写在前面
【WeThinkIn出品】栏目专注于分享Rocky的认知思考与经验感悟,范围涵盖但不限于AI行业。
欢迎大家关注Rocky的知乎:Rocky DingAIGC算法工程师/开发工程师面试面经秘籍分享:WeThinkIn/Interview-for-Algorithm-Engineer欢迎大家Star~
AIGC时代的 《三年面试五年模拟》AI算法工程师求职面试秘籍独家资源: 【三年面试五年模拟】AI算法工程师面试秘籍
Rocky最新撰写AI Agent(AI智能体)的深入浅出全维度解析文章: 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
AIGC算法岗/开发岗面试面经交流社群 (涵盖AI Agent、AIGC图像创作、AI视频、LLM大模型、AI多模态、数字人、传统深度学习、具身智能等AIGC面试干货资源)欢迎大家加入:https://t.zsxq.com/33pJ0
大家好,我是Rocky。
核心导读
Rocky 认为,HiDream-I1 这篇论文值得看的地方,并不只是它又发布了一个 17B 参数的开源图像生成模型。更本质的信号是:图像生成模型的竞争,正在从单点画质竞争,进入"基础模型 + 加速模型 + 编辑模型 + Agent 工作流"的系统竞争。
过去两年,文生图模型的主线很清楚:更大的模型、更好的数据、更强的审美、更稳定的 prompt following。但到了今天,只会"生成一张好图"已经不够了。真实产品里,用户要的是:能快速出图、能听懂复杂指令、能低成本部署、能持续修改、最好还能在一个对话界面里完成连续创作。HiDream-I1 的意义就在这里。它不是把所有精力押在单张图的观感上,而是试图把生成、加速、编辑和 Agent 化交互放进同一套系统里。

Figure 1 是论文的能力展示图,但不能只把它当成"样张好不好看"来看。它真正想表达的是覆盖面:人物、风景、文字风格、季节变化、材质、插画、摄影感、物体建模都被放在同一张图里。换句话说,作者想证明 HiDream-I1 不是一个只适合某种固定审美的 demo 模型,而是要往"可被产品系统调用的图像基础模型"靠近。
不过,Rocky 也会提醒一句:样例图永远只能说明"模型具备这种可能性",不能说明稳定性。真正判断一个图像模型有没有长期价值,不能只看门面图,而要看它能不能在数据、架构、推理成本、编辑一致性和工作流集成上形成闭环。
1. 问题背景:这篇工作站在什么技术拐点上
图像生成已经过了最早的惊艳期。今天的核心问题不是"AI 能不能画图",而是"AI 图像系统能不能进入真实生产流程"。这两件事差别很大。前者是模型能力展示,后者是产品基础设施。
从这个角度看,HiDream-I1 刚好踩在一个关键拐点上。文生图模型已经能做出高质量结果,但商业和创作场景里仍然有三类长期矛盾。
第一,质量和复杂指令之间有矛盾。模型不仅要画得漂亮,还要听懂多对象、多属性、多关系、多风格混合的复杂 prompt。第二,质量和速度之间有矛盾。扩散模型越追求质量,采样步数和推理延迟往往越难压。第三,生成和编辑之间有矛盾。很多系统能从零生成一张图,却很难在不破坏原图结构的前提下进行精细修改。
HiDream-I1 的论文逻辑,就是围绕这三组矛盾展开:先用数据和 sparse DiT 提升生成底座,再用蒸馏做快版本,最后把底座延伸到 HiDream-E1 编辑模型和 HiDream-A1 图像 Agent。它的目标不是单模型炫技,而是把图像生成变成一个可以被连续调用的工作流节点。
这也是 Rocky 比较关注它的原因:单点模型能力会被更强的 foundation model 吸收,但系统化能力、工程效率和工作流集成,才更接近跨周期价值。
2. 总体思路:作者的解法主线
如果把这篇论文压缩成一句话:HiDream-I1 用 sparse DiT 做高质量生成底座,用混合文本编码增强复杂提示理解,用 GAN-powered diffusion distillation 把高质量模型压成快版本,再把同一套能力扩展到图像编辑和 Agent 化交互。
这条路线不是非常"新奇"的单点发明。它更像一次系统集成:把 DiT、MoE、多文本编码器、flow matching、DMD 蒸馏、图像编辑训练、Agent 产品形态串成一条链。Rocky 认为,这类工作的价值往往不在于每个模块都前所未有,而在于它是否把模块组合成了一个能落地的能力结构。
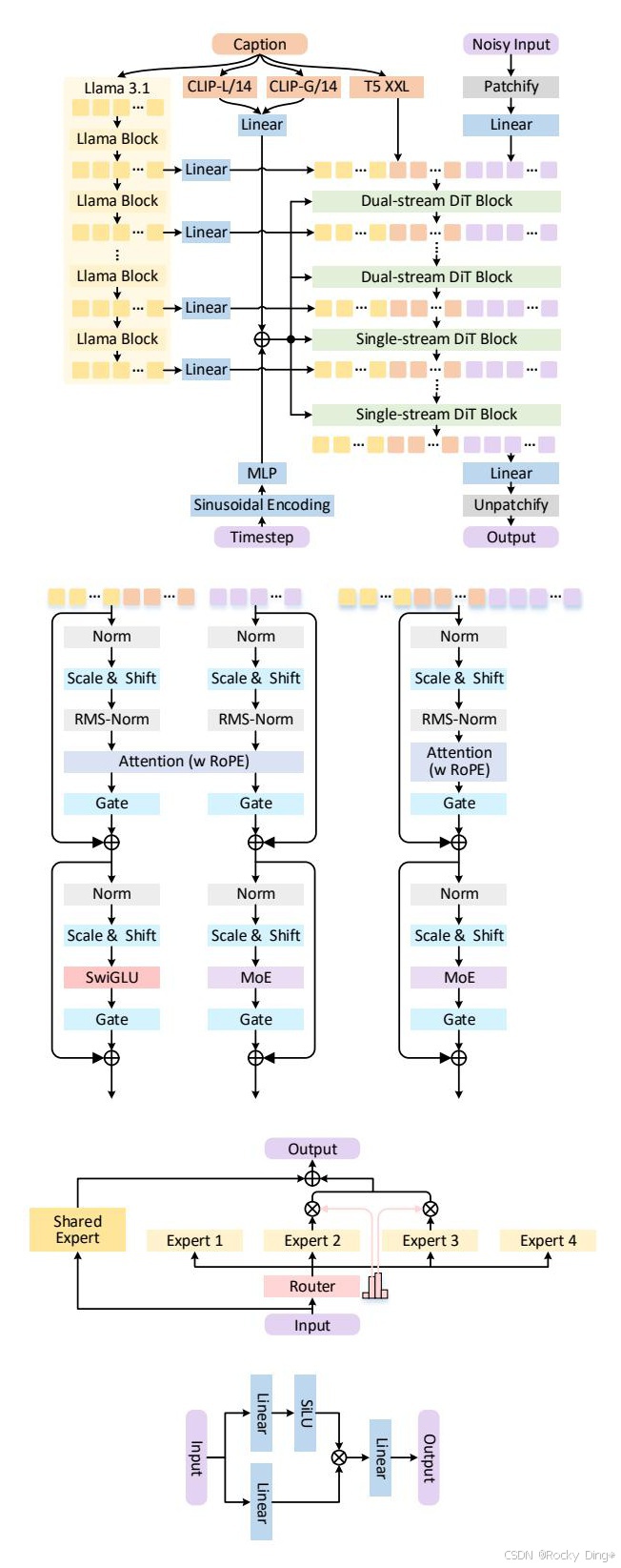
Figure 2 是整篇论文的技术骨架。上半部分可以看到,HiDream-I1 不是只依赖单一文本编码器,而是同时引入 Llama 3.1、Long-CLIP-L/14、Long-CLIP-G/14 和 T5 XXL。这个设计背后的判断很清楚:图像生成里的"理解 prompt"并不是单一任务。CLIP 更像图文对齐锚点,T5 更擅长结构化文本理解,LLM 中间层则承担更深语义的补充。
再看生成主干,它不是密集 DiT,而是先双流、后单流的 sparse DiT。双流阶段让图像 token 和文本 token 保持各自表征空间,单流阶段再强化跨模态交互;MoE 则负责在扩大模型容量的同时控制每次计算真正激活的专家数量。这其实是当下大模型工程里很典型的一种方向:不是一味堆算力,而是让容量和计算解耦。
| 层级 | 作者的做法 | Rocky 解读 |
|---|---|---|
| 生成底座 | 混合文本编码 + sparse DiT + flow matching | 解决"听懂复杂 prompt 并稳定生成"的基础问题 |
| 加速版本 | DMD 蒸馏 + 对抗损失 | 解决"高质量模型无法低延迟产品化"的问题 |
| 编辑扩展 | HiDream-E1 指令式图像编辑 | 从一次性生成走向可修正、可迭代创作 |
| Agent 外延 | HiDream-A1 对话式图像 Agent | 把模型能力包装成连续工作流,而不是孤立接口 |
这一节真正要抓住的是:HiDream-I1 的路线不是"做一个更大的画图模型",而是"把画图模型放进一个可交互、可加速、可编辑的系统结构里"。这会是下一阶段图像模型竞争很重要的分水岭。
3. 方法拆解:沿着论文原始逻辑往下看
3.1 数据预处理:先把训练分布洗干净
很多人看图像生成论文,会第一时间盯架构。但 Rocky 一直觉得,图像模型真正的底层能力,至少有一半藏在数据里。架构决定模型怎么学,数据决定模型最终能学到什么世界。
HiDream-I1 把数据预处理放在第二章,这一点很值得注意。作者不是简单说"我们用了大规模数据",而是把数据流程拆成收集、去重、过滤、标注四个环节。它对应的不是论文排版需要,而是一个生成模型的基本工程常识:如果数据分布不干净,后面再先进的 DiT、MoE、蒸馏都只是在放大噪声。
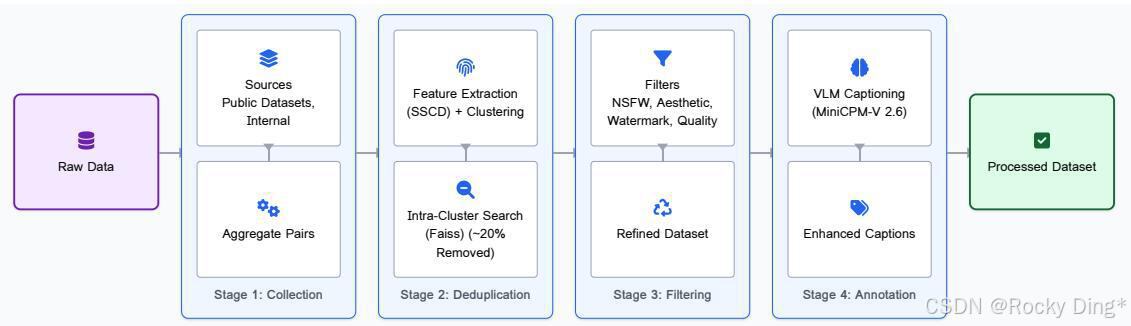
Figure 3 展示了完整的数据预处理链路。先从公开数据和内部图片聚合图文对,再用 SSCD 特征和聚类做大规模近重复筛查,随后在簇内用 Faiss 进一步去重,约 20% 的初始图片会被移除。之后再经过 NSFW、安全、水印、审美质量、技术质量等过滤,最后用 MiniCPM-V 2.6 做更详细的 caption 标注。
这条管线的核心价值有三点。
第一,去重不是洁癖,而是防止模型把训练样本记成答案。大规模图像生成模型如果不认真去重,很容易把"生成能力"伪装成"记忆能力"。第二,过滤不是简单美化数据,而是在提前决定模型的审美和安全边界。第三,VLM 标注本质上是在重建图像和语言之间的契约。caption 越细,模型越有机会学会对象、属性、关系和风格之间的绑定。
所以这部分看起来朴素,但其实是 HiDream-I1 后面 prompt following 能站上去的基础。数据不是论文里最性感的部分,却往往是最决定长期效果的部分。
3.2 模型结构:为什么 sparse DiT 是这篇论文的中轴
HiDream-I1 的生成主干建立在 flow matching 框架上。论文把生成过程写成从噪声样本到目标图像的连续路径,模型学习的是这个路径上的速度场。训练目标如下:
L F M = E t , X 0 , X 1 , y ∥ u ( X t , y , t ; θ ) − ( X 1 − X 0 ) ∥ 2 (1) \mathcal {L} _ {\mathrm{FM}} = \mathbb {E} _ {t, X _{0}, X _{1}, y} \left \\\| u (X _{t}, y, t; \\theta) - (X _{1} - X _{0}) \\\| \^ {2} \\right \tag {1} LFM=Et,X0,X1,y∥u(Xt,y,t;θ)−(X1−X0)∥2(1)
这个公式不用被吓住。它的直觉是:模型不是在死记一张图,而是在学习从噪声走向真实图像的方向。给定当前状态、文本条件和时间步,模型要预测应该往哪里"推"。这类方法与 latent space、DiT 主干和蒸馏加速都很容易衔接,因此适合做大规模图像生成底座。
真正体现 HiDream-I1 风格的,是它的文本编码和 sparse DiT 设计。
在文本侧,作者没有相信一个编码器能解决所有问题。CLIP 的优势在图文对齐,T5 的优势在语言结构,LLM 中间层的优势在复杂语义。HiDream-I1 把这些信号整合起来,本质上是在承认一个现实:现代文生图 prompt 已经不是"a cat on the sofa"这种简单短句,而是越来越接近创意 brief、摄影指令、设计需求和多轮上下文。单一文本编码器很难覆盖这种复杂度。
在图像生成主干侧,作者采用双流到单流的结构。早期让图像 token 和文本 token 分别处理,是为了避免过早混合带来的表征干扰;后期把它们拼接到同一序列里,是为了强化跨模态对齐。再叠加 sparse MoE,模型可以拥有更大的参数容量,但每次推理只激活一部分专家。这是一个很典型的工程取舍:模型要有大脑容量,但每次思考不能把所有脑区都烧一遍。
Rocky 认为,这里最值得关注的不是"用了 MoE"这件事本身,而是 MoE 被放进了图像 DiT 的关键位置。它意味着图像生成模型也在走语言模型走过的路:容量继续变大,但计算必须稀疏化、路由化、可控化。
3.3 训练策略:先打底,再对齐,再补细节
训练策略上,HiDream-I1 采用多阶段流程。预训练阶段先在 latent space 里学习基础生成能力,再通过 progressive resolution training 逐步提高分辨率:先 256,再 512,最后 1024。这种做法并不花哨,但很符合大模型训练的基本规律:先学结构,再学细节;先学分布,再学高频纹理。
论文还提到,训练图像会先通过 VAE 编码成 latent 并预计算存储。这是一个很工程化的选择。对这类大规模训练来说,真正的瓶颈不只是模型参数,还有数据吞吐、编码成本、显存分配和训练稳定性。很多论文只讲模型结构,但真正能训出来,靠的是这些看起来不起眼的工程细节。
后训练阶段,作者用更高质量、经过人工验证的图文对继续 fine-tune,目标是提升 prompt fidelity、审美质量和人类偏好。这一步很像图像模型里的"对齐层":预训练负责广泛学习世界,后训练负责把模型拉向人类更愿意使用的输出分布。
这里可以给一个 Rocky 式判断:图像生成模型的后训练,本质上不是简单补课,而是在决定模型面向什么用户、什么审美、什么产品场景。 同样的基础能力,如果后训练数据和偏好方向不同,最后长出来的模型性格会完全不同。
3.4 蒸馏与加速:快版本不是缩略版,而是再训练出来的
HiDream-I1-Full 是 50+ 步的完整版本,质量优先。但如果只停在这个版本,产品意义会打折。真实业务里,推理速度、成本和并发能力不是附属问题,而是模型能不能被用起来的前提。
所以作者进一步推出 HiDream-I1-Dev 和 HiDream-I1-Fast。这里的路线不是粗暴减少采样步数,而是使用 DMD 蒸馏,并额外加入 adversarial loss。DMD 负责让学生模型在更少步数下逼近老师模型的生成分布,对抗损失则尝试弥补蒸馏后常见的局部细节和锐度损失。
这部分其实很有产品味。一个模型如果只有 full version,就更像实验室成果;如果能提供 full/dev/fast 三个版本,就开始像基础设施。不同用户、不同设备、不同延迟预算,可以选择不同能力档位。未来模型公司真正做平台化,必须提供这种能力分层,而不是只给一个"最强但最贵"的版本。
不过论文中有一个小细节值得保留:摘要写 HiDream-I1-Fast 是 14 步,正文第 5 节写的是 16 步。这个不一致不影响论文主线,但对复现和工程使用来说不是小事。因为步数直接影响速度、成本和画质折中。Rocky 的习惯是:看到这种细节,不急着否定论文,但会提醒读者在使用开源权重和代码时再核实具体版本。
3.5 从生成走向编辑,再走向 Agent
HiDream-E1 是这篇论文从"文生图模型"走向"视觉创作系统"的关键一步。它不是只输入文本,而是把源图、编辑指令和目标图都放进训练流程。源图和目标图经过 VAE 编码后,在 latent space 中形成编辑条件,模型学习如何在保留原图上下文的同时生成目标结果。
作者还引入空间加权损失,让模型更关注源图和目标图差异较大的区域。这一点很重要。图像编辑最怕的不是不会改,而是改错地方。用户让你换背景,你把人物脸也改了;用户让你改颜色,你把构图也漂移了。真正可用的编辑模型,核心能力不是"生成新图",而是"只动该动的部分"。
HiDream-A1 则把生成和编辑包装成对话式 Agent。Coordinator 负责理解用户输入并分流任务,Planner 决定具体调用生成模型还是编辑模型。这个设计说明作者已经不把图像模型看成一个孤立 API,而是看成一个可被调度的工具节点。
这也是 Rocky 对 Agent 的一贯判断:Agent 的本质不是聊天框,而是把模型能力变成可编排、可执行、可迭代的工作流。HiDream-A1 是否成熟另说,但它的方向是对的:图像生成不会永远停留在 prompt box,它会进入更长链条的创作流程。
4. 实验与证据:结果能支撑到什么程度
4.1 Prompt adherence:它确实更会听话,但不是每个子项都统治
评测部分,作者主要用 DPG-Bench 和 GenEval 来证明 HiDream-I1 的 prompt adherence。DPG-Bench 更强调复杂提示的细粒度理解,GenEval 更强调组合式生成能力。从 overall 看,HiDream-I1 都排在第一:DPG-Bench 为 85.89,GenEval 为 0.83。
但 Rocky 不建议只看 overall。真正读 benchmark,要看模型赢在哪里,也要看它没赢在哪里。
在 DPG-Bench 上,HiDream-I1 的 Relation 是 93.74,Other 是 91.83,这说明它对复杂关系和细节约束的理解确实强。但它的 Global 只有 76.44,低于不少对比模型。这意味着它不是所有层面都压倒性领先,而是在某些复杂语义维度上更突出。
Table 1. DPG-Bench 结果(%)
| Model | Overall | Global | Entity | Attribute | Relation | Other |
|---|---|---|---|---|---|---|
| PixArt-alpha | 71.11 | 74.97 | 79.32 | 78.60 | 82.57 | 76.96 |
| SDXL | 74.65 | 83.27 | 82.43 | 80.91 | 86.76 | 80.41 |
| DALL-E 3 | 83.50 | 90.97 | 89.61 | 88.39 | 90.58 | 89.83 |
| FLUX.1-dev | 83.79 | 85.80 | 86.79 | 89.98 | 90.04 | 89.90 |
| SD3-Medium | 84.08 | 87.90 | 91.01 | 88.83 | 80.70 | 88.68 |
| Janus-Pro-7B | 84.19 | 86.90 | 88.90 | 89.40 | 89.32 | 89.48 |
| CogView4-6B | 85.13 | 83.85 | 90.35 | 91.17 | 91.14 | 87.29 |
| HiDream-I1 | 85.89 | 76.44 | 90.22 | 89.48 | 93.74 | 91.83 |
在 GenEval 上,HiDream-I1 的 single object、two object、counting、colors、color attribution 都很强,overall 最高。但 Position 是 0.60,低于 Janus-Pro-7B 的 0.79。这说明空间位置仍然是图像生成模型的硬问题。很多模型能画对对象,能画对颜色,但不一定总能把对象放在正确空间关系里。
Table 2. GenEval 结果
| Model | Overall | Single Obj. | Two Obj. | Counting | Colors | Position | Color Attr. |
|---|---|---|---|---|---|---|---|
| PixArt-alpha | 0.48 | 0.98 | 0.50 | 0.44 | 0.80 | 0.08 | 0.07 |
| SDXL | 0.55 | 0.98 | 0.74 | 0.39 | 0.85 | 0.15 | 0.23 |
| FLUX.1-dev | 0.66 | 0.98 | 0.79 | 0.73 | 0.77 | 0.22 | 0.45 |
| DALL-E 3 | 0.67 | 0.96 | 0.87 | 0.47 | 0.83 | 0.43 | 0.45 |
| CogView4-6B | 0.73 | 0.99 | 0.86 | 0.66 | 0.79 | 0.48 | 0.58 |
| SD3-Medium | 0.74 | 0.99 | 0.94 | 0.72 | 0.89 | 0.33 | 0.60 |
| Janus-Pro-7B | 0.80 | 0.99 | 0.89 | 0.59 | 0.90 | 0.79 | 0.66 |
| HiDream-I1 | 0.83 | 1.00 | 0.98 | 0.79 | 0.91 | 0.60 | 0.72 |
所以,这组实验能支撑的结论是:HiDream-I1 的复杂提示遵循能力很强,尤其在关系、对象组合和颜色属性方面优势明显。但它不能证明模型已经彻底解决空间布局和全局场景稳定性问题。这个边界必须讲清楚。
4.2 Human preference:审美分数也站上去了
HPSv2.1 评估的是预测人类偏好。HiDream-I1 平均分 33.82,在对比模型中最高,并且在 Animation、Concept Art、Painting、Photo 四类上都排第一。
这部分说明 HiDream-I1 不只是"听话",也在审美分布上被推到了比较高的位置。对图像模型来说,这是一个重要信号。因为很多模型有两种常见缺陷:要么 prompt following 强但画面平,要么画面漂亮但指令执行不稳。HiDream-I1 想证明自己在两者之间取得了更好的平衡。
Table 3. HPSv2.1 结果
| Model | Averaged | Animation | Concept Art | Painting | Photo |
|---|---|---|---|---|---|
| Stable Diffusion v2.0 | 26.38 | 27.09 | 26.02 | 25.68 | 26.73 |
| Midjourney V6 | 30.29 | 32.02 | 30.29 | 29.74 | 29.10 |
| SDXL | 30.64 | 32.84 | 31.36 | 30.86 | 27.48 |
| DALL-E 3 | 31.44 | 32.39 | 31.09 | 31.18 | 31.09 |
| SD3 | 31.53 | 32.60 | 31.82 | 32.06 | 29.62 |
| Midjourney V5 | 32.33 | 34.05 | 32.47 | 32.24 | 30.56 |
| CogView4-6B | 32.31 | 33.23 | 32.60 | 32.89 | 30.52 |
| FLUX.1-dev | 32.47 | 33.87 | 32.27 | 32.62 | 31.11 |
| Stable Cascade | 32.95 | 34.58 | 33.13 | 33.29 | 30.78 |
| HiDream-I1 | 33.82 | 35.05 | 33.74 | 33.88 | 32.61 |
但这里也要保持克制。HPS 是模型预测的人类偏好,不等同于真实用户长期使用反馈。它能说明输出更接近某种审美偏好分布,但不能直接证明它在商业设计、广告生产、游戏资产、影视概念图等专业工作流里一定更好用。模型偏好分数只是入口,真实 workflow 里的返工率、可控性和一致性才是最终指标。
4.3 编辑能力:整体最强,但不是每个子任务都第一
HiDream-E1 的评测使用 EmuEdit 和 ReasonEdit。这里的结果很值得看,因为它已经不只是文生图,而是在验证"改图"能力。HiDream-E1 在 EmuEdit 平均分上达到 6.40,在 ReasonEdit 上达到 7.54,整体领先。
编辑能力的本质是两件事同时成立:第一,执行指令;第二,不破坏不该改的区域。只做到第一点,会变成重新生成;只做到第二点,会变成保守不动。好的编辑模型必须在这两者之间找到平衡。
Table 4. 编辑任务结果
| Model | Global | Add | Text | BG | Color | Style | Remove | Local | Average | ReasonEdit |
|---|---|---|---|---|---|---|---|---|---|---|
| MagicBrush | 4.06 | 3.54 | 0.55 | 3.26 | 3.83 | 2.07 | 2.70 | 3.28 | 2.81 | 1.75 |
| UltraEdit | 5.31 | 5.19 | 1.50 | 4.33 | 4.50 | 5.71 | 2.63 | 4.58 | 4.07 | 2.89 |
| OmniGen | 1.37 | 2.09 | 2.31 | 0.66 | 4.26 | 2.36 | 4.73 | 2.10 | 2.67 | 7.36 |
| Gemini-2.0-Flash | 4.87 | 7.71 | 6.30 | 5.10 | 7.30 | 3.33 | 5.94 | 6.29 | 5.99 | 6.95 |
| HiDream-E1 | 5.32 | 6.98 | 6.45 | 5.01 | 7.57 | 6.49 | 5.99 | 6.35 | 6.40 | 7.54 |
这张表的结论不能写成"HiDream-E1 全面碾压"。更准确的说法是:HiDream-E1 在平均表现和复杂推理编辑上领先,但 Gemini-2.0-Flash 在 Add、BG 等子任务上仍然很强。HiDream-E1 的价值更像"整体均衡",不是每个单项都第一。
对工程团队来说,这个判断很重要。真实产品里,平均稳定性往往比某个子项高分更有价值。因为用户不会只做一种编辑任务,他们会反复追加、撤回、局部调整、换风格、换背景。一个编辑模型能否产品化,关键不是 demo 中某张图惊艳,而是多轮修改中的失控概率是否足够低。
5. 能力边界和案例:这些图真正说明了什么
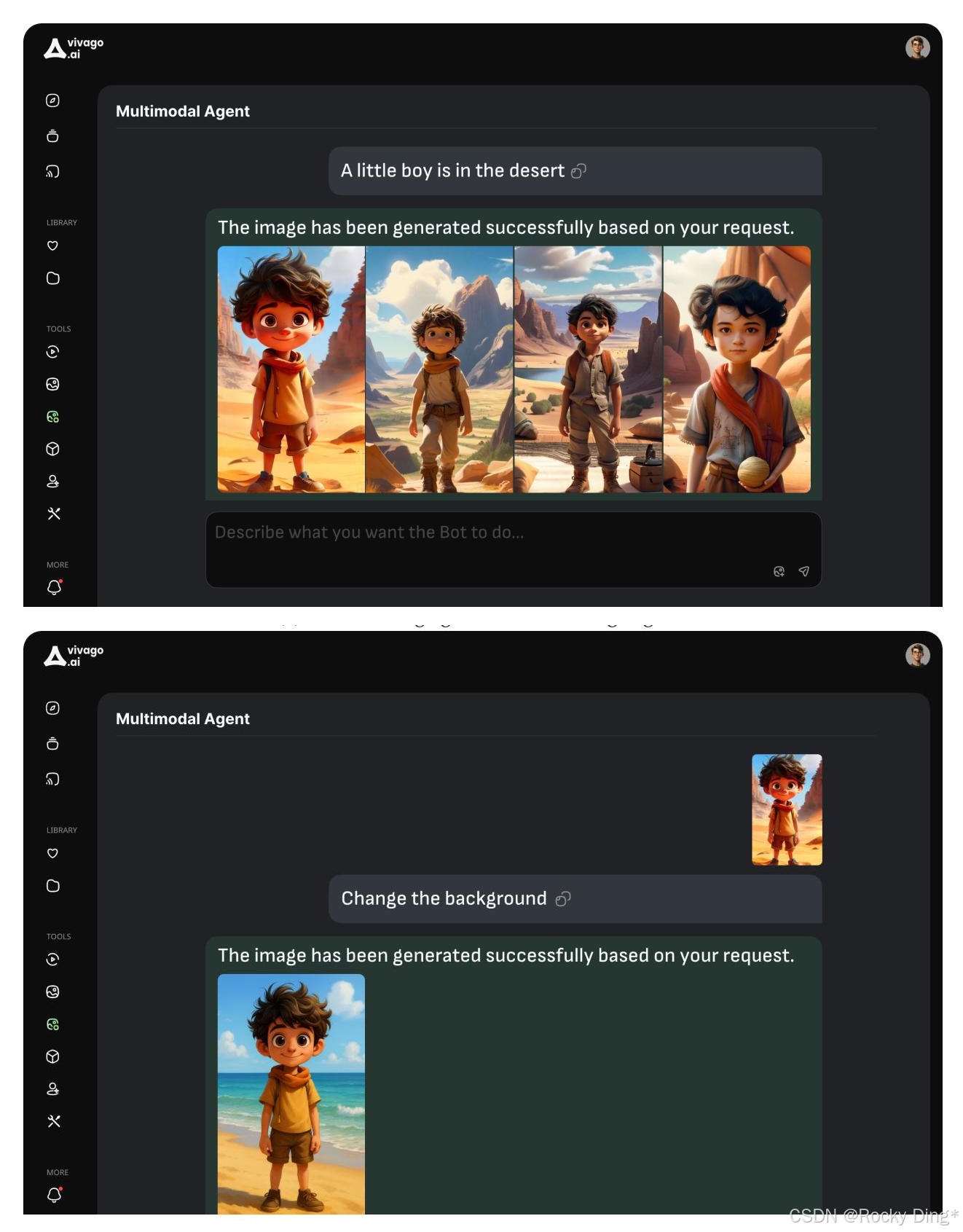
Figure 4 展示了 HiDream-A1 的两个交互入口:上半部分是 text-to-image,下半部分是 instruction-based editing。它说明作者已经把 HiDream-I1 和 HiDream-E1 接进了一个对话式图像创作界面。
Rocky 认为,这张图最重要的价值,不是 UI,而是产品范式。传统图像生成工具通常是"输入 prompt -> 得到图片"。Agent 化之后,它会变成"表达意图 -> 系统规划 -> 调用生成或编辑模型 -> 继续对话修改"。这一步很关键,因为图像创作本来就不是一次性任务,而是反复试探、选择、修改、收敛的过程。
但 Figure 4 也不能被过度解读。它能证明系统形态已经被搭起来,却不能证明 Agent 体验已经成熟。论文没有给出多轮交互成功率、任务路由准确率、编辑漂移率、平均延迟、用户满意度等指标。也就是说,HiDream-A1 目前在论文里更像"系统方向展示",而不是经过严格评测的 Agent 产品。
这正是 AI Agent 论文和产品最容易混淆的地方:接上工具不等于形成可靠工作流,能对话不等于能稳定完成任务。真正的 Agent 护城河不在聊天框,而在任务规划、状态保持、工具调用、失败恢复和用户意图校准。
6. 局限性、隐含假设与可复现性
这篇工作有价值,但也必须把边界讲清楚。Rocky 不喜欢把技术报告写成发布会稿子,因为那样会错过真正值得研究的地方。
第一,benchmark 领先不等于能力全维度成熟。HiDream-I1 在 DPG-Bench 和 GenEval 的 overall 表现很好,但 Global、Position 等子项并不绝对领先。这说明它在复杂关系和组合生成上强,但全局布局、空间位置、场景稳定性仍然需要继续验证。
第二,论文没有给出足够完整的算力和部署账本。它披露了训练阶段、分辨率进程、batch size、部分优化策略,但对总训练成本、推理延迟、显存占用、吞吐、MoE 路由分布等工程指标展开不够。对于想复现或部署的人来说,这些指标不是锦上添花,而是模型是否可用的核心。
第三,HiDream-E1 和 HiDream-A1 的证据还偏早期。编辑模型有 benchmark,但真实多轮编辑体验、失败案例和一致性保持仍然需要更多实验。Agent 部分更多是系统展示,缺少严肃的交互评测。这意味着它展示了路线,但还没有完全证明路线的可靠性。
第四,摘要和正文对 HiDream-I1-Fast 步数存在 14/16 的不一致。这不是致命问题,但会影响复现判断。对开源模型来说,版本、权重、默认推理参数和论文描述之间的一致性非常重要。很多工程坑,最后都不是算法大方向错,而是这些小细节没对齐。
所以,Rocky 对这篇工作的判断是:它是一篇有系统价值的技术报告,但还不是一份充分完整的工程白皮书。它告诉我们方向和能力边界,但如果要把它当作生产基础设施,还需要更多部署和稳定性证据。
7. 如果继续研究/落地,应该关注什么
如果我是一个研究者,我会优先做三类 ablation。第一,混合文本编码器到底各自贡献多少。Llama 中间层、T5、Long-CLIP 分别提升了哪些能力,是关系理解、长 prompt、审美对齐,还是细粒度属性绑定?第二,sparse MoE 的路由是否真的形成专家分工。不同 prompt 类型是否会激活不同专家?专家是否出现塌缩?第三,蒸馏之后的 dev/fast 版本在质量、速度和一致性上具体损失多少。
如果我是一个工程团队,我更关心另一组问题:Full、Dev、Fast 三个版本的延迟、吞吐、显存、并发成本分别是多少?快版本在用户可感知质量上掉多少?编辑模型在多轮修改中漂移概率多大?Agent 的任务路由失败之后能不能自我修正?这些指标比单次 benchmark 更接近真实业务。
如果我是产品经理,我会把 HiDream-I1 看成一个提醒:下一代图像产品不要只做"更好看的生成按钮"。更有价值的方向,是围绕创作流程设计能力层:生成初稿、局部编辑、风格统一、版本管理、多轮对话、素材复用、团队协作。模型能力只是底层发动机,真正的产品价值来自工作流。
如果我是创业者或投资人,我会更谨慎地区分"模型发布价值"和"商业护城河"。HiDream-I1 的开源会降低很多团队做高质量图像生成的门槛,但这也意味着单纯套模型做工具的护城河会继续变薄。长期来看,护城河更可能出现在垂直数据、行业 workflow、交付能力、稳定性工程和分发渠道上。
总结一句:HiDream-I1 不是图像生成终局,但它很清楚地指出了一个方向:图像模型的下一阶段竞争,不是单模型跑分,而是生成、编辑、加速、Agent 工作流之间的系统协同。
术语与概念速查
| 术语 | 解释 |
|---|---|
| Flow matching | 把生成过程看成从噪声到数据分布的连续速度场学习 |
| DiT | Diffusion Transformer,用 Transformer 做扩散主干 |
| Sparse MoE | 稀疏专家混合,只激活少量专家来控制计算成本 |
| adaLN | 自适应层归一化,用全局条件调制特征缩放与平移 |
| DMD | Distribution Matching Distillation,用蒸馏缩短采样步骤 |
| HPSv2.1 | 预测人类偏好的图像评分基准 |
| GenEval | 评估文本到图像组合式对齐能力的基准 |
| DPG-Bench | 细粒度提示遵循评测基准 |
| EmuEdit | 面向图像编辑的评测基准 |
| ReasonEdit | 更强调推理式编辑指令的评测基准 |
拓展思考:值得继续扩展研究与思考的创新点
这篇论文最值得继续研究的,不是某个单独模块,而是"图像基础模型如何系统化"。过去我们很容易把文生图理解成一个模型任务:输入文字,输出图片。但 HiDream-I1 提醒我们,真正的图像基础设施应该至少包含四层能力:高质量生成底座、可调档的加速模型、稳定的指令编辑模型,以及能组织多轮任务的 Agent 层。
这背后有一个更大的趋势:AI 创作工具正在从"单次生成工具"变成"连续创作系统"。 单次生成追求的是惊艳,多轮创作追求的是可控;单次生成看重模型上限,多轮创作看重稳定性、状态保持和返工成本。未来真正被专业用户长期使用的图像 AI,不一定是样张最炸裂的那个,而是能最稳定地嵌入创作流程的那个。
后续可以继续往三个方向扩展。
第一,做更细的机制解释。比如 MoE 路由是否形成风格专家、对象专家、语义关系专家;混合文本编码器是否真的对复杂 prompt 有明确分工;DMD 和 adversarial loss 对不同风格图像的影响是否一致。
第二,做更真实的产品评测。不要只看单轮 benchmark,而要看多轮编辑、失败恢复、用户返工率、延迟体验、局部一致性和跨图风格保持。图像生成的专业化评测,应该从"这张图好不好"走向"这个工作流能不能稳定完成任务"。
第三,做更强的工程透明度。开源模型如果想成为基础设施,就需要更清晰的模型版本、默认参数、推理成本、硬件需求和失败边界。只有这些信息足够透明,开发者才敢把它接进自己的产品链路。
Rocky 最后的判断是:HiDream-I1 的跨周期价值,不在于它今天某个榜单分数有多高,而在于它把图像生成模型从"画图能力"推向了"视觉创作系统能力"。如果未来图像模型真的进入 Agent 化工作流,这类生成、编辑、加速、调度一体化的路线,会比单纯追逐样张效果更值得长期关注。
推荐阅读
Rocky一直在运营技术交流群(WeThinkIn-技术交流群),这个群的初心主要聚焦于技术话题的讨论与学习,包括但不限于算法,开发,竞赛,科研以及工作求职等。群里有很多人工智能行业的大牛,欢迎大家入群一起学习交流~(请添加小助手微信Jarvis8866,拉你进群~)
1. 深入浅出完整解析AI Agent(AI智能体)的核心基础知识
2025年可以说是AI Agent全面落地应用的元年,因此Rocky在持续撰写对AI Agent的全维度解析文章:https://zhuanlan.zhihu.com/p/1919046969076195976
2. 深入浅出完整解析扩散模型DDPM、DDIM、Classifier/Classifier-Free Guidance、Rectified Flow核心基础知识
和Rocky一起学习探究扩散模型的本质原理与和核心基础知识,同时不断跟进扩散模型的最新发展。Rocky在本文中对扩散模型的本质做了全面系统的梳理与讲解:https://zhuanlan.zhihu.com/p/1964029619658261252
3、Sora等AI视频大模型的核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用AI视频大模型,从0到1训练自己的AI视频大模型,AI视频大模型性能测评,AI视频领域未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Sora等AI视频大模型文章地址:https://zhuanlan.zhihu.com/p/706722494
4、Stable Diffusion 3和FLUX.1核心原理,核心基础知识,网络结构,从0到1搭建使用Stable Diffusion 3和FLUX.1进行AI绘画,从0到1上手使用Stable Diffusion 3和FLUX.1训练自己的AI绘画模型,Stable Diffusion 3和FLUX.1性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion 3和FLUX.1文章地址:https://zhuanlan.zhihu.com/p/684068402
5、Stable Diffusion XL核心基础知识,网络结构,从0到1搭建使用Stable Diffusion XL进行AI绘画,从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型,AI绘画领域的未来发展等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion XL文章地址:https://zhuanlan.zhihu.com/p/643420260
6、Stable Diffusion 1.x-2.x核心原理,核心基础知识,网络结构,经典应用场景,从0到1搭建使用Stable Diffusion进行AI绘画,从0到1上手使用Stable Diffusion训练自己的AI绘画模型,Stable Diffusion性能优化等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Stable Diffusion文章地址:https://zhuanlan.zhihu.com/p/632809634
7、ControlNet核心基础知识,核心网络结构,从0到1使用ControlNet进行AI绘画,从0到1训练自己的ControlNet模型,从0到1上手构建ControlNet商业变现应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
ControlNet文章地址:https://zhuanlan.zhihu.com/p/660924126
8、LoRA系列模型核心原理,核心基础知识,从0到1使用LoRA模型进行AI绘画,从0到1上手训练自己的LoRA模型,LoRA变体模型介绍,优质LoRA推荐等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
LoRA文章地址:https://zhuanlan.zhihu.com/p/639229126
9、Transformer核心基础知识,核心网络结构,AIGC时代的Transformer新内涵,各AI领域Transformer的应用落地,Transformer未来发展趋势等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
Transformer文章地址:https://zhuanlan.zhihu.com/p/709874399
10、最全面的AIGC面经《手把手教你成为AIGC算法工程师,斩获AIGC算法offer!(2024年版)》文章正式发布!
码字不易,欢迎大家多多点赞:
AIGC面经文章地址:https://zhuanlan.zhihu.com/p/651076114
11、50万字大汇总《"三年面试五年模拟"之算法工程师的求职面试"独孤九剑"秘籍》文章正式发布!
码字不易,欢迎大家多多点赞:
算法工程师三年面试五年模拟文章地址:https://zhuanlan.zhihu.com/p/545374303
《三年面试五年模拟》github项目地址(希望大家能多多star):https://github.com/WeThinkIn/Interview-for-Algorithm-Engineer
12、Stable Diffusion WebUI、ComfyUI、Fooocus三大主流AI绘画框架核心知识,从0到1搭建AI绘画框架,从0到1使用AI绘画框架的保姆级教程,深入浅出介绍AI绘画框架的各模块功能,深入浅出介绍AI绘画框架的高阶用法等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
AI绘画框架文章地址:https://zhuanlan.zhihu.com/p/673439761
13、GAN网络核心基础知识,网络架构,GAN经典变体模型,经典应用场景,GAN在AIGC时代的商业应用等全维度解析文章正式发布!
码字不易,欢迎大家多多点赞:
GAN网络文章地址:https://zhuanlan.zhihu.com/p/663157306