一、PaddleOCR简介
PaddleOCR 是基于百度飞桨(PaddlePaddle)深度学习框架开发的开源 OCR 工具库。它有以下特点:
1、超轻量级:PP-OCR 系列模型非常小(几 MB 大小),但在 CPU 和移动端上速度飞快。
2、通用性强:支持中、英、法、德、韩、日等 80 多种语言的识别。
3、功能丰富:不仅支持文字检测和识别,还支持版面分析、表格识别等复杂任务。
二、环境搭建
这里建议新建一个虚拟环境来安装PaddleOCR,避免与其他python库冲突。
示例代码:
conda create -n paddleocr python=3.9参考以下说明文档:
doc/doc_ch/quickstart.md · PaddlePaddle/PaddleOCR - Gitee.com

发现需要安装两个包:paddlepaddle,paddleocr
2.1 paddleocr(飞桨)安装
2.1.1 有NVIDIA显卡
如果机器安装的是CUDA9或CUDA10,请运行以下命令安装
python
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple其他CUDA版本的安装方式参考以下链接:
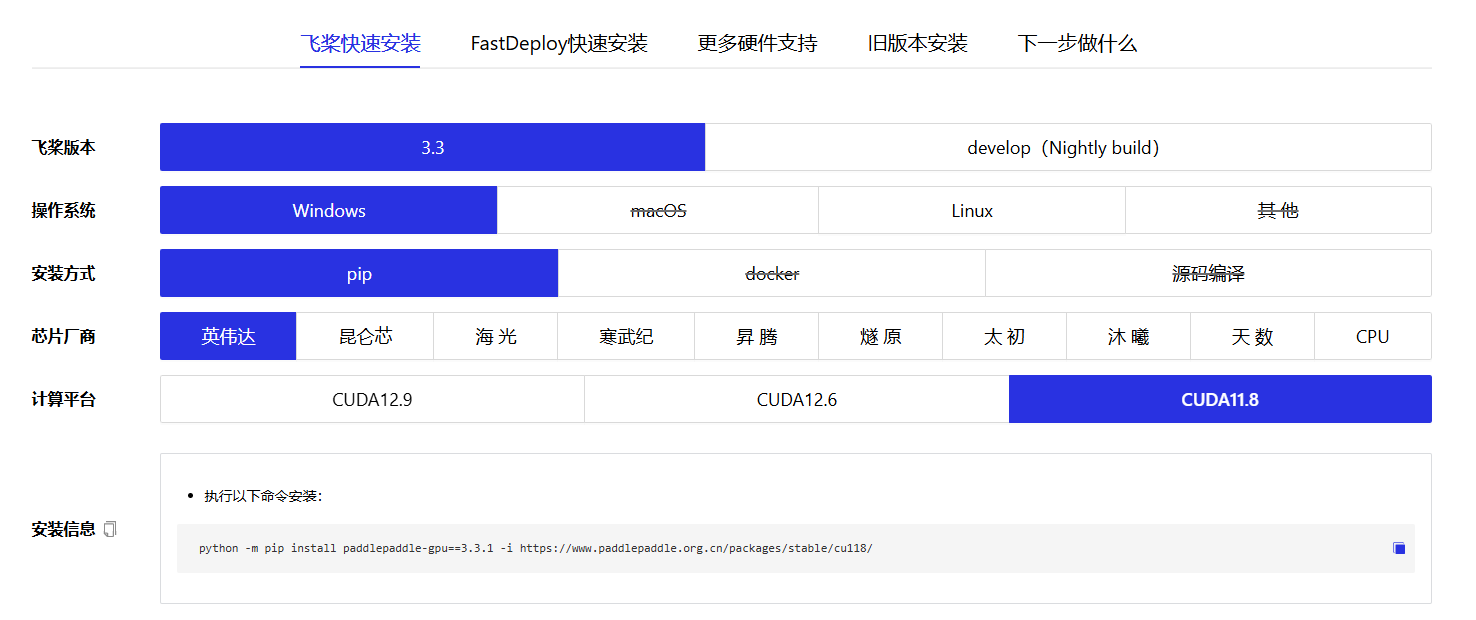
2.1.2 只有CPU/通用版本
请运行以下命令:
python
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple2.2 PaddleOCR的安装
python
pip install "paddleocr>=2.0.1" # 推荐使用2.0.1+版本三、快速上手------命令行
这里以古诗图片为例,代码:
python
paddleocr --image_dir ./shi.jpg --use_angle_cls true --lang ch参数介绍:
--image_dir: 图片路径。
--use_angle_cls: 是否加载方向分类器(如果是倒着的文字能自动纠正)。
--lang: 语言,ch 代表中文,en 代表英文。
结果: 终端会输出识别到的文字列表,包含:[[文字位置坐标], (识别结果, 置信度)]
四、实战------识别唐诗案例
唐诗图片如下:

代码如下:
python
from paddleocr import PaddleOCR
# 参数含义参考:
'''
https://blog.csdn.net/qq_41273999/article/details/135868038?ops_request_misc=%257B%2522request%255Fid%2522%253A%252299FC8A
'''
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='ch') # 'ch' 就是识别中文
# 如果报路径错误,使用一下代码,指定模型下载路径
# ocr = PaddleOCR(use_angle_cls=True, use_gpu=True,
# det_model_dir='ch_PP-OCRv3_det_infer', # 文本检测
# rec_model_dir='ch_PP-OCRv3_rec_infer', # 文本识别
# cls_model_dir='ch_ppocr_mobile_v2.0_cls_slim_infer', # 旋转文本(通用)
# lang="ch")
# ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, # 关闭日志
# det_model_dir='en_PP-OCRv3_det_infer', # 文本检测
# rec_model_dir='en_PP-OCRv3_rec_infer', # 文本识别
# cls_model_dir='ch_ppocr_mobile_v2.0_cls_slim_infer', # 旋转文本(通用)
# lang="en")
img_path = r'tangshi2.png'
result = ocr.ocr(img_path, cls=True)
print(result)
for line in result[0]:
print(line[1][0])
关于代码需要注意:
1、代码中 ocr = PaddleOCR(use_angle_cls=True, use_gpu=False, show_log=False, lang='ch') 的可选参数有很多,具体参数详解请参考:链接
2、模型自动下载 :第一次运行代码时,PaddleOCR 会自动下载轻量级模型(PP-OCRv4)到 ~/.paddleocr/ 目录下,无需手动下载
3、数据结构 :result 的返回值比较复杂,是一个嵌套列表。最核心的数据是 (text, score),分别代表识别出的文本内容和置信度(0-1之间,越大越准)。
4、字体问题 :draw_ocr 函数如果需要绘制中文结果,必须指定 font_path,否则中文会显示为乱码。你可以从 Windows 的 C:\Windows\Fonts 下复制一个 simhei.ttf 或 simfang.ttf 到项目目录。