:每次送 1 张图
-
batch size = 8:每次送 8 张图
-
batch size = 16:每次送 16 张图
2. 为什么不用"一张图一张图"训练
因为训练神经网络时,一次只看一张图通常不太划算。
常见原因有几个:
第一,GPU 更擅长并行计算。
一次处理一批数据,通常效率更高。
第二,一次只看一张图,梯度可能抖动得更厉害。
一次看一批图,更新通常更稳定一些。
第三,很多训练框架和优化过程,本来就是围绕 batch 设计的。
3. batch 和 shape 怎么对应
如果一张 RGB 图是:
[3, 640, 640]那么 16 张图组成一个 batch 后,就会变成:
[16, 3, 640, 640]也就是说,最前面多了一维。
这最前面这一维,就是 batch 维度。
七、像素值为什么有时是 0~255,有时又变成 0~1
1. 原始图像里常见的是 0~255
无论灰度图还是 RGB 图,常见的 8 位图像里,像素值通常都在 0 到 255 之间。
2. 进入模型前为什么常做归一化
因为神经网络训练时,数值尺度更统一,通常更好优化。
所以很多时候,图像在真正输入网络前,会先做归一化,比如变成:
-
0 到 1
-
或者减均值、除方差后变成更适合训练的范围
3. 这并不表示图像内容变了
这只是数字尺度变了。
你可以理解成:
-
图像还是那张图
-
只是从"整数表示"变成了"更适合计算的数值表示"
八、resize 和 crop 到底在做什么
这两个操作在 YOLOv8 和各种视觉任务里都非常高频。
1. resize
resize 就是:
把整张图缩放到指定大小。
比如把一张原始尺寸不规则的图,统一变成:
640 × 640为什么要这么做?
因为模型通常希望输入尺寸相对统一,这样更方便批量处理和网络计算。
2. crop
crop 就是:
从原图里裁出一块区域。
比如原图里有一只猫,你只保留猫附近这一块,其他地方裁掉。
3. 它们为什么不只是"普通图片处理"
因为它们会直接影响:
-
输入图像的尺寸
-
目标在图里的相对大小
-
坐标系统
-
标注框位置是否需要同步变化
这一点特别关键。
如果你改了图,但没同步改标签,训练就会出问题。
比如:
-
图像缩放了
-
框坐标没缩放
那模型学到的就是错位的监督信号。
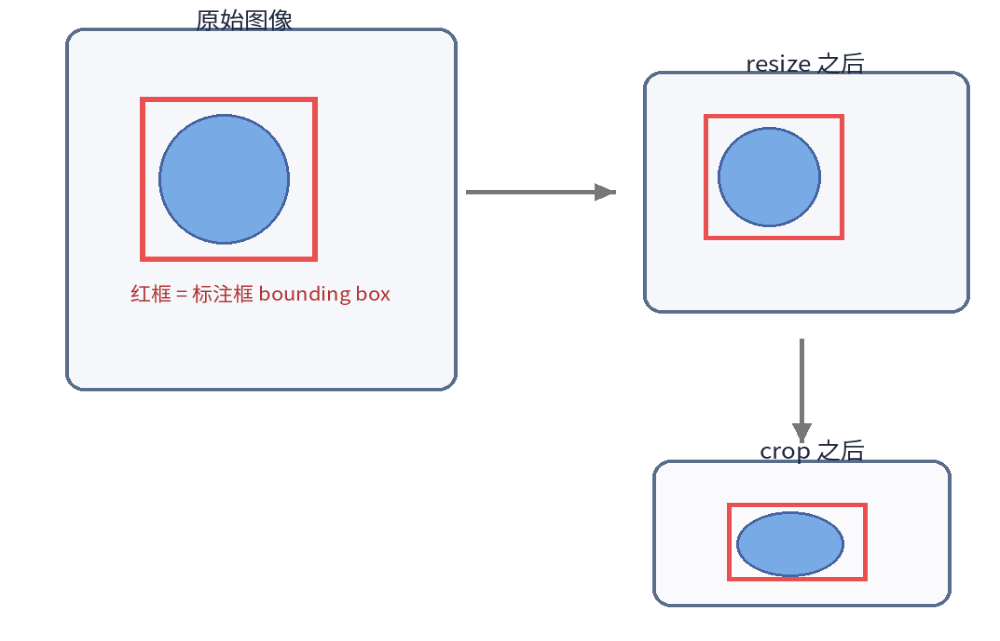
图 4 resize、crop 和标注框都和"图像怎样被表示、怎样被处理"直接相关。
九、标注框和坐标,为什么对目标检测特别重要
目标检测和普通分类最大的区别之一,就是:
它不只要判断"有什么",还要判断"在哪里"
所以检测任务里的标签,一般不只是类别名,还包括位置信息。
1. 什么是标注框
标注框就是一个矩形框,用来把目标圈出来。
比如:
-
这个框里是一只猫
-
那个框里是一辆车
-
2. 框通常怎么表示
最常见的两种方式是:
第一种,左上角 + 右下角:
x1, y1, x2, y2第二种,中心点 + 宽高:
cx, cy, w, h不管写法怎么变,本质上都是在描述:
-
这个框在哪里
-
这个框有多大
3. 图像坐标系和数学课坐标系不一样
这里你要特别注意:
在图像里,通常默认:
-
左上角是原点
-
x 向右增大
-
y 向下增大
这和很多数学图像里"y 轴向上"为正不同。
十、进入神经网络后,图像还会保持原来的样子吗
不会。
图像进入网络之后,不会一直保持"原始像素"的状态。会经过卷积、下采样、激活等一系列操作,
逐步变成新的 tensor。
这些新的 tensor,通常叫做:
特征图(feature map)
1. 什么叫特征图
图像经过网络提炼之后得到的新表示
2. 原图和特征图的区别
原图更接近真实像素。
特征图更接近模型在提取"有用信息"之后的内部表示。
比如:
-
浅层特征图更容易保留边缘、纹理、局部细节
-
深层特征图更强调整体语义,比如"像人""像车"
3. 这和 YOLOv8 有什么关系
关系非常大。
因为后面你学 YOLOv8 的 Backbone、Neck、Head 时,会一直看到"特征图"这个词。
你现在先知道一件事就够了:
特征图本质上仍然是 tensor,只是已经不是原始图像了。
十一、把这一篇和 YOLOv8 连接起来
1. [3, 640, 640]
表示一张 RGB 图像。
2. [16, 3, 640, 640]
表示一个 batch,有 16 张 RGB 图像。
3. resize 到 640
表示把图像统一缩放到模型期望的输入尺寸附近。
4. bbox 坐标
表示目标在图里的位置。
5. feature map
表示图像进入网络后,被变换成的新 tensor 表示。
所以 YOLOv8 并不是直接"看懂了照片",而是先接收图像 tensor,再对这些 tensor 做多层计算,最后预测目标框和类别。
十二、这一篇最容易混淆的点
1. 图像不等于图片文件
你磁盘里的 jpg、png 是文件格式。
真正参与神经网络计算的,是文件解码之后得到的像素数据。
2. tensor 不只装图像
图像很常见,但标签、参数、特征图、loss 也都可以表示成 tensor。
3. batch 不是"更大的一张图"
batch 表示一批样本,它是在最前面多加了一维,不是把多张图拼成一张图。
4. resize 不只是视觉上的缩放
在深度学习里,它会改变输入尺寸,也可能影响目标相对大小和坐标。
5. 标注框不是画给人看的装饰
在检测任务里,框的位置本身就是监督信息的一部分。
十三、本篇小结
-
图像在计算机里本质上是数字
-
灰度图通常是二维数据,彩色图通常有多个通道
-
在深度学习里,图像常被组织成 tensor
-
一张图常写成
[C, H, W] -
一批图常写成
[N, C, H, W] -
resize、crop、bbox、坐标都和图像表示直接相关
-
图像进入网络后,会逐步变成新的特征图 tensor