TL;DR
- 场景:机器学习入门者学习回归分析,华氏度转摄氏度、房价/销售额/贷款额度预测等回归场景
- 结论:线性回归通过最小二乘法或梯度下降优化损失函数,找到特征与目标值之间的最优线性关系
- 产出:掌握线性回归定义、损失函数、正规方程与梯度下降两种优化算法的原理与对比
版本矩阵
| 功能 | 状态 | 说明 |
|---|---|---|
| 线性回归定义与公式 | ✅ 已验证 | 单变量回归、多元回归概念清晰 |
| 线性关系分析 | ✅ 已验证 | 单变量与多变量线性关系图解 |
| 非线性关系 | ✅ 已验证 | 非线性关系示意图 |
| 损失函数 | ✅ 已验证 | 最小二乘法,总损失函数公式 |
| 解析解方式(正规方程) | ✅ 已验证 | 直接求解最优解,但计算复杂度高 |
| 梯度下降法 | ✅ 已验证 | 学习率控制步长,迭代收敛 |
| 单变量梯度下降示例 | ✅ 已验证 | J(θ)=θ² 迭代计算演示 |
| 多变量梯度下降示例 | ✅ 已验证 | J(θ)=θ₁²+θ₂² 迭代计算演示 |
| 梯度下降与正规方程对比 | ✅ 已验证 | 特征数量与样本量适用性对比 |
线性回归场景
● 房价预测 ● 销售额度预测 ● 贷款额度预测
以华氏度与摄氏度之间的转换为例进行描述 
线性回归定义
定义与公式
线性回归(Linear Regression)是利用回归方程(函数)对一个或多个自变量和因变量之间关系进行建模的一种分析方式
特点:只有一个自变量的情况称为单变量回归,多于一个自变量情况的叫做多元回归 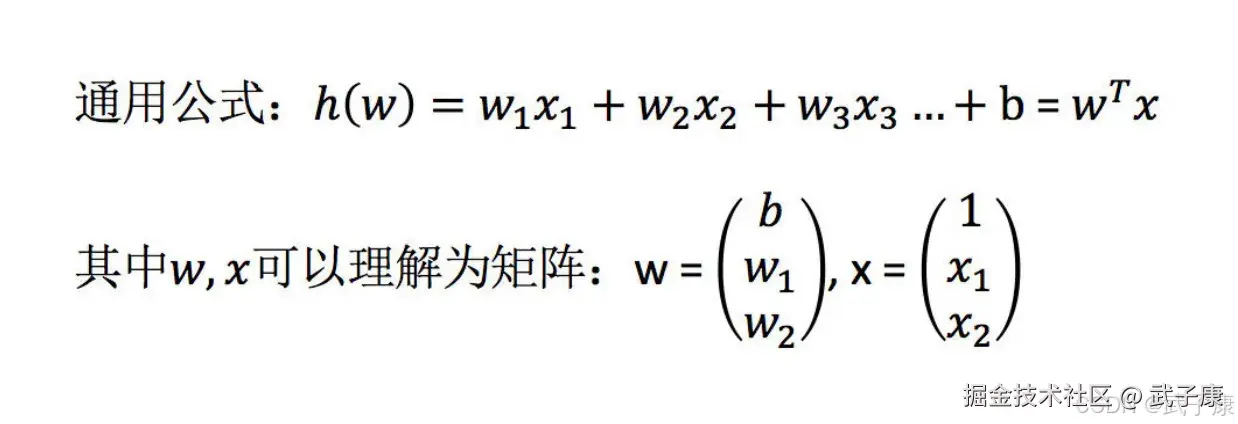 如下图的例子:
如下图的例子: 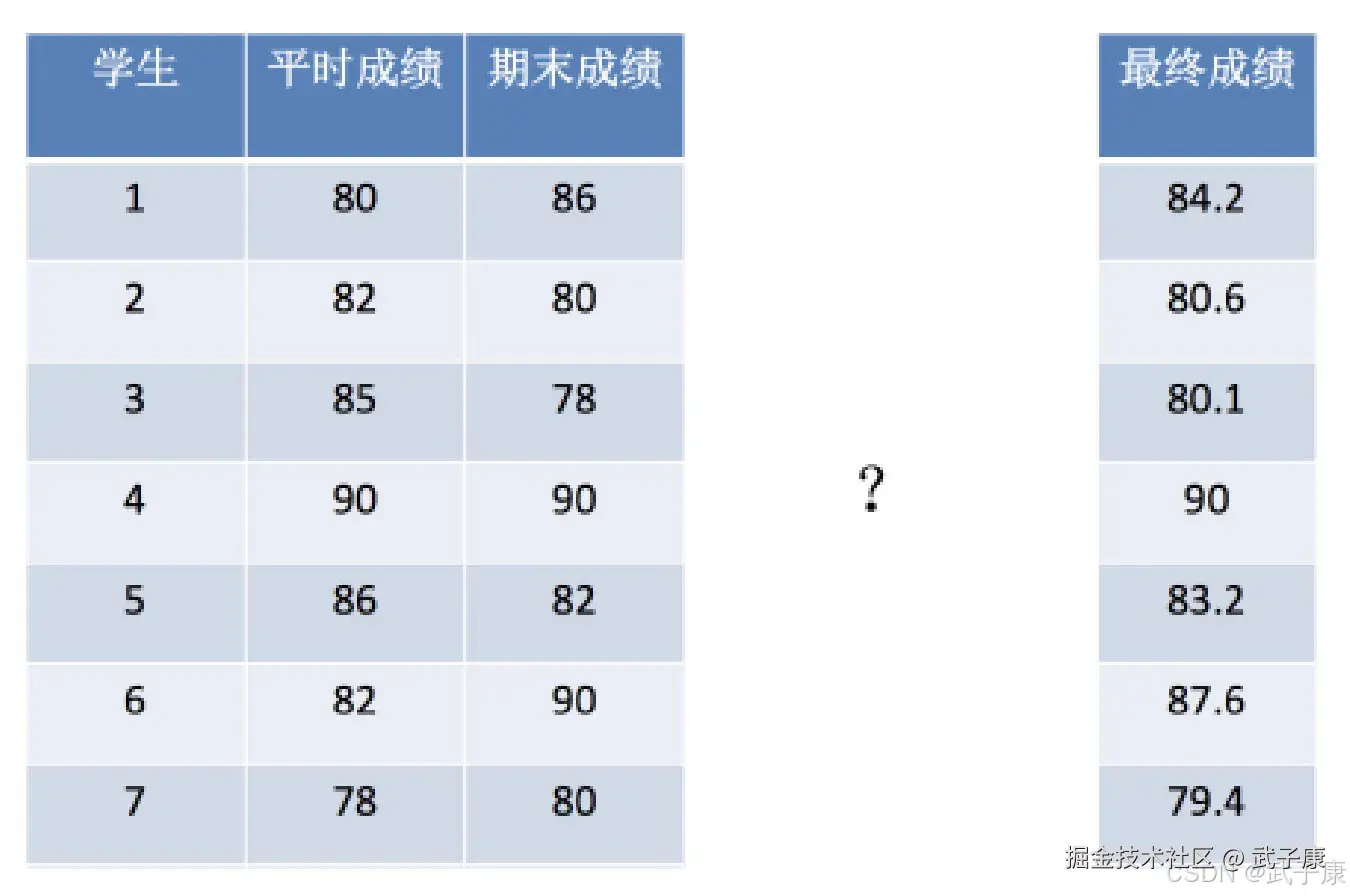 上面两个例子,我们看到特征值与目标值之间建立了一个关系,这个关系可以理解为线性模型。
上面两个例子,我们看到特征值与目标值之间建立了一个关系,这个关系可以理解为线性模型。
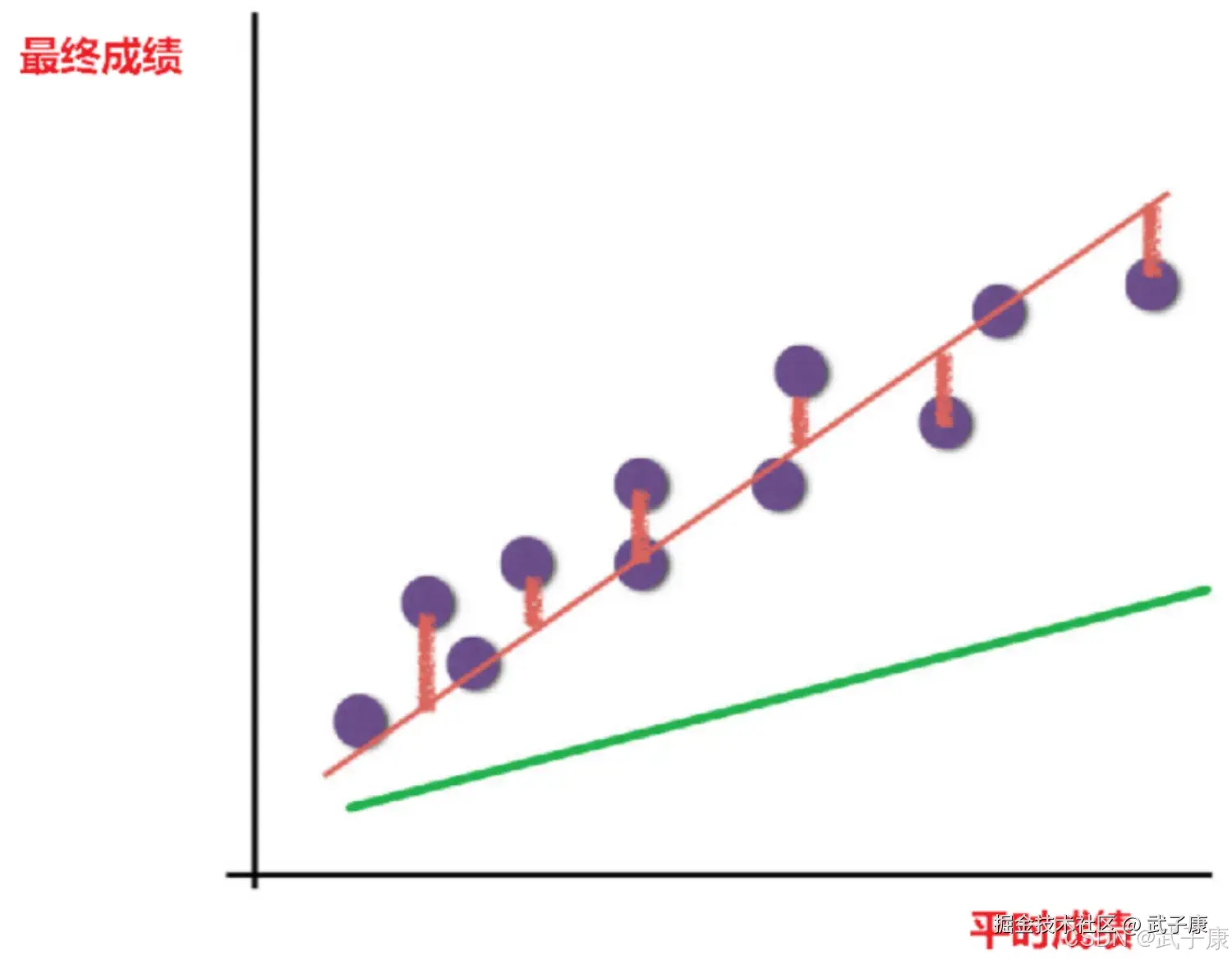
线性回归特征与目标关系分析
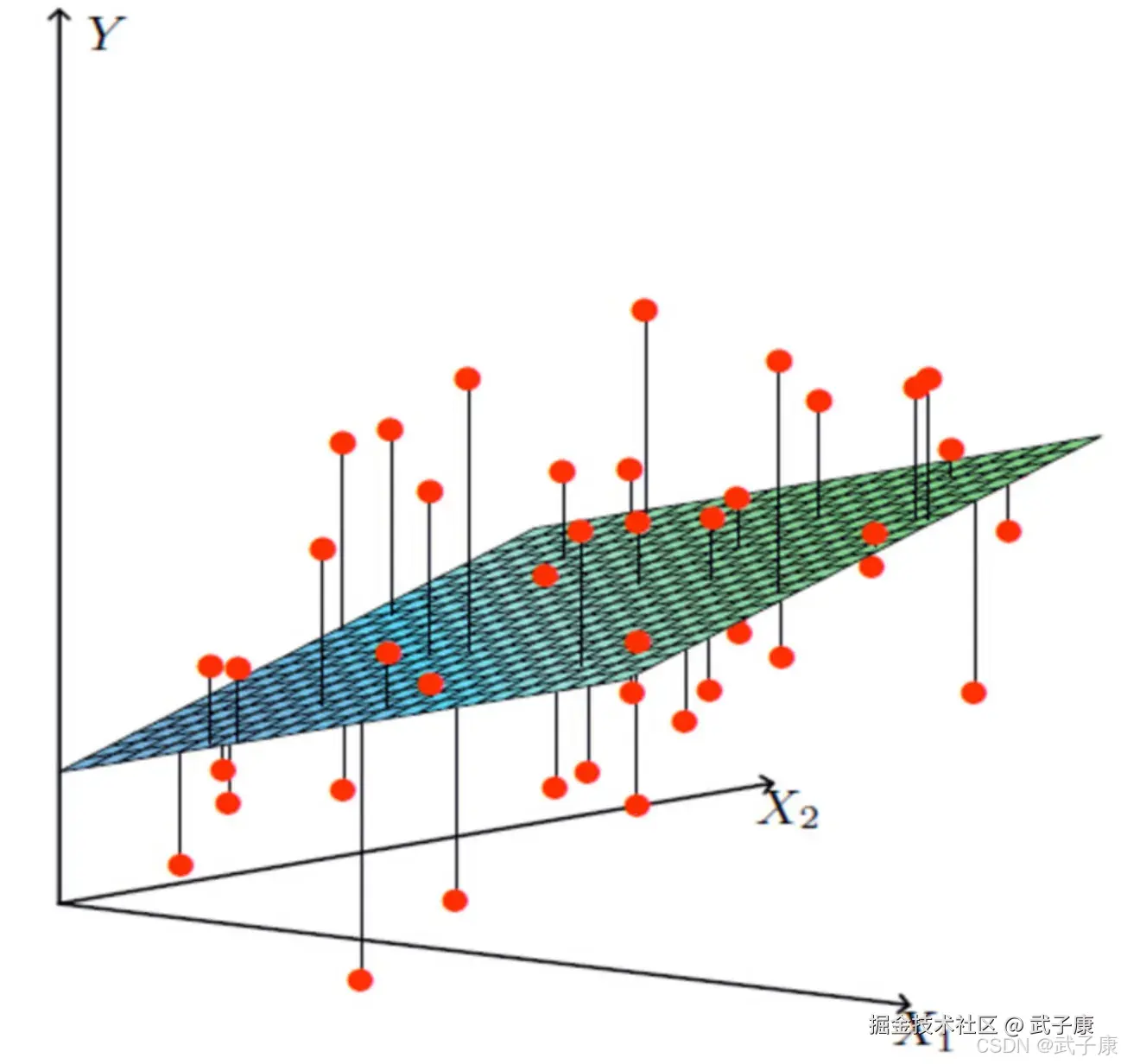
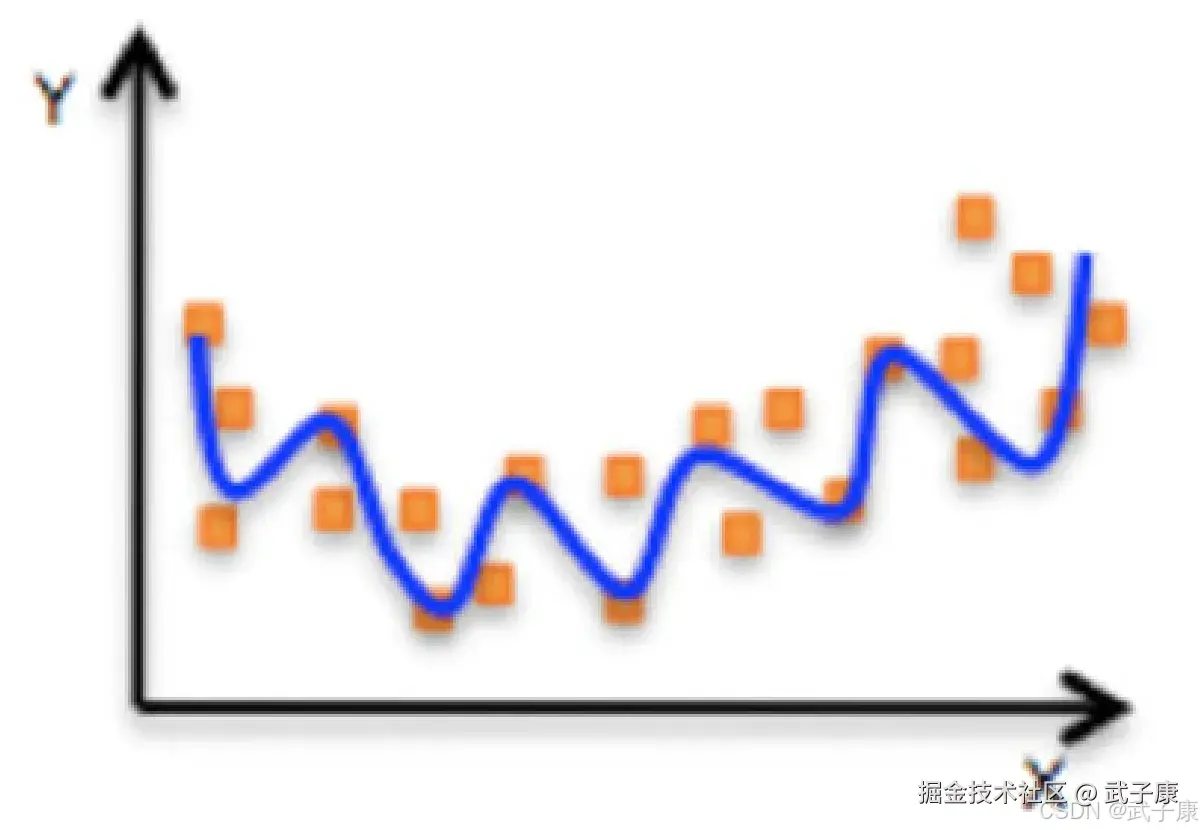
线性回归当中主要两个模型,一种是线性关系,另一种是非线性关系。在这里我们只能画一个平面去理解,所以都用单个特征或者两个特征举例子。
线性关系的单变量线性关系
线性关系的多变量线性关系
非线性关系
线性回归的损失和优化
假设学习成绩例子,真是的数据之间存在这样的关系:
shell
真实关系:最终成绩 = 0.5x平时成绩 + 0.3x期末成绩那么现在呢,猜测一个关系:
shell
猜测关系:预测最终成绩 = 0.45x平时成绩 + 0.2x期末成绩可以想到,真实结果与我们的预测的结果之间存在一定的误差。 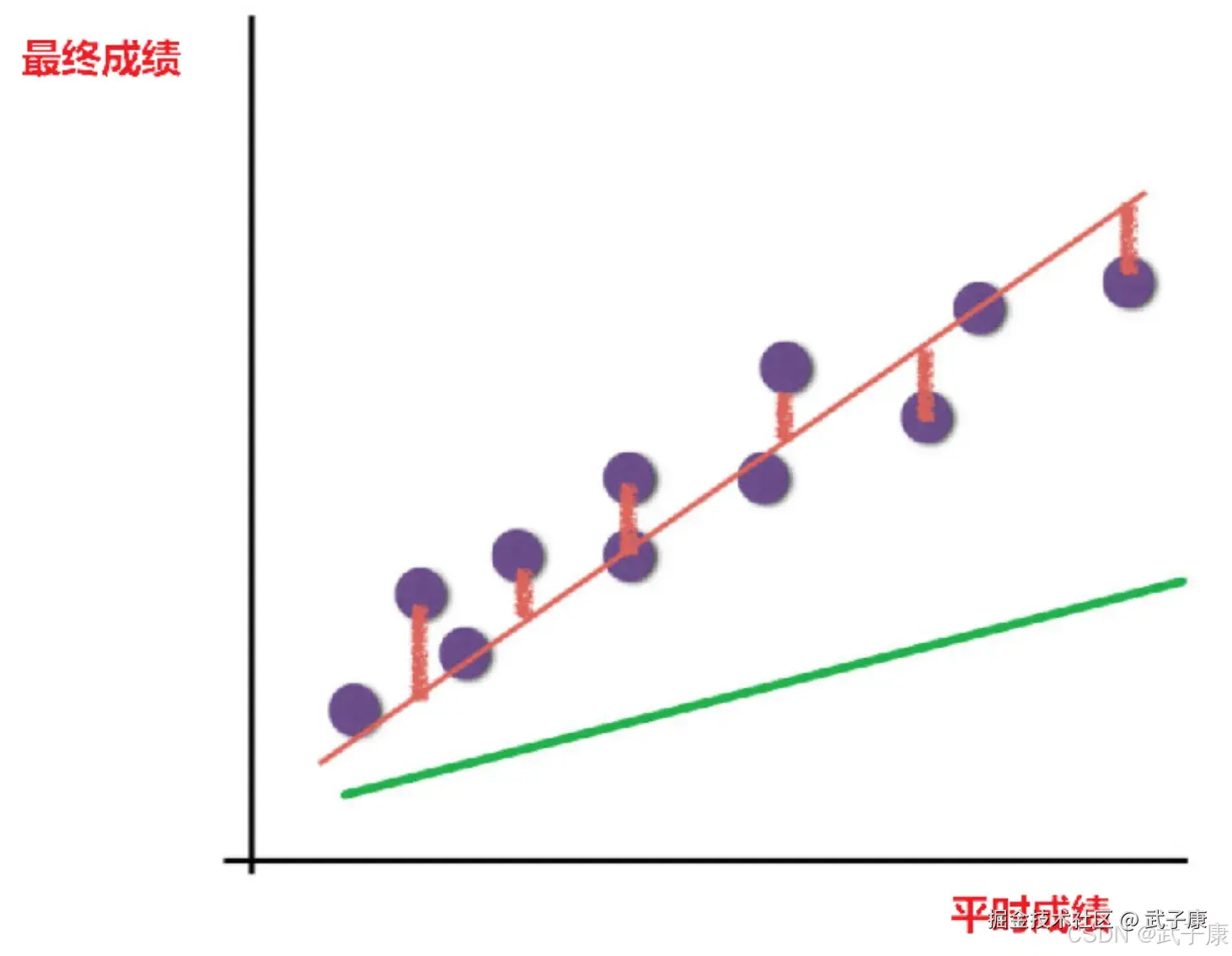 既然存在这个误差,如何衡量误差呢?
既然存在这个误差,如何衡量误差呢?
损失函数
总损失函数为: 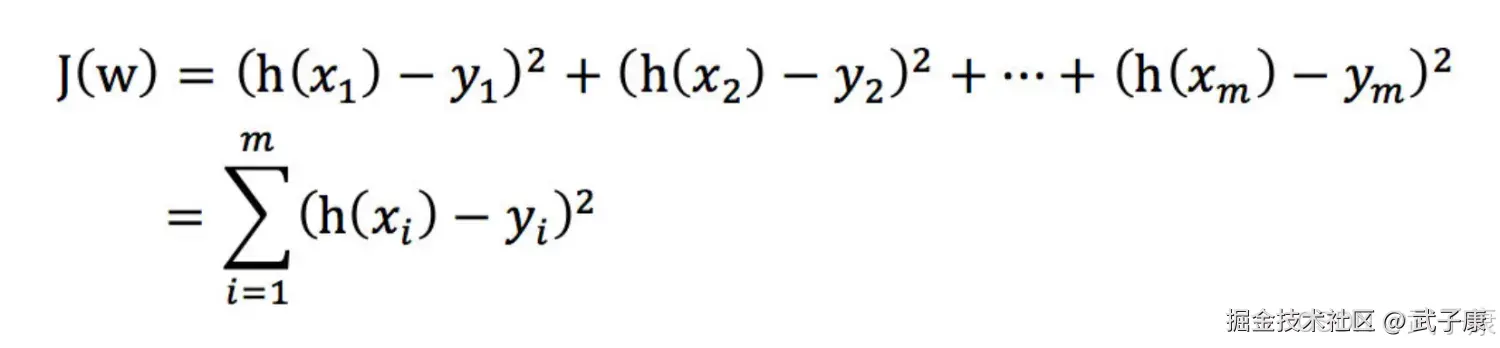 ● yi 为第i个训练样本的真实值 ● h(xi)为第i个训练样本特征值组合预测函数 ● 又称最小二乘法
● yi 为第i个训练样本的真实值 ● h(xi)为第i个训练样本特征值组合预测函数 ● 又称最小二乘法
优化算法
如何去模型当中的W,使得损失最小(目的是找到最小损失对应的W值) 线性回归经常使用的两种优化算法:解析解方式(正规方程)+ 梯度下降法
解析解方式
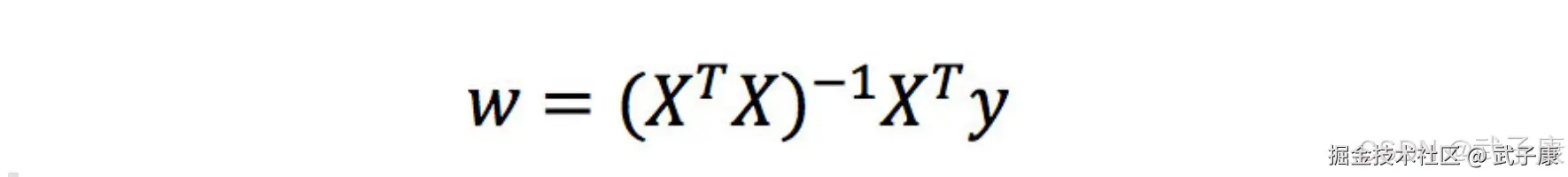
理解:X为特征值矩阵,Y为目标值矩阵,直接求到最好的结果。 缺点:当特征过多复杂时,求解速度太慢并且得不到结果。
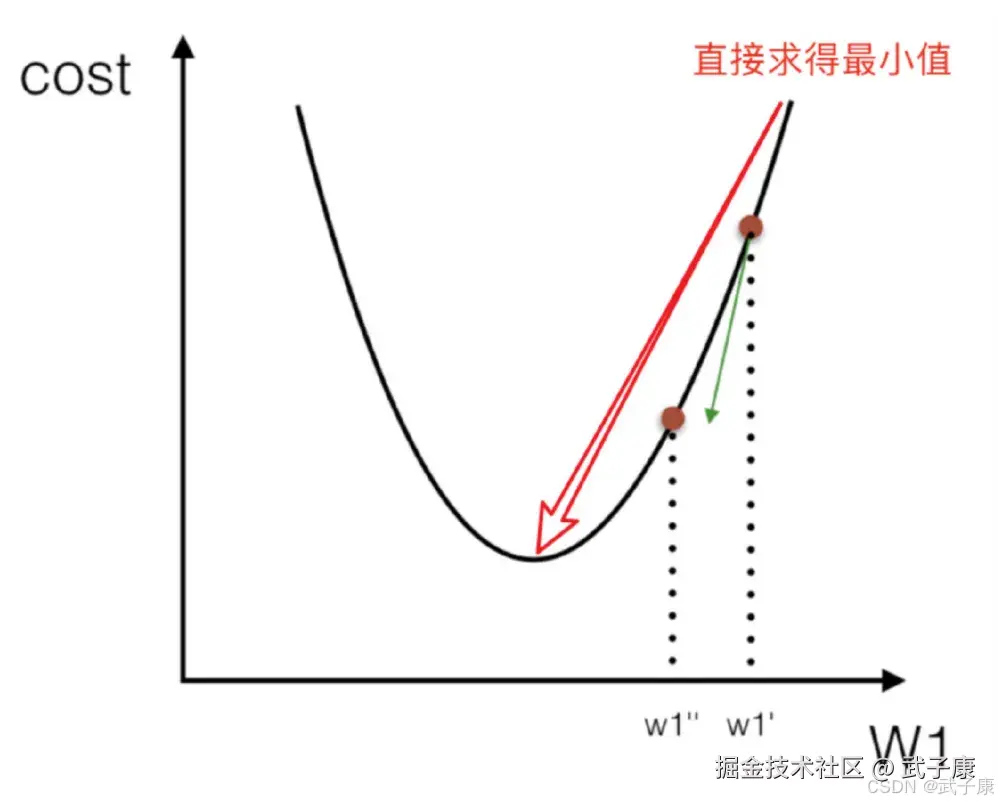
梯度下降(Gradient Descent)
梯度下降法的基本思想可以类比为一个下山的过程,一个人被困在山上,需要从山上下来(比如,找到山的最底点,也就是山谷),但此时山上的浓雾很大,导致可视度很低。因此,下山的路径无法确定,它必须利用自己周围的信息去找到下山的路径,这个时候,他就可以利用梯度下降算法来帮助自己下山。
具体来说,以它当前所处的位置为基准,寻找这个位置最陡峭的地方,然后朝着山的高度下降的地方走。同理,如果我们的目标是上山,也就是爬山山顶,那么此时应该是朝着最陡峭的方向往上走,然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。
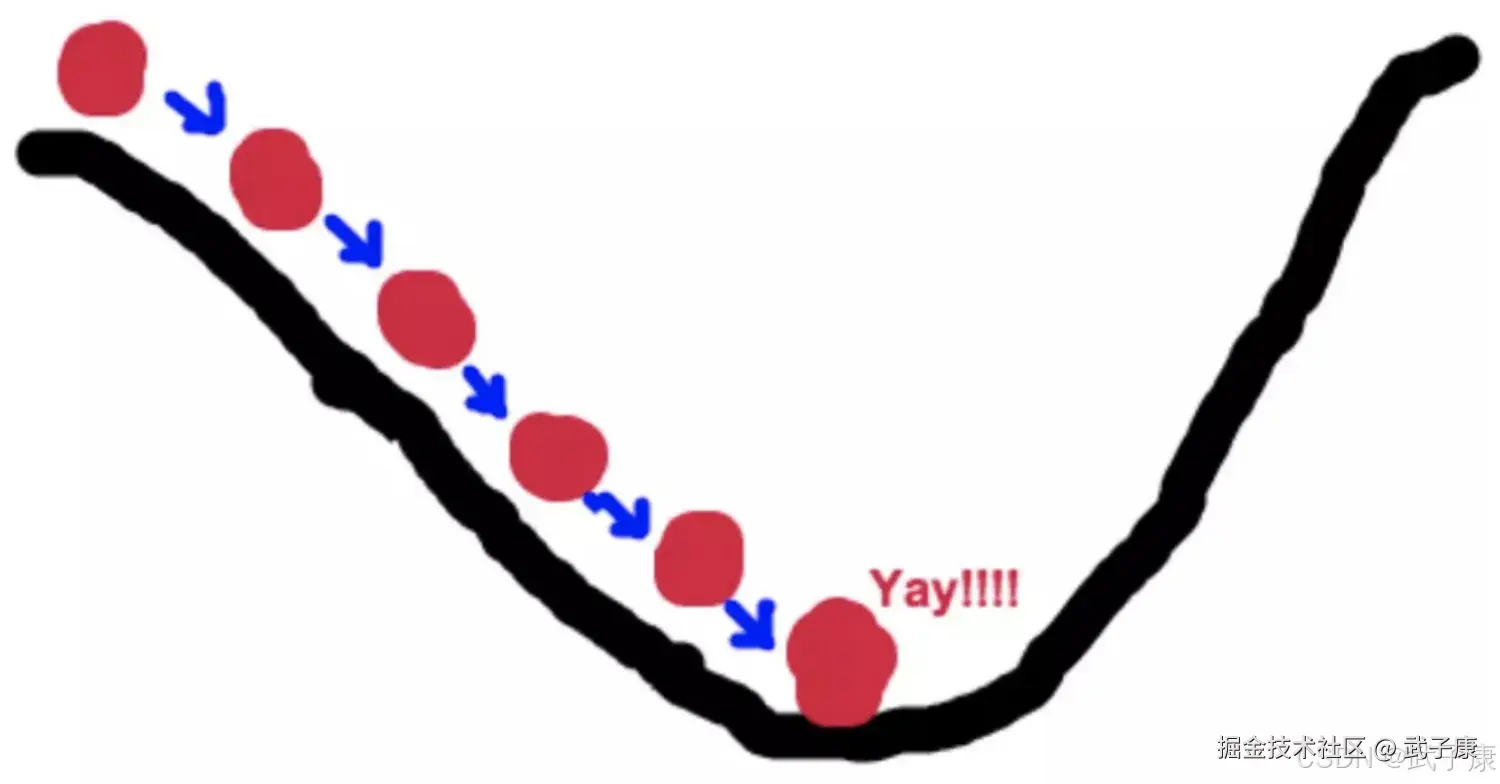 梯度下降的基本过程就和下山的场景很类似。梯度是微积分中的一个很重要的概念: ● 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个定点的切线的斜率 ● 再多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指定了函数在给定点的上升最快的方向 ● 在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
梯度下降的基本过程就和下山的场景很类似。梯度是微积分中的一个很重要的概念: ● 在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个定点的切线的斜率 ● 再多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指定了函数在给定点的上升最快的方向 ● 在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
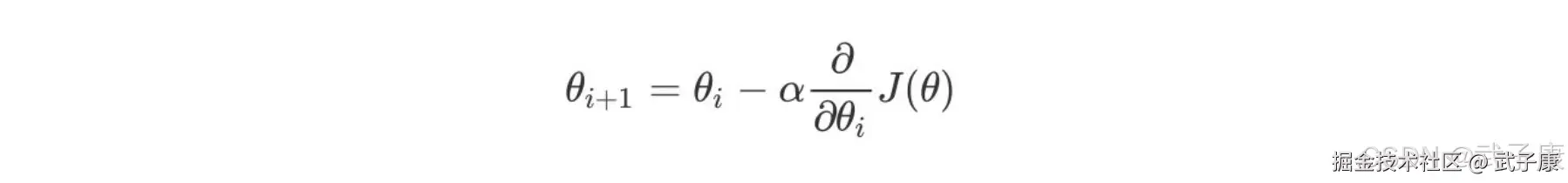 α 的含义:α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步长跨的太大扯着蛋。其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以α的选择在梯度下降中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点。
α 的含义:α在梯度下降算法中被称作为学习率或者步长,意味着我们可以通过α来控制每一步走的距离,以保证不要步长跨的太大扯着蛋。其实就是不要走太快,错过了最低点。同时也要保证不要走的太慢,导致太阳下山了,还没有走到山下。所以α的选择在梯度下降中往往是很重要的!α不能太大也不能太小,太小的话,可能导致迟迟走不到最低点,太大的话,会导致错过最低点。
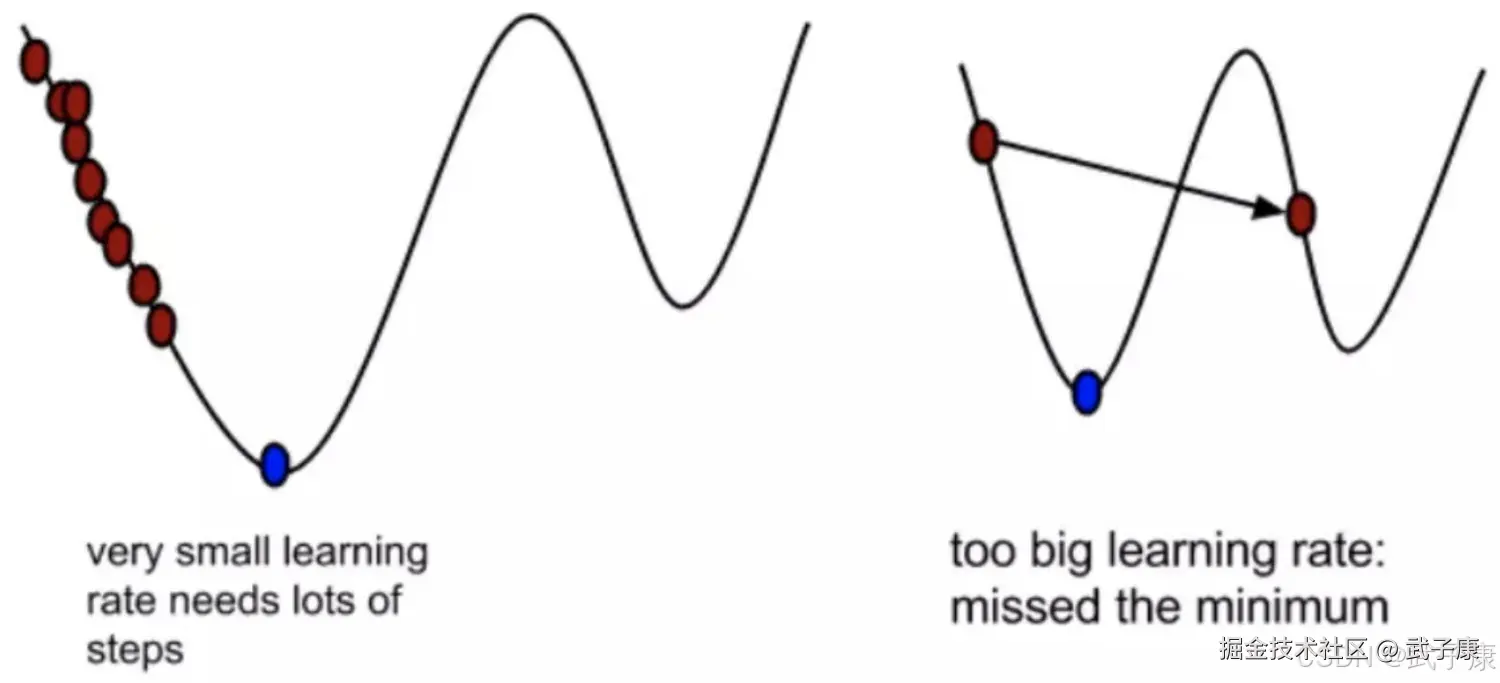
为什么梯度要乘以一个负号
梯度前加一个负号,就意味着朝着梯度相反的方向前进!我们在前文中提过,梯度的方向实际就是函数在此点上升最快的方向,自然就是负的梯度的方向,所以此处需要加上负号。 我们通过两个图更好理解梯度下降的过程。
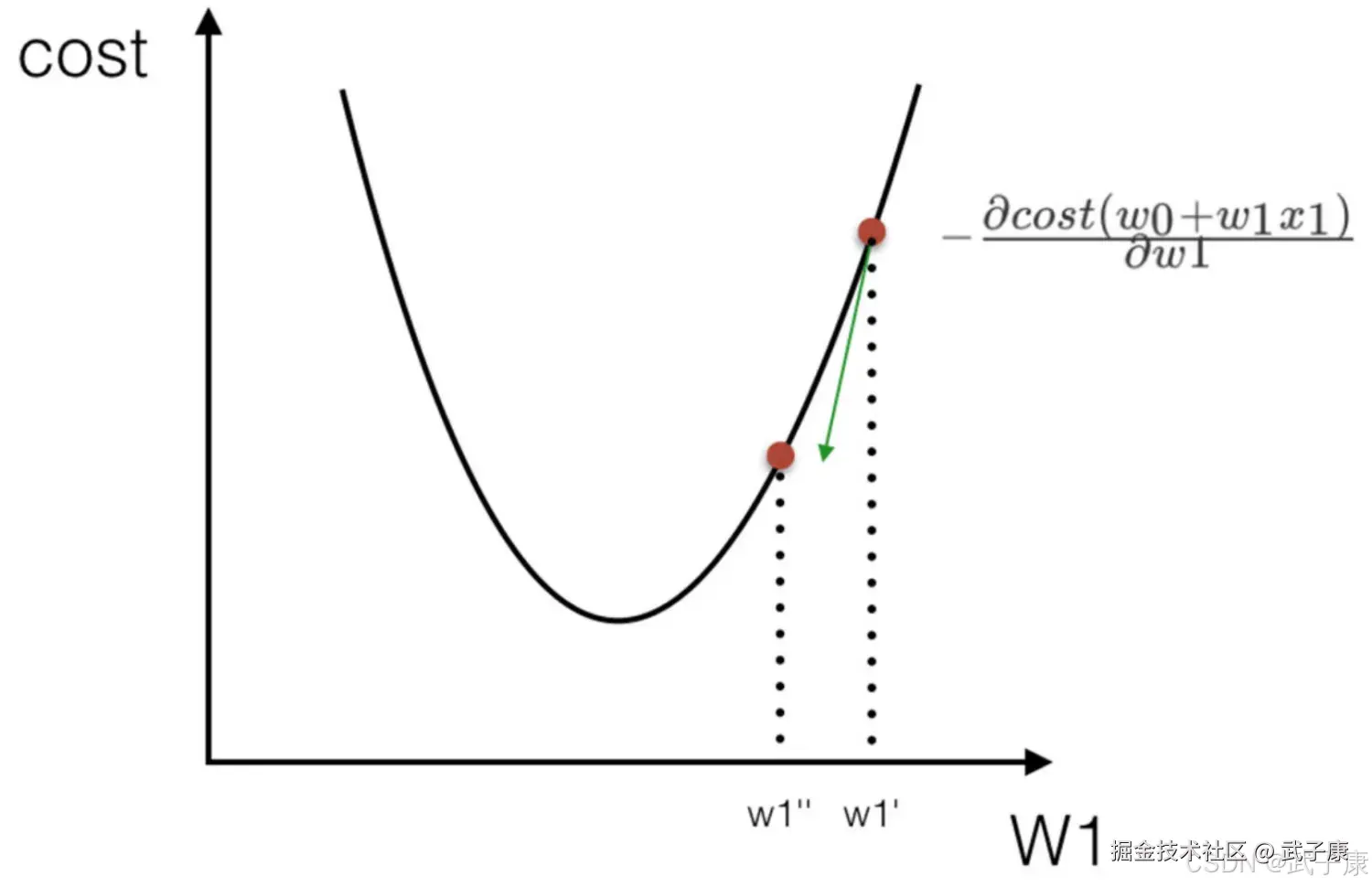 优化动态图演示
优化动态图演示 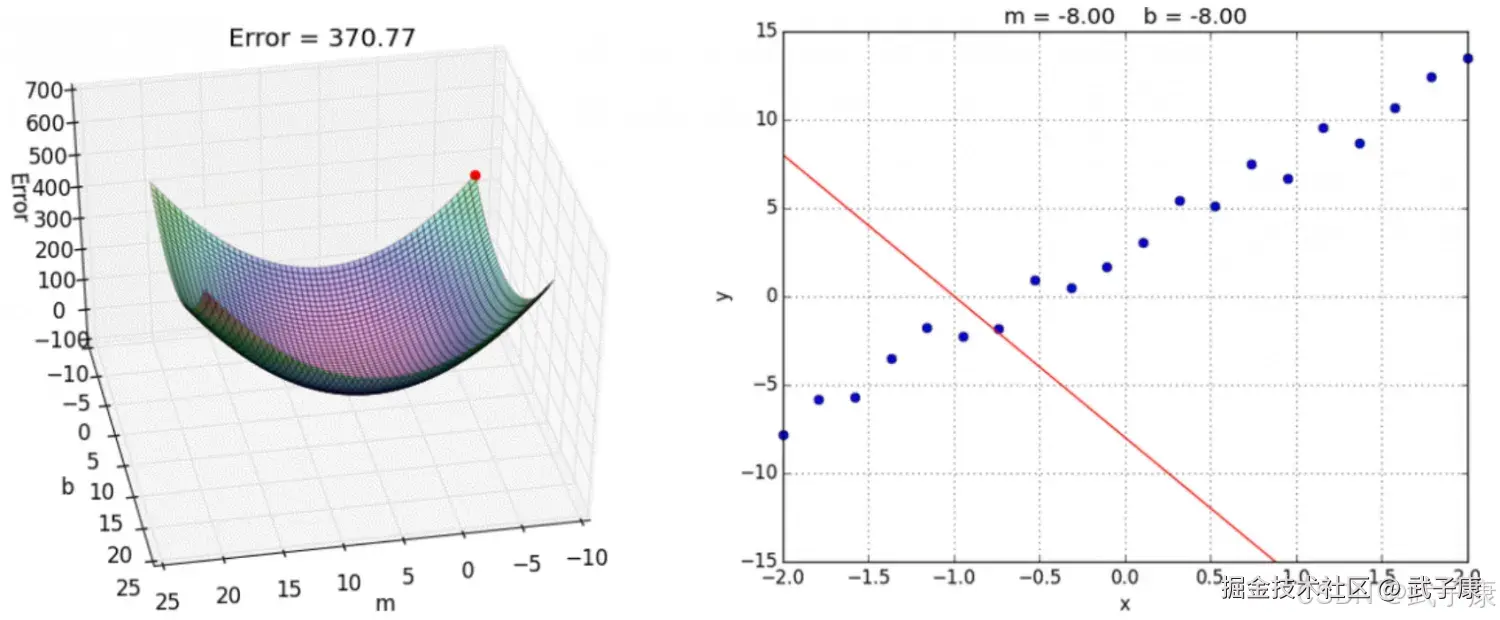
单变量函数的梯度下降:
- 我们假设有一个单变量的函数 J(θ) = θ2
- 初始化,起点为 θ0 = 1
- 学习率 α = 0.4
我们开始进行梯度下降的迭代计算过程: 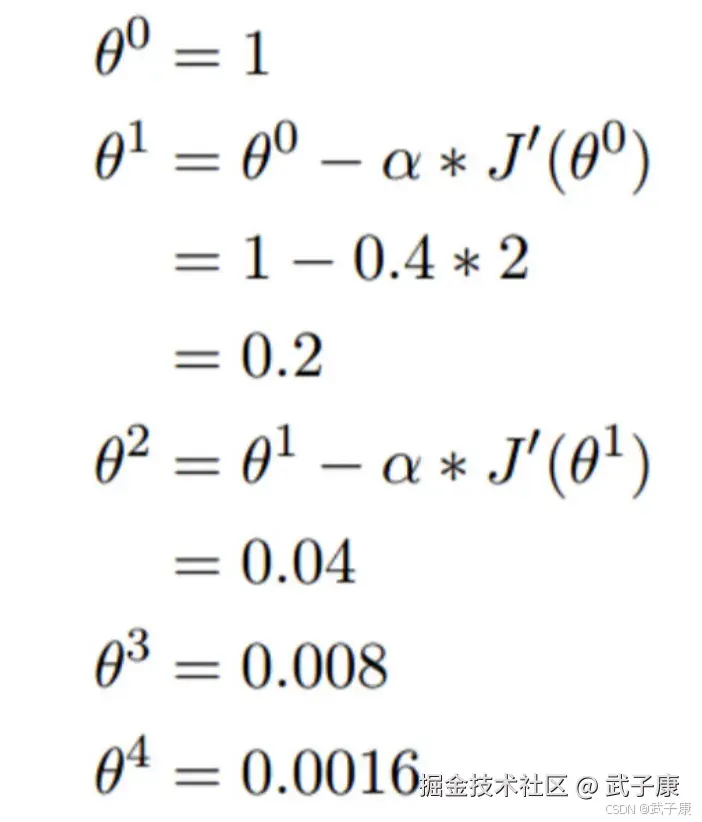
如果,经过四次的运算,也就是走了四步,基本就抵达了函数的最低点,也就是山底。 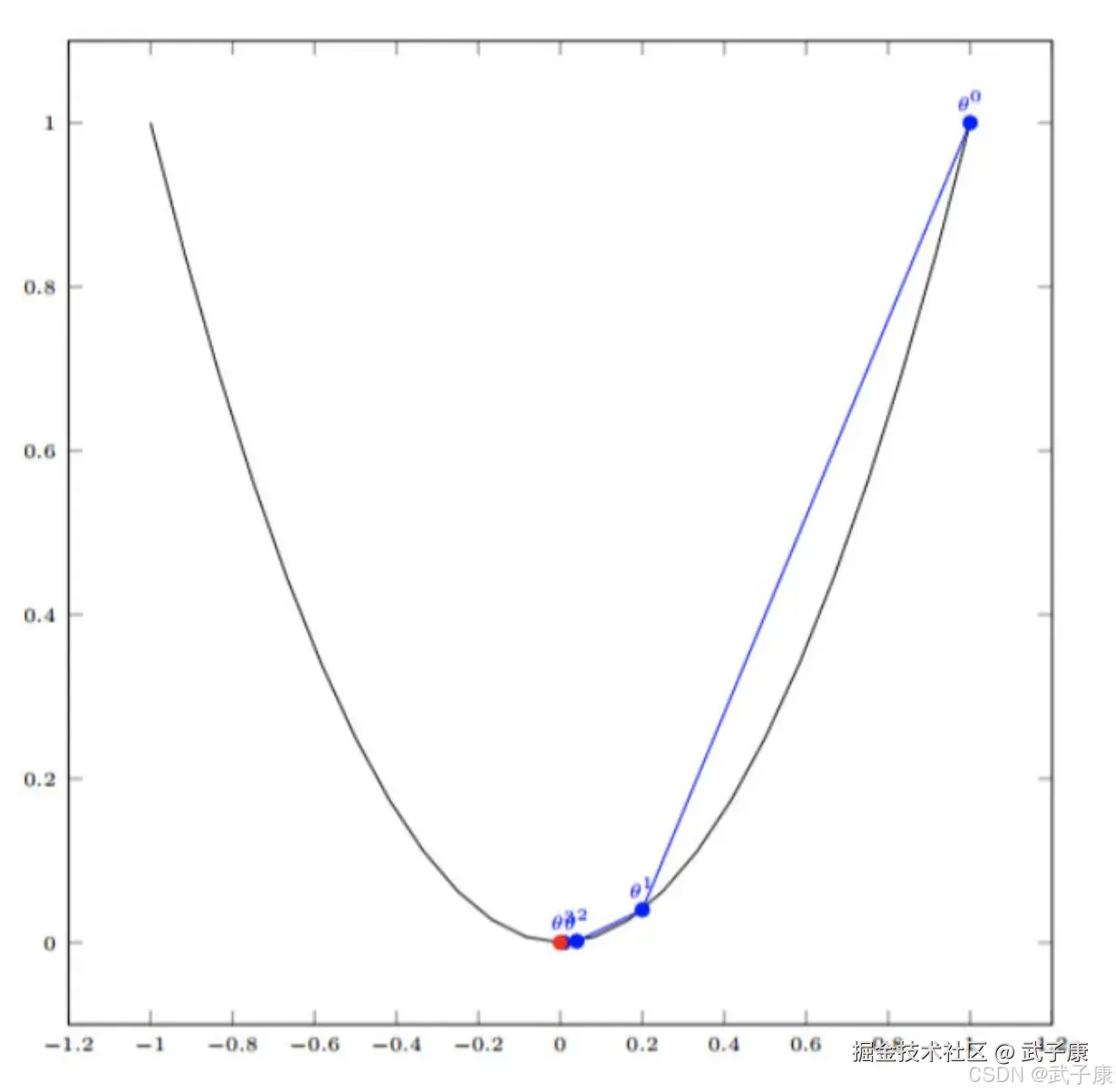
多变量函数的梯度下降
我们假设有一个目标函数:J(θ) = θ12 + θ22
- 现在要通过梯度下降法计算这个函数的最小值,我们通过观察就能发现最小值其实就是(0,0)点。但是接下来,我们会从梯度下降算法开始一步步计算到这个最小值!我们假设初始的起点为:θ0 = (1, 3)。
- 初始的学习率为 α = 0.1
- 函数的梯度为:J(θ) =< 2θ1 ,2θ2>
进行多次迭代: 
我们发现,已经基本靠近函数的最小值点: 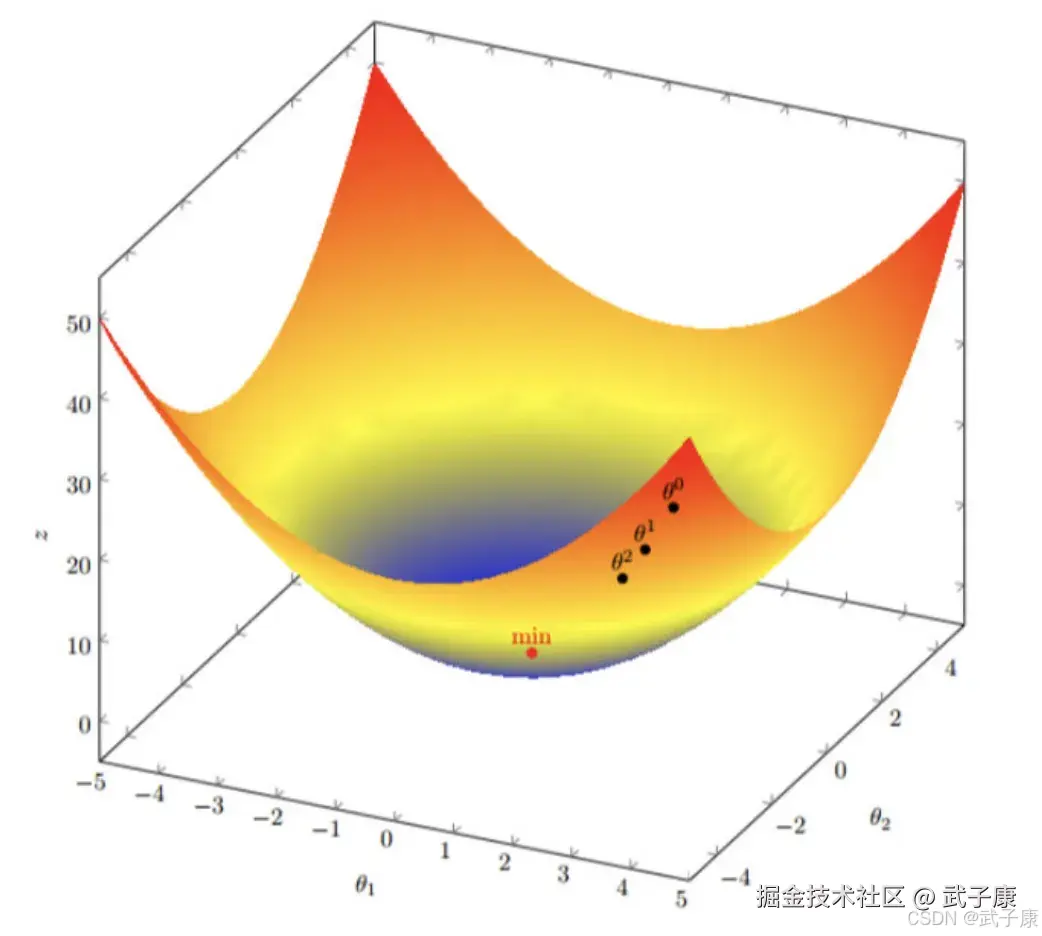 梯度下降和正规方程的对比
梯度下降和正规方程的对比 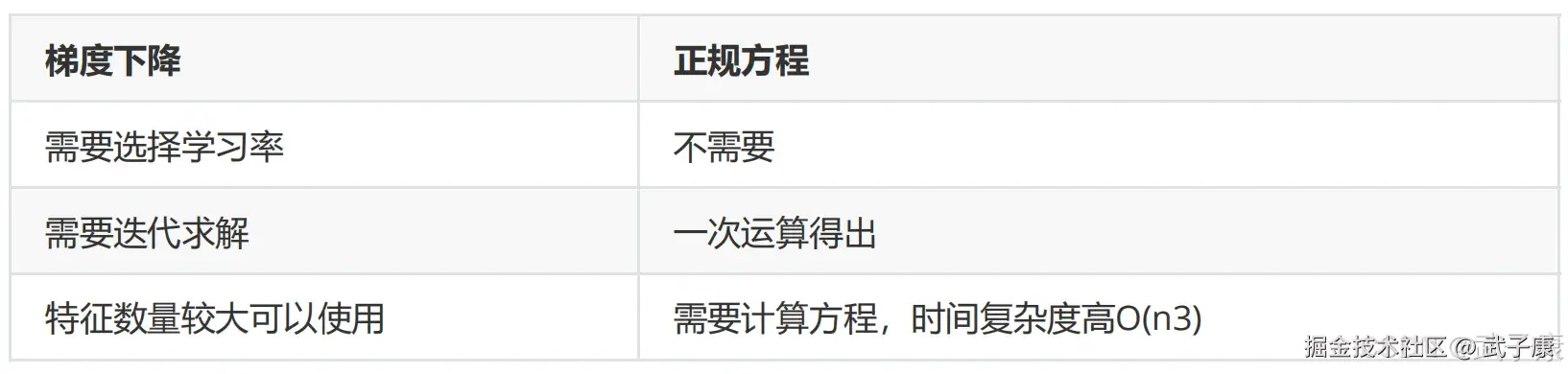
错误速查卡
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| 梯度下降迟迟无法收敛 | 学习率 α 设置过小 | 观察损失函数曲线下降速度 | 适当增大学习率 |
| 梯度下降越过最低点来回震荡 | 学习率 α 设置过大 | 观察损失函数曲线发散模式 | 减小学习率或使用衰减学习率 |
| 正规方程求解耗时过长 | 特征矩阵维度太高(n过大) | 观察特征数量与样本量比值 | 改用梯度下降法 |
| 正规方程无解或数值不稳定 | XTX 矩阵奇异或接近奇异 | 检查特征是否存在多重共线性 | 添加正则项或删除冗余特征 |
| 预测结果为 NaN | 特征值未标准化/学习率过大 | 检查输入数据范围 | 先标准化数据,减小学习率 |
| 过拟合(训练集好测试集差) | 模型过于复杂/特征过多 | 对比训练集与测试集误差 | 增加正则化或减少特征 |