震惊!C++ 为了让我们能写std::vector<int> v = {1, 2};到底付出了什么代价?
我们先看一个场景:
c++
std::vector<int> v1(10, 20); // 大哥,这铁定是:10个元素,每个都是20。
std::vector<int> v2{10, 20}; // 大哥,这是:两个元素,10 和 20。为什么 {} 这么霸道?
因为编译器看到花括号就疯了,会拼了老命去找一个参数是 std::initializer_list 的构造函数。
哪怕参数类型对不上,它宁愿报错也不愿意调别的构造函数。
这就像钓鱼佬平时钓不到几条鱼,但要是哪天让他钓上条大鱼。
嘿,那这几天就别想看到他回家,哪怕媳妇拿把刀架在他脖子上都没用。
这就是 initializer_list 劫持。
基础语法与使用
1. 列表初始化
以前初始化个变量,那叫一个麻烦:int 用 =,struct 用 {},数组用 \[\],vector 得先构造再 push_back,累得跟狗似的。
现在好了,C++11 大手一挥:都给老子用大括号!
c++
int a{5}; // 行!
std::string s{"hello"}; // 这也行!
std::vector<int> v{1,2,3};// 包行的!
struct Point { int x; int y; };
Point p{10, 20}; // 太行了!这里得插一条小知识:{} 禁止窄化转换,这是它比 = 安全的地方。
c++
int x = 3.14; // 编译器睁一只眼闭一只眼,警告都懒得给,x变成3
int y{3.14}; // 编译器直接掀桌:ERROR,从 double 到 int 会丢数据2. std::initializer_list 的基本操作
initializer_list 就三个操作:
- 瞅一眼大小:lst.size()
- 拿个开头指针:lst.begin()
- 拿个结尾指针:lst.end()
因为它没有 operator\[\]。
所以我们想 lst2 是不行的。
想取第三个值?老老实实 *(lst.begin() + 2)。
为什么不让随机访问?
因为它本质只是对底层数组的两个指针(首、尾),C++标准委员会觉得给我们俩指针就够了,要啥自行车?
虽然它自己没 \[\],但因为它有 begin/end,所以我们可以:
c++
void print(std::initializer_list<int> list)
{
// 范围for
for (auto& elem : list)
{
std::cout << elem << " ";
}
}因为 elem 的类型是 const 的,我们想改都改不了。
3. 接受 initializer_list 的函数
使用 initializer_list 能让我们自定义些花括号函数。
情景一:我要写个自定义求和
c++
// 写法极其无脑
int sum(std::initializer_list<int> list)
{
int total = 0;
for (auto x : list) total += x;
return total;
}
// 调用:
sum({1, 2, 3, 4, 5}); // 返回15情景二:接受一推参数
c++
std::string join(std::string delim, std::initializer_list<std::string> strs);
// 调用:join(", ", {"a", "b", "c"});4. 构造函数中的 initializer_list
先看一段代码:
c++
class MyVector
{
public:
// 默认构造
MyVector() :_data(0)
{
std::cout << "调了默认构造函数" << std::endl;
}
// 构造函数1:老老实实建N个默认值
MyVector(size_t n) : _data(n)
{
std::cout << "调了 size_t 构造函数" << std::endl;
}
// 构造函数2:列表初始化
MyVector(std::initializer_list<int> list) : _data(list)
{
std::cout << "调了 initializer_list 构造函数" << std::endl;
}
private:
std::vector<int> _data;
};灵魂拷问环节:
c++
MyVector v1(5); // 输出:调了 size_t 构造函数。这没毛病
MyVector v2{ 5 }; // 输出:调了 initializer_list 构造函数。
MyVector v3{ 1, 2 }; // 铁定是列表初始化。
MyVector v4{}; // 此时会调哪个?以为 {} 一定调列表构造?错咯!
当 {} 为空时,它调用的是默认构造函数。
因为编译器一看:"哦,你想列表初始化,但列表里没东西啊?那算了,你回默认构造那儿排队去吧。"
当然了,只要花括号里有一丁点东西,哪怕只有一个,列表构造就是第一优先级。
内部机制与生命周期
1. initializer_list 的本质
先看看 initializer_list 的源码,依旧是简化版:
c++
// 这玩意儿底层差不多就长这样(简化版)
template<class T>
class initializer_list
{
public:
initializer_list() :_first(nullptr), _last(nullptr) {}
initializer_list(T* first_arg, T* last_arg)
: _first(first_arg), _last(last_arg) {}
const T* begin() const noexcept { return _first; }
const T* end() const noexcept { return _last; }
size_t size() const noexcept { return static_cast<size_t>(_first - _last); }
private:
const T* _first; // 指向第一个元素的指针
const T* _last; // 指向最后一个元素的指针
};假设我们写了这行代码:
c++
auto list = {1, 2, 3, 4, 5};编译器偷偷干的事儿:
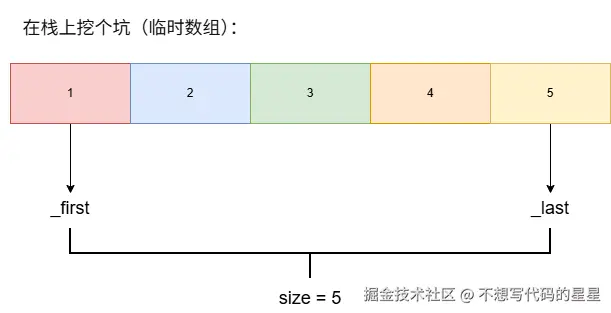
initializer_list 不拥有数据,它只是数据的观察者。
2. 临时数组的生命周期
这是最危险、最反直觉、Bug 率最高的玩意。
情况 A:正常的局部使用(安全)
c++
void func()
{
std::initializer_list<int> lst = {1, 2, 3};
// 在这花括号里面,底层数组是活着的,放心用
for (auto x : lst) std::cout << x;
} // 函数结束,底层数组和 lst 一起升天,完美编译器保证:底层数组的生命周期完全等同于 initializer_list 对象本身的生命周期。
情况 B:返回给上级领导
c++
std::initializer_list<int> make_list()
{
return {1, 2, 3};
}
int main()
{
auto list = make_list();
std::cout << *list.begin(); // 大概率打印出 1,但这只是因为栈还没被覆盖
}分析:
- return {1,2,3}; 这句话会先在 make_list 的栈帧上创建临时数组。
- 函数一返回,栈帧被销毁,那片内存就变成公共厕所,谁都能来踩一脚。
- 我们还在 main 里拿着那个 list 使用,其实它指向的已经是垃圾数据。
initializer_list 并不拥有它指向的元素数组。
它只是一个轻量级的视图,内部通常仅包含指向数组首尾元素的指针或长度。
情况 C:基于范围的for循环
这是最隐蔽的,因为 for 语句里那个临时对象我们看不见。
c++
// 错误示范:list 的生命周期只在这一行
for (auto x : std::initializer_list<int>{a, b, c})
{
// 如果这里把 x 的地址存到全局变量,或者起个线程异步处理...
// 循环体执行时 list 确实活着,但如果有延后操作,立刻完蛋。
}看了三个栗子,真是江湖险恶,处处都是危险呐。
那么正确做法:
- initializer_list 永远不要作为函数返回值。
- 如果必须返回一堆值,请用 std::vector 或 std::array,别偷懒。
- initializer_list 就是一个引用型参数,适合传参,不适合存储。
3. 拷贝与赋值
拷贝 initializer_list 不会拷贝底层数据。
c++
std::initializer_list<int> lst1 = {1, 2, 3};
std::initializer_list<int> lst2 = lst1; // 这是拷贝拷了什么玩意?
只拷贝了那俩指针和长度,底层数组纹丝不动,还是原来那个。
所以:
- lst1.size() 和 lst2.size() 都是 3。
- 修改底层数组?想都别想,因为元素是 const 的。
- 那拷贝有什么用?就是多了一个指向同一块只读内存的观察者。
因为拷贝只是浅拷贝,所以 initializer_list 的拷贝构造函数和赋值运算符都是 noexcept 的、极轻量级的。
所以我们在函数传参时,请大胆地按值传递。
4. 与 auto 的恩怨情仇
陷阱:
c++
auto x = {1, 2, 3}; // x 是什么类型?这很坑,因为大部分时候 auto 会推导出 int、double、std::string。
但唯独遇到 {},C++ 标准规定必须推导为 initializer_list。
安全建议:
c++
auto x = 1; // int
auto y = {1}; // std::initializer_list<int>
auto z{1}; // C++17 后是 int 了所有有些地方能别用 auto 接花括号就别用吧。
想用列表初始化容器,老老实实写 std::vector<int> v = {1,2,3} 蒜鸟。
与标准库的集成
1. 标准库容器的 initializer_list 构造函数
在 C++98 中,我们想初始化一个 vector,得这么写:
c++
std::vector<int> v;
v.push_back(1);
v.push_back(2);
v.push_back(3);或者稍微聪明点,用个数组:
c++
int arr[] = {1,2,3};
std::vector<int> v(arr, arr + sizeof(arr)/sizeof(int));简直是又累又慢。
现在好了,从 C++11 开始,所有标准库容器(除了 std::array 有点特殊)都给构造函数加了一条:
c++
std::vector<int> v = {1, 2, 3, 4, 5};
std::list<std::string> lst = {"hello", "world"};
std::map<std::string, int> m = {{"apple", 1}, {"banana", 2}};
std::set<double> s{3.14, 2.718, 1.414};我们看这个 = 后面的花括号,它就是通过 initializer_list 构造函数实现的。
看个伪代码:
c++
template<typename T>
class vector
{
public:
vector(std::initializer_list<T> init) {
_M_allocate_and_copy(init.begin(), init.end());
}
// ...
};标准库容器内部就是把 initializer_list 的首尾指针传给内部的内存分配函数,做个深拷贝。
这里必须提一嘴 std::map 的操作:
c++
std::map<int, std::string> m = {
{1, "one"},
{2, "two"}
};花括号里套花括号,外层的 {} 是 initializer_list 构造,内层的 {} 是调用了 std::pair<const Key, T> 的构造函数。
2. 赋值运算符重载
我们先看个示例:
c++
std::vector<int> v = {10, 20, 30};
v = {100, 200}; // v 现在长啥样?v 变成了 {100, 200},原来的 {10,20,30} 被彻底干掉了。
这背后发生了什么?
- 调用 v.operator=({100,200})。
- 这个重载函数内部会先 clear() 掉原有元素。
- 然后把 initializer_list 里的数据拷贝进来。
所以啊,千万别以为 v = {100, 200} 是往里面追加元素。
追加的活是 insert 和 push_back 干的,不是 operator= 的职责。
这哥们只负责替换。
3. initializer_list 与 std::array
这是很多人容易犯晕的地方,我们列个表格对比一下:
| 对比维度 | std::initializer_list | std::array |
|---|---|---|
| 我是谁? | 一个观察者,一个视图 | 一个真容器,一个包装类 |
| 我占内存吗? | 只有俩指针+长度(栈上) | 直接在栈上存所有元素 |
| 我能改数据吗? | 不能,元素是 const | 能,有 operator\[\] |
| 我有所有权吗? | 没有,全靠底层临时数组 | 有,数据是我的私有财产 |
| 我能拷贝数据吗? | 拷贝只是指针别名 | 拷贝是真拷贝,元素全复制一遍 |
直接上代码看看:
c++
// initializer_list 不能这样用
std::initializer_list<int> il = {1,2,3};
// il[1] = 5; // 编译错误
// array 可以
std::array<int, 3> arr = {1,2,3};
arr[1] = 5; // 完美,arr 变成 {1,5,3}它们的核心差异在于构造函数:
- array 的初始化必须知道大小,且大小是模板参数的一部分。
- initializer_list 的大小是运行时的,可以任意。
这时候爱发问的小明要问了:那 std::array 有 initializer_list 构造函数吗?
答案是没有!
因为 std::array 是一个聚合类,它的大小是编译期决定的。
它使用的是聚合初始化,而不是 initializer_list 构造。
自定义类型与 initializer_list
1. 构造函数重载优先级
虽然之前我们讨论过了,但这里还是要提一嘴:
- 如果有 initializer_list 构造函数,且花括号里的所有元素都能转换成 initializer_list 的元素类型,铁定调它。
- 如果元素类型转换失败,编译错误,不会退而求其次去找别的构造函数。
- 唯一的例外:空花括号 {}。因为实在没东西可转,它会去调用默认构造函数(如果没有默认构造,才可能考虑带默认参数的 initializer_list 构造)。
2. 多个 initializer_list 参数
假设我们要这样写:
c++
class Foo
{
public:
Foo(std::initializer_list<int> a, std::initializer_list<double> b);
};如果允许两个连续的 initializer_list 参数,那么:
c++
Foo f{1, 2, 3, 4.5, 6.7};编译器会一脸懵逼:第一个 {} 到哪里结束?是 {1,2} 然后 {3,4.5,6.7}?还是 {1} 然后 {2,3,4.5,6.7}?
所有 initializer_list 参数最好出现在函数参数列表的最后一个位置(或者唯一位置)。
要是实在想这么写,那就加两花括号:
c++
Foo f{ {1, 2, 3}, {4.5, 6.7} };让编译器知道要在哪结束。
3. 手写一个迷你 MyVector 类
我们来实现一个极简的动态数组,重点在于如何正确处理 initializer_list 构造函数,以及拷贝控制。
c++
template<typename T>
class MyVector
{
public:
// 默认构造函数
MyVector() : _data(nullptr), _size(0), _capacity(0)
{
std::cout << "默认构造" << std::endl;
}
// 列表初始化构造函数
MyVector(std::initializer_list<T> il)
{
std::cout << "initializer_list 构造" << std::endl;
_size = _capacity = il.size();
_data = new T[_size];
std::copy(il.begin(), il.end(), _data); // 深拷贝数据
}
// 拷贝构造函数
MyVector(const MyVector& other)
{
std::cout << "拷贝构造" << std::endl;
_size = other._size;
_capacity = other._capacity;
_data = new T[_capacity];
std::copy(other._data, other._data + _size, _data);
}
// 拷贝赋值运算符
MyVector& operator=(const MyVector& other)
{
std::cout << "拷贝赋值" << std::endl;
if (this != &other) {
delete[] _data;
_size = other._size;
_capacity = other._capacity;
_data = new T[_capacity];
std::copy(other._data, other._data + _size, _data);
}
return *this;
}
// initializer_list 赋值运算符
MyVector& operator=(std::initializer_list<T> il)
{
std::cout << "initializer_list 赋值" << std::endl;
delete[] _data; // 释放旧内存
_size = _capacity = il.size();
_data = new T[_size];
std::copy(il.begin(), il.end(), _data);
return *this;
}
// 析构函数
~MyVector()
{
delete[] _data;
}
// 一些辅助函数
size_t size() const { return _size; }
const T* begin() const { return _data; }
const T* end() const { return _data + _size; }
void print() const
{
std::cout << "[ ";
for (size_t i = 0; i < _size; ++i) std::cout << _data[i] << " ";
std::cout << "]" << std::endl;
}
private:
T* _data;
size_t _size;
size_t _capacity;
};测试代码:
c++
int main()
{
MyVector<int> v1{ 1, 2, 3 }; // 调列表构造
v1.print(); // [ 1 2 3 ]
MyVector<int> v2 = { 4, 5, 6, 7 }; // 同样列表构造
v2.print(); // [ 4 5 6 7 ]
v2 = { 10, 20 }; // 调 initializer_list 赋值
v2.print(); // [ 10 20 ],且旧数据被清除了
// 拷贝
MyVector<int> v4 = v1; // 拷贝构造
v4.print(); // [ 1 2 3 ]
v4 = v2; // 拷贝赋值
v4.print(); // [ 10 20 ]
return 0;
}解释:
- 深拷贝是必须的:在列表构造函数和赋值运算符中,我们没有直接保存传入的 initializer_list 的指针,而是用 new 分配了新内存并拷贝了数据。因为 initializer_list 底层数组是临时的,拷贝它必须深拷贝。
- 先释放再分配:赋值运算符必须先释放旧内存,再根据新列表分配,否则会内存泄漏。
- 异常安全? 我们这个简易版没考虑 new 失败的情况,实际上应该使用 RAII 和 try-catch 保证安全。
性能考量
1. 与 push_back 循环对比
既然 initializer_list 是轻量级观察者,那用它构造容器肯定比循环 push_back 快?
那么是真的快吗?
我们分两种情况来讨论:
情况一:vector<int> v = {1,2,3} vs push_back 循环
表面看:
- 列表初始化:一行搞定,编译器直接分配恰好大小的内存。
- push_back:可能触发多次扩容和拷贝。
实际情况:
c++
// 场景1:列表初始化
std::vector<int> v1 = {1, 2, 3, 4, 5};
// 场景2:循环 push_back
std::vector<int> v2;
v2.reserve(5); // 先预留空间
v2.push_back(1);
v2.push_back(2);
v2.push_back(3);
v2.push_back(4);
v2.push_back(5);以 int 这种平凡类型为例:
- 列表初始化:编译器在构造时一次性分配恰好5个 int 的内存,然后从临时数组拷贝过来。一次内存分配,5次 int 拷贝。
- 带 reserve 的 push_back:一次内存分配,5次 int 拷贝。
- 所以对于平凡类型,两者性能差不多,列表初始化的优势在于代码简洁。
但是,如果不带 reserve:
- push_back 循环可能触发多次扩容,导致多次内存分配和元素移动,这时候列表初始化胜出。
情况二:拷贝成本很高的时候
这是真正的性能分水岭。
看这个例子:
c++
class HeavyObject
{
public:
HeavyObject() { std::cout << "默认构造" << std::endl; }
HeavyObject(const HeavyObject&) { std::cout << "拷贝构造(贵)" << std::endl; }
HeavyObject(HeavyObject&&) noexcept { std::cout << "移动构造(便宜)" << std::endl; }
// 假设它持有一大块内存或文件句柄
};
int main()
{
// 方式A:列表初始化
std::vector<HeavyObject> v1 = { HeavyObject(), HeavyObject(), HeavyObject() };
// 方式B:循环 emplace_back
std::vector<HeavyObject> v2;
v2.reserve(3);
v2.emplace_back();
v2.emplace_back();
v2.emplace_back();
}输出会是什么?
- 方式A:临时对象被拷贝到 initializer_list 底层数组(一次拷贝),然后 vector 构造时再从底层数组拷贝到堆内存(第二次拷贝),一共两次拷贝。
- 方式B:emplace_back 直接在堆上构造对象,零拷贝。
所以方式 A 会调用3次默认构造和3次拷贝构造,方式 B 只会调用3次默认构造。
如果 HeavyObject 禁止拷贝呢?
比如我们使用 std::unique_ptr:
c++
std::vector<std::unique_ptr<int>> v =
{
std::make_unique<int>(1),
std::make_unique<int>(2)
}; // 编译错误,因为 initializer_list 试图拷贝 unique_ptr(它不可拷贝)initializer_list 强制要求元素可拷贝,因为它底层就是拷贝过去的。
2. 移动语义的支持:为什么 initializer_list 不能移动?
答案藏在设计里:
initializer_list 的迭代器返回的是 const T&,元素是常量。
我们不能把常量对象移动走,移动操作需要修改源对象(将其置于空状态)。
c++
std::initializer_list<std::string> il = {"hello", "world"};
std::vector<std::string> v;
for (auto& s : il)
{
v.push_back(std::move(s)); // 看似移动,实则拷贝。因为 s 是 const string&
}编译器会悄悄选择拷贝构造函数,因为 std::move 把 const string& 转成了 const string&&,而移动构造函数接受的是 string&&(非 const),不匹配。
这么大的问题为什么不修复呢?
- initializer_list 设计之初是为了方便轻量级、可拷贝的字面量。
- 如果允许移动,那么多次使用同一个 initializer_list 会导致内容被掏空,语义混乱。
- 编译器优化:临时数组可能放在只读段,移动修改会导致段错误。
当然了,如果我们有一堆临时对象想放进 vector,又不想多次拷贝,可以这样:
c++
// 先放一个空 vector,然后用 insert 配合移动迭代器
std::vector<std::string> v;
v.reserve(3);
std::initializer_list<std::string> il = { "a", "b", "c" }; // 这里发生一次拷贝到临时数组
v.insert(v.end(),
std::make_move_iterator(const_cast<std::string*>(il.begin())),
std::make_move_iterator(const_cast<std::string*>(il.end())));但是我不推荐这么用,const_cast 去掉常量性容易导致未定义行为。
所以我们还是老老实实 emplace_back 吧。
结尾
好了,我们就用3句话为这篇文章画上个完美的句号吧。
第一句:这玩意到底是个啥?
说白了,它就是个天天拿两根破签子在那举着的临时工。
两根破签子:一根指着头,一根指着尾。
我们要是让它搬个小板凳坐在那数人头,没有任何问题。
但让它去工地搬砖,哎呦,那可要老命了。
第二句:花括号会劫持我们的构造函数
编译器只要看见花括号,哪怕里面装的是屎,它也得先去找那个带 initializer_list 参数的坑位蹲一下。
第三句:免费的往往最贵
便利有价,拷贝收费。
小打小闹随便用,核心循环请清醒。
就3句话,说到做到( ◜◡‾),完~