
大家好,在这篇文章中我将继续介绍我的毕业设计项目 S.A.A.U.S.O ------ 一个轻量级 Python 虚拟机。
项目 GitHub 链接:github.com/WU-SUNFLOWE...(如果你喜欢,请顺手帮我点一个⭐star~)
在上一篇文章中,我主要介绍了实现一个 Python 虚拟机之前需要理解的理论基础,包括 PVM 的栈机执行模型、函数与栈帧、闭包、对象系统、异常机制和模块机制等内容。
这一篇文章继续向后推进,开始进入系统设计层面。
如果说上一篇文章回答的是:
一个 Python 虚拟机需要支持哪些核心机制?
那么本文要回答的就是:
当我们真的要实现一个轻量级 Python 虚拟机时,整个系统应该如何组织?各个核心模块应该如何分层?底层内存管理、对象系统、执行系统和嵌入接口之间应该如何协作?
本文对应我的毕业论文第 3 章,重点介绍 S.A.A.U.S.O 的总体设计与技术路线。
1. 本文到底要解决什么问题?
在正式进入架构设计之前,我先说明一下本文的目标。
实现一个虚拟机,最容易低估的地方并不是某一条字节码指令怎么跑,也不是某一个对象类型怎么表示,而是:多个子系统之间如何稳定、清晰、可维护地协作。
一个 PVM 后端至少会涉及这些能力:
- 托管堆内存;
- 自动垃圾回收;
- C++ 本地代码中的对象引用安全;
- Python 对象和类型系统;
- 属性查找与方法调用;
- 内建函数;
- 模块加载;
- 字节码解释执行;
- 异常状态维护;
- 面向宿主程序的嵌入接口。
如果所有逻辑都塞进解释器主循环里,短期内可能能跑出几个 demo,但系统很快会变得难以理解、难以扩展,也难以定位问题。
所以,在后续真正介绍 S.A.A.U.S.O 的具体实现之前,我在本文中要首先讲清楚一件事:设计系统的整体结构和技术路线。
具体来说,本文主要回答四个工程问题:
- 系统整体架构如何划分,才能提供较好的可读性与可维护性?
- 如何通过运行时容器统一管理各核心模块的状态?
- 整个系统应该按照什么顺序逐层搭建?
- 每个核心模块应该采用什么样的技术路线?
2. 设计目标:不是复刻 CPython,而是做一个轻量、可嵌入、可理解的 PVM
S.A.A.U.S.O 的目标不是替代 CPython,也不是完整复刻 CPython 的全部内部机制。
这个项目更关注的是:在教学演示、轻量嵌入和定制化开发场景下,能否实现一个结构清晰、规模可控、真实可运行的 Python 虚拟机后端。
因此,系统设计主要围绕三个目标展开。
2.1 兼容 CPython 3.12 字节码模型中的核心执行路径
首先,系统需要兼容 CPython 3.12 字节码模型中的核心执行路径,使常见的 Python 核心功能能够被正确解释执行。
这里的"兼容"并不是逐项复刻完整的 CPython 实现。
CPython 是一个成熟的工业级实现,包含大量历史兼容逻辑、性能优化逻辑、平台适配逻辑和生态支持能力。如果直接以完整 CPython 为目标,对于一个轻量级教学与定制化项目来说,范围会过大。
因此,S.A.A.U.S.O 的策略是:优先支持最有代表性的语言语义和运行时机制,例如:
- 基本表达式执行;
- 变量读写;
- 控制流;
- 函数创建与调用;
- 闭包;
- 基本内建类型;
- 类与对象;
- 异常;
- 模块导入;
- 内建函数;
- 嵌入式调用。
也就是说,这里的兼容目标更接近于"兼容核心执行模型",而不是"完整兼容 CPython 生态"。
2.2 保持良好的可嵌入性
第二个目标是可嵌入性。
这个系统不仅要能作为独立解释执行系统运行 Python 脚本,还应该能够通过清晰的对外接口嵌入到宿主 C++ 程序中,作为一个脚本引擎使用。
这意味着系统不能只暴露解释器内部接口。
如果宿主程序需要直接接触内部对象布局、GC 状态、解释器栈帧或模块缓存,那么这个虚拟机就很难被安全地嵌入和维护。
所以,在架构设计时,我专门预留了嵌入接口层。它的职责是把 VM 内核中的能力包装成宿主程序更容易理解、更稳定的抽象,同时尽量隔离宿主程序和 VM 内部逻辑。
2.3 工程组织上尽量可读、可维护
第三个目标是工程结构上的可读性和可维护性。
对这个项目来说,真正困难的地方不是让某个单独模块跑起来,而是让多个模块之间形成稳定、清晰、可解释的协作关系。
因此,系统设计时需要避免把 VM 的全部能力都集中耦合进解释器内部。
更合理的做法是把对象系统、执行系统、运行时语义、模块系统和内存管理拆成相对独立、但又能协同工作的层次结构。
基于这三个目标,S.A.A.U.S.O 的总体设计思路可以概括为:
内核与嵌入接口解耦,子系统之间低耦合高内聚,系统各层之间依赖关系明确。
3. 总体架构:VM 内核层 + 嵌入接口层
从整体结构上看,S.A.A.U.S.O 可以分成两大部分:
- VM 内核层
- 嵌入接口层
VM 内核负责封装 PVM 的基础设施与核心能力,包括内存管理、对象系统、执行系统、模块系统和字节码解释器等。
嵌入接口层则负责把 VM 内核中的能力,以相对稳定、易用的形式暴露给宿主 C++ 应用。
也就是说,VM 内核更关注"虚拟机内部如何运作",嵌入接口层更关注"外部程序如何安全、方便地使用这个虚拟机"。
4. VM 内核内部的自底向上分层
如果继续细分 VM 内核,并按照自底向上的单向依赖方向观察,可以把它概括为五层:
- 工具基础层;
- 虚拟机堆层;
- 句柄机制层;
- 对象系统层;
- 执行层。
外侧再接一个嵌入接口层。
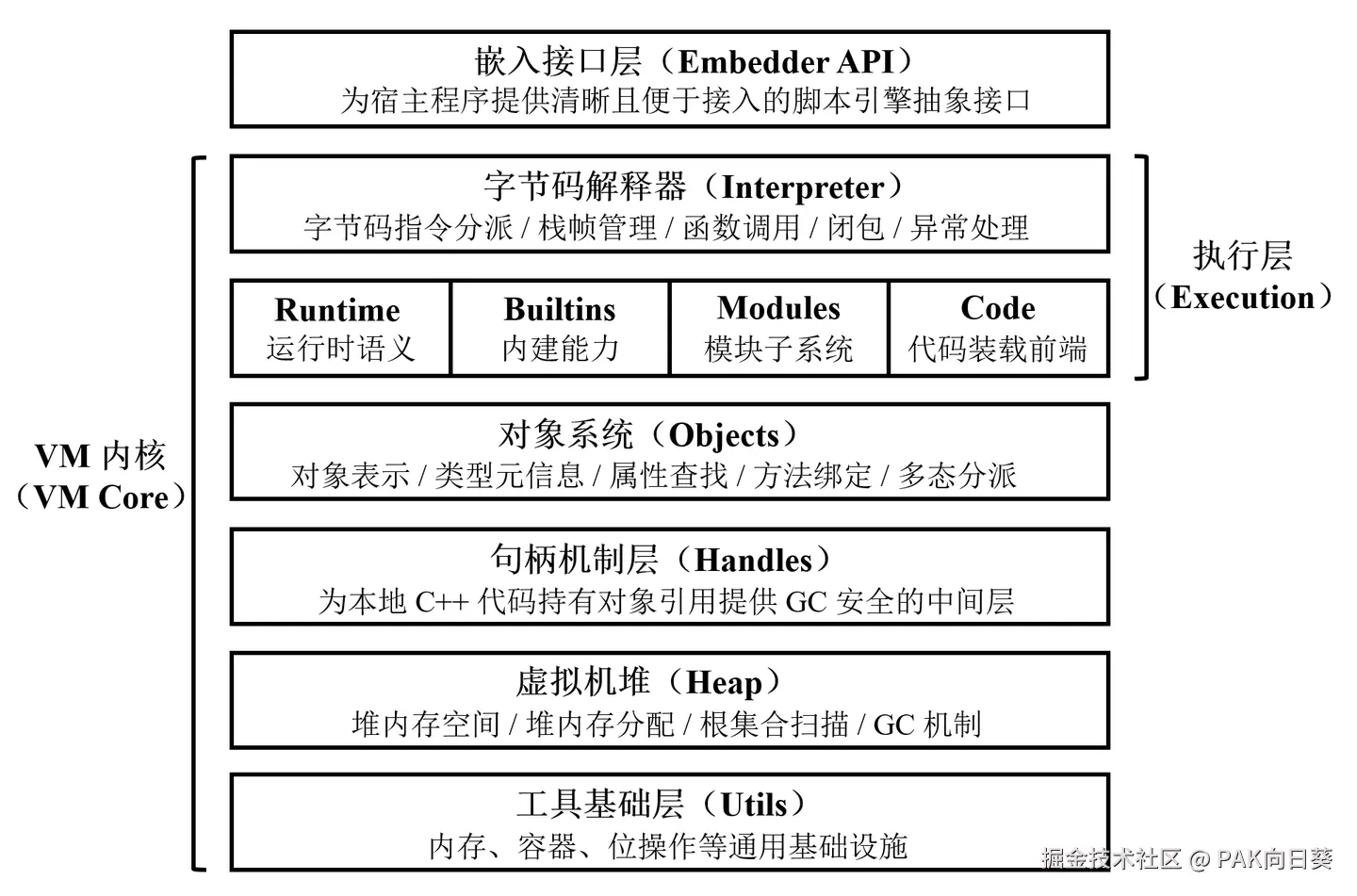
S.A.A.U.S.O 虚拟机的整体架构
这个分层关系非常重要。它不只是目录组织方式,也决定了系统的开发顺序和依赖方向。
4.1 工具基础层:提供与 VM 业务无关的基础设施
工具基础层主要提供与 VM 业务无关的通用工具与基础设施。
它本身不承载 Python 语义,也不直接关心对象系统、解释器或模块导入,而是为上层模块提供基础支持。
这类模块通常包括一些通用数据结构、辅助类、宏定义、基础配置、不可拷贝对象封装等工具性代码。
虽然这一层看起来不"高级",但它是整个系统工程化组织的底座。
4.2 虚拟机堆层:托管对象分配与 GC
虚拟机堆层负责提供 VM 内部使用的托管堆内存空间,并承担自动化内存管理任务。
Python 是动态语言,对象会在运行过程中频繁创建和销毁。对于一个 PVM 来说,如果没有自己的对象分配与回收机制,很难形成完整的运行时系统。
因此,堆层需要解决几个基础问题:
- Python 对象在哪里分配?
- 堆对象如何组织?
- 哪些对象仍然存活?
- 哪些对象可以被回收?
- 如果 GC 会移动对象,系统如何更新引用?
在 S.A.A.U.S.O 中,虚拟机堆层是更上层对象系统和执行系统的基础。
4.3 句柄机制层:让 C++ 本地代码安全持有对象引用
句柄机制层负责提供对象句柄机制。
为什么需要这一层?
因为在虚拟机内部,不只有 Python 代码会持有 Python 对象引用,C++ 本地代码同样会持有堆上对象的引用。
例如:
- 内建函数的 C++ 实现可能会临时保存 Python 对象;
- 解释器执行字节码时可能会临时保存对象;
- 模块系统加载代码时可能会创建和传递对象;
- 对象系统内部进行属性查找和方法绑定时也会操作对象。
如果 GC 发生时不知道这些 C++ 本地引用的存在,就可能把仍然被 C++ 代码使用的对象误回收。
更进一步,如果 GC 算法会移动存活对象在堆中的位置,那么 C++ 中原本保存的裸指针就可能变成悬空指针。
所以,句柄机制层的核心任务是:
在 GC 场景下,让 C++ 本地代码能够安全持有堆上对象引用。
它本质上是 VM 内部 C++ 代码和托管堆之间的一层安全隔离。
4.4 对象系统层:统一表示 Python 对象与 Python 类型
对象系统层负责定义 Python 对象和 Python 类型的统一表示模型,并在这个模型之上实现对象行为派发、属性查找、方法绑定等面向对象核心功能。
在 Python 中,万物皆对象。
整数、字符串、列表、字典、函数、模块、类、实例,最终都需要被虚拟机统一管理。
因此,对象系统层需要解决:
- Python 对象实例如何表示?
- Python 类型如何表示?
- 内建类型如何初始化?
- 实例属性和类属性如何查找?
- 方法绑定如何发生?
- 继承和 MRO 如何参与属性解析?
- 对象的核心行为如何高效分派?
如果说虚拟机堆层解决"对象放在哪里",那么对象系统层解决的就是"对象是什么,以及对象如何表现出 Python 语义"。
4.5 执行层:组织运行时语义并驱动脚本执行
执行层封装运行时语义、内建能力、模块子系统等高层 Python 语言行为,并负责驱动 Python 脚本的实际解释执行。
这一层并不等同于"字节码解释器"。
解释器当然属于执行层的重要组成部分,但执行层还包括很多解释器之外的基础设施,例如:
- 统一执行入口;
- 运行时语义接口;
- 内建函数和内建命名空间;
- 模块系统;
- 代码装载前端;
- 字节码解释器;
- 调用栈管理;
- 异常控制流。
这样的设计可以避免解释器独自承担全部执行职责,使解释器更专注于逐条解释执行字节码指令。
5. 为什么必须按这个顺序开发?
这个分层架构不仅用于解释系统结构,也直接决定了实际开发顺序。
开发一个 PVM 系统时,不能一上来就写解释器主循环。
原因很简单:解释器需要依赖大量底层能力。
例如:
- 执行 LOAD_CONST 时,需要能表示和分配对象;
- 执行 BINARY_OP 时,需要对象系统提供运算行为;
- 执行函数调用时,需要函数对象、栈帧、调用协议;
- 执行 IMPORT_NAME 时,需要模块系统;
- 调用 print 时,需要内建函数机制;
- 创建大量临时对象时,需要内存管理和 GC;
- C++ 代码临时持有对象时,需要句柄机制保护引用安全。
因此,实际开发顺序应该是:
markdown
工具基础设施
↓
虚拟机堆与 GC
↓
句柄机制
↓
对象系统
↓
运行时语义、内建能力、模块系统、代码装载
↓
字节码解释器
↓
嵌入接口层也就是说,系统中的高层功能必须建立在先前各层提供的基础之上。
6. 核心运行时容器:Isolate
有了分层架构之后,还需要解决另一个问题:
真实的 PVM 系统中,各个子系统的运行时状态应该放在哪里?
虚拟机运行过程中会产生大量状态,例如:
- 堆的内存分配状态;
- GC 状态;
- 句柄槽位状态;
- 内建类型对象;
- 内建命名空间;
- 模块缓存;
- 字节码解释器状态;
- 当前调用栈;
- 当前异常状态;
- 运行时上下文信息。
这些状态如果分散在全局变量或各个模块内部,系统会很快变得难以管理,也不利于支持多个虚拟机实例。
为了解决这个问题,S.A.A.U.S.O 参考了 V8 等工业级虚拟机的设计经验,引入了一个核心运行时容器:Isolate。
在这个系统中,Isolate 不是某个单一功能模块,而是一个完整的 Python 运行时上下文容器,也可以理解为一个独立的虚拟机实例。
虚拟机堆、字节码解释器、模块系统等子系统及其运行时状态,以及异常状态等运行时上下文信息,都会被统一收敛到单个 Isolate 之中管理。
可以简单理解为:
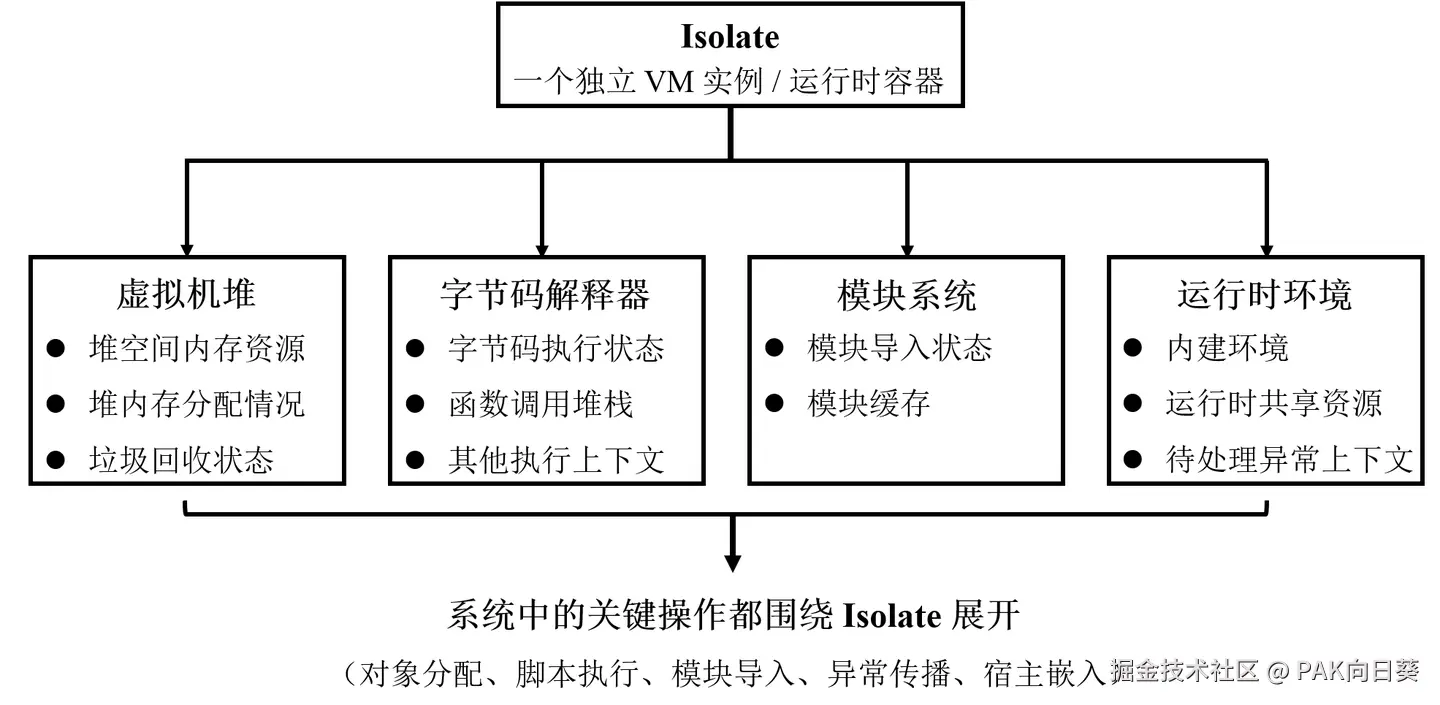
S.A.A.U.S.O 虚拟机中的 Isolate 容器
这样设计的好处是,各层能力虽然在工程结构上分层,但在运行时并不是彼此孤立的,而是共同挂接到同一个运行时上下文中。
从宿主程序角度看,一个 Isolate 就代表一个相对独立的虚拟机实例。后续嵌入接口层也会复用这个概念,把它作为对外暴露的重要抽象之一。
7. 虚拟机堆层的技术路线
接下来进入各核心层的技术路线。
首先是虚拟机堆层。
在 Python 程序运行过程中,对象会被频繁创建。对于一个 PVM 后端来说,系统必须有一套自己的托管堆机制,用于统一管理 Python 对象的生命周期。
虚拟机堆层需要解决三个核心问题:
- 如何分配堆对象;
- 如何判断对象是否仍然存活;
- 如何回收不再存活的对象。
S.A.A.U.S.O 在总体技术路线上采用追踪式 GC 的思路。
追踪式 GC 的基本思想是:从一组根对象(被称为"根集合")出发,沿着对象之间的引用关系遍历对象图。凡是能从根集合出发访问到的对象,就认为是存活对象;无法被访问到的对象,则认为是垃圾,可以回收。
为进一步说明这一算法思想,下图给出了一个具体的例子。如图所示,在追踪式 GC 算法执行时,由于对象 E、H 和 I 既不属于根集合,同时从根集合出发亦不能遍历到它们,因此它们是不可达的垃圾对象,会被回收。
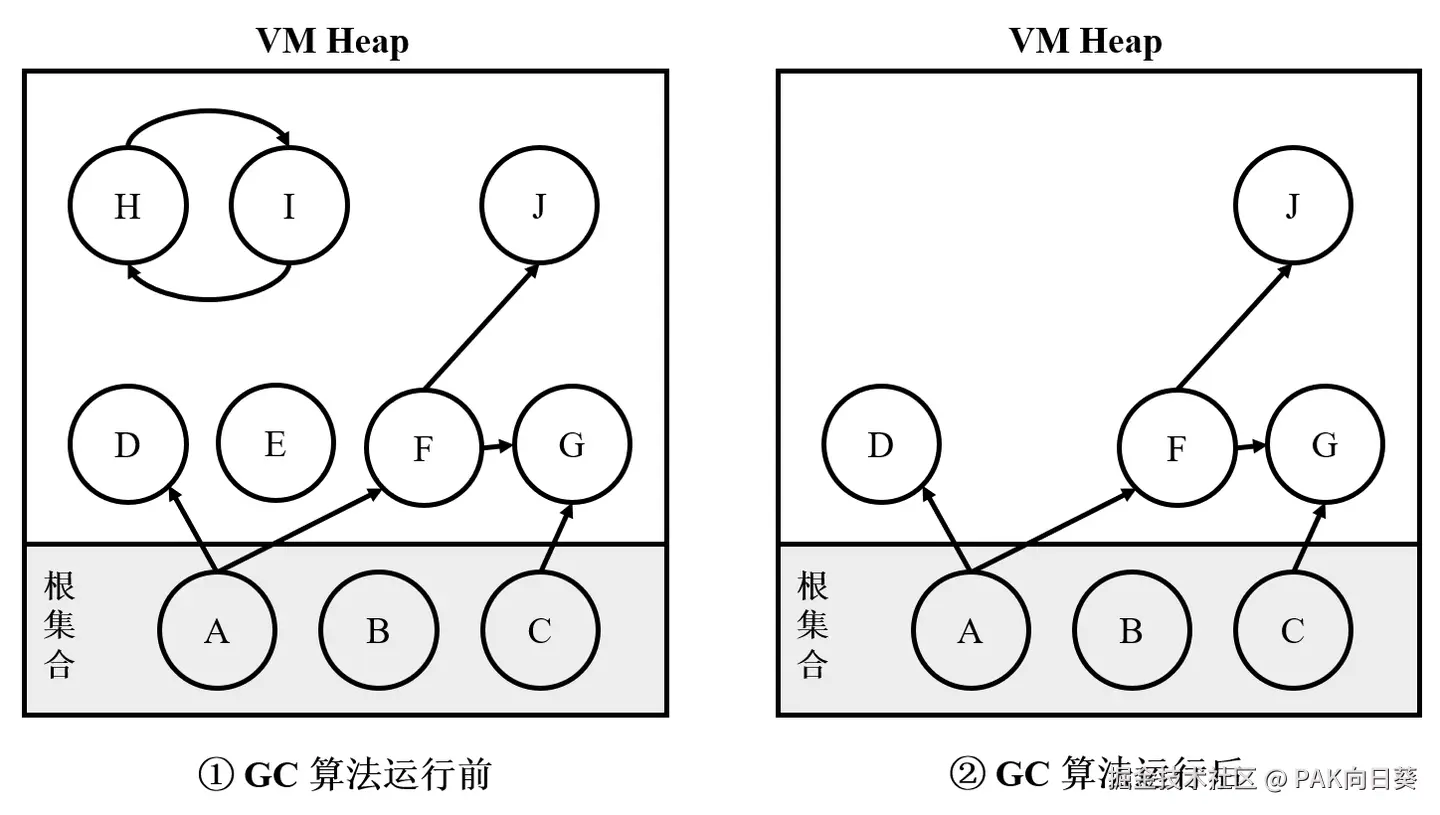
追踪式 GC 中对象可达性判定示例
在这个模型下,实现一个可实际运行的 GC 机制,重点不只是"写一个回收算法",而是要解决三个更工程化的问题:
- 具体选择什么 GC 算法;
- 根集合如何组织;
- 对象图如何遍历。
其中,根集合可能包括解释器调用栈中的对象引用、全局运行时状态中的对象引用、本地 C++ 代码通过句柄保存的对象引用等。
这也是为什么虚拟机堆层之后需要引入句柄机制层:GC 不仅要知道 Python 层面的引用,也必须知道 VM 内部 C++ 代码中仍然有效的对象引用。
8. 句柄机制层的技术路线
在建立虚拟机堆和 GC 机制后,系统需要立刻解决第二个基础问题:
VM 内部的 C++ 本地代码如何安全地持有堆上对象引用?
这个问题有两个方面。
第一,C++ 本地代码持有的对象引用也必须被 GC 看见。
例如,一个内建函数正在执行,它临时拿到了某个 Python 对象。如果此时触发 GC,而 GC 不知道这个 C++ 局部变量里保存着对象引用,就可能把这个对象误判为不可达。
第二,如果 GC 会移动对象,那么 C++ 本地代码保存的裸指针可能失效。
假设对象原本位于地址 A,GC 后被移动到地址 B。如果 C++ 局部变量里还保存着地址 A,那么后续继续访问它就会出错。
因此,S.A.A.U.S.O 引入对象句柄机制,把"C++ 代码直接持有堆对象裸指针"转化为"C++ 代码持有一个可被 VM 管理的句柄"。
句柄背后可以理解为一个受 VM 管理的槽位。C++ 代码通过句柄访问对象,而 GC 可以遍历这些槽位,把它们作为根集合的一部分。
如果对象被移动,GC 也可以更新槽位中的对象地址。这样,C++ 代码通过句柄再次访问对象时,拿到的就是更新后的最新地址。
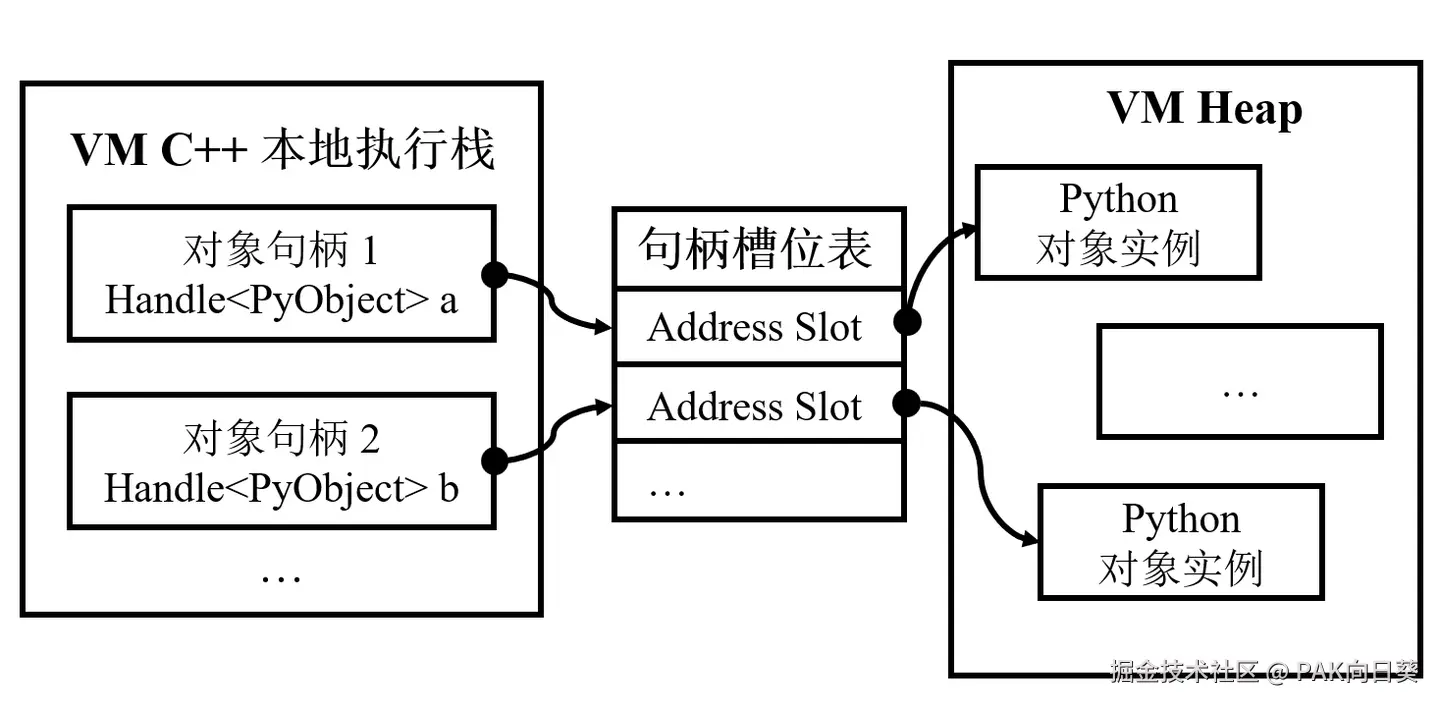
句柄机制与槽位模型示意图
这一层的价值在于,它把散落在 C++ 调用栈中的零碎对象引用,集中转换成 VM 可管理、可遍历、可更新的一组槽位。
因此,句柄机制层可以看作整个系统中本地代码引用安全的守门员。
9. 对象系统层的技术路线
在虚拟机堆和句柄机制都具备之后,系统才能进一步建立统一对象系统。
对象系统层的核心目标,是在 C++ 实现中建模 Python 的"万物皆对象"和动态面向对象语义。
这里有一个很重要的设计思路:
对象实例数据与类型行为分离。
也就是说,Python 对象实例本身保存对象状态,而类型相关的元信息和行为描述则由另一套结构统一承担。
在 S.A.A.U.S.O 中,所有 Python 对象实例统一纳入 PyObject 体系,而类型元信息则由 Klass 体系统一描述。
可以粗略理解为:
PyObject:描述对象实例本身
Klass:描述对象对应类型的行为与元信息这种设计的好处是,对象实例和类型行为之间形成清晰分工。
对象系统层需要支持的能力主要包括:
- 基础内建类型表示;
- 用户自定义类;
- 实例属性字典;
- 类属性字典;
- 属性查找;
- 方法绑定;
- 继承关系;
- MRO;
- 对象核心行为分派。
其中,属性查找和方法绑定用于支持 Python 语言层面的动态行为;而对象核心行为分派则用于支持 VM 内部更高效地执行运算、比较、迭代等常用操作。
这对应上一篇文章中提到的"双层多态"思想:
第一层是面向 Python 语言语义的动态属性查找与方法绑定。它保证用户在 Python 代码中观察到的行为符合语言语义。
第二层是面向 VM 内部执行效率的核心行为分派。它避免所有底层操作都退化为昂贵的字典查找和动态绑定。
例如,对于整数加法,虚拟机不应该每次都完整走一遍 int.add 的动态属性查找流程,而应该有更直接的内部调度路径。
因此,对象系统层既要保持 Python 语言的动态性,又要为虚拟机内部提供较高效的对象行为分派机制。
10. 执行层的技术路线
在完成虚拟机堆、句柄机制和对象系统之后,系统才真正开始具备驱动 Python 程序运行的基础。
不过,执行层并不只是字节码解释器。
如果把所有执行相关逻辑都写进解释器主循环,解释器会变得非常臃肿。例如:
- 名称查找逻辑;
- 属性查找逻辑;
- 模块导入逻辑;
- 内建函数注册;
- 用户自定义类型创建;
- 脚本加载;
- 函数调用封装;
- 异常传播辅助逻辑。
这些内容如果全部耦合在解释器里,后续维护会非常困难。
因此,S.A.A.U.S.O 的执行层被拆成几类基础设施。
10.1 统一执行入口
系统并不把脚本执行直接暴露为解释器底层接口,而是通过统一执行入口封装主脚本执行、模块执行和函数调用。
这样做有两个好处。
第一,可以避免其他模块直接耦合解释器内部实现。
第二,可以统一不同执行场景下的接口约定。
例如,执行一个主脚本、执行一个模块体、调用一个 Python 函数,本质上都需要进入 VM 的执行系统。如果每个模块都直接调用解释器底层接口,系统很容易出现重复逻辑和不一致行为。
10.2 运行时语义能力
有些高层语义并不适合直接塞进解释器主循环。
例如:
- 类属性查找;
- 用户自定义类型创建;
- 方法绑定;
- 某些运行时对象操作。
这些逻辑更适合由运行时语义子系统统一承担,并对外暴露为一组 Runtime 系列接口。
这样,解释器在执行字节码时,只需要在合适的位置调用这些运行时语义接口,而不需要自己承担所有高层语言规则。
解释器因此可以更专注于:
- 字节码调度;
- 操作数栈维护;
- 调用堆栈管理;
- 异常控制流处理。
10.3 内建能力子系统
一个 PVM 即使已经拥有对象系统和解释器,如果没有基本内建运行环境,仍然无法真正可用。
例如,用户代码中非常常见的:
python
print("hello")
len([1, 2, 3])
isinstance(obj, MyClass)这些都依赖内建能力。
因此,系统在执行层中专门组织了内建能力子系统,用于承载内建函数和内建命名空间。
在现阶段设计中,Isolate 容器会持有一个 builtins 字典,用于表示内建命名空间。全体内建函数的 C++ 实现,会在 Isolate 初始化时被包装成可调用对象并注入进 builtins 字典。
后续解释器执行用户代码并需要调用内建函数时,就会按照名称查找规则访问这个字典。
10.4 模块系统
模块导入虽然由解释器通过 IMPORT_NAME、IMPORT_FROM 等字节码指令触发,但它背后并不是一两条指令就能完成的简单逻辑。
一个完整的模块导入过程通常涉及:
- 导入请求触发;
- 模块名称解析;
- 缓存检查;
- 模块定位;
- 模块装载;
- 模块代码执行;
- 模块缓存回写;
- 父子模块绑定;
- 返回目标模块对象。
因此,S.A.A.U.S.O 将模块系统设计为执行层中的独立子系统,而不是把名称解析、模块定位、模块加载和缓存维护等逻辑耦合进解释器主循环。
换句话说,解释器只负责在执行到导入相关字节码时触发模块导入,而真正复杂的模块导入流程由模块系统承担。
这样的设计更符合单一职责原则,也更方便后续维护和扩展。
10.5 代码装载前端
这个课题的重点是 PVM 后端,而不是重新实现完整 Python 编译器前端。
因此,S.A.A.U.S.O 在源码编译能力上选择直接封装 CPython 的编译前端。
这是一种工程取舍:项目把重点放在字节码解释执行、对象系统、运行时系统和嵌入能力上,而不是把大量时间投入到 Python 语法解析和编译器前端实现中。
同时,系统也支持直接装载 CPython 编译器前端生成的 .pyc 代码对象二进制文件,从而为脚本执行提供源码和字节码两类输入入口。
也就是说,系统既可以通过源码入口运行 Python 脚本,也可以通过字节码入口执行已经生成好的代码对象。
10.6 字节码解释器
在上述基础设施准备好之后,才真正轮到字节码解释器上场。
解释器的职责是驱动 Python 程序实际执行,包括:
- 读取当前字节码指令;
- 根据操作码分派执行逻辑;
- 操作操作数栈;
- 读写局部变量和全局变量;
- 发起函数调用;
- 触发模块导入;
- 处理异常控制流;
- 维护调用栈和栈帧。
由于执行层中已经提前拆出了运行时语义、内建能力、模块系统和代码装载等基础设施,解释器就不需要独自承担全部执行职责。
这种高内聚、低耦合的工程形态,有利于执行层系统的可维护性和可扩展性。
11. 嵌入接口层的技术路线
在完成前面各层的开发与组合后,VM 内核已经可以作为独立脚本执行系统运行。
在此基础上,S.A.A.U.S.O 在最外层设计了面向宿主方的嵌入接口层,为宿主 C++ 程序提供清晰且便于接入的脚本引擎抽象。
这一层的整体思路参考了 V8 的设计经验:对外暴露宿主程序能够直接理解的高级抽象概念,对内连接 VM 内核中的执行层和对象系统。
这样设计的好处是:
- 宿主程序不需要理解 VM 内部复杂的对象布局;
- 宿主程序不需要直接接触 GC 状态;
- 宿主程序不需要直接操作解释器内部细节;
- VM 内核中的运行时状态不会轻易被宿主逻辑意外破坏;
- 对外接口可以保持相对稳定,而内部实现可以继续演进。
不过,S.A.A.U.S.O 并没有直接照搬 V8 庞大而复杂的接口体系。
它只是围绕轻量级 PVM 的目标,对 V8 的设计思想进行简化和迁移,形成一套最小可用的轻量级 API 集合。
在这个接口体系中,比较核心的概念包括:
- Isolate:表示一个独立的虚拟机实例;
- Context:表示脚本运行所依赖的上下文环境;
- Script:表示可编译、可执行的脚本;
- Value:表示宿主侧可感知的脚本值;
- Function:表示可从宿主侧调用或注册的函数抽象;
- TryCatch:用于宿主侧观察脚本执行中的异常。
宿主程序通常按照如下流程使用:
javascript
创建 Isolate
↓
创建 Context
↓
编译 Script
↓
执行 Script
↓
读取 Value / 调用 Function / 捕获异常这样,宿主方只需要围绕这些高级抽象组织业务逻辑,而不需要直接触碰 VM 内核中的对象系统、解释器栈帧或 GC 细节。
最后给出一个 S.A.A.U.S.O 项目源码仓库中,使用嵌入接口执行简单 Python 脚本的具体例子。感兴趣的读者可以先自行看一下。
其中出现的Local、MaybeLocal、HandleScope、Isolate::Scope等次要概念,这里先不展开介绍。
C++
// Copyright 2026 the S.A.A.U.S.O project authors. All rights reserved.
// Use of this source code is governed by a GNU-style license that can be
// found in the LICENSE file.
#include "saauso.h"
int main() {
// 初始化 S.A.A.U.S.O 库
saauso::Saauso::Initialize();
// 创建虚拟机实例
saauso::Isolate* isolate = saauso::Isolate::New();
{
// 创建一个与 isolate 绑定的 scope,之后会自动进入 isolate 实例
saauso::Isolate::Scope isolate_scope(isolate);
// 创建一个 HandleScope
saauso::HandleScope scope(isolate);
// 创建一个默认的全局环境
saauso::Local<saauso::Context> context = saauso::Context::New(isolate);
// 创建并编译一段Python脚本
saauso::MaybeLocal<saauso::Script> maybe_script = saauso::Script::Compile(
isolate, saauso::String::New(isolate, "print('Hello World')\n"));
// 运行编译好的Python脚本
maybe_script.ToLocalChecked()->Run(context);
// 此处 isolate_scope 会被析构,然后 isolate 会自动退出
}
// 销毁虚拟机实例
isolate->Dispose();
// 关闭 S.A.A.U.S.O 库
saauso::Saauso::Dispose();
return 0;
}12. 这个架构的核心价值
回过头看,S.A.A.U.S.O 的总体架构其实围绕一个核心问题展开:
如何在轻量级目标下,仍然尽量保持虚拟机系统的结构清晰和可扩展性?
最终形成的设计可以总结为三点。
12.1 内核与嵌入接口解耦
VM 内核负责实际执行 Python 语义,嵌入接口负责向宿主程序提供稳定抽象。
这样,虚拟机内部可以继续演进,而宿主程序不必直接依赖内部实现细节。
12.2 子系统之间低耦合、高内聚
虚拟机堆负责内存管理,句柄机制负责本地引用安全,对象系统负责对象语义,执行层负责运行时行为和解释执行,嵌入接口负责对外抽象。
每一层都有明确职责,不把所有事情都堆给解释器。
12.3 各层依赖方向明确
系统按照自底向上的方式逐层构建:
vbnet
Heap / Handles / Objects 是基础
Execution 建立在它们之上
Embedder API 建立在完整 VM 内核之上这种依赖方向让整个系统更容易解释,也更容易调试和维护。
13. 小结
本文介绍了 S.A.A.U.S.O 这个轻量级 Python 虚拟机后端的总体架构设计与技术路线,从而回答了一个基础问题:如何把一个 PVM 后端组织成一个真实可运行、可维护、可扩展的系统。
我的虚拟机最终采用了如下设计:
- 整体分为 VM 内核层和嵌入接口层;
- VM 内核内部按照 Utils、Heap、Handles、Objects、Execution 自底向上组织;
- 使用 Isolate 作为核心运行时容器,统一管理虚拟机实例中的运行时状态;
- 虚拟机堆层负责对象分配和 GC;
- 句柄机制层解决 C++ 本地代码安全持有堆对象引用的问题;
- 对象系统层负责统一对象表示、类型行为、属性查找、方法绑定和核心行为分派;
- 执行层拆分出运行时语义、内建能力、模块系统、代码装载前端和字节码解释器;
- 嵌入接口层参考 V8 的设计思想,但进行轻量化简化,为宿主 C++ 程序提供最小可用的脚本引擎 API。
在下一篇文章中,我会具体介绍这些核心层是如何落地实现的,包括虚拟机堆、句柄机制、对象系统、执行层和嵌入接口层的关键实现细节。