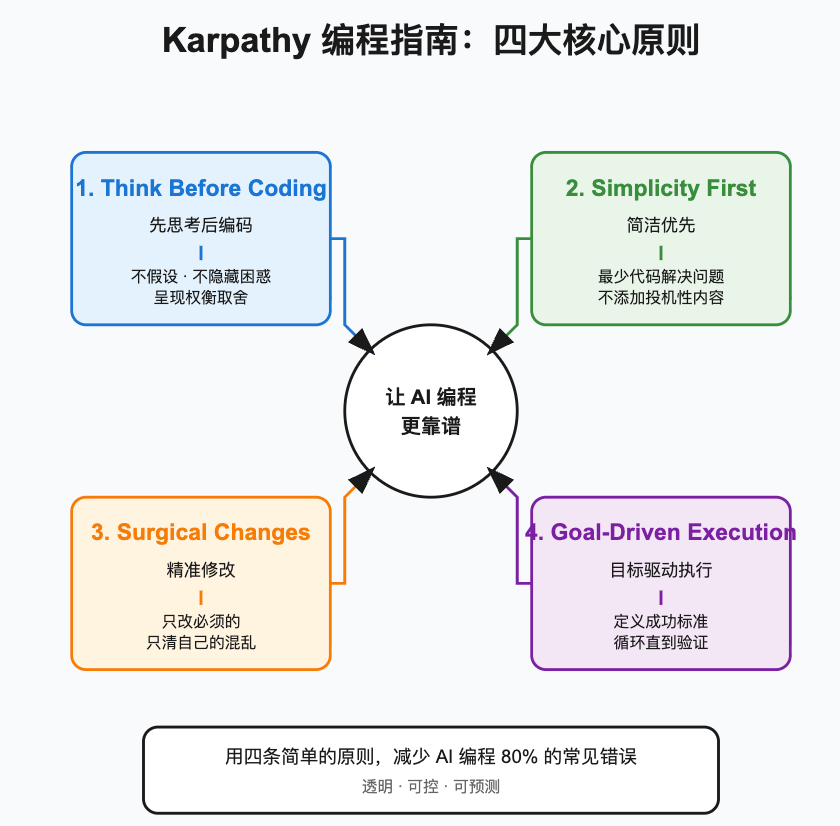
导读 / TL;DR
核心价值 :Andrej Karpathy 总结了 LLM 编程的常见陷阱,提出了四条简单但有效的行为准则。这套指南以单个
CLAUDE.md文件形式存在,可以直接用于改善 Claude Code 的编程行为。关键判断:
- 核心理念:先思考后编码、简洁优先、精准修改、目标驱动
- 设计哲学:这不是要束缚 AI,而是让 AI 的编程行为更透明、可控
- 实操性:每条原则都有可执行的检查清单和检验标准
一句话总结:用四条简单的原则,减少 AI 编程 80% 的常见错误。
一、问题背景:为什么 AI 编程总让人不放心?
1.1 Karpathy 的观察
2024 年,Andrej Karpathy 在 Twitter 上发表了一系列关于 LLM 编程缺陷的观察,字字珠玑:
"模型会替你做出错误的假设,然后不加确认地继续执行。它们不会管理自己的困惑,不会寻求澄清,不会指出不一致的地方,不会呈现权衡取舍,不会在应该时提出反对意见。"
"它们真的很喜欢过度复杂化代码和 API,膨胀抽象,不清理死代码......用 1000 行实现本可用 100 行完成的功能。"
"它们有时会删除或修改它们不理解的代码和注释,即使这些代码与任务无关。"
个人感觉,这些观察非常精准。在实际使用 Claude Code、Cursor 等工具时,这些问题确实经常出现。
1.2 这些问题的本质
在我看来,这些问题的根源在于 LLM 的几个特性:
1. 过度自信
LLM 天生倾向于给出"确定"的答案,即使它并不确定。这种自信让它不会主动说"我不确定,需要澄清"。
2. 缺乏元认知
模型不会管理自己的困惑状态。人类程序员在困惑时会停下来思考、询问,但 LLM 会直接跳过这个环节。
3. 表演欲过强
LLM 倾向于展示"聪明",倾向于构建复杂的抽象和架构,即使简单的方案就足够了。
1.3 实际影响
这些问题带来的实际后果:
- 代码审查成本增加:需要花更多时间检查 AI 生成的代码
- 技术债务积累:过度设计和不必要的抽象会长期存在
- 开发者信任度下降:逐渐不敢完全依赖 AI 生成的代码
基于这些观察,Karpathy 提出了四条核心原则。下面我来逐一解读。
二、四大原则深度解析
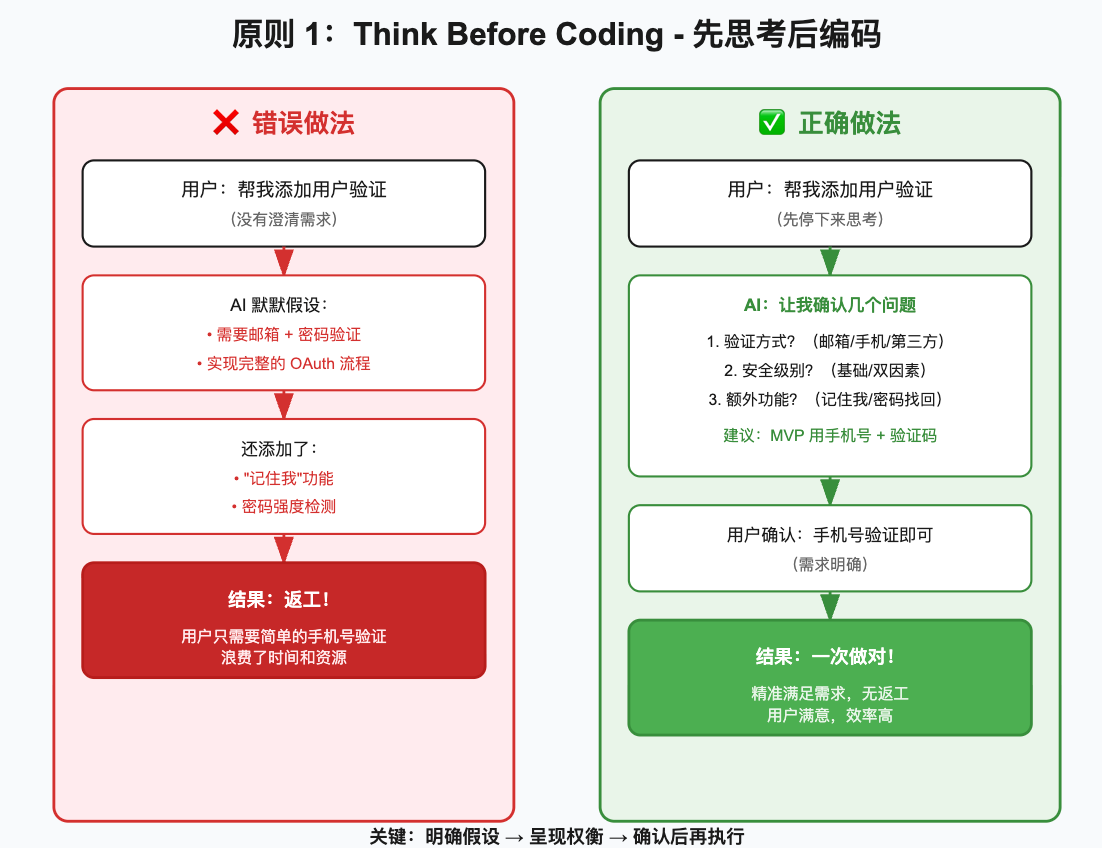
2.1 原则一:Think Before Coding(先思考后编码)
核心要义
不要假设,不要隐藏困惑,呈现权衡取舍
反面案例
让我模拟一个真实的场景:
用户:帮我添加用户验证
❌ 错误做法(直接编码):
AI 默默假设需要邮箱 + 密码验证
直接实现完整的 OAuth 流程
添加了未请求的"记住我"功能
还顺便加了密码强度检测
结果:用户只需要简单的手机号验证
✅ 正确做法(先思考):
AI:在开始之前,我需要确认几个问题:
1. 验证方式:需要哪种验证?
- 邮箱 + 密码
- 手机号 + 验证码
- 第三方登录(Google/GitHub)
2. 安全级别:
- 简单应用:基础验证即可
- 金融/医疗:需要双因素认证
3. 额外功能:
- 是否需要"记住我"?
- 是否需要密码找回?
我的建议:如果是 MVP,建议先用手机号 + 验证码,最简单。实践检查清单
根据我的理解,每次 AI 编程前都应该问自己(或要求 AI):
- 我是否明确陈述了所有假设?
- 如果有多种解释,我是否都呈现出来了?
- 我是否指出了潜在的权衡取舍?
- 如果有更简单的方法,我是否提出了建议?
- 我是否在困惑时停下来寻求澄清?
实战中的价值
在实战中,这个原则可以避免 80% 的返工。很多时候,AI 直接开写,结果写了一半发现理解错了,或者写完了发现不是用户想要的。
关键转变:从"默默假设→直接执行"变成"明确假设→确认→执行"。
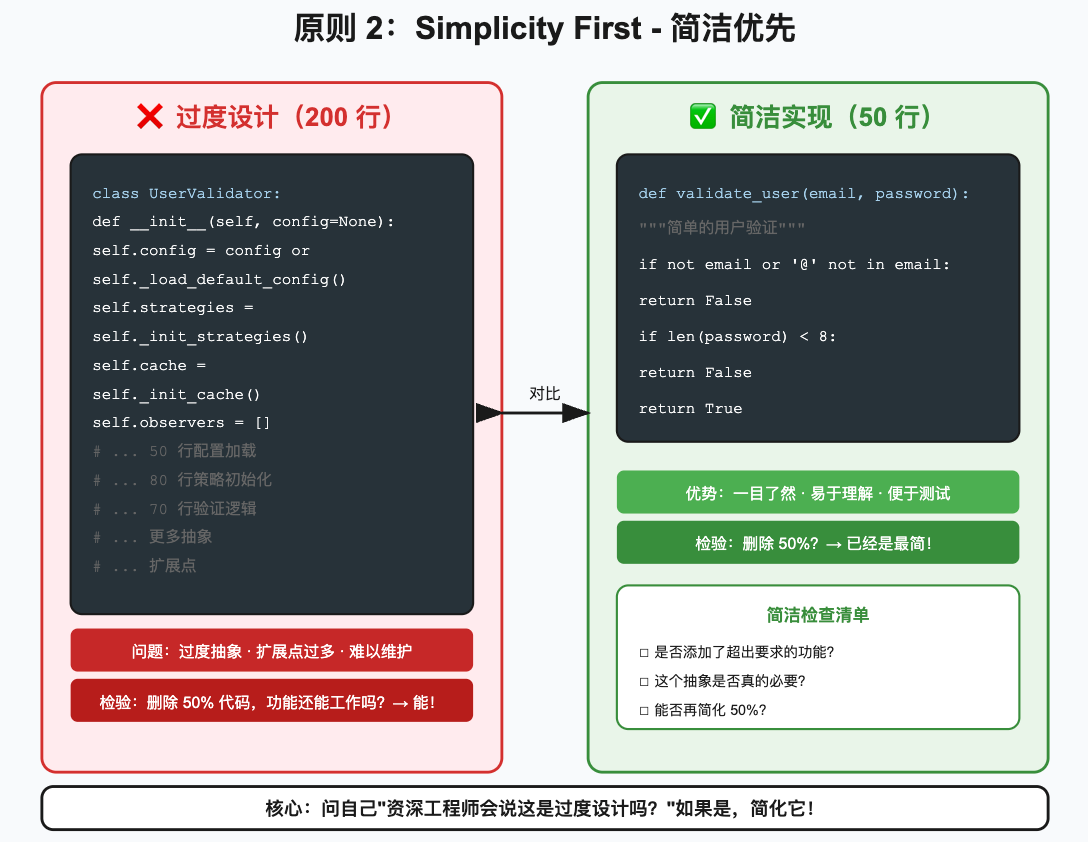
2.2 原则二:Simplicity First(简洁优先)
核心要义
用最少的代码解决问题,不添加任何投机性内容
反面案例
来看一个对比示例:
python
# ❌ 错误:过度设计(200 行)
class UserValidator:
def __init__(self, config=None):
self.config = config or self._load_default_config()
self.strategies = self._init_strategies()
self.cache = self._init_cache()
self.observers = []
def _load_default_config(self):
# 加载默认配置
# ... 50 行代码
def _init_strategies(self):
# 初始化策略模式
# ... 80 行代码
def validate(self, email, password):
# 复杂的验证流程
# ... 70 行代码
# ✅ 正确:简洁实现(50 行)
def validate_user(email, password):
"""简单的用户验证"""
if not email or '@' not in email:
return False
if len(password) < 8:
return False
return True为什么会过度设计?
个人感觉,AI 过度设计的原因有几个:
- 训练数据偏差:高质量的开源代码往往有更完善的抽象,AI 学到了这些模式
- 展示欲:AI 倾向于展示"我知道设计模式"
- 防御性编程:为了"将来可能用到"而添加扩展点
实践检查清单
每次 AI 生成代码后,用这些问题检查:
- 我是否添加了超出要求的功能?
- 这个抽象是否真的必要?(还是为了"将来可能用到")
- 我是否添加了未请求的"灵活性"?
- 这段代码能否再简化 50%?
- 资深工程师会说这是过度设计吗?
检验标准
指南里提供了一个很好的检验标准:
问自己:如果删除这段代码的 50%,功能还能正常工作吗?
如果答案是"能",那就删掉那 50%。
2.3 原则三:Surgical Changes(精准修改)
核心要义
只修改必须修改的部分,只清理自己造成的混乱
这个原则我个人非常喜欢,因为它解决了一个很常见但容易被忽视的问题。
反面案例
用户:修复这个计算 bug
❌ 错误做法:
- 修复了 bug ✓
- "顺便"重构了相邻的函数 ✗
- 修改了注释风格 ✗
- 删除了"看起来没用"的变量 ✗
结果:Diff 很大,引入了新的 bug,用户很困惑
✅ 正确做法:
- 只修复 bug 相关的代码 ✓
- 保持相邻代码不变 ✓
- 匹配现有风格 ✓
- 如果看到死代码,提及但不删除 ✓
结果:Diff 很小,只改必要的,用户放心为什么这个原则重要?
在我的理解中,这个原则的核心价值是尊重用户的代码所有权。
AI 经常会"好心"地改进代码,但:
- 用户可能故意那样写
- 用户可能有历史原因
- 用户可能不认同你的"改进"
实践检查清单
- 我是否修改了与任务无关的代码?
- 我是否"改进"了相邻的代码或注释?
- 我是否匹配了现有的代码风格?
- 我删除的代码是否都是因为我的修改而变得无用?
- 每一行修改都能直接追溯到用户的要求吗?
检验标准
**Diff 检验标准:每一行修改的代码,都能说出"这是为了 XXX 要求"。
如果某行修改说不清楚为什么改,那就不要改。

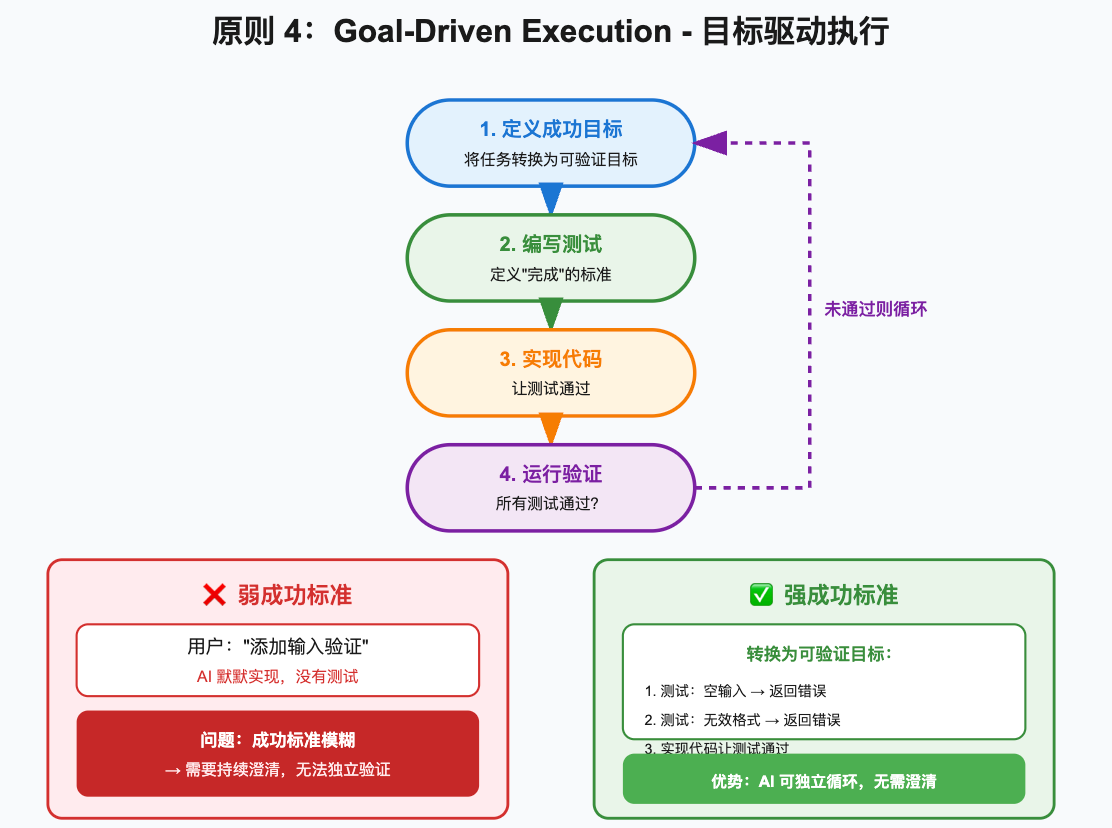
2.4 原则四:Goal-Driven Execution(目标驱动执行)
核心要义
定义成功标准,循环直到验证
这个原则可能是四个中最实用的一个。
反面案例
用户:添加输入验证
❌ 错误做法:
- 默默实现验证逻辑
- 没有测试
- 成功标准模糊:"让它工作"
结果:不知道是否真的工作了,用户需要手动测试
✅ 正确做法:
- 转换为可验证目标:
1. 编写测试:无效邮箱 → 返回错误
2. 编写测试:空密码 → 返回错误
3. 编写测试:有效输入 → 通过验证
4. 实现代码让测试通过
5. 运行测试确认全部通过
结果:有测试证明功能正确,用户放心核心洞察
指南里有一句话非常精辟:
"强大的成功标准让 LLM 能够独立循环。弱的标准('让它工作')需要持续的澄清。"
我的理解是:定义清楚"完成"是什么样子,AI 才能独立完成。
实践检查清单
- 我是否将任务转换为可验证的目标?
- 我是否编写了测试来定义成功?
- 我是否有明确的验证步骤?
- 我能否独立循环直到所有测试通过?
- 成功标准是否足够强,不需要额外澄清?
多步骤任务格式
对于复杂任务,指南推荐使用这种格式:
1. [编写测试:空输入应该失败] → 验证:测试运行失败
2. [实现验证逻辑] → 验证:测试通过
3. [添加边界条件测试] → 验证:所有测试通过这种格式的好处是:
- 每一步都有明确的目标
- 每一步都有验证标准
- 可以独立执行和检查
三、实战应用
3.1 如何在日常开发中使用
场景 1:新功能开发
基于我的理解,推荐这个流程:
1. 先思考(原则 1)
- 明确需求和边界
- 呈现技术方案和权衡
- 确认后再开始
2. 简洁优先(原则 2)
- 从最简单的实现开始
- 不添加"将来可能用到"的功能
- 如果复杂了,重写
3. 精准修改(原则 3)
- 只写必要的代码
- 不影响现有代码
- 匹配现有风格
4. 目标驱动(原则 4)
- 用测试验证功能
- 定义"完成"的标准
- 循环直到通过场景 2:Bug 修复
1. 先思考
- 重现 bug
- 理解根因
- 确认修复方案
2. 简洁优先
- 最小修复方案
- 不"顺便"重构
3. 精准修改
- 只改 bug 相关代码
- 不影响其他功能
4. 目标驱动
- 编写重现测试
- 确保修复
- 回归测试场景 3:代码审查
用四大原则作为审查清单:
Review Checklist:
- [ ] 是否先思考了假设和权衡?
- [ ] 代码是否足够简洁?
- [ ] 修改是否精准?
- [ ] 是否有明确的验证标准?3.2 与现有工作流整合
整合到 Code Review
在 PR 模板中添加四大原则检查项:
markdown
## AI 编程检查清单
- [ ] Think Before Coding: 是否明确了假设和权衡?
- [ ] Simplicity First: 代码是否足够简洁?
- [ ] Surgical Changes: 修改是否精准?
- [ ] Goal-Driven: 是否有验证测试?整合到 CI/CD
- 自动化测试覆盖(原则 4):所有 AI 生成的代码必须有测试
- 代码复杂度检查(原则 2):使用工具检查圈复杂度
- Diff 大小限制(原则 3):单次修改不超过 N 行
3.3 常见误区与规避
误区 1:过度谨慎
问题:每个小任务都要写长篇分析
用户:把这个变量改名
AI:(开始长篇分析)
- 假设你要改这个变量...
- 有多种改名方案...
- 权衡如下...
用户:我只是改个名啊!规避:指南里说了,"这些指南偏向谨慎而非速度。对于琐碎的任务,需要运用判断力。"
我的建议:对于简单任务,简化流程,直接做。
误区 2:教条主义
问题:死守原则,不考虑实际情况
用户:快速修复这个 typo
AI:根据原则 1,我需要先确认...
根据原则 2,我应该考虑最简方案...
根据原则 4,我需要编写测试...
用户:我只是为了修个拼写错误啊!规避:原则是指导,不是铁律。根据实际情况调整。
误区 3:忽视速度
问题:过度追求完美,拖延交付
规避:在谨慎和速度之间找到平衡。MVP 阶段可以牺牲一些完美度,快速迭代。
四、这套指南的牛逼之处
4.1 设计上的精妙
个人感觉,这套指南有几个很聪明的地方:
1. 极简设计
- 单个文件,易于分发和维护
- 可以直接合并到项目中
- 没有复杂的配置
2. 问题驱动
- 直接针对 Karpathy 观察到的具体问题
- 每条原则都有明确的针对性
- 不是空洞的"最佳实践"
3. 可操作性强
- 每条原则都有具体的行为指导
- 有检查清单
- 有检验标准
4. 可验证
- 提供了明确的检验标准
- 可以量化评估
- 不是模糊的建议
4.2 与其他实践的区别
vs 传统最佳实践
| 维度 | 传统最佳实践 | Karpathy 指南 |
|---|---|---|
| 目标 | 人类程序员 | LLM 编程助手 |
| 重点 | 代码质量 | 行为透明度 |
| 形式 | 文档/规范 | 可执行指令 |
| 验证 | Code Review | 自动化检查 |
vs Code Review 标准
| 维度 | Code Review | Karpathy 指南 |
|---|---|---|
| 时机 | 事后检查 | 事前预防 |
| 重点 | 代码质量 | 编程行为 |
| 执行 | 人工审查 | AI 自律 |
我的理解是:这套指南不是要替代 Code Review,而是让 Code Review 更容易。
五、最后的思考
个人感觉,这套指南的本质是让 AI 更透明。
它不是要束缚 AI,而是让 AI 的行为更可预测、更可控。最终目标是人机协作更高效。
在实践中,我发现遵循这些原则的 AI 编程:
- 返工更少
- 代码更干净
- 信任度更高
或许,这就是 AI 编程的最佳实践。
参考文献
- Andrej Karpathy 原始推文:https://x.com/karpathy/status/2015883857489522876
- Karpathy-Inspired Claude Code Guidelines: https://github.com/multica-ai/karpathy-code-guidelines
- CLAUDE.md:
andrej-karpathy-skills-main/CLAUDE.md - SKILL.md:
andrej-karpathy-skills-main/skills/karpathy-guidelines/SKILL.md - README.md:
andrej-karpathy-skills-main/README.md