你有没有遇到过这种情况:精心搭建的RAG系统,处理普通文本时如鱼得水,一碰到PDF里的表格、图表、信息图,立刻哑火------不是找错了页面,就是关键数据完全没检索到。
这不是你的系统问题。这是整个行业在视觉文档检索上集体踩的坑。
过去几年,RAG(检索增强生成------一种让大模型先检索相关文档再生成回答的技术范式)几乎成了企业AI应用的标配。但当文档里的关键信息藏在一张能量来源分布图里、藏在一个跨越半页的财务报表里、藏在一份密密麻麻的政府报告版面里------现有的检索系统,基本束手无策。
这个问题,来自法国CentraleSupélec、Illuin Technology和Equall.ai的研究团队,在ICLR 2025上给出了一个出人意料的答案。
1.那条"越修越重"的流水线
今天,一个工业级文档检索系统长什么样?
你拿到一份PDF,首先要跑版面检测------用深度学习模型识别哪里是标题、哪里是段落、哪里是表格、哪里是图片。检测完之后,要跑OCR(光学字符识别)------把非原生PDF里的扫描文字识别成可索引的文本。识别完之后,还要做分块------把文本按语义边界切开,保证每个chunk(文本片段)都有连贯的信息。
如果文档里有图表呢?有两条路:要么用OCR强行"读"它------大概率读出一堆乱码;要么调用一个强大的视觉语言模型,花好几秒钟给它生成一段文字描述,再把描述送进检索系统。
这段描述长什么样?下面这张来自能源领域的图表,就是系统调用Claude-3 Sonnet生成的结果------几百字的文字描述,替代了原本一眼能看清的可视化内容。信息,在这里已经开始变形
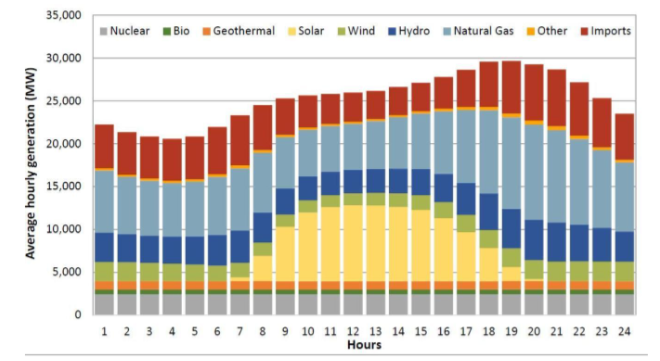
图1
图1对"Energy"测试集中一张能源来源分布图,描述生成模型需要输出数百字文本来尽量还原原图内容。这是当前最强的描述生成方案------但它依然是翻译,而翻译必然有损
一页文档,走完这条流水线,平均要花7秒多。
不是工程师不努力。是这条路的代价,已经越来越难以承受------每增加一个视觉理解步骤,就多一处出错的概率、多一层延迟、多一笔API调用的成本。更关键的是,无论怎么优化,文字描述永远是对原始视觉信息的有损压缩。表格的精确数字、图表的空间关系、版面布局传达的层级信息,统统会在这个"翻译"过程中丢失一部分。
三条现有路线,用一句话总结:文本只检索文本,太局限;OCR强行读图,太粗暴;VLM生成描述,太缓慢。三条路都没有真正触及"让系统直接理解视觉文档"这个核心问题。
那,有没有可能完全绕开这条路?
2.一个大胆的想法:直接看图
ColPali给出的答案,简单得有点出乎意料------
把文档页面当成一张图片,直接嵌入。
不要OCR。不要版面检测。不要分块。不要生成文字描述。把每一页PDF渲染成图像,送进一个视觉语言模型,得到它的多向量嵌入表示,然后直接拿来检索。
这个想法的核心转变,是把检索的战场从"文字空间"移到了"视觉空间"。
研究团队由Illuin Technology的Manuel Faysse、Hugues Sibille、Tony Wu等人联合主导,Equall.ai的Pierre Colombo和CentraleSupélec的Céline Hudelot参与其中。这支队伍同时覆盖了工业NLP系统、视觉语言模型和信息检索三个方向------提出这个想法时,他们已经有足够的弹药把它做实。
但"直接看图"说起来容易。真正的问题有两个:一,用什么模型来"看"?二,怎么让图像嵌入和文字查询高效匹配?
3.架构解析:VLM × 晚期交互的化学反应
先来看整体。下面这张图把两条路放在一起------左边是传统流水线,右边是ColPali------差距一目了然
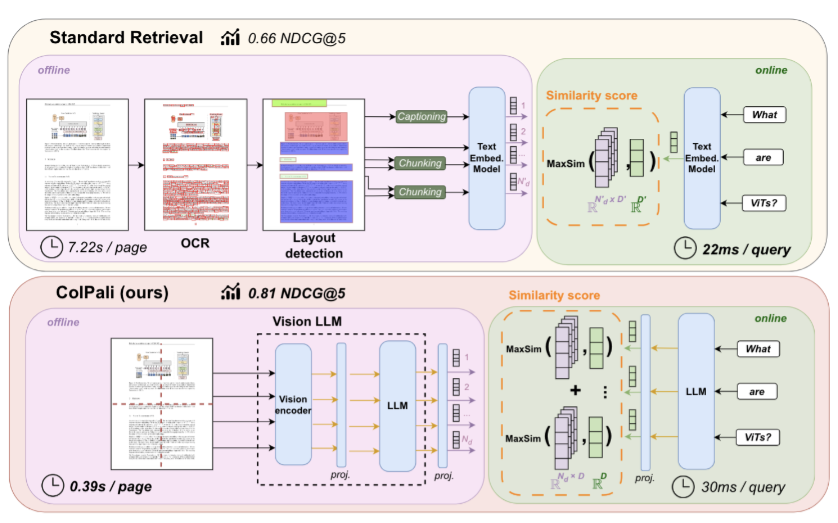
图2
图2是ColPali与标准检索方案的对比示意图。传统方案需要经历版面检测、OCR、分块、嵌入四个串联步骤;ColPali只需一步:将页面图像直接送入VLM,生成多向量嵌入,性能更强,延迟更低
ColPali的架构,是两个已有思路的化学组合------PaliGemma和ColBERT晚期交互机制。
为什么选PaliGemma?
PaliGemma是Google发布的一个3B参数视觉语言模型(VLM)。它的结构直接:SigLIP视觉编码器(负责把图像切成patch,每个patch------大约14×14像素的小块------生成一个向量)+ Gemma-2B语言模型(负责把这些视觉向量与文字语义对齐)。
它的关键特性,是使用了全注意力的前缀语言模型架构------图像token和文字token之间可以做完整的双向注意力计算。这意味着,PaliGemma处理一页文档图像时,图像里每一个局部区域都有机会与整体语义上下文交互。
一句大白话:它不只是"看"图,而是"理解"图里每个局部在整张图语义中的位置。
把PaliGemma用于检索,还有一个关键优势------它的输出token天然处于一个统一的嵌入空间里。文字query的token向量和图像patch的token向量,可以直接做相似度计算,不需要额外的跨模态对齐步骤。
晚期交互:每个patch都是一个"证据片段"
传统的双编码器(bi-encoder)检索,做法是把整篇文档压缩成一个向量、把查询也压成一个向量,然后算余弦相似度。干净,高效。但有个巨大问题------一个向量装不下一页图文混排文档的所有信息。就像你要在一句话里概括一部百科全书,必然会丢掉大量细节。
ColBERT的晚期交互(Late Interaction)机制,提供了另一种思路。与其把所有信息压进一个向量,不如给文档的每个token都保留一个向量,组成一个"向量组"。匹配的时候,对查询的每个token,找文档向量组里与它最相似的那一个,把所有这些最大相似分加起来,就是最终匹配分数。
公式写出来是:
其中Eq是查询的多向量表示,Ed是文档的多向量表示。逐个查询向量,找文档向量里与它点积最大的那一个,加总。
翻译成人话------不是让整篇文档和整个查询"握手",而是让查询里的每个词,在文档里找最相关的那块区域,把这些局部相关分数加总。
这对图像尤其有用。一个查询词"每小时发电量",不需要整张图都跟它相关------只需要在图里精确定位到那个标注了横轴hours的区域就够了。
投影层:降维与统一
ColPali在PaliGemma的输出上额外加了一个线性投影层,把每个token的向量映射到128维的公共嵌入空间------与原始ColBERT保持一致。每页文档被PaliGemma处理后产生1024个patch向量,经投影后得到1024个128维向量,用于晚期交互检索。
整体结构:图像 → PaliGemma(SigLIP + Gemma-2B)→ 1024个patch向量 → 128维投影 → 晚期交互打分。
这是一条端到端完全可训练的路径。不需要在检索目标之外做任何额外优化。
4.训练:教会模型"检索式"看图
ColPali的训练用的是对比学习框架------给一批查询-页面对,让正确的查询和对应页面的晚期交互分尽量高,批次内错误配对的分数尽量低。损失函数用的是pairwise cross-entropy(成对交叉熵),只考虑批次内最难的负样本,而非所有负样本------这让训练信号更加集中,消融实验证明比in-batch全负样本对比损失高出1.6个nDCG@5点。
训练集共118,695个查询-页面对,来源分两块:63%来自公开学术数据集(DocVQA、InfoVQA、TAT-DQA、arXivQA等),37%是用网络爬虫收集的PDF页面配合Claude-3 Sonnet生成的合成问题。
数据的具体构成如下------
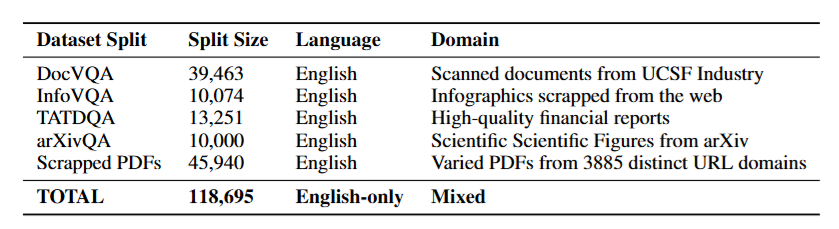
图3
图3是ColPali训练集数据来源详情。DocVQA贡献39,463条,InfoVQA贡献10,074条,TATDQA贡献13,251条,arXivQA贡献10,000条,网络爬虫PDF贡献45,940条,合计118,695条,全部为英文数据
全部训练数据都是英文。
但研究者特意保留了非英文测试集------ViDoRe里有法语任务。他们想看PaliGemma底层Gemma-2B的多语言预训练知识,能否帮助模型做零样本跨语言泛化。结果:可以,而且效果相当可观。
训练用LoRA(低秩适应------一种只更新模型中少量参数的高效微调技术),不全量微调。在语言模型的Transformer层和最终投影层上施加LoRA适配器(rank=32, α=32)。8块GPU并行,1个epoch,batch size 32。整个训练过程轻量,结果却扎实。
5.ViDoRe:给视觉文档检索立一把新标尺
光有模型不够。ColPali同时发布了ViDoRe(Visual Document Retrieval Benchmark),一个专门评测视觉文档检索能力的基准------而这个基准本身,就是这篇工作的第一个核心贡献。
为什么需要新基准?
现有的文本检索基准(MTEB、BEIR等)只评测纯文本嵌入能力;现有的视觉语言模型基准测的是自然图像;没有任何基准,在工业真实场景下端对端评测一个系统从接收查询到找到正确文档页面的完整链路。ViDoRe填了这个空。
基准包含10个子任务,分两类:
学术任务(Academic Tasks):复用现有的视觉问答数据集------DocVQA(扫描文档)、InfoVQA(信息图)、TAT-DQA(金融报告)、arXivQA(科学图表)------把每个问题当查询,对应页面当检索目标。另外还有TabFQuAD,一个针对法语工业PDF表格的新数据集,随这篇论文一起首次发布。
实用任务(Practical Tasks):用网络爬虫收集了能源、政府报告、医疗、AI和环保(法语)五个领域的真实PDF文档,每个领域1000页,配100条经人工审核的高质量查询。这些任务有个刻意为之的设计------同领域文档语义高度相近,制造更难的检索场景,更贴近真实工业部署情况。
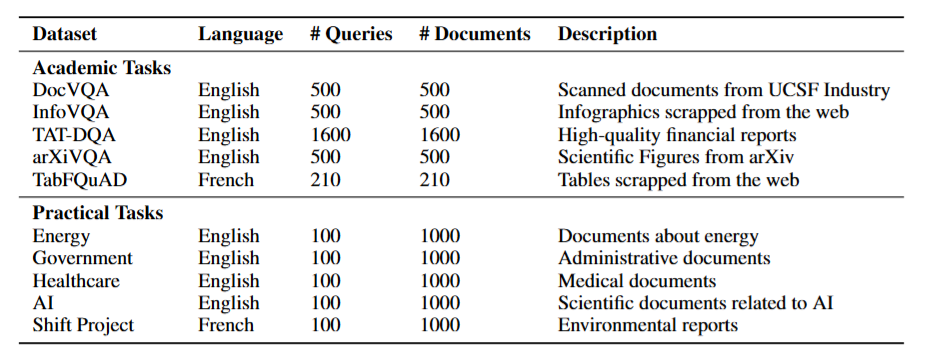
图4
图4是ViDoRe任务构成一览。学术任务覆盖扫描文档(DocVQA)、信息图(InfoVQA)、金融报告(TAT-DQA)、科学图表(arXivQA)和法语工业表格(TabFQuAD);实用任务覆盖能源、政府、医疗、AI和环保(法语)五个领域,每个领域1000页文档配100条人工审核查询。光看这张表,就能明白为什么之前没有系统真正把"视觉文档检索"当成一个严肃的独立问题来评测
主评测指标是nDCG@5(归一化折扣累计增益------衡量前5个检索结果的排名质量),同时报告每页索引延迟和查询延迟。
6.数字:差距究竟有多大?
一句话概括实验结论:ColPali在视觉文档检索上,把所有现有方法甩出了一大截------不只是好一点,而是好了一个量级。
基线对比
现有工业级方案的最强配置:Unstructured(版面检测+OCR+分块)+ Claude-3 Sonnet描述视觉元素 + BGE-M3嵌入。在ViDoRe上,这个方案的平均nDCG@5是67.0。
ColPali是81.3。
差了14个点。在信息检索领域,这不是小差距------这是一个维度的跨越。
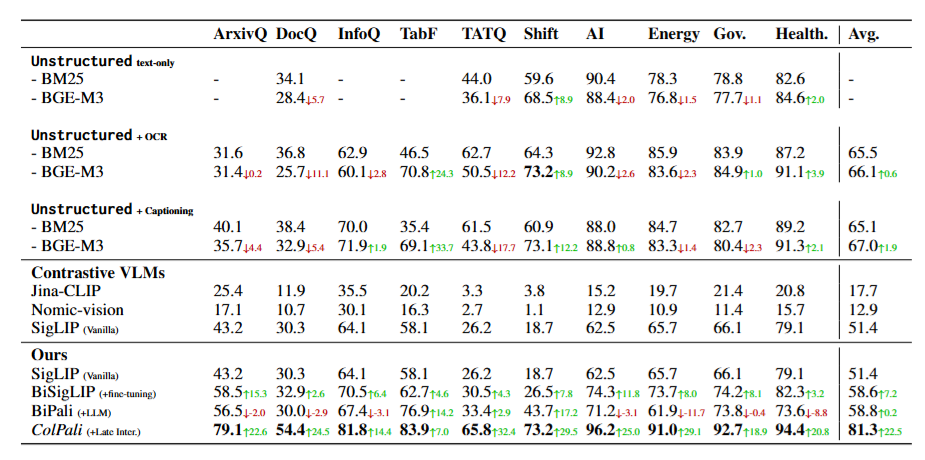
图5
图5是ViDoRe全任务评测结果(nDCG@5)。从最弱的对比式VLM(Jina-CLIP均值17.7),到最强的文本流水线(Unstructured+描述生成+BGE-M3均值67.0),再到ColPali(81.3)。差距最悬殊的是ArxivQA一列:最强基线35.7,ColPali79.1------这个差距,几乎是质变
在最考验视觉理解的子任务上,差距更夸张:
-
信息图(InfoVQA):81.8 vs 71.9
-
科学图表(ArxivQA):79.1 vs 35.7(这个差距接近一倍)
-
法语表格(TabFQuAD):83.9 vs 70.8
更重要的是,ColPali在索引速度上完全碾压传统流水线------每页0.39秒 vs 7.22秒,快了将近20倍。
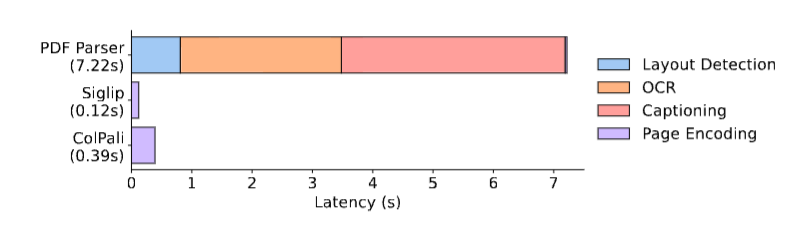
图6
图6是各方案每页文档的离线索引延迟对比。Unstructured标准流水线(含描述生成)耗时7.22秒,拆解下来:版面检测0.81s、OCR 2.67s、描述生成3.71s、页面编码0.03s。SigLIP 0.12秒。ColPali 0.39秒。每一步都是可以省掉的代价------ColPali把它们全省掉了
逐步叠加:每个组件的贡献
研究团队用了一个非常清晰的消融实验设计,把三个核心要素逐步叠加,测试每一步的贡献:
去掉任务特定训练,只用原始SigLIP:nDCG@5均值51.4。
加入文档检索数据微调(BiSigLIP):升到58.6。图表和表格任务提升明显,说明任务特定数据确实重要。
接入LLM上下文处理图像patch(BiPali):英文任务只微升到58.8,但法语任务大幅改善------LLM的多语言预训练知识起了关键作用。
加入晚期交互(ColPali):一跃到81.3。
这说明什么?说明那14个百分点的核心贡献者,不是更大的模型,不是更多的数据,而是"多向量+晚期交互"这个机制本身。去掉它,系统退回到双编码器,性能瞬间跌回58档。
更强的VLM,更强的检索器
用Qwen2-VL 2B替换PaliGemma,用同样的训练策略训出ColQwen2(控制patch数量在768),nDCG@5提升到86.6------高出ColPali 5.3个点。
这意味着什么?意味着视觉语言模型的生成能力提升,会直接转化为检索能力的提升。ColPali框架把VLM进步的红利,直接传导到了文档检索任务上。未来每一代更强的多模态基础模型,都是这个框架的免费升级。
7.可解释性与存储优化:两个意外收获
晚期交互的"透明度红利"
晚期交互机制有一个传统双编码器没有的能力------可解释性。
对每个查询词,可以把它的向量与所有图像patch向量做相似度计算,在原图上高亮最相关的区域。不是模型说它觉得哪里重要------是数学直接告诉你,每个查询词定位到了图像的哪个具体位置。
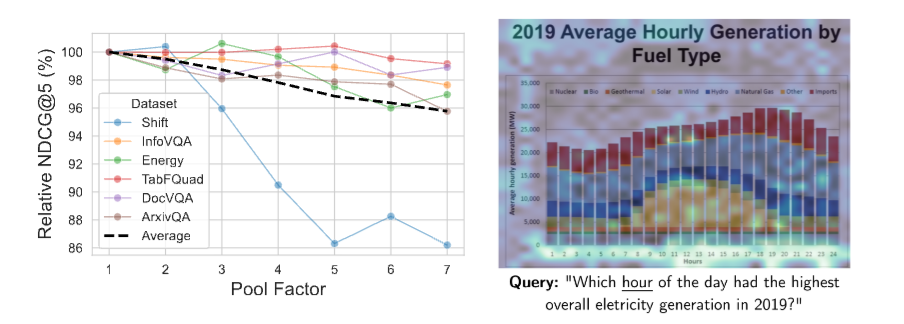
图7
图7左中,不同pool factor下,各数据集的相对nDCG@5保留率。绝大多数数据集在pool factor=3时保持在97%以上;Shift数据集(文字密集型环保报告)是明显的离群点,下降更快------这恰好揭示了一个规律:文档视觉信息越密集,patch之间的差异越不可压缩
图7右中,对查询词"hourly",ColPali精确定位到了图表横轴(标注hours的位置),同时对图中"hours"文字区域也有高响应。模型展现出了强OCR能力,但不只是文字匹配------轴的视觉结构本身也被识别为高度相关的视觉特征。
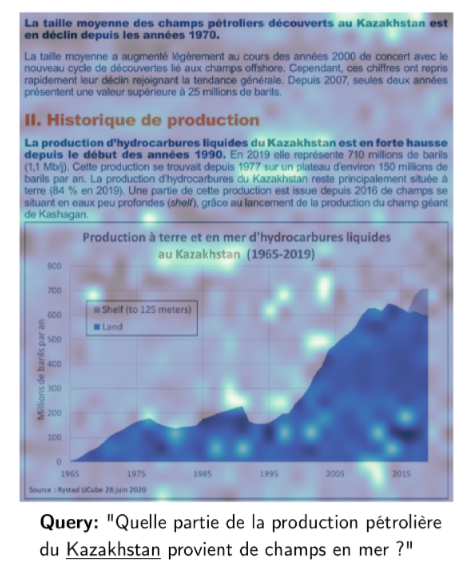
图8
图8中,查询词"Kazakhstan"对应的图像patch相似度热力图,来自Shift测试集中一张哈萨克斯坦油田分布地图。文字"Kazakhstan"所在区域最亮,但离岸油田名称"Kashagan"附近的patch也明显亮起------模型的响应,超越了字符匹配的范畴
在一个哈萨克斯坦油田地图的测试中,查询词"Kazakhstan"触发了一个令人意外的结果------除了文字"Kazakhstan"本身,"Kashagan"(哈萨克斯坦一个著名的离岸油田名称)附近的patch也亮了起来。模型调用了世界知识,而不只是做字符串匹配。
这种可解释性,在高风险的工业应用场景里,是极其宝贵的------你可以精确知道模型为什么检索到这一页,而不是拿到一个不知来源的相似度分数。
Token Pooling:压缩存储,几乎不损性能
ColPali每页文档需要存储1024个向量,每个128维,float16格式,约257.5KB/页。对存储上亿页文档的大型企业,这个成本需要认真对待。
Token Pooling提供了一个简洁的压缩方案:把图像中相邻且内容相似的patch均值池化合并,减少需要存储的向量数量。
图7左:pool factor=3时(每3个patch合并成1个,总向量数减少66.7%),平均nDCG@5只下降2.2%,相对性能保留97.8%。代价极小,收益显著。
唯一的注意点:文字密集的文档(如Shift环保报告数据集)在池化后下降更明显------信息密度越高的文档,相邻patch之间差异越大,池化损失越多。实际部署时,可以根据文档类型动态选择pool factor。
8.这是视觉检索时代的入场券
ColPali展示的,不只是一个比现有方案更快更强的检索模型------它展示的是一种新的文档理解范式的可行性:不要把文档拆成碎片再重组,直接在视觉层面理解整页内容。
不是为了省掉几步工程流水线,而是为了在信息源头保留更多原始语义。不是为了让检索更快,而是为了让检索更真实地反映人类理解文档的方式。不是一次工程优化,而是一次路线切换。
向前看,有三个值得追踪的方向:
端到端视觉RAG。ColPali解决的是检索端,但如果检索之后的生成端也能直接在图像上操作------不再需要把检索结果转回文字才能送给语言模型------整个管道将彻底消除文字转换环节的信息损失。研究团队明确把这个列为最重要的未来方向。
可信度估计。多向量晚期交互输出的是"每个查询词在文档中的局部匹配分数",这比单向量余弦相似度携带更多信息------可以用来做置信度估计,支持"不知道就拒绝回答"的abstention机制,对医疗、法律、金融等高风险场景的部署至关重要。
基础模型即检索器。ColQwen2的结果已经证明:VLM生成能力越强,改造成检索器之后效果越好。随着多模态基础模型能力的持续提升,这个框架只会越跑越快。
如果说过去十年的文档检索,是一场靠工程堆砌勉强触碰视觉内容的艰难跋涉,那么ColPali展示的是一条真正意义上"直接理解"文档的新路。
而这条路,才刚刚开始。