4月16日,阿里巴巴通义实验室正式开源最新多模态智能体大模型Qwen3.6-35B-A3B,其轻量高效的核心特性一经发布,便迅速成为开源AI领域的焦点,引发行业广泛关注。
清微智能技术团队第一时间响应,依托自研可重构计算架构与全栈软件工具链,在24小时内完成该模型的适配、精度对齐与部署验证,实现"发布即适配、开箱即满血"。
Day0适配背后,是可重构计算架构的天然前瞻性,更体现了清微智能全栈软件工具链在应对复杂前沿大模型时的高效与从容。

01.
模型革新:
轻量高效
解读"小钢炮"核心优势
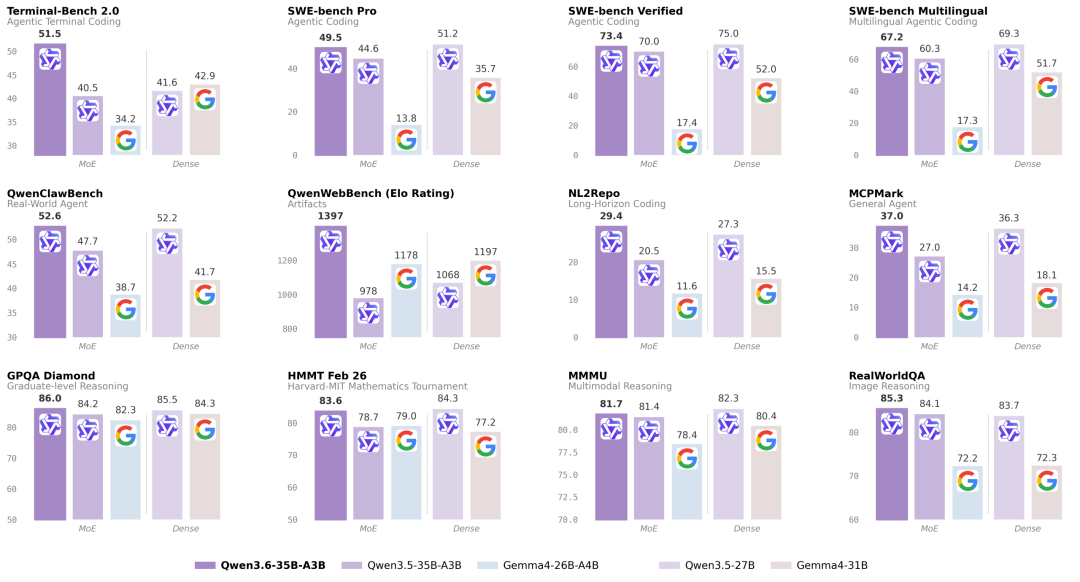
作为业内备受瞩目的"智能体小钢炮",Qwen3.6-35B-A3B在架构设计与应用场景上实现了重大突破。
极致的参数效能
模型采用稀疏混合专家(MoE)架构,在拥有350亿总参数量的情况下,实际激活参数仅为30亿,兼顾了超大规模与轻量化运行,实现了性能与成本的最优平衡。
卓越的智能体编程
(Agentic Coding)
在处理前端工作流与仓库级复杂代码推理时流畅度与精确度大幅提升,在SWE-bench Verified、Terminal-Bench 2.0等核心基准测试中,不仅超越前代模型,更优于部分同级稠密大模型,凸显出强劲的落地实用性。
首创思维保留
(Thinking Preservation)
这一创新机制可完整保留并复用历史会话中的推理轨迹,开启相关功能后,能大幅降低开发者迭代过程中的算力开销与调试成本,让多轮智能体任务执行更具连贯性与高效性。
强大的多模态感知
具备优异的视觉与语言综合处理能力,原生支持图像、文本等多模态输入,能够无缝接入OpenClaw、Qwen Code等各类第三方编程助手与智能体框架中,适配更多元的应用场景。
02.
软硬协同:
TX81驱动
释放大模型极致效能
针对Qwen3.6-35B-A3B轻量高效的MoE架构特性,清微智能TX81芯片展现出高度适配性。
在硬件层面,TX81充沛的算力与大容量显存带宽,为模型频繁的专家路由调度和长文本上下文推理提供坚实物理支撑,精准适配模型原生262144 tokens的超长上下文需求。
在软件层面,清微自研的AI编译框架与高性能算子库实现对该模型的深度解析与高效加速,用户无需进行繁琐的代码重构,即可实现业务代码平滑迁移。这种软硬协同的双擎驱动模式,让Qwen3.6-35B-A3B在TX81芯片上达成稳跑、快跑、省跑的三重优势,充分释放模型核心效能。
03.
繁荣生态:
智算赋能
共筑国产算力新底座
大模型时代的算力竞争,核心是生态效能的比拼,更是国产自主技术实力的彰显。
清微智能始终以降低前沿AI技术应用门槛为己任,此次完成Qwen3.6-35B-A3B的Day0适配,正是其拓宽软硬件生态朋友圈、赋能国产AI发展的生动实践。
当"可重构"遇上"MoE",我们看到的不仅是一次技术适配的成功,更是国产AI算力从"可用"迈向"好用"的关键一跃。未来,清微智能将以更开放的姿态拥抱开源社区,让每一次架构的"可重构",都成为算力底座向上生长的坚实阶梯。
往期推荐
|---|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 | "双子星"合璧:清微智能Day 0适配国产最强开源模型智谱GLM-5.1 |
| 2 | 携手智源 FlagOS 开源生态,清微智能基于Triton-TLE实现2.5倍性能提升! |
END