一、前言
前两天研究了一下Moonshine Voice,当时拿了几个简单的音频文件测试了一下,感觉效果还可以,所以我就开始将其整合到了OddASR项目里。
但是在完成了整合后,再进行测试的时候发现一些比较严重的问题,所以,我又赶紧把我刚刚上传到pypi的OddASR给撤了,然后重新将主力模型改回到paraformer-zh-streaming和paraformer-zh。
当前OddAsr最新版本:v2.1.0,已恢复paraformer模型。
以下是在OddAsr自带的测试界面上分别跑paraformer-zh和moonshine base模型的效果
二、安装测试 OddAsr
安装OddAsr
bash
pip install oddasr打开OddAsr的Demo Web
bash
http://localhost:9002注:首先安装的话,需要从huggingface.co下载模型,记得设镜像,否则国内无法访问。并且,如果你家的网速不是非常快的话,可能要下载个十几分钟到半个钟头。
测试音频
- 前面一段和后面一段的声音都是干净的,转写效果非常好,准确率基本可认为100%;
- 中间一段模拟了一些背景噪声与嘈杂环境,无论是持续的空调嗡鸣、键盘敲击声,还是突发的交通噪音、旁人交谈,都会干扰ASR模型,导致其识别错误甚至完全遗漏词语。
具体的声音情况可以看这个视频:
https://mp.weixin.qq.com/s/y4l-YtaUhayV9k9EDatCzw
注:这个视频中并未使用我的OddASR,效果差不是我OddAsr项目的锅。相反,下面我后来有将这个视频中的音频提取出来,专门作为OddAsr的一个测试集,每次测试不同的ASR模型的时候都会来测试一下这种场景。比如:这次的Moonshine base中文模型的测试。
三、测试效果
测试使用的音频就是上面那个视频里提取出来的音频。
paraformer模型效果
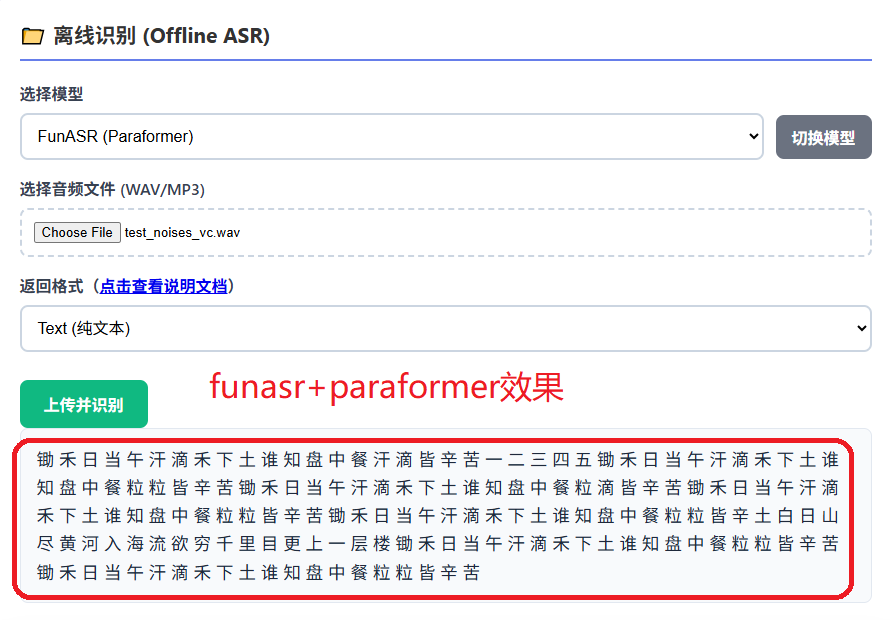
只想用一个字来形容:bravo!
moonshine base模型效果
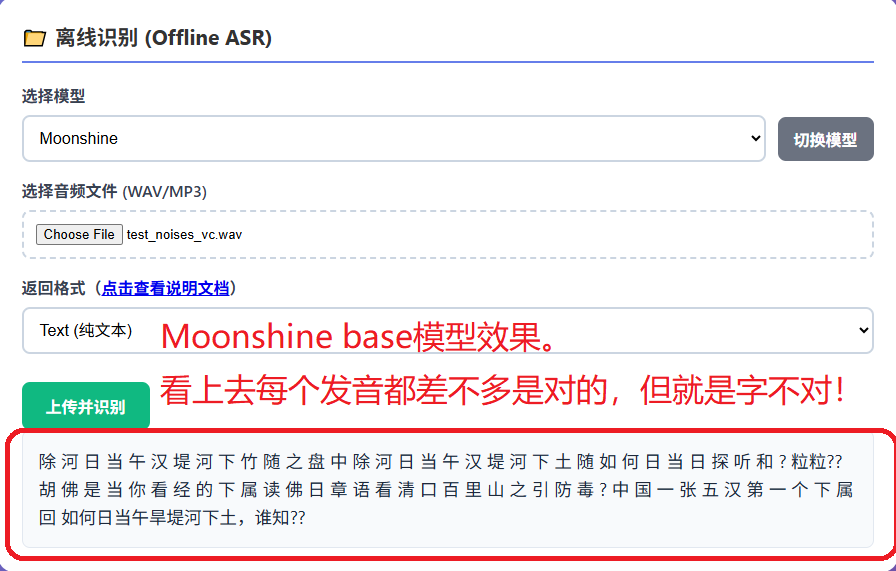
看上去转写出来的每个发音都是对的,但是。。。。这些个字呢。。。。好像就没几个是对的。
四、总结
唉,如果不是因为我这个用了超过十年的老笔记本CPU不太够用,我也完全不想去折腾一些其他的轻量级的ASR模型。